1.2 硬件环境要求
基于1.1节介绍的分布式架构,一般服务器配置分为如下几个模块。
(1)模型解析服务器:提供模型解析服务GPU服务器,需要高内存,高CPU主频,参考BIM工作站配置,可弹性拓展。
| 服务器 | 参数项 | 推荐参数 |
|---|---|---|
| 中心管理服务器 | CPU | 服务器CPU或Intel i9系列的高主频CPU。 |
| 内存 | 根据模型大小确定,推荐至少64GB-128GB内存(Revit大模型吃内存资源)。 | |
| GPU | 推荐NVIDIA GeForce系列GPU,RTX2060/2070/2080/3060/3070/3080/3090;或Quadro系列。 | |
| 存储 | 根据实际项目需求量配置。需求量极大的,可单独配置存储服务器。 | |
| 操作系统 | Windows Server 2019系统。 | |
| 带宽要求 | 用户上传模型文件需要考虑到带宽需求,内网则无需考虑。 | |
| 软件安装 | 按需安装Revit等等需要用到的第三方软件(按使用场景,按需安装),详见下一节软件环境要求部分。 |
如果解析服务用得少,建议无需单独配置,采用OurBIM公有云的解析服务,解析完下载数据包到本地;或与实时云渲染服务器共用即可。
(2)实时云计算服务器:采用GPU渲染服务器,支持一机多卡,可弹性拓展。
实时云渲染服务器,一般分中心管理服务器和渲染节点服务器。如果简易部署,则不用区分;如节点数量较多,一般还可单独配置共享存储服务器(可供实时渲染服务单独使用,或供模型解析服务与实时渲染服务共享使用)。
一般中心管理节点保证高可用,不用做实时渲染任务。中心节点与渲染节点,可处于同一局域网,也可分布在不同的公网网段。与中心节点在同一局域网的各个渲染节点,可共享一个公网IP地址,与中心节点不在一个局域网的各个渲染节点,需要每个服务器节点都有一个独立的公网IP。
中心管理服务器:不需要GPU,配置CPU服务器或虚拟机,保证高可用,配置参考用户自己的应用服务器,可与应用服务器共用。
渲染节点服务器:
| 服务器 | 参数项 | 推荐参数 |
|---|---|---|
| 渲染节点服务器 | CPU | 推荐志强系列的服务器CPU或Intel i9系列的高主频CPU,多显卡集群主机可配置双CPU。 |
| 内存 | 按显卡数量确定,按每块显卡配置16-32GB内存进行配置。 | |
| GPU | 推荐NVIDIA GeForce系列GPU,RTX 2060/2070/2080/3060/3070/3080/3090等,推荐一机多卡版本的服务器,可有效节省其他组件的费用。显卡数量按BIM模型的并发需求量配置。针对大场景,按单卡2-4个并发核算。比如10个并发,可配置3-5块RTX 3060。针对小场景,按3-8个并发核算,比如10个并发,可配置2-3块RTX3060。单显卡配置越高,理论上支持的并发数量越多。 | |
