一、基本的概念
图:表示多对多的关系。是一种数据结构,其中的节点可以包含零个或者多个节点,两个节点之间的连接称为边,节点也称之为顶点。
图分为无向图、有向图、带权图。
图的表示方式:二维数组表示(邻接矩阵),链表表示(邻接表)
邻接矩阵:表示图形中顶点之间的相邻关系的矩阵,对于n个顶点关系的矩阵,矩阵是nn的
邻接表:邻接表只关心存在的边,不关心不存在的边,因此没有浪费空间,使用*数组与链表实现。
二、图的遍历
2.1 深度优先
深度优先遍历(DFS):从初始访问点出发,初始访问节点可能有多个邻接节点,深度优先遍历的策略是首先访问第一个临接点,然后再以这个被访问的邻接节点作为初始节点,继续访问它的第一个邻接节点,直到访问到最后为止。然后再访问第二节点。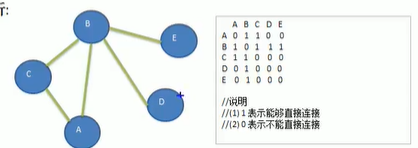
算法步骤:
- 访问初始节点v,并且标记节点v已经访问
- 查找节点v的第一个临界点w
- 如果w存在,则继续执行4;如果w不存在,则返回1,将从v的下一个节点继续
- 如果w未被访问,则对w进行深度优先遍历递归(把w看做是v,然后递归执行123)
- 查找节点v的w邻接节点的下一个邻接节点,转到步骤3
代码的实现:
/*** 获取第一个邻接节点* @param index* @return*/public int getFirstNeigbor(int index) {for(int i=0; i<vertextList.size(); i++) {// if(!isVisited[i])if(edges[index][i] > 0) return i;}return -1;}/*** 获取从n后的第一个邻接节点* @param index 表示访问第index个节点* @param n 从第n个位置开始访问* @return*/public int getOtherNeigbor(int index, int n) {for(int i=n+1; i<vertextList.size(); i++) {if(edges[index][i] > 0) return i;}return -1;}/*** 深度优先遍历* @param isVisited 布尔数组,存储节点是否被访问过* @param i 当前遍历的节点的位置*/public void dfs(boolean[] isVisited, int i) {// 输出第i个节点System.out.print(getVertexByIndex(i) + "->");// 将该位置标记为已访问isVisited[i] = true;// 获取该位置的第一个邻接节点int w = getFirstNeigbor(i);// 如果w存在,则进行递归深度遍历while(w != -1) {// 如果w位置的节点没有被访问过,则进行深度递归if(!isVisited[w]) {dfs(isVisited, w);}// 然后继续进行查找相邻的邻接节点w = getOtherNeigbor(i, w);}}/*** 深度优先遍历*/public void dfs() {isVisited = new boolean[vertextList.size()];for(int i=0; i<vertextList.size(); i++) {// 如果该节点没有被访问过,则进行深度遍历if(!isVisited[i]) {dfs(isVisited, i);}}System.out.println();}
2.2 广度优先
广度优先遍历(BFS):广度遍历需要一个队列来保存已经访问过的节点的顺序,以便按照这个顺序来访问这些节点的相邻节点。
算法步骤:
- 访问初始节点v,并且标记节点v已经访问
- 节点v入队列
- 当位列为非空时,则继续执行,否则算法结束
- 出队列,取得都头节点u
- 查找节点u的第一个邻接点w
如果u的邻接点不存在,则转到步骤3;否则执行以下的三个步骤:
- 若是节点w未被访问,则访问节点w并标记为已经访问
- 节点w加入队列
- 查找节点u的继w邻接点后的下一个邻接点w,转到步骤6
代码的实现: ```java /**
- 广度优先遍历算法
*/
public void bfs() {
// 标记顶点访问
isVisited = new boolean[vertextList.size()];
// 队列存储同一层的节点
Queue
list = new LinkedList<>(); // 遍历所有的节点,防止有节点为独立节点,不与其他节点相连 for(int i=0; i<vertextList.size(); i++) {
