- 前言
- 1 JavaScript
- 2 HTML/CSS
- 3 HTTP/计网
- 3.1 网址栏输入地址之后具体会发生什么?
- 3.2 三次握手,四次挥手
- 3.3 状态码
- 3.4 跨域
- 3.5 简单请求/预检请求
- 3.6 content-type常用值
- 3.7 jwt/access token/refresh token
- 3.8 TCP四种定时器
- 3.9 TCP/UDP
- 3.10 文件断点续传
- 3.11 HTTP迭代
- 3.12 websocket/HTTPS
- 3.13 HTTP缓存
- 3.14 DNS域名解析
- 3.15 cookie/session/localStorage/sessionStorage
- 3.16 常见协议
- 3.17 TCP粘包现象
- 3.18 IP地址划分
- 3.19 窗口滑动协议
- 3.20 计网模型7/5/4
- 3.21 ARP协议
- 4 数据库
- 5 Vue
- 6 前端工程化
- 7 手撕代码
- 8 其他
- 参考资料
前言
这是一篇所有前端面试常见问题的合集,内容过于繁杂,建议配合目录使用,手机端外链版目录在屏幕左下角,手机端APP目录在右上角,PC端目录在右侧。
1 JavaScript
1.1 this
对于函数而言,指向最后调用函数的那个对象,是函数运行时内部自动生成的一个内部对象,只能在函数内部使用;
对于全局而言,this 指向 window。
箭头函数下this指向外层最近对象
1.2 arr.map()
let array = [ , 1, , 2, , 3];array = array.map((i) => ++i) // [ , 2, , 3, , 4]

1.3 柯里化
add(1)(2)(3):function add(a){const tmp = function(b){return add(a + b)}tmp.toString = function(){return a}return tmp}
1.4 防抖和节流
1.4.1 防抖
对于短时间内连续触发的事件(上面的滚动事件),防抖的含义就是让某个时间期限(如上面的1000毫秒)内,事件处理函数只执行一次。
就是一直拖就一直不执行,结束才执行
1.4.2 节流
如果短时间内大量触发同一事件,那么在函数执行一次之后,该函数在指定的时间期限内不再工作,直至过了这段时间才重新生效。
一直拖,中间执行一次,过段时间再执行下一次
1.5 渲染 & 回流 & 重绘
1.5.1 渲染
- 浏览器将获取的HTML文档并解析成DOM树。
- 处理CSS标记,构成层叠样式表模型CSSOM(CSS Object Model)。
- 将DOM和CSSOM合并为渲染树(rendering tree)将会被创建,代表一系列将被渲染的对象。
- 渲染树的每个元素包含的内容都是计算过的,它被称之为布局layout。浏览器使用一种流式处理的方法,只需要一次pass绘制操作就可以布局所有的元素。
- 将渲染树的各个节点绘制到屏幕上,这一步被称为绘制painting.
1.5.2 回流
当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候,这时候是一定会发生回流的,因为要构建render tree。在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为重绘。1.5.3 重绘
当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。1.6 addEventListen
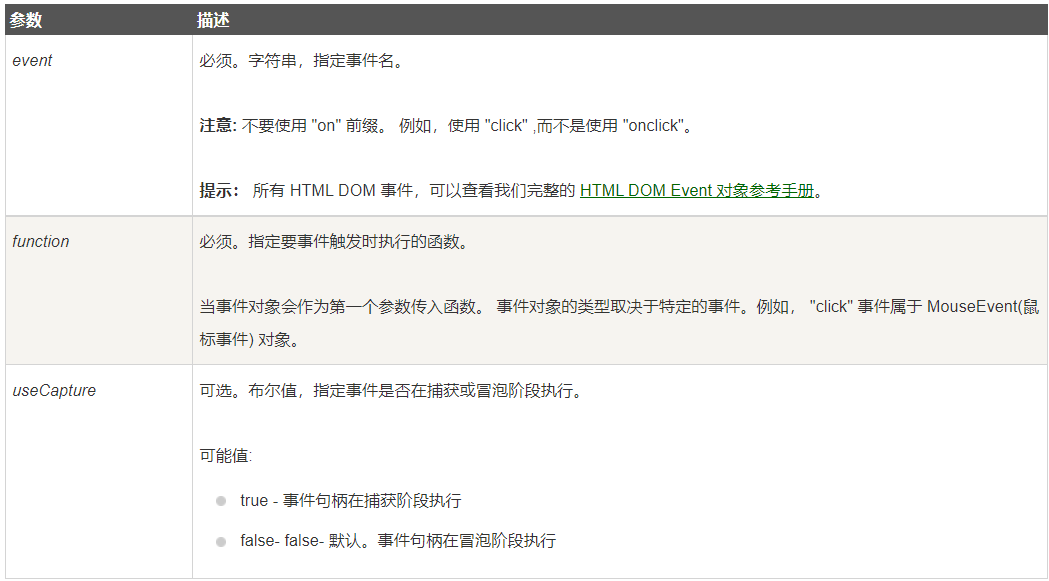
1.7 闭包
闭包函数
声明在一个函数中的函数,比如下面例子中的b函数
闭包
内部函数总是可以访问其所在的外部函数(下面的a)中声明的参数和变量,即便外部函数被返回
作用function a() {var i = 0; // 这个就是外面还想访问的变量,不会因a的return就被清理function b() {alert(++i); // 这里调用外部函数的变量}return b // 这里如果不返回b,则ab互相引用,与外界无关,则ab被回收}var c = a() // 事实上是返回(调用)bc(); // 显示++i
让外部访问函数内部变量成为可能,且该局部变量常驻内存,不被清理,可以避免使用全局变量,防止全局变量污染
缺点
内存泄漏,一块内存空间被长期占用不释放1.8 promise
promise有三种状态:pending/reslove/reject 。
pending就是未决,resolve可以理解为成功,reject可以理解为拒绝。
then和cantch都有reject的时候,优先调用then,then没有就用catch的rejectsettimeout等属于宏任务,跟promise并列执行,promise是微任务,如果触发,放入微任务列表,优先执行
// then中的onfulfilled,onreject回调是异步执行的
new Promise(function(resolve,reject){
// 未决部分代码,直接执行
console.log(1);
// 在合适的时间,将任务推向已决
resolve(3); // 推向已决,并附带数据 3
}).then(function(value){//onfulfilled函数
console.log(value);
},function(err){//onreject函数
console.log(reason)
})
console.log(2);
//打印结果
1
2
3
// 未决部分代码直接执行,输出1,resolve之后状态改变,但不直接执行回调函数,先继续走,打印2,
一轮之后回去调用resolve部分,输出3
Q:promise链式调用,后面状态是如何改变的?
A:通过return和throw error
Q:then里面,如果原来是rejected,加一个什么处理可以变成resolved?
A:在rejected调用函数中return 1即可
Q:通过promise.rejected构造一个返回rejected状态的方法?
