1. Presto介绍
1.1 Presto简介
1.1.1 Presto概述
Presto is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
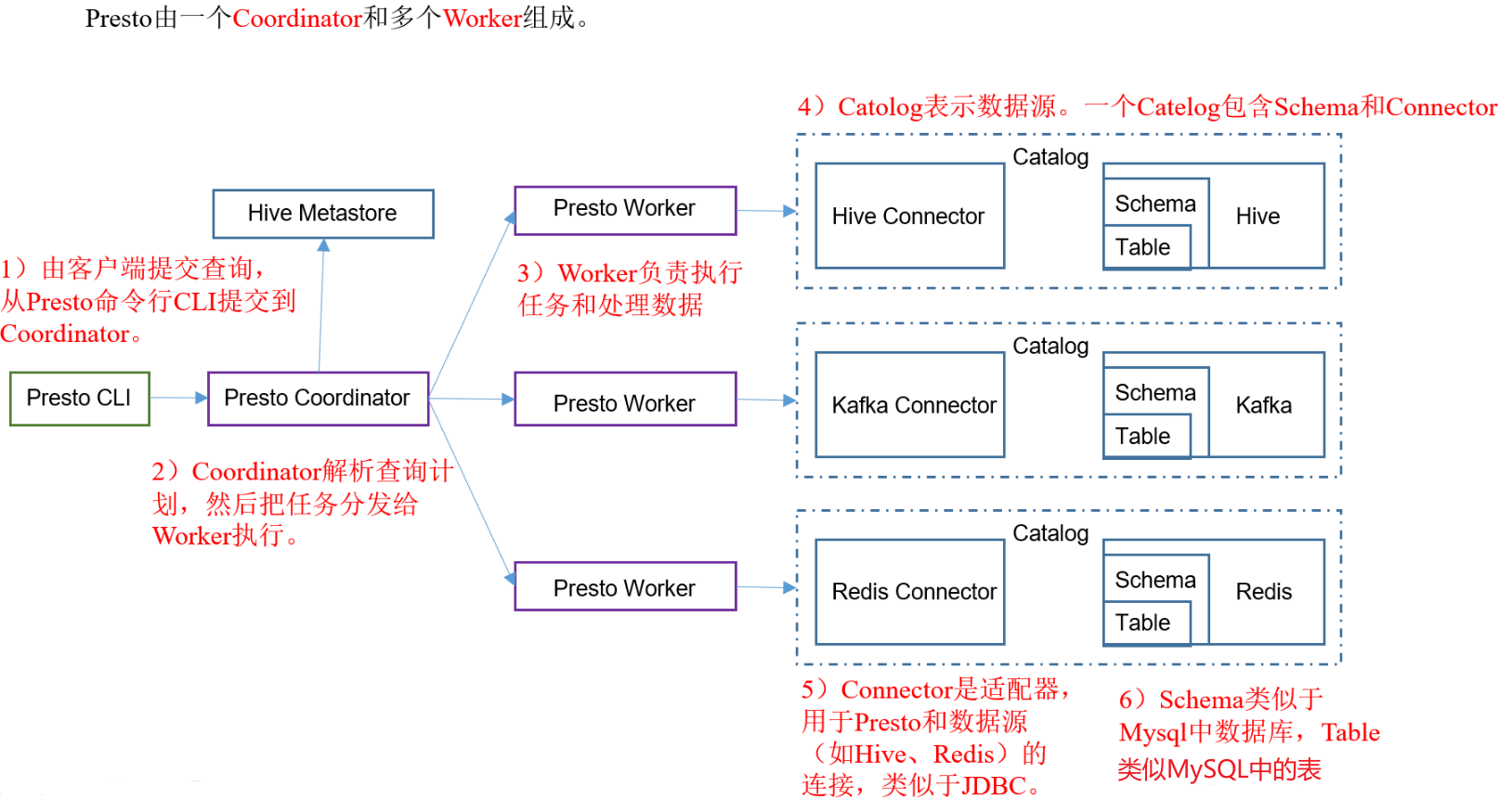
1.1.2 Presto架构
1.1.3 官网地址
就在2020年12月27日,prestosql与facebook正式分裂,并改名为trino.