}// 判断该节点是否被访问过,如果被访问过就直接进行下一个if(!isVisited[i]) {// 打印节点System.out.print(getVertexByIndex(i) + "->");list.offer(i); // 将当前节点添加到队列中isVisited[i] = true; // 将输出的节点标记为已访问while(!list.isEmpty()) {int k = list.poll(); // 队列抛出节点,遍历该节点相连的相邻节点for(int j =0; j<k; j++) {if(!isVisited[k] && edges[k][j] > 0) {System.out.print(getVertexByIndex(j) + "->");isVisited[j] = true;}}}}
System.out.println(); } ```
三、图的算法
普里姆算法
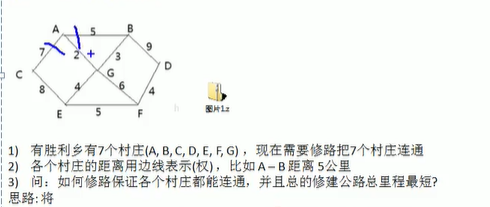
正确思路是:就是尽可能的选择少的路线,并且每条路线最小,保证总里程数最小。
修路的问题就是最小生成树问题。
最小生成树,简称MST:
- 给定一个带权的无向连通图,如何选择一颗生成树,使得树上所有边上权的总和为最小,这就叫做最小生成树。
- N个顶点,一定有N-1条边
- 包括全部的顶点
- N-1条边都在图中
普里姆算法求最小生成树,也就是在包含n个顶点的连通图中,找出(n-1)条边包含所有的n个顶点的连通子图,也就是所谓的极小连通子图。
算法步骤为:
- 设G=(V,E)是连通图,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合
- 若从顶点u开始构建最小生成树,则从集合v中取出顶点u放入到集合U中,标记顶点v的visited[v]=1
- 若集合U中的顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中的权值最小的边,但不能构成回路,将顶点vj加入到集合U中,将边(ui, vj)加入到集合D中,并标记visited[vj]=1
- 重复步骤2,直到U与V完全相等,即所有的顶点都被访问过了,此时D中有n-1条边。
迪杰拉斯特算法
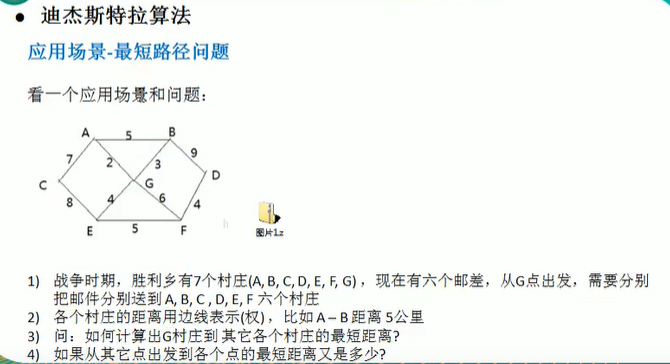
迪杰斯特拉算法是典型的最短路径算法,用于计算一个节点到其他节点的最短路径。它的主要特点是以起始点为中心,向外层层扩散(广度优先搜索思想),直到扩展到终点为止。
迪杰斯塔拉算法算法的步骤:
- 首先给定出发点为index,设置dis[]数组存储节点到出发点的距离,alreadyArr[]数组为该点是否已经访问,preArr为该点的上一个节点。
- 从index节点出发,遍历从index点能够到达的点j;如果j点的距离+index点到出发点的距离小于已经存在的j节点或者该j点的距离dis为空,将dis[]数组中j点的位置距离设置为j点的距离+index点到出发点的距离。设置该j点的preArr为index。继续遍历其他的节点。
- 继续遍历,寻找alreadyArr[]数组中未遍历的节点,取未遍历节点中距离dis[k]最小的节点作为index节点,然后重复步骤2,3。直到alreaArr[]数组中的节点全部遍历完成。
- 输出最后的结果
代码的实现:
public class DijkstraAlgorithm {// 迪杰斯塔拉算法public static void main(String[] args) {char[] point = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};int[][] matrix = new int[point.length][point.length];final int N = -1;matrix[0] = new int[]{0, 5, 7, N, N, N, 2};matrix[1] = new int[]{5, 0, N, 9, N, N, 3};matrix[2] = new int[]{7, N, 0, N, 8, N, N};matrix[3] = new int[]{N, 9, N, 0, N, 4, N};matrix[4] = new int[]{N, N, 8, N, 0, 5, 4};matrix[5] = new int[]{N, N, N, 4, 5, 0, 6};matrix[6] = new int[]{2, 3, N, N, 4, 6, 0};// 创建迪杰斯塔拉算法对象,设置初始点位置为G// Dijkstra dijkstra = new Dijkstra(point.length, 6);Dijkstra dijkstra = new Dijkstra(point.length, 0);dijkstra.addPoint(point);dijkstra.addMatrix(matrix);dijkstra.djs();dijkstra.show();}}class Dijkstra{char[] point;int[][] matrix;int pointNum;int index;Vetext vetext;// 构造器public Dijkstra(int