A:throw error
参考资料:https://blog.csdn.net/weixin_43715100/article/details/107014776
1.9 ES6新特性
// 1
let const
// 块级作用域:var没有块的概念,let const有,即跨块不能访问别处变量
// 暂时性死区
console.log(a) // undefined
var a
console.log(b) // ReferenceError: b is not defined
let b
// 2
str.includes()
// 3 重复
str.repeat()
'x'.repeat(3) // 'xxx'
// 4
str.replaceAll('a', 'b')
'aabbcc'.replaceAll('a', 'b') // 'bbbbcc'
// 5 去除小数
Math.trunc(4.12) // 4
// 6 立方根
Math.cbrt(2) // 1.2....
// 7 数组扩展spread
...[1, 2, 3] // 1, 2, 3
...'abc' // ['a', 'b', 'c']
// 8 复制数组
a2 = a1 // a2改则a1改,本质是直接把指针给了a2
a2 = a1.concat() // 如果真的想单纯复制就这样
// 9 for...of
for (let i of [1, 2, 3].values()) // 1,2,3
// 10 flat 拉平
[1, 2, [3, [4, 5]]].flat() // [1, 2, 3, [4, 5]]
// 11 arr.map
[1, 2, 3].map(x => x * x); // 1, 4, 9
1.10 forEach & for..in & for..of
objArr.forEach(function (value) {
console.log(value);
});
// foreach 方法没办法使用 break 语句跳出循环,或者使用return从函数体内返回
for(var index in objArr){
console.log(objArr[index])
}
/*
以上代码会出现的问题:
1.index 值 会是字符串(String)类型
2.循环不仅会遍历数组元素,还会遍历任意其他自定义添加的属性,如,objArr上面包含自定义属性,objArr.name,那这次循环中也会出现此name属性
3.某些情况下,上述代码会以随机顺序循环数组
*/
for(let value of objArr){
console.log(value)
}
/*
1.可以避免所有 for-in 循环的陷阱
2.不同于 forEach(),可以使用 break, continue 和 return
3.for-of 循环不仅仅支持数组的遍历。同样适用于很多类似数组的对象
4.它也支持字符串的遍历
5.for-of 并不适用于处理原有的原生对象
*/
1.11 原型 & 原型链
function Person() {
var person = new Person()
console.log(person.__proto__ === Person.prototype)//true
console.log(Person.prototype.constructor===Person)//true
}
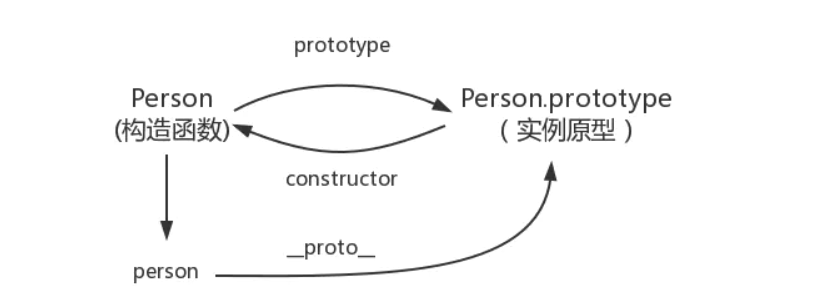
1.12 继承
原型链继承
// 将父类作为子类的原型
function Cat(){ }
Cat.prototype = new Animal();
Cat.prototype.name = 'cat';
// 优点:父类新增原型方法/原型属性,子类都能访问到,简单,易于实现
// 缺点:无法实现多继承,创建子类实例时,无法向父类构造函数传参
构造继承
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
}
// 优点:可以实现多继承(call多个父类对象),创建子类实例时,可以向父类传递参数
// 缺点:无法实现函数复用,每个子类都有父类实例函数的副本,影响性能
1.13 多态
静态
编译时多态,在编译时确定对象使用的形式
动态
运行时多态,在运行时才能确定
1.14 基本数据类型
null, undefined, boolean, number, string, Object
typeof 42 // "number"
typeof "s" // "string"
typeof true // "boolean"
typeof {a:1} // "object"
typeof null // "object" ,因为前面是000,obj的判定正好就是前面三位是000的是obj
typeof somethingUndefined // "undefined"
1.15 JS模块化
let basicNum = 0;
const add = (a, b) => {
return a + b
}
export { basicNum, add };
import { basicNum, add } from './math';
function test(e) {
e = add(99, basicNum)
}
1.16 垃圾回收
标记清除
这是javascript中最常用的垃圾回收方式。当变量进入执行环境是,就标记这个变量为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到他们。当变量离开环境时,则将其标记为“离开环境”。
垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记。然后,它会去掉环境中的变量以及被环境中的变量引用的标记。而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后。垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
引用计数
另一种不太常见的垃圾回收策略是引用计数。引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型赋值给该变量时,则这个值的引用次数就是1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数就减1。当这个引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其所占的内存空间给收回来。这样,垃圾收集器下次再运行时,它就会释放那些引用次数为0的值所占的内存。
1.17 Vue+Vuex+ElementUI怎么实现页面
本质是实现一个页面时,三个JS库分别起到什么作用?
1.18 call/apply/bind
相同
第一个参数都是对this对重定向,将函数对this指向传入的第一个参数
不同
- bind返回值为一个函数,需要再次调用
- 传入参数时apply将所有参数打包进数组后统一传入
2 HTML/CSS
2.1 click事件发生具体顺序
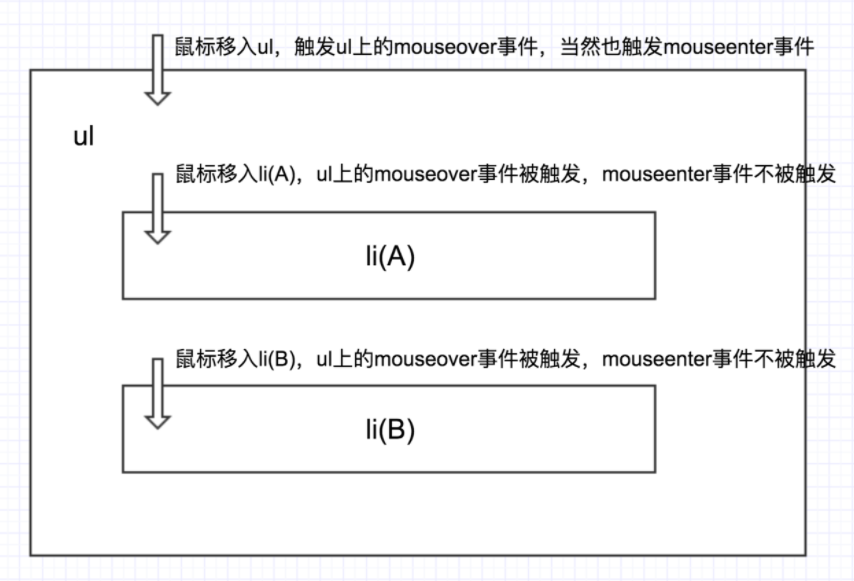