https://prestosql.io/
https://trino.io
1.1.4 Prestodb VS Prestosql(trino)
根据目前社区活跃度和使用广泛度,更加推荐prestosql.具体区别参考博文:
http://armsword.com/2020/05/02/the-difference-between-prestodb-and-prestosql/
1.2 Prestosql的安装和使用
1.2.1 prestosql版本的选择
在presto330版本里已经提到,jdk8只支持到2020-03月发行的版本.详情参考:
https://prestosql.io/docs/current/release/release-330.html
在2020年4月8号presto社区发布的332版本开始,需要jdk11的版本.由于现在基本都使用的是jdk8,所以我们选择presto315版本的,此版本在jdk8的环境下是可用的.如果我们生产环境是jdk8,但是又想使用新版的presto,可以为presto单独指定jdk11即可使用.最后附录部分会给出使用jdk11的配置方式.
1.2.2 集群安装规划
| host | coordinator | worker |
|---|---|---|
| linux121 | √ | × |
| linux122 | × | √ |
| linux123 | × | √ |
1.2.3 Presto Server的安装
- 安装包下载地址
https://repo1.maven.org/maven2/io/prestosql/presto-server/315/presto-server-315.tar.gz
- 将presto-server-315.tar.gz上传到服务器上,这里导入到linux121服务器上的/opt/software目录下,并解压至/opt/servers目录下
| Shell [root@linux121 software]# tar -zvxf presto-server-315.tar.gz -C /opt/servers/ |
|---|
- 创建presto的数据目录(presto集群的每台机器都要创建).用来存储日志这些
| Shell [root@linux121 presto-server-315]# mkdir -p /file/data/presto |
|---|
- 在安装目录/opt/servers/presto-server-315下创建etc目录,用来存放各种配置文件
| Shell [root@linux121 presto-server-315]# mkdir etc |
|---|
1.2.4 Node Properties配置
在/opt/servers/presto-server-315/etc路径下,配置node属性(注意:集群中每台presto的node.id必须不一样,后面需要修改集群中其它节点的node.id值)
| Shell [root@linux121 etc]# vim node.properties #环境名称,自己任取.集群中的所有Presto节点必须具有相同的环境名称. node.environment=develop #支持字母,数字.对于每个节点,这必须是唯一的.这个标识符应该在重新启动或升级Presto时保持一致 node.id=1 #指定presto的日志和其它数据的存储目录,自己创建前面创建好的数据目录 node.data-dir=/file/data/presto |
|---|
1.2.5 JVM Config配置
在/opt/servers/presto-server-315/etc目录下添加jvm.config配置文件,并填入如下内容
| Shell [root@linux121 etc]# vim jvm.config #参考官方给的配置,根据自身机器实际内存进行配置 -server #最大jvm内存 -Xmx15G -XX:-UseBiasedLocking #指定GC的策略 -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+ExplicitGCInvokesConcurrent -XX:+ExitOnOutOfMemoryError -XX:+HeapDumpOnOutOfMemoryError -XX:ReservedCodeCacheSize=512M -Djdk.attach.allowAttachSelf=true -Djdk.nio.maxCachedBufferSize=2000000 |
|---|
1.2.6 Config Properties配置
The config properties file, etc/config.properties, contains the configuration for the Presto server. Every Presto server can function as both a coordinator and a worker, but dedicating a single machine to only perform coordination work provides the best performance on larger clusters.