len, int index) {this.pointNum = len;this.index = index;point = new char[len];matrix = new int[len][len];vetext = new Vetext(len, index);}// 添加顶点public void addPoint(char[] point) {for(int i=0; i<pointNum; i++) {this.point[i] = point[i];}}// 添加边的条件public void addMatrix(int[][] m) {for(int i=0; i<pointNum; i++) {for (int j = 0; j < pointNum; j++) {this.matrix[i][j] = m[i][j];}}}// 寻找下一个遍历的节点public int findNextPoint() {int min = Integer.MAX_VALUE;int index = 0;for(int i=0; i<pointNum; i++) {if(vetext.dis[i] != -1 && vetext.alreadArr[i] == 0 && vetext.dis[i] < min) {min = vetext.dis[i];index = i;}}vetext.alreadArr[index] = 1;return index;}/*** 更新vetex中的各个数组* @param index*/public void updateArr(int index) {int len = 0;for(int i=0; i<matrix[index].length; i++) {if(matrix[index][i] == -1) continue;len = matrix[index][i] + vetext.dis[index];if((vetext.isDis(i) && len < vetext.dis[i]) || !vetext.isDis(i)) {vetext.dis[i] = len;vetext.prePoint[i] = index;}}}/*** 迪杰拉斯算法的主要实现过程*/public void djs() {for(int i=0; i<pointNum; i++) {int index = findNextPoint();updateArr(index);}}/*** 将数组进行打印*/public void show() {vetext.show();}}/*** 用来存储迪杰斯塔拉算法算法中所使用的的几个数组* @author Administrator**/class Vetext{int[] alreadArr;int[] dis;int[] prePoint;// 构造器public Vetext(int len, int index) {alreadArr = new int[len];dis = new int[len];prePoint = new int[len];// 使用-1表示没有距离Arrays.fill(dis, -1);dis[index] = 0; // 初始点的距离为0}/*** 展示数组*/public void show() {System.out.println("节点是已访问:");System.out.println(Arrays.toString(alreadArr));System.out.println("节点的距离:");System.out.println(Arrays.toString(dis));System.out.println("前置节点的位置:");System.out.println(Arrays.toString(prePoint));}/*** 判断节点i是否被访问过了* @param index* @return*/public boolean already(int index) {return alreadArr[index] == 1;}/*** 判断距离是否有效* @param index* @return*/public boolean isDis(int index) {return dis[index] != -1;}}
弗洛伊德(Floyd)算法
弗洛伊德算法计算图中各个顶点之间的最短路径。
迪杰斯塔拉算法是计算选中访问顶点到其他各个顶点之间的最短路径。
弗洛伊德算法的分析:
- 设置顶点
vi到vk的最短路径已知为Lik,顶点vk到vj的最短路径为已知的Lkj,顶点vi到vj的路径为Lij。则vi到vj的最短路径为min((Lik+Lkj), Lij)。vk的取值为图中的所有顶点,则可以获得vi到vj的所有最短路径。 - 设置顶点的前驱关系图与顶点之间的距离图。
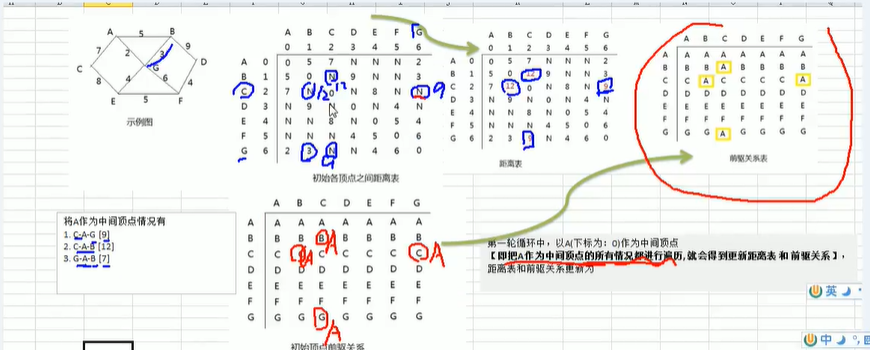
代码的实现:
public class FloydAlgorithm {public static void main(String[] args) {char[] point = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};int[][] matrix = new int[point.length][point.length];final int N = -1;matrix[0] = new int[]{0, 5, 7, N, N, N, 2};matrix[1] = new int[]{5, 0, N, 9, N, N, 3};matrix[2] = new int[]{7, N, 0, N, 8, N, N};matrix[3] = new int[]{N, 9, N, 0, N, 4, N};matrix[4] = new int[]{N, N, 8, N, 0, 5, 4};matrix[5] = new int[]{N, N, N, 4, 5, 0, 6};matrix[6] = new int[]{2, 3, N, N, 4, 6, 0};FloydGraph floydGraph = new FloydGraph(point.length, matrix, point);floydGraph.floyd();floydGraph.show();}}class FloydGraph{char[] point;int[][] dis;int[][] pre;public FloydGraph(int length, int[][] dis, char[] point) {this.point = new char[length];this.dis = new int[length][length];this.pre = new int[length][length];for(int i=0; i<length; i++) {this.point[i] = point[i];}for(int i=0; i<length; i++) {for(int j=0; j<length; j++) {this.dis[i][j] = dis[i][j];pre[i][j] = i;}}}/*** 弗洛伊德算法,实现三层遍历算法*/public void floyd() {int len = 0;// 第一次遍历 所有的节点作为中间节点,路径为i -> k -> jfor (int k = 0; k < point.length; k++) {// 第二次遍历 节点作为开始节点for (int i = 0; i < point.length; i++) {// 第三次遍历 节点作为结束节点for(int j = i+1; j<point.length; j++) {if(dis[i][k] == -1 || dis[k][j] == -1) continue;len = dis[i][k] + dis[k][j];if(dis[i][j] == -1 || len < dis[i][j]) {// 更新距离dis[i][j] = len;dis[j][i] = len;// 更新前缀pre[i][j] = pre[k][j];pre[j][i] = pre[k][j];}}}}}/*** 打印dis与pre数组*/public void show() {System.out.println("打印dis位置数组:");for(int i=0; i<point.length; i++) {for (int j = 0; j < point.length; j++) {System.out.printf("%4d", dis[i][j]);}System.out.println();}System.out.println("打印pre前缀数组:");for (int i = 0; i < point.length; i++) {for (int j = 0; j < point.length; j++) {System.out.printf("%4d", pre[i][j]);}System.out.println();}System.out.println("打印节点之间的距离关系:");for (int i = 0; i < point.length; i++) {for (int j = 0; j < point.length; j++) {System.out.print("<" + point[i] + "," + point[j] + ">=" + dis[i][j] +" ");}System.out.println();}}}
马踏棋盘算法(骑士周游算法)
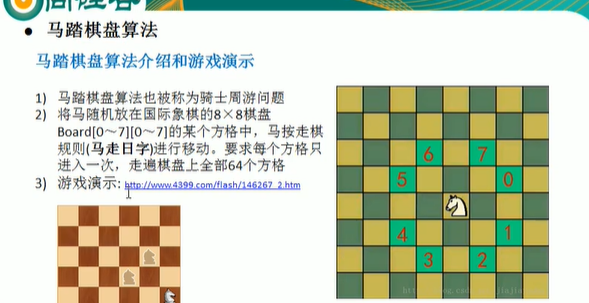
骑士周游问题的解决步骤和思路:
- 创建棋盘chessboard,是一个二维数组