onmouseenter -> onmousedown -> onfocus -> onmouseup -> onclick2.2 onmouseover/onmouseenter
2.3 CSS盒子模型
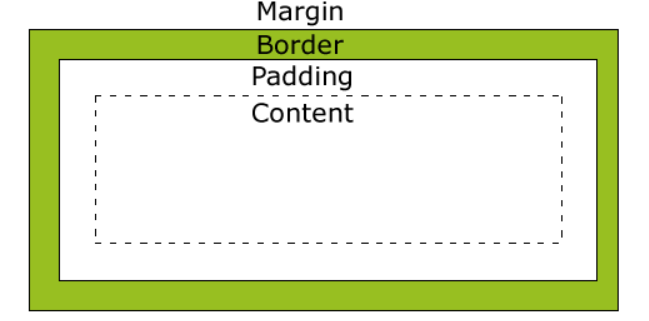
标准模式:总宽度=width + margin(左右) + padding(左右) + border(左右)
怪异模式:总宽度= width + margin(左右)即width已经包含了padding和border值
2.4 absolute/relative
- 文档流不同
relative 不脱离文档流,absolute 脱离文档流。
- 分级不同
relative 参考自身静态位置通过 top, bottom, left, right定位,并且可以通过z-index进行层次分级。
absolute通过 top,bottom,left,right 定位。选取其最近的父级定位元素,当父级 position 为 static 时,absolute元素将以body坐标原点进行定位,可以通过z-index进行层次分级。
- 定位不同
absolute是绝对定位,绝对定位就是相对于父元素的定位,不受父元素内其他子元素的影响;而relative是相对定位,相对定位是相对于同级元素的定位,也就是上一个同级元素。
2.5 纯CSS画三角形
#triangle-up {
width: 0;
height: 0;
border-left: 50px solid transparent;
border-right: 50px solid transparent;
border-bottom: 100px solid red;
}
#triangle-left {
width: 0;
height: 0;
border-top: 50px solid transparent;
border-right: 100px solid red;
border-bottom: 50px solid transparent;
}
#triangle-topleft {
width: 0;
height: 0;
border-top: 100px solid red;
border-right: 100px solid transparent;
}
2.6 px/em/rem
px
px是固定的像素,一旦设置了就无法因为适应页面大小而改变。
em
em相对于父元素
rem
rem相对于根元素
2.7 inline元素的无效属性
- inline元素设置width,height属性无效
- inline元素的padding和margin可以设置,但是水平方向的padding-right,padding-left,margin-right,margin-left都产生了效果,而垂直方向的padding-top,padding-bottom,margin-bottom,margin-top是没有效果的
2.8 隐藏元素方法
display: none
如果给一个元素设置了display: none,那么该元素以及它的所有后代元素都会隐藏,占据的空间消失。
visibility: hidden
给元素设置visibility: hidden也可以隐藏这个元素,但是隐藏元素仍需占用与未隐藏时一样的空间,也就是说虽然元素不可见了,但是仍然会影响页面布局。
opacity: 0
透明度完全透明,但是同样占位
3 HTTP/计网
3.1 网址栏输入地址之后具体会发生什么?
DNS域名解析 —> 发起TCP的三次握手 —> 建立TCP连接后发起HTTP请求 —> 服务器响应HTTP请求,浏览器得到HTML代码 —> 浏览器解析HTML代码,并请求HTML代码中的资源(如JS、CSS、图片等) —> 浏览器对页面进行渲染呈现给用户
DNS解析过程参见3.14 TCP连接/三次握手四次挥手参见3.2 HTTP状态码参见3.3 HTTP渲染步骤参见1.5
3.2 三次握手,四次挥手
3.2.1 三次握手
过程
- 客户端发送到服务器。客户端发送 SYN 报文给服务器,并且指明客户端初始化序列号为 ISN(c),即以 SYN=1, seq=x 的形式发送过去。此时客户端处于 SYN_SEND 状态。
- 服务器发送给客户端。服务器收到客户端的 SYN 和 ISN(c),也发送一个 SYN 回去,同时设置 ACK = ISN(c) + 1 以及指明服务器初始化序列号为 ISN(s),即以 SYN=1, ACK=x+1, seq=y 的形式发送给客户端。
- 客户端发送到服务器。客户端收到服务器发送的消息后,设置 ACK = ISN(s) + 1,将自身的 ISN(c) + 1,即以 ACK=y+1, seq=x+1 的形式发送给服务器。此时客户端处于 ESTABLISHED 阶段,服务器收到报文,也处于 ESTABLISHED 阶段,双方建立了连接。
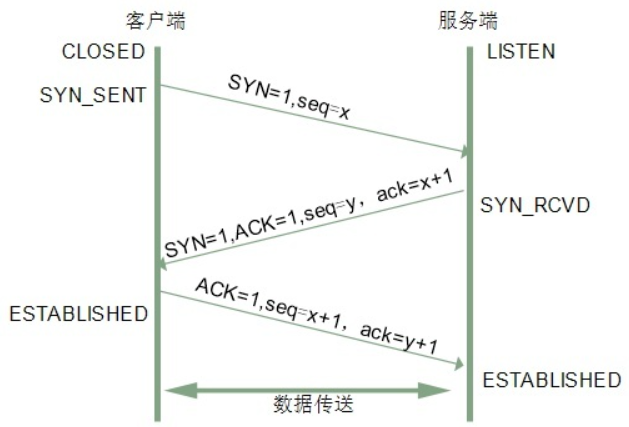
目的
- 客户端发送数据给服务器,服务器确认自己可以接受客户端的请求。
- 服务器发送数据给客户端,客户端确认自己可以发送数据给服务器,也可以接受到服务器的请求。
- 客户端发送数据给服务器,服务器确认自己可以发送数据给客户端。
如果采用两次握手,客户端发送数据给服务器,服务器确认后就当连接开始:
- 客户端发送一次请求给服务器……指定时间后没响应再发了一个
- 服务器先接收到后一个建立连接的请求,然后前一个建立连接的请求,因为网络延迟等问题,在第二个之后达到了
- 服务器认为第二个请求是最新发的,于是向客户端发送确认报文段,同意建立连接,于是连接建立了(两次握手)
- 这时候客户端还在等待最新的请求连接(第二次请求),自动忽略服务器发送的关于第一个请求连接的响应,也不发送数据
- 服务器一直等待客户端发送数据,服务器资源被占用
客户端 -> 1 -> 服务器 客户端 -> 2 -> 服务器 服务器 get 1 服务器 get 2 服务器 reply 1 客户端 wait 2 gg
3.2.2 四次挥手
- 客户端发送给服务器。客户端以 FIN=1, seq=u 的形式发送给服务器,表示需要关闭客户端和服务器的数据传输。此时客户端处于 FIN_WAIT 状态。
- 服务器发送给客户端。服务器收到信息,先返回 ACK 给客户端,即以 ACK=1, seq=v, ack=u+1 的形式返回给客户端,表示收到客户端报文了。此时服务器处于 CLOST_WAIT 状态。
- 服务器发送给客户端。服务器等待一会,看客户端还有没有数据没发过来,等处理完这些数据之后,也想断开连接了,于是发送 FIN 给客户端,即以 FIN=1, ACK=1, seq=w, ack=u+1 的形式发送给客户端。此时服务器处于 LAST_ACK 状态。
- 客户端发送给服务器。客户端收到 FIN 之后,返回 ACK 报文作为应答,即以 ACK=1, seq=w+1 的形式发送给服务器。此时客户端处于 TIME_WAIT 状态。
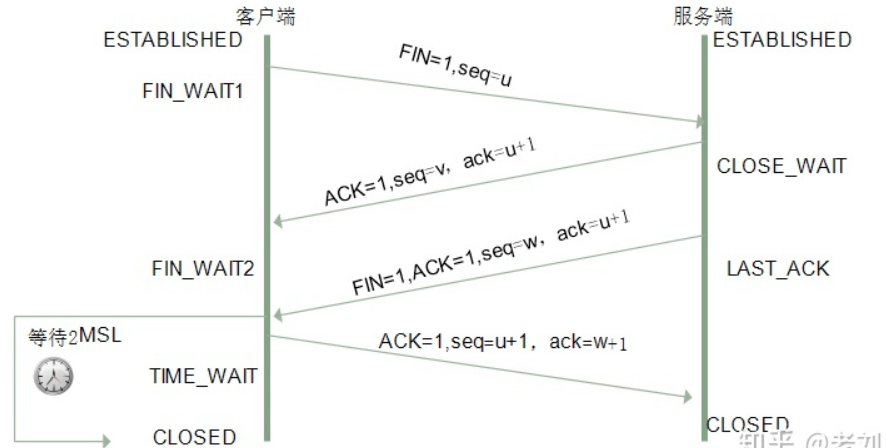
其中,ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
3.3 状态码
3.3.1 Status Code