Presto是由一个coordinator节点和多个worker节点组成.由于在单独一台服务器上配置coordinator有利于提高性能,所以在linux121上配置成coordinator,在linux122,linux123上配置为worker(如果实际机器数量不多的话可以将在协调器上部署worker.)在/opt/servers/presto-server-315/etc目录下添加config.properties配置文件
| Shell 这是针对coordinator所在节点的配置信息(针对worker所在节点配置信息后面会配置.): [root@linux122 etc]# vim config.properties #该节点是否作为coordinator,如果是true就允许该Presto实例充当协调器 coordinator=true #允许在协调器上调度工作(即配置worker节点).为false就是不允许.对于较大的集群,协调器上的处理工作可能会影响查询性能,因为机器的资源无法用于调度,管理和监视查询执行的关键任务 #如果需要在协调器所在节点配置worker节点改为true即可 node-scheduler.include-coordinator=false #指定HTTP服务器的端口.Presto使用HTTP进行所有内部和外部通信 http-server.http.port=7788 #每个查询可以使用的最大分布式内存量。 query.max-memory=12GB #查询可在任何一台计算机上使用的最大用户内存量 query.max-memory-per-node=5GB #查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存。 query.max-total-memory-per-node=6GB #该参数默认值时-Xmx的30%.且这个值加上query.max-total-memory-per-node的值不能大于-Xmx的值.否则无法启动 memory.heap-heaproom-per-node=2GB #discover-server是coordinator内置的服务,负责监听worker discovery-server.enabled=true #发现服务器的URI.因为已经在Presto协调器中启用了discovery,所以这应该是Presto协调器的URI discovery.uri=http://linux121:7788 |
|---|
1.2.7 Catalog Properties配置
Presto可以支持多个数据源,在Presto里面叫catalog,这里以配置支持Hive和MySQL的数据源为例,配置一个Hive的catalog和多个MySQL的catalog:
| Shell #在etc目录下创建catalog目录 [root@linux121 etc]# mkdir catalog |
|---|
Hive的catalog:
| Shell #在catalog目录下创建hive.properties文件 [root@linux121 catalog]# vim hive.properties #代表hadoop2代版本,并不是单单指hadoop2.x的版本,而是hadoop第二代.固定写法 connector.name=hive-hadoop2 #指定hive的metastore的地址(hive必须启用metastore) hive.metastore.uri=thrift://linux123:9083 #如果hdfs是高可用必须增加这个配置.如果不是高可用,可省略.如果Presto所在的节点没有安装Hadoop,需要从其它hadoop节点复制这些文件到Presto的节点 hive.config.resources=/opt/servers/hadoop-2.9.2/etc/hadoop/core-site.xml,/opt/servers/hadoop-2.9.2/etc/hadoop/hdfs-site.xml |
|---|
MySQL的catalog(第一个对接的是a业务线的Mysql):
| Shell #通过文件名称区分不同的mysql数据来源 [root@linux121 catalog]# vim mysql_a.properties #配置Mysql源.这里必须是mysql connector.name=mysql #指定连接Mysql的url connection-url=jdbc:mysql://linux123:3306 #连接mysql的主机名 connection-user=root #连接mysql的密码 connection-password=12345678 |
|---|
MySQL的catalog(第二个对接的是b业务线的Mysql):
| Shell #通过文件名称区分不同的mysql数据来源 [root@linux121 catalog]# vim mysql_b.properties #配置Mysql源.这里必须是mysql connector.name=mysql #指定连接Mysql的url connection-url=jdbc:mysql://linux121:3306 #连接mysql的主机名 connection-user=root #连接mysql的密码 connection-password=123456 |
|---|
1.2.8 分发安装目录到集群中其它节点上
将linux121上配置好的presto安装包分发到集群中的其它节点(这里使用的是自己写的分发脚本)
| Shell [root@linux121 servers]# rsync-script /opt/servers/presto-server-315/ |
|---|
1.2.9 修改node.id
修改linux122和linux123机器上node.properties配置文件中的node.id(因为每台机器node.id必须要不一样)
| Shell [root@linux122 etc]# vim node.properties node.id=2 [root@linux123 etc]# vim node.properties node.id=3 |
|---|
1.2.10 修改work节点的配置信息
修改worker节点(即linux122和linux123机器)上的config.properties配置文件.里面的配置内容与coordinator所在的节点是不一样的.