- 将当前位置设置为已经访问了,然后根据当前位置,计算马儿还能走哪些位置,并放入到一个集合中,最多有8个位置,每走1步,就使用step+1
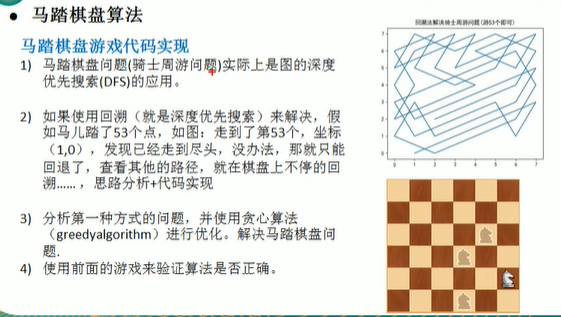
- 遍历ArrayList中所存放的所有位置,看看哪个位置可以走通,如果能够走通,就继续,走不通就回溯。
- 判断马儿是否完成了任务,使用step和该走的步数进行比较,如果没有达到数量,则表示没有完成任务,将整个棋盘置0;
使用贪心算法的贪心策略,减少
代码的实现:
import java.awt.Point;import java.util.ArrayList;import java.util.Arrays;import java.util.Comparator;import java.util.List;public class HorseChessBorad {// private static int[][] chessborad;private static int col;private static int row;private static boolean[] visited;private static boolean finished;// 骑士周游问题public static void main(String[] args) {System.out.println("骑士周游算法开始。。。");row = 8;col = 8;visited = new boolean[row * col];finished = false;int[][] chessborad = new int[row][col];long start = System.currentTimeMillis();ChessBoradRun(chessborad, 0, 0, 1);long end = System.currentTimeMillis();System.out.println("花费的时间为:" + (end - start) + "毫秒");for(int[] rows: chessborad) {System.out.println(Arrays.toString(rows));}}/*** 用来解决骑士周游问题的最主要的方法* @param board 表示棋盘的位置* @param i 表示当前为第i行* @param j 表示当前为第j列* @param step 表示当前步数*/public static void ChessBoradRun(int[][] board, int i, int j, int step) {board[i][j] = step;visited[i * col + j] = true;List<Point> points = getNext(new Point(j, i));pointSort(points);while(!points.isEmpty()) {Point p = points.remove(0);if(!visited[p.y * col + p.x]) {ChessBoradRun(board, p.y, p.x, step+1);}}// 如果没有step没有遍历完成所有的网格,则需要进行回退if(step < col * row && !finished) {board[i][j] = 0;visited[i * col + j] = false;}else {finished = true;}}/*** 根据获得下一步中的点的下一步中最少点数进行非递减排序* @param list*/public static void pointSort(List<Point> list) {list.sort(new Comparator<Point>() {@Overridepublic int compare(Point o1, Point o2) {return getNext(o1).size() - getNext(o2).size();}});}/*** 获取下一步将要走的位置* @param point* @return*/public static List<Point> getNext(Point point){int[] steps = {-2, -1, 2, 1, -2, 1, 2, -1, -2};Point p = new Point();List<Point> result = new ArrayList<>();for (int i = 0; i < steps.length-1; i++) {p.x = point.x + steps[i];p.y = point.y + steps[i+1];if(p.x < 0 || p.y < 0 || p.x >= col || p.y >= row) {continue;}result.add(new Point(p));}return result;}}

若有收获,就点个赞吧
0 人点赞