1xx 指示信息-表示请求已接收;
- 101 Switching Protocols:在 HTTP升级为WebSocket的时候,如果服务器同意变更,就会发送状态码为101。
2xx 请求成功-表示请求成功接收并解析;
- 200 OK:请求成功状态码,响应体中含有数据。
- 204 No Content:含义同200,但是响应报文不含实体的主体部分。
- 206 Partial Content:表示部分内容请求成功。使用场景为HTTP分块下载和断点续传,当然也会带上相应的响应头字段Content-Range
3xx 重定向-表示要完成请求需要更进一步操作;
- 301 Move Permanently:永久重定向。HTTP升级 HTTPS,之前站点再也不用,那就是301。
- 302 Found:临时重定向。当前站点暂时不可用,那就是302,后续可能换回来。
- 304 Not Modified:当命中协商缓存时会返回这个状态码。
4xx 客户端错误-请求有语法错误或者请求无法实现;
- 400 Bad Request:请求无效。通常为前后端数据格式不一致或者其他原因。
- 403 Forbidden:服务器已经得到请求,但是拒绝执行,比如没权限、法律禁止等。
- 404 Not Found:资源未找到,服务器不存在对应的资源。
5xx 服务端错误-服务端未能实现合法的请求。
- 500 Internal Server Error: 服务器报错,有些时候可以在Response看到后端PHP等技术的报错信息等。
- 502 Bad Gateway:服务器正常,但是访问出错。
- 503 Service Unavailable:服务器繁忙或者停机维护,暂时无法处理请求。
3.3.2 ReadyState
0:未初始化,还没有调用send()方法
1:载入,已调用send()方法,正在发送请求
2:载入完成,send()方法执行完成,已经接收到全部响应内容
3:交互,正在解析响应内容
4:完成,响应内容解析完成,可以在客户端进行调用3.4 跨域
3.4.1 同源策略
出于浏览器的同源策略限制。同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。3.4.2 跨域
所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。而当三者有一个不一样时,两个资源就不在一个域中。3.4.3 如何解决
- CORS跨域资源分享
- 通过配置代理服务器
- 通过使用jsonp
- WebSocket
CORS具体策略参见3.5
3.5 简单请求/预检请求
3.5.1 简单请求
请求方法是以下三种方法之一:
- HEAD
- GET
- POST
HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
Content-Type内容具体参见3.6
3.5.2 预检请求
其他就是复杂请求
比如我项目中用的axios就是复杂请求
3.6 content-type常用值
multipart/form-data
需要在表单中进行文件上传时,就需要使用该格式。常见的媒体格式是上传文件之时使用的 这个常用于文件上传 我用得最多就是图片上传的时候。
application/x-www-form-urlencoded
数据被编码为名称/值对。这是标准的编码格式 这个其实是form表单默认的post请求时发送的数据格式。也就是form表单post请求,你不设置entype属性,它自动会使用这个。
application/json
消息主体是序列化后的 JSON 字符串 这里要注意的是 我在使用webapi,前台使用$.ajax的时候 假如我要传递的数据为 var obj = {“name”:”zhangsan”,”age”:20}.这个时候我使用ajax传递 后台无论如何都接收不到数据直到后来我才发现这里声明了发送到后台的是josn字符串 所以data属性应该为JSON.strfy(obj); 具体字符串方法名忘了 但是跟这个长得很像
text/plain
正常文本
3.7 jwt/access token/refresh token
jwt
Json web token (JWT),是一种基于JSON的开放标准
1、可以避免用户信息泄露。
2、payload中可以携带一些必要的非敏感信息,比如用户名、用户邮箱,供前端使用
3、服务端不用存放jwt的状态信息,减轻服务端压力,在分布式场景中更方便,不需要状态共享
4、通过时间戳的方式避免重放攻击,token的时效性尽量短
access token
Access Token应该维持在较短有效期,过长不安全,过短也会影响用户体验,因为频繁去刷新带来没有必要的网络请求。可以参考我们常常在某些网站停止操作一段时间之后就会掉线,这个时间是Refresh Token的有效期,Access Token不应长过这个时间。
refresh token
Refresh Token的有效期就是允许用户在多久时间内不用重新登录的时间,可以很长,视业务而定。我们在使用某些APP的时候,即使一个月没有开过也是登录状态的,这就是Refresh Token决定的。授权服务在接到Refresh Token的时候还要进一步做客户端的验证,尽可能排除盗用的情况。
3.8 TCP四种定时器
重传计时器 Retransmission Timer
为了控制丢失的报文段或丢弃的报文段,也就是对报文段确认的等待时间。当TCP发送报文段时,就创建这个特定报文段的重传计时器,可能发生两种情况:若在计时器超时之前收到对报文段的确认,则撤销计时器;若在收到对特定报文段的确认之前计时器超时,则重传该报文,并把计时器复位;
坚持计时器 Persistent Timer
当发送端收到零窗口的确认时,就启动坚持计时器,当坚持计时器截止期到时,发送端TCP就发送一个特殊的报文段,叫探测报文段,这个报文段只有一个字节的数据。探测报文段有序号,但序号永远不需要确认,甚至在计算对其他部分数据的确认时这个序号也被忽略。探测报文段提醒接收端TCP,确认已丢失,必须重传。
保活计时器 Keeplive Timer
每当服务器收到客户的信息,就将keeplive timer复位,超时通常设置2小时,若服务器超过2小时还没有收到来自客户的信息,就发送探测报文段,若发送了10个探测报文段(没75秒发送一个)还没收到响应,则终止连接。
时间等待计时器 Time_Wait Timer
在连接终止期使用,当TCP关闭连接时,并不认为这个连接就真正关闭了,在时间等待期间,连接还处于一种中间过渡状态。这样就可以时重复的FIN报文段在到达终点后被丢弃,这个计时器的值通常设置为一格报文段寿命期望值的两倍。
3.9 TCP/UDP
TCP
Transmission Control Protocol
UDP
User Datagram Protocol
确认机制、重传机制、滑动窗口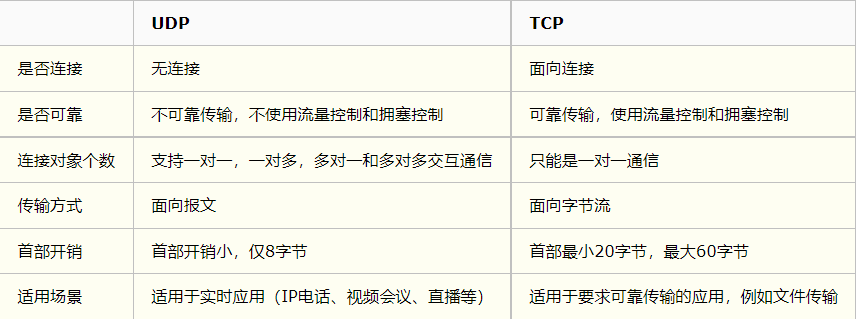
3.10 文件断点续传
断点续传指的是在下载或上传时,将下载或上传任务人为的划分为几个部分
每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载。用户可以节省时间,提高速度
一般实现方式有两种:
- 服务器端返回,告知从哪开始
- 浏览器端自行处理
上传过程中将文件在服务器写为临时文件,等全部写完了(文件上传完),将此临时文件重命名为正式文件即可
如果中途上传中断过,下次上传的时候根据当前临时文件大小,作为在客户端读取文件的偏移量,从此位置继续读取文件数据块,上传到服务器从此偏移量继续写入文件即可
3.11 HTTP迭代
HTTP 1.0
无状态,无连接
短连接:每次发送请求都要重新建立tcp请求,即三次握手,非常浪费性能
无host头域,也就是http请求头里的host,
不允许断点续传,而且不能只传输对象的一部分,要求传输整个对象
HTTP 1.1
长连接,流水线,使用connection:keep-alive使用长连接
请求管道化
增加缓存处理(新的字段如cache-control)
增加Host字段,支持断点传输等
由于长连接会给服务器造成压力
HTTP 2.0
二进制分帧
头部压缩,双方各自维护一个header的索引表,使得不需要直接发送值,通过发送key缩减头部大小
多路复用(或连接共享),使用多个stream,每个stream又分帧传输,使得一个tcp连接能够处理多个http请求
服务器推送(Sever push)
HTTP 3.0
基于google的QUIC协议,而quic协议是使用udp实现的
减少了tcp三次握手时间,以及tls握手时间
解决了http 2.0中前一个stream丢包导致后一个stream被阻塞的问题
优化了重传策略,重传包和原包的编号不同,降低后续重传计算的消耗
连接迁移,不再用tcp四元组确定一个连接,而是用一个64位随机数来确定这个连接
更合适的流量控制
3.12 websocket/HTTPS
websocket
Websocket 通过HTTP/1.1 协议的101状态码进行握手。
而比较新的技术去做轮询的效果是Comet。这种技术虽然可以双向通信,但依然需要反复发出请求。而且在Comet中,普遍采用的长链接,也会消耗服务器资源。在这种情况下,HTML5定义了WebSocket协议,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。
HTTPS
Hyper Text Transfer Protocol over SecureSocket Layer
是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性 。HTTPS 在HTTP 的基础下加入SSL,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。 HTTPS 存在不同于 HTTP 的默认端口及一个加密/身份验证层(在 HTTP与 TCP 之间)。
HTTPS建立过程:
- 客户端发起连接,同时传入自己支持的加密算法
- 服务端发送证书,和自己的算法(私钥)进行比对,如果不符合,直接断开连接;如果符合,将SSL证书发送给客户端
- 客户端验证服务端发来的证书,当证书受信之后,浏览器会随机生成一串密码,并使用证书中的公钥加密。之后就是使用约定好的哈希算法握手消息,并生成随机数对消息进行加密,再将生成的信息发送给服务器
- 服务端接收随机数加密的信息,并解密得到随机数,验证握手信息是否被篡改,然后服务器会使用密码加密新的握手信息,发送给客户端
-
3.13 HTTP缓存
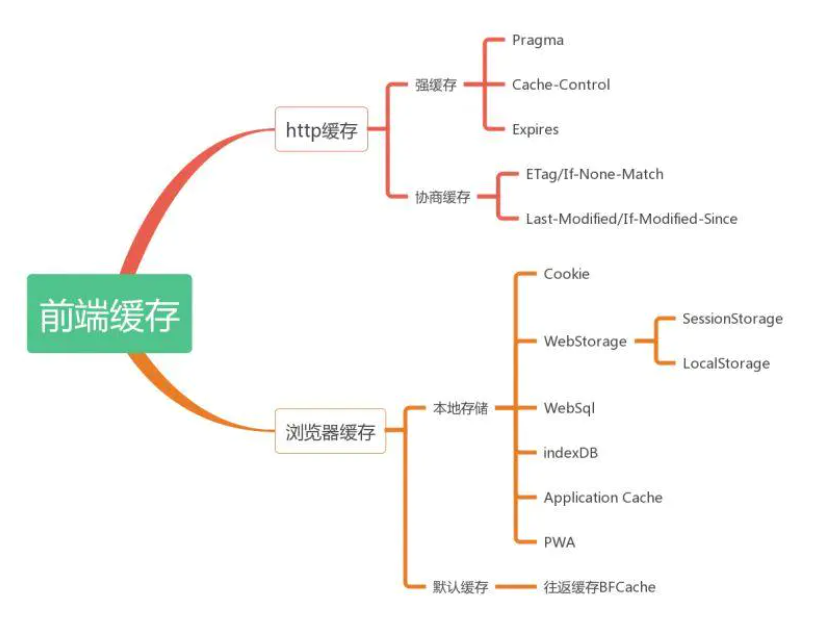
http缓存指的是: 当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。
常见的http缓存只能缓存get请求响应的资源,对于其他类型的响应则无能为力,所以后续说的请求缓存都是指GET请求。
http缓存都是从第二次请求开始的。第一次请求资源时,服务器返回资源,并在respone header头中回传资源的缓存参数;第二次请求时,浏览器判断这些请求参数,命中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否命中协商缓存,命中则返回304,否则服务器会返回新的资源。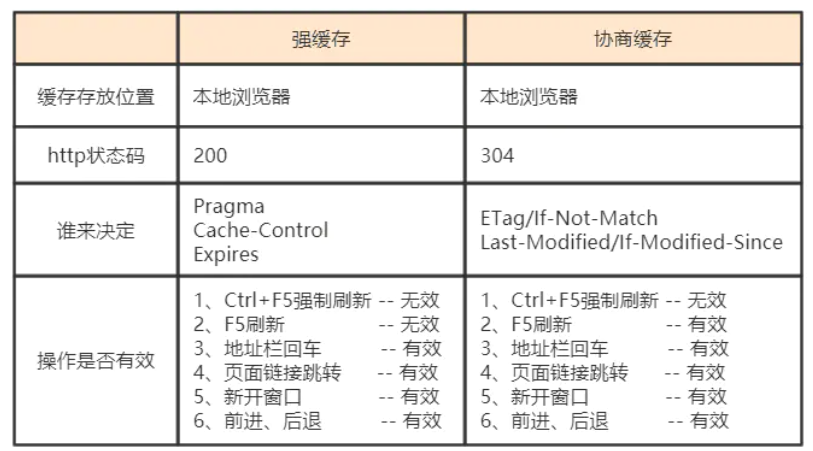
如何清除http缓存<% response.setHeader("Pragma", "no-cache"); response.setHeader("Cache-Control", "no-cache"); response.setDateHeader("Expires", 0); %>3.14 DNS域名解析
浏览器先检查自身缓存中有没有被解析过的这个域名对应的ip地址,如果有,解析结束。同时域名被缓存的时间也可通过TTL属性来设置。
如果浏览器缓存中没命中,浏览器会检查操作系统缓存中有没有对应的已解析过的结果。
而操作系统也有一个域名解析的过程。在windows中可通过c盘里一个叫hosts的文件来设置,如果你在这里指定了一个域名对应的ip地址,那浏览器会首先使用这个ip地址。
如果至此还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。
- 如果LDNS仍然没有命中,就直接跳到Root Server域名服务器请求解析
- 根域名服务器返回给LDNS一个所查询域的主域名服务器(gTLD Server,国际顶尖域名服务器,如.com .cn .org等)地址
- 此时LDNS再发送请求给上一步返回的gTLD
- 接受请求的gTLD查找并返回这个域名对应的Name Server的地址,这个Name Server就是网站注册的域名服务器
- Name Server根据映射关系表找到目标ip,返回给LDNS
- LDNS缓存这个域名和对应的ip
LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
3.15 cookie/session/localStorage/sessionStorage
3.16 常见协议
应用层
DNS (Domain Name System)
- FTP (File Transfer Protocol)
- HTTP

传输层
- TCP
- UDP
TCP/UDP相关知识参见3.9
网络层
- IP (Internet Protocol)
网际协议,一般指在现网使用最多的IPv4,最新的IPv6正在部署中,已在一部分网络里使用。IP协议负责把数据包从发送方路由到接收方。
3.17 TCP粘包现象
概念
发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
原因
- 发送方原因
TCP默认会使用Nagle算法。而Nagle算法主要做两件事:1)只有上一个分组得到确认,才会发送下一个分组;2)收集多个小分组,在一个确认到来时一起发送。
- 接收方原因
TCP接收到分组时,并不会立刻送至应用层处理,或者说,应用层并不一定会立即处理;实际上,TCP将收到的分组保存至接收缓存里,然后应用程序主动从缓存里读收到的分组。这样一来,如果TCP接收分组的速度大于应用程序读分组的速度,多个包就会被存至缓存,应用程序读时,就会读到多个首尾相接粘到一起的包。
解决
- 关闭Nagle算法