| Shell [root@linux122 etc]# vim config.properties #该节点是否作为coordinator,因为是worker节点,这里是false coordinator=false #访问端口,可以自己指定 http-server.http.port=7788 #每个查询可以使用的最大分布式内存量。 query.max-memory=12GB #查询可在任何一台计算机上使用的最大用户内存量 query.max-memory-per-node=5GB #查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存。 query.max-total-memory-per-node=6GB #该参数默认值时-Xmx的30%.且这个值加上query.max-total-memory-per-node的值不能大于-Xmx的值.否则无法启动 memory.heap-heaproom-per-node=2GB #指定discovery-server的地址,这样worker才能找到它.与上面的端口须一致 discovery.uri=http://linux121:7788 |
|---|
| Shell [root@linux123 etc]# vim config.properties #该节点是否作为coordinator,如果是true就是作为协调器 coordinator=false #访问端口,可以自己指定 http-server.http.port=7788 #每个查询可以使用的最大分布式内存量。 query.max-memory=12GB #查询可在任何一台计算机上使用的最大用户内存量 query.max-memory-per-node=5GB #查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存。 query.max-total-memory-per-node=6GB #该参数默认值时-Xmx的30%.且这个值加上query.max-total-memory-per-node的值不能大于-Xmx的值.否则无法启动 memory.heap-heaproom-per-node=2GB #指定discovery-server的地址,这样worker才能找到它.与上面的端口须一致 discovery.uri=http://linux121:7788 |
|---|
1.2.11 以presto用户启动服务
如果是以root用户就可以直接启动了,我们这里使用presto用户启动,还需要进行下面的操作(须保证每台已存在presto用户)
- 将presto的数据目录/file/data/presto所有者修改为presto:presto(使用自己写的脚本一次性修改集群中每个节点)
| Shell [root@linux121 ~]# myssh chown -R presto:presto /file/data/presto/ |
|---|
- 将presto的安装目录/opt/servers/presto-server-315所有者修改为presto:presto
| Shell [root@linux121 ~]# myssh chown -R presto:presto /opt/servers/presto-server-315/ |
|---|
1.2.12 启动presto服务
分别在linux121,linux122,linux123上启动Presto Server(为了连接hive,需要先要保证Hive的metastore是启动的),这里使用后台进程启动的命令.
| Shell [presto@linux121 presto-server-315]$ bin/launcher start [presto@linux122 presto-server-315]$ bin/launcher start [presto@linux123 presto-server-315]$ bin/launcher start |
|---|
说明:若启动有问题去查看日志.日志目录在前面指定的数据目录的var/log下,即/file/data/presto/var/log目录下
1.2.13 启动成功后会看到多了一个PrestoServer进程
| Shell [presto@linux121 presto-server-315]$ jps 14881 PrestoServer |
|---|
1.2.14 访问presto的webui界面
1.3 Presto命令行Client的安装
- 下载Presto的客户端(下载presto对应的版本)
https://repo1.maven.org/maven2/io/prestosql/presto-cli/315/presto-cli-315-executable.jar
- 将presto-cli-315-executable.jar上传至服务器,放在linux121的/opt/servers/presto-server-315/bin目录下.