| 存储 | 根据实际项目需求量配置。需求量极大的,可单独配置存储服务器。 | |
| 操作系统 | Windows Server 2019系统。 | |
| 带宽要求 | 按单路并发2-4MB/s配置服务器的外网带宽资源。比如10个并发,可配置20-40MB/s的专线带宽资源。 如果要适配高分辨率终端,比如2K、4K大屏,对服务端带宽的配置要同步提升。如果是内网使用,此项可不考虑。 |
|
| 软件安装 | 按需安装需要用到的第三方软件,详见下一节软件环境要求部分。 | |
| 显卡欺骗器 | 需要给每块显卡的视频输出插槽,各插一个显卡欺骗器硬件,或使用第三方虚拟显示器软件,给每块显卡虚拟出一个虚拟显示器。推荐显卡欺骗器。(否则可能无法检测到显卡资源,无法正常分配显卡算力,无法加载BIM模型) |
(3)共享存储服务器:当渲染节点特别多,存储需求量特别大的,单机独立存储成本较高,可单独配置高I/O的共享存储节点服务器(内网传输,推荐内网万兆网口,千兆起步)。
(4)应用服务器:这个不是OurBIM运行需要的服务器,而是用户自己的产品或项目应用服务运行的服务器。一般采用普通CPU服务器,无GPU需求,Windows Server或Linux系统,内存、存储、带宽等按需配置。此项一般可与OurBIM的中心管理服务部署在一台服务器上,共享资源,减少数据跨网流转。
OurBIM支持的部署方式,很灵活:
(1)简易部署:即多项服务合并部署。如果并发数量并不高,或部分服务并不常用,则以上几项服务器需求,可合并到一台机器,共享资源。适用于OurBIM私有化(项目版)授权。
(2)分布式集群部署:各项服务均可进行分布式的集群部署。如下服务器部署示例:
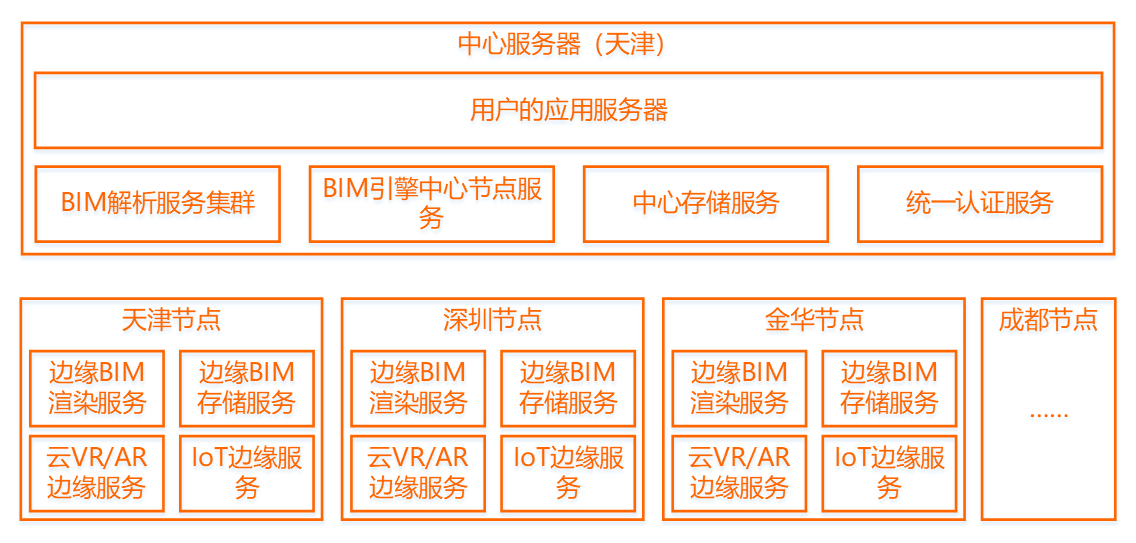
一般需要较多的是实时渲染资源,渲染节点最好部署在离用户进的区域,以尽量降低网络传输的时延,这对云VR、云AR的用户体验至关重要。每一个边缘节点,均需要一套存储服务,通过公网实现与中心服务器的数据同步。
不同地理位置的用户发起访问时,会自动判断距离用户最近的空闲渲染节点,将其算力资源分配给此用户,弹性消耗和释放。
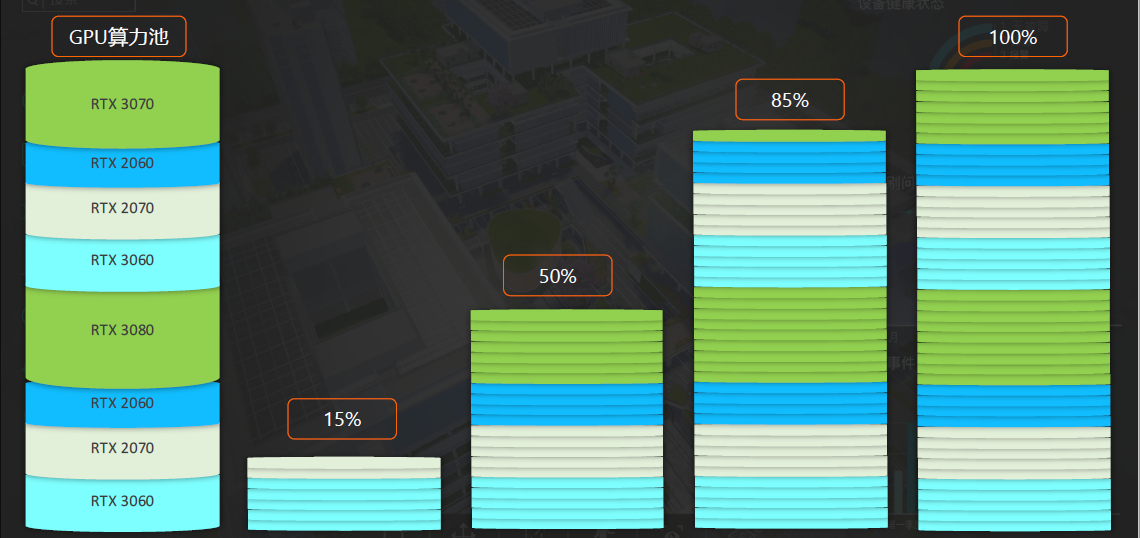
(3)推荐企业版配置:一般把模型解析服务器单独部署(按模型解析工作的处理工作量和使用频率配置,高主频CPU);应用服务器、模型渲染中心服务器、共享存储服务器可合并1台(无GPU需求);渲染节点服务器按购买的并发数量授权进行配置(GPU集群)。这三类服务器处于同一内网,共享存储空间资源。
(4)推荐项目版配置:没有模型解析服务器需求,一般采用简易部署模式即可。

若有收获,就点个赞吧
0 人点赞