- 解决方法就是循环处理:应用程序在处理从缓存读来的分组时,读完一条数据时,就应该循环读下一条数据,直到所有的数据都被处理;但是如何判断每条数据的长度呢?
A类
地址范围:1.0.0.1-126.255.255.254
默认子网掩码:255.0.0.0
A类第1位必须是0。
B类
地址范围:128.1.0.1-191.255.255.254
默认子网掩码:255.255.0.0
前两位固定为10。
C类
地址范围:192.0.1.1-223.255.255.254
子网掩码:255.255.255.0
前3位固定为110。
D类
地址范围:224.0.0.1-239.255.255.254
E类
是保留地址。该类IP地址的最前面为“1111”,所以地址的网络号取值于240~255之间。
每一个字节都为0的地址(0.0.0.0)对应当前主机。 IP地址中的每一个字节都为1的IP地址(255.255.255.255)是当前子网的广播地址。 子网掩码作用:子网掩码的作用是通过划分IP地址减少网络流量、提高网络性能、扩大地理范围。
3.19 窗口滑动协议
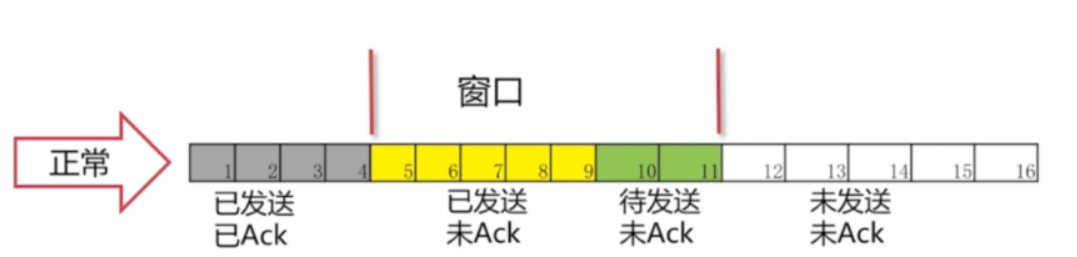
慢启动
CWND一开始比较小,后面指数变大。慢启动算法的理由是,TCP模块刚开始发送数据时并不知道网络的实际情况,需要用一种试探的方式平滑地增加CWND的大小。
拥塞避免算法
拥塞避免算法是的CWND按照线性增长方式增加,从而减缓了其扩大。
快速重传
当接收端收到报文段的顺序不符合序号,即在两个报文段之间的报文段没收到,就会立即发送三条重复确认报文,接收方收到三条重复的确认报文段后,就立即重传确认报文段后面的报文
快恢复
快恢复的执行就是将ssthresh设置为减半的大小。也有的快恢复算法再开始时会将CWND值再增大一些,即等于ssthresh+3×MSS。理由是:既然发送方收到三个重复的确认,就表明有三个分组已经离开了网络。这三个分组不再消耗网络资源而是停留在接收方的缓存中。可见现在网络中并不是堆积了分组而是减少了三个分组。因此可以适当把拥塞窗口增大些。
3.20 计网模型7/5/4
OSI参考模型
(物联网淑慧试用)
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
TCP/IP四层模型
- 应用层
- 传输层
- 网际层
- 网络接口层
TCP/IP五层模型
- 应用层:支持各种网络应用
- 传输层:进程-进程的数据传输
- 网络层:源主机到目的主机的数据分组路由与转发
- 数据链路层:把网络层传下来的数据报组装成帧
- 物理层
3.21 ARP协议
概念
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。
工作过程主机A的IP地址为192.168.1.1,MAC地址为0A-11-22-33-44-01; 主机B的IP地址为192.168.1.2,MAC地址为0A-11-22-33-44-02;
- 根据主机A上的路由表内容,IP确定用于访问主机B的转发IP地址是192.168.1.2。然后A主机在自己的本地ARP缓存中检查主机B的匹配MAC地址。
- 如果主机A在ARP缓存中没有找到映射,它将询问192.168.1.2的硬件地址,从而将ARP请求帧广播到本地网络上的所有主机。源主机A的IP地址和MAC地址都包括在ARP请求中。本地网络上的每台主机都接收到ARP请求并且检查是否与自己的IP地址匹配。如果主机发现请求的IP地址与自己的IP地址不匹配,它将丢弃ARP请求。
- 主机B确定ARP请求中的IP地址与自己的IP地址匹配,则将主机A的IP地址和MAC地址映射添加到本地ARP缓存中。
- 主机B将包含其MAC地址的ARP回复消息直接发送回主机A。
- 当主机A收到从主机B发来的ARP回复消息时,会用主机B的IP和MAC地址映射更新ARP缓存。本机缓存是有生存期的,生存期结束后,将再次重复上面的过程。主机B的MAC地址一旦确定,主机A就能向主机B发送IP通信了。
4 数据库
《数据库》 — 某不知名朋友lucario 整理了一下发现,好像前端不考这个
4.0 必问必答
- 事务四大特性、事务隔离级别
- 索引特点、B+树、索引最左匹配、索引失效的情况
- 存储引擎有哪些?重点:innodb
- mysql中有哪些锁
- bin log/redo log/undo log
- mysql架构(以一条sql语句执行经过哪些过程为例)
- 优化、分库分表
4.1 事务四大特性
主要有四个特性,ACID,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
- 一致性是指一个事务执行之前和执行之后都必须处于一致性状态。比如a与b账户共有1000块,两人之间转账之后无论成功还是失败,它们的账户总和还是1000。
- 隔离性。跟隔离级别相关,如read committed,一个事务只能读到已经提交的修改。
- 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
4.2 连接
内连接:每个表共有的列的值进行匹配
左连接:返回左表所有行,如果在右表中没有匹配,则为空
右连接:返回右表所有行,如果在左表中没有匹配,则为空
全连接:返回两个表所有行4.3 隔离级别
脏读:在一个事务中读取了另一个未提交的事务中的数据。 不可重复读:对于某行记录,一个事务多次查询却返回了不同的数据值,这是由于在查询间隔,另一个事务修改了数据并提交了。 幻读:当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行,就像产生幻觉一样,这就是发生了幻读。
MySQL
- Serializable (串行化):通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。
- Repeatable read (可重复读)默认:它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行,解决了不可重复读的问题。
- Read committed (读已提交):一个事务只能看见已经提交事务所做的改变。可避免脏读的发生。
- Read uncommitted (读未提交):所有事务都可以看到其他未提交事务的执行结果。
Oracle
- Serializable (串行化):通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。
- Read committed (读已提交)默认:一个事务只能看见已经提交事务所做的改变。可避免脏读的发生。
4.4 索引
《索引》
5 Vue
5.1 Vue生命周期
生命周期(Vue2)
beforeCreate、created、
beforeMount、mounted、
beforeUpdate、updated、
actived、deactived、
beforeDestroy、destroyed、
errorCaptured
生命周期(Vue3)
beforeCreate、created、
beforeMount、mounted、
beforeUpdate、updated、
actived、deactived、
beforeUnmount、unmount、
errorCaptured
renderTracked