- 为方便使用,修改jar包名称为presto
| Shell [presto@linux121 bin]$ mv presto-cli-315-executable.jar presto |
|---|
- 给文件增加执行权限
| Shell [root@linux121 presto-server-315]# chmod +x presto |
|---|
1.4 Presto的基本使用
- 启动presto客户端并选择连接的数据源(这里以hive为例)
| Shell [presto@linux121 presto-server-315]$ ./presto \ —server linux121:7788 \ —catalog hive \(可选) —schema test \(可选) —user xiaobai (可选) |
|---|
说明:
—server指定的是coordinator的地址
—catalog指定的是连接的数据源.(跟配置文件里面的名称一致)
—schema指定的是连接哪个数据库,这里是test数据库
- Presto命令行操作
| Shell #查看所有的数据库 presto:test> show schemas; #查看某个库下的所有表 presto:test> show tables; #查看一条sql查询(6亿多条数据比hive快很多) presto:test> select count(1) from test.test_hive; _col0 —————- 620756992 |
|---|
1.5 Presto可视化客户端的安装(了解)
Presto可视化客户端有多种.这里我们选择使用yanagishima-20.0版本
- 将yanagishima-20.0.zip安装包上传至linux121服务器上
- 解压yanagishima-20.0.zip安装包
| Shell [root@linux121 software]# unzip yanagishima-20.0.zip -d /opt/servers |
|---|
- 进入到/opt/servers/yanagishima-20.0/conf/目录下,修改yanagishima.properties配置文件
| Shell [root@linux121 conf]# vim yanagishima.properties #可以删除原文件的内容,然后重新填入下面的内容 #指定jetty的端口,类似tomcat的web容器的一个组件 jetty.port=8080 #指定数据源 presto.datasources=presto_test presto.coordinator.server.presto_test=http://linux121:7788 catalog.presto_test=hive schema.presto_test=ods sql.query.engines=presto |
|---|
- 启动yanagishima
| Shell [root@linux121 yanagishima-20.0]# nohup bin/yanagishima-start.sh 1>/dev/null 2>&1 & |
|---|
- webUI访问界面
1.6 附录(补充知识)
1.6.1 使用新版的Presto为其单独配置jdk11
在presto的各集群节点上安装jdk11.0.9(注意不要配置jdk11的JAVA_HOME.这里是在/opt/servers/jdk-11.0.9目录下.然后在$PRESTO_HOME/bin/launcher文件中增加下面1行参数:
| Shell PATH=/opt/servers/jdk-11.0.9/bin/:$PATH |
|---|
注意:一定要加在exec “$(dirname “$0”)/launcher.py” “$@”之前!!!
然后按照上面的配置好之后,就可启动presto了.
1.6.2 修改Presto访问HDFS的用户名
当Kerberos没有与HDFS一起使用时,Presto默认将使用启动Presto进程的OS用户访问HDFS(即操作系统用户).例如,如果Presto是以root用户运行的 ,它访问HDFS的权限即为root用户的权限.如果需要修改该用户,可以在$PRESTO_HOME/etc/jvm.config中设置系统属性来覆盖默认使用的用户.比如以xiaobai用户来访问,增加如下:
| Shell -DHADOOP_USER_NAME=xiaobai |
|---|
1.6.3 Presto-338版本之前查询MySQL时可能遇到的Bug
在实际场景中,我们对于smallint,int等整数类型的值都是使用的无符号类型的,所以它存的值比标准的会大一倍.这时如果使用Presto查询时可能会遇到”outside valid range…的错误”.这个问题在338版本中被修复,具体可参考github的代码:
https://github.com/trinodb/trino/commit/ed1c554acf31db6bab9d2f971419e798ab15289a
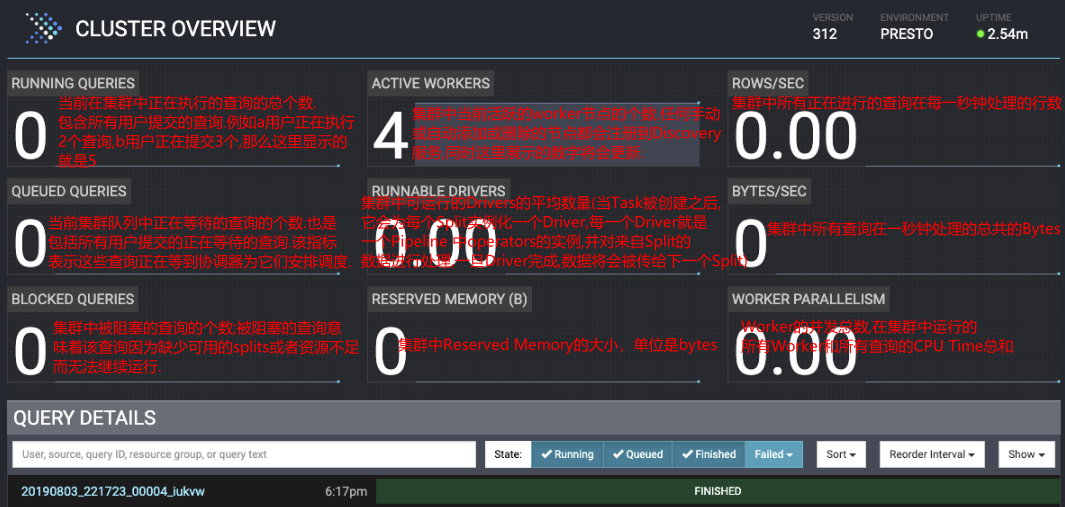
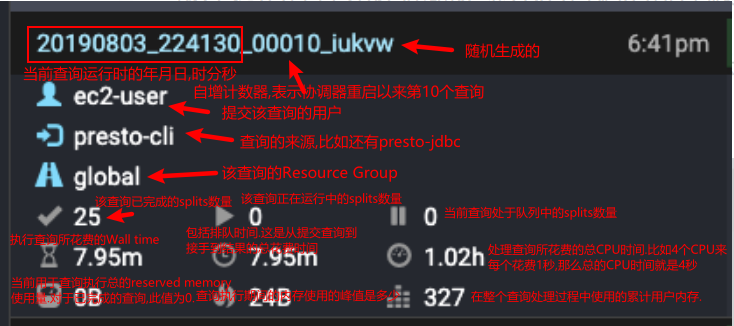
1.6.4 Presto WebUI监控页面的含义
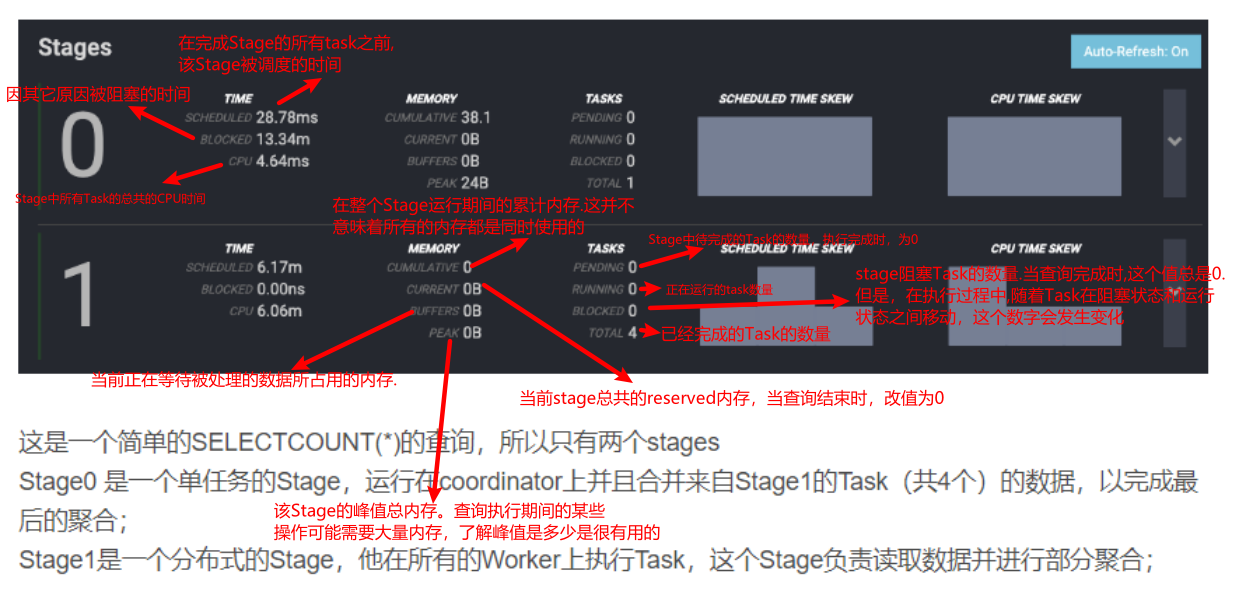
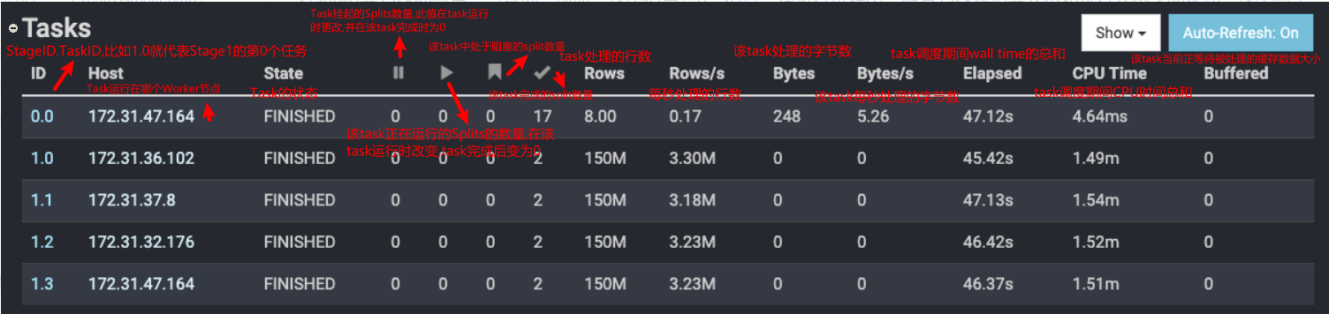
1.6.5 使用Presto sql实现几个常见的SQL场景
场景1: 分组求topN
| SQL —1.在hive的test库下车间presto1表 create table hive.test.presto1( “sid” int comment ‘学生id’, “sname” varchar(50) comment ‘学生姓名’, “cname” varchar(50) comment ‘班级名称’, “total_score” int comment ‘考试总分’ ) ; —2.往表中插入数据 insert into hive.test.presto1 values(1101,’孙悟空’,’1班’,500),(1102,’猪八戒’,’1班’,600),(1103,’如来佛祖’,’1班’,600) ,(1104,’观音菩萨’,’2班’,480),(1105,’姜子牙’,’2班’,500),(1106,’李达康’,’2班’,550) ,(1107,’王瞎子’,’3班’,500),(1108,’姜子牙’,’3班’,500),(1109,’凤姐’,’3班’,550),(1110,’张无忌’,’3班’,480) ; —3.