renderTriggered
renderTriggered深挖具体trigger什么参见5.2
父子组件先后顺序
- 加载渲染过程
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
- 更新过程
父beforeUpdate->子beforeUpdate->子updated->父updated
- 销毁过程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
5.2 renderTriggered
// 精确跟踪发生变化的值,进行针对性调试。
onRenderTriggered((event) => {
console.log("状态触发组件--------------->");
console.log(event);
});
5.3 Vue双向绑定原理
Vue是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发响应的监听回调。
- 需要observer的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter,这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
- compile解析模板令,将模板中的变量替换成数据.然后初始化渲染页面视图,并将每个令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
- Watcher订阅名是 observer和 Compile之间通信的桥梁,主要做的事情是:
- 在自身实例化时往属性订倒器(dep)里面添加自己
- 自身必须有一个 update()方法
- 待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中定的回调,则功成身退
- MVVM作为数据绑定的入口,合 observer、 Compile和 Watcher三者,通过 Observer来监听自己的model数据変化,通过 Compile来解析编译模板指令,最终利用 Watcher搭起 Observer和 Compile之间的通信标梁,达到数据变化->视图更新新:视图交互变化(Input)->数据mode变更的双向绑定效果。
v-model原理其实就是给input事件绑定oninput事件,就会立刻调用底层对象对应的setter方法,改变data里的属性的值,从而实现双向数据绑定 这玩意虽然恶心,但是必考!
5.4 Vue/React
核心
Vue以数据响应式为核心的UI框架,它的核心思想就是把所有的数据放在一个对象里面,然后当你操作对象时,对象就会改变数据,然后监听这个改变去改变UI。
React用一个函数来表示一个组件,当你把数据放进去时,它就会把数据渲染到组件里面,同时,在放数据的时候,要做到 “ 不可变 ”,也就是说,更新数据时,不是改变之前的数据,而是新生成一个和之前不一样的数据并放入函数,函数会得到一个新的UI,最后更新DOM树。
区别
1、监听数据变化的实现原理不同
Vue通过 getter/setter以及一些函数的劫持,能精确知道数据变化。
React默认是通过比较引用的方式(diff)进行的,如果不优化可能导致大量不必要的VDOM的重新渲染。为什么React不精确监听数据变化呢?这是因为Vue和React设计理念上的区别,Vue使用的是可变数据,而React更强调数据的不可变
2、模板渲染方式的不同
在表层上,模板的语法不同,React是通过JSX渲染模板。而Vue是通过一种拓展的HTML语法进行渲染,但其实这只是表面现象,毕竟React并不必须依赖JSX。
3、渲染过程不同
Vue可以更快地计算出Virtual DOM的差异,这是由于它在渲染过程中,会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。
React在应用的状态被改变时,全部子组件都会重新渲染。通过shouldComponentUpdate这个生命周期方法可以进行控制,但Vue将此视为默认的优化。
4、框架本质不同
Vue本质是MVVM框架,由MVC发展而来;
React是前端组件化框架,由后端组件化发展而来。
相同
- 使用 Virtual DOM(虚拟DOM)
- 提供了响应式 (Reactive) 和组件化 (Composable) 的视图组件。
- 将注意力集中保持在核心库,而将其他功能如路由和全局状态管理交给相关的库。
5.5 nextTick
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。5.6 Vue3和Vue2区别
组件语法部分
组合式API(Composition API):Vue3.0 使用组合式api,使用的地方在setup回调函数中,这个回调函数是创建组件之前执行,由于在执行 setup 时尚未创建组件实例,因此在 setup 选项中没有 this。
选项式API(Options API):Vue2.0中使用选项式api,data,methods等等
观察者
Vue2.0中不管数据多大,都会在一开始就为其创建观察者;当数据很大时,这可能会在页面载入时造成明显的性能压力。
Vue3.0只会对“被用于渲染初始可见部分的数据”创建观察者,而且Vue3.0的观察者更高效。
TypeScript
Vue3更好适配TypeScriptsetup() { // reactive state const count = ref(0) // computed state const plusOne = computed(() => count.value + 1) // method const increment = () => { count.value++ } // watch watch(() => count.value * 2, val => { console.log(`count * 2 is ${val}`) }) // lifecycle onMounted(() => { console.log(`mounted`) }) onUnmounted(() => { window.removeEventListener('mousemove', update) }) // expose bindings on render context return { count, plusOne, increment } }5.7 Vuex中mutation/action
异步操作都放在action,同步操作都放在mutation尤雨溪: 区分 actions 和 mutations 并不是为了解决竞态问题,而是为了能用 devtools 追踪状态变化。 事实上在 vuex 里面 actions 只是一个架构性的概念,并不是必须的,说到底只是一个函数,你在里面想干嘛都可以,只要最后触发 mutations 就行。异步竞态怎么处理那是用户自己的事情。vuex 真正限制你的只有 mutations 必须是同步的这一点(在 redux 里面就好像 reducer 必须同步返回下一个状态一样)。 同步的意义在于这样每一个 mutations 执行完成后都可以对应到一个新的状态(和 reducer 一样),这样 devtools 就可以打个 snapshot 存下来,然后就可以随便 time-travel 了。 如果你开着 devtool 调用一个异步的 actions,你可以清楚地看到它所调用的 mutations 是何时被记录下来的,并且可以立刻查看它们对应的状态。其实我有个点子一直没时间做,那就是把记录下来的 mutations 做成类似 rx-marble 那样的时间线图,对于理解应用的异步状态变化很有帮助。
5.8 双向绑定原理/单向数据流
不冲突的,Vue本质是单向数据流,双向绑定只是一个语法糖,本质是通过Object.defineProperty()的get和set方法来实现响应式更新
6 前端工程化
6.1 webpack
概念
webpack是一个打包模块化js的工具,可以通过loader转换文件,通过plugin扩展功能。
过程
- 解析webpack配置参数,合并从shell传入和webpack.config.js文件里配置的参数,生成最后的配置结果。
- 注册所有配置的插件,好让插件监听webpack构建生命周期的事件节点,以做出对应的反应。
- 从配置的entry入口文件开始解析文件构建AST语法树,找出每个文件所依赖的文件,递归下去。
- 在解析文件递归的过程中根据文件类型和loader配置找出合适的loader用来对文件进行转换。
- 递归完后得到每个文件的最终结果,根据entry配置生成代码块chunk。
-
6.2 前端优化方案
减少http请求数
- 将外部脚本置底
- 异步执行 inline脚本
- Lazy Load Javascript
-
6.3 一段代码不停请求,响应顺序不同,如何解决?
识别哪次是最新结果,每次请求发出去定义一个计时器,在回调函数里需要知道这个计时器,进行比较
6.4 扫码登录
web端初次渲染时会向服务器请求一个id 然后二维码就是一个请求接口 参数有这个id 。扫码就是发起请求 携带id和客户端用户信息。服务器收到客户端请求后在内存?redis?里面保存状态 web端会长轮询请求该id对应的用户状态 一旦改变 web端获取用户信息 进入下一个页面
6.5 SYN/XSS/CSRF攻击
6.5.1 SYN
利用三次握手的缺陷,发送SYN得到响应之后,不再确认,导致一直处于挂起状态,占用系统资源,泛洪攻击
6.5.2 XSS
xss攻击主要是针对表单的input文本框发起的,比如输入的是一个html代码,就会让所有用户都运行这部分html代码,同样的,xss还可以利用这一点盗取所有cookie
// 防范: npm install xss -- save import xss from 'xss'6.5.3 CSRF
概念
攻击者盗用了你的身份,以你的名义发送恶意请求。 登录受信任网站A,并在本地生成Cookie。
- 在不登出A的情况下,访问危险网站B。
防范
服务端的CSRF方式方法很多样,但总的思想都是一致的,就是在客户端页面增加伪随机数。
- Cookie Hashing(在表单里增加Hash值,以认证这确实是用户发送的请求)
- 验证码
- One-Time Tokens
7 手撕代码
8 其他
8.1 红黑树
规则
- 每个结点要么是红的,要么是黑的。
- 根结点是黑的。
- 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
- 如果一个结点是红的,那么它的俩个儿子都是黑的。
- 对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
平衡树
平衡树(AVL)更平衡,结构上更加直观,时间效能针对读取而言更高,但是维护起来比较麻烦(需要不断rebalance)
8.2 Node.js/Java/Go
Node.js
node.js开发快,运行的效率也算比较高,但是如果项目大了就容易乱,而且JavaScript不是静态类型的语言,要到运行时才知道类型错误,所以写的多了之后免不了会出现光知道有错但是找不到哪儿错的情况,所以测试就得些的更好更详细。
Java
Java开发慢,但是如果项目大、复杂的话,用Java就不容易乱,管理起来比Node.js省。
Go
Go轻量,性能高,语法简洁
Go语言的主要的功能在于令人简易使用的并行设计,这个方法叫做Goroutine,通过Goroutine能够让你的程序以异步的方式运行,而不需要担心一个函数导致程序中断
8.3 事件代理
事件委托,事件委托就是利用事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。
8.4 死锁条件
8.5 多线程安全问题
When
有可能会出现同时访问同一个资源的情况,由于每个线程执行的过程是不可控的,所以很可能导致最终的结果与实际上的愿望相违背或者直接导致程序出错。
How
同步互斥访问(互斥锁
悲观锁:每次都假设最坏情况,共享资源每次只给一个线程使用,其他先阻塞 乐观锁:假设最好的情况,适用于多读的应用类型,提高吞吐率
8.6 进程间通信IPC
工厂模式(Factory Pattern)
针对每一种产品提供一个工厂类,通过不同的工厂实例来创建不同的产品实例
抽象工厂模式(Abstract Factory Pattern)
定义一个用以创建对象的工厂, 根据不同的条件生成不同的对象
单例模式(Singleton Pattern)
单例模式只能有一个实例
建造者模式(Builder Pattern)
- 原型模式(Prototype Pattern)
结构型模式
- 适配器模式(Adapter Pattern)
- 桥接模式(Bridge Pattern)
- 过滤器模式(Filter、Criteria Pattern)
- 组合模式(Composite Pattern)
- 装饰器模式(Decorator Pattern)
- 外观模式(Facade Pattern)
- 享元模式(Flyweight Pattern)
- 代理模式(Proxy Pattern)
行为型模式
- 责任链模式(Chain of Responsibility Pattern)
- 命令模式(Command Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 空对象模式(Null Object Pattern)
- 策略模式(Strategy Pattern)
- 模板模式(Template Pattern)
- 访问者模式(Visitor Pattern)
J2EE模式
- MVC 模式(MVC Pattern)
- 业务代表模式(Business Delegate Pattern)
- 组合实体模式(Composite Entity Pattern)
- 数据访问对象模式(Data Access Object Pattern)
- 前端控制器模式(Front Controller Pattern)
- 拦截过滤器模式(Intercepting Filter Pattern)
- 服务定位器模式(Service Locator Pattern)
- 传输对象模式(Transfer Object Pattern)
参考资料
[1]TCP相关知识
[2]promise相关知识
[3]
[4]
[5]
[6]

若有收获,就点个赞吧
0 人点赞