查看数据 select * from hive.test.presto1; —4.计算出每个班级总分排在前2名的学生信息(分数相同就名次并列.如果第一名有2个并列,那么分数第2的就排名第3了).语法与hive一模一样 select sid ,sname ,cname ,total_score from ( select sid ,sname ,cname ,total_score ,rank() over(partition by cname order by total_score desc) as dn from hive.test.presto1 )t1 where dn<=2 ; |
|---|
场景2: 求连续
| SQL —1.创建hive.test.presto2表 create table hive.test.presto2( “user_id” int comment ‘用户id’, “login_time” varchar(50) comment ‘登陆时间.精确到秒’ ) ; —2.往表中插入数据 insert into hive.test.presto2 values(1001,’2020-12-30 12:10:15’),(1001,’2020-12-30 13:10:15’),(1001,’2020-12-31 10:00:00’),(1001,’2021-01-01 15:00:00’) ,(1002,’2020-12-25 12:10:15’),(1002,’2020-12-26 13:10:15’),(1002,’2020-12-27 10:00:00’) ,(1003,’2020-12-25 12:08:50’),(1003,’2020-12-25 13:10:15’),(1003,’2020-12-26 10:00:00’),(1003,’2020-12-26 11:00:00’),(1003,’2020-12-28 18:00:00’) ; —3.查询表的数据 select * from hive.test.presto2 order by user_id,login_time; —4.求出连续3天都有登陆的用户id(语法与hive有一些区别) select distinct user_id from ( select user_id ,date_add(‘day’,-rn,date(login_date)) as date_diff from ( select user_id ,login_date ,row_number() over(partition by user_id order by login_date) as rn from ( select user_id ,format_datetime(cast(login_time as timestamp),’yyyy-MM-dd’) as login_date from hive.test.presto2 group by user_id,format_datetime(cast(login_time as timestamp),’yyyy-MM-dd’) )t1 )t2 )t3 group by user_id,date_diff having count(user_id)>=3 ; |
|---|
说明:写sql使用的工具是dbeaver连接presto.

若有收获,就点个赞吧
0 人点赞
