20200514
1.你们框架工作流用的是?
activity工作流
2.自定义注解了解嘛?说说自定义注解吧
3.聊聊spring ioc和aop吧
beanFactory和factoryBean的区别?
4.说下HashMap
5.对mysql的索引了解嘛?除了B+树外还有没有其他的方式了?为什么使用B+树?
除了B+树外还有hash的方式,hash以Key/value的方式计算,复杂度O(1),效率非常高,但是他不支持排序和范围查找,还有一个hash冲突的问题。
要说为什么使用b+树,这个要从二叉树和平衡二叉树说起,二叉树的性质是左子树的键值小于根的键值,右子树的键值大于根的键值,但是容易出现单链或者深度差过大的情况,这时候我们可以使用平衡二叉树来代替二叉树,平衡二叉树左右子树的深度差不会超过1;B树(多路平衡查找树)是为磁盘等外存储设备设计的一种平衡查找树,在Innodb中,读取一次加载磁盘的最小单位是page,就是页,默认16KB的大小,就是每次读取至少读16KB的大小(磁盘预读、局部性的原理),这里读取一次磁盘块,就发生了一次磁盘的I/O,硬盘中发生I/O操作又有寻址的时间,这个是非常耗时的。为了不造成空间和时间上的浪费,在每一个节点上,我们需要存储更多的键值和指针(这里不再是二叉了,而是多叉),这样子使得读取的空间不在浪费,也有效的解决了树的深度问题,使得IO的次数减少了。
如下图所示,B树中我们会在每个节点上存储我们的键值、磁盘地址、指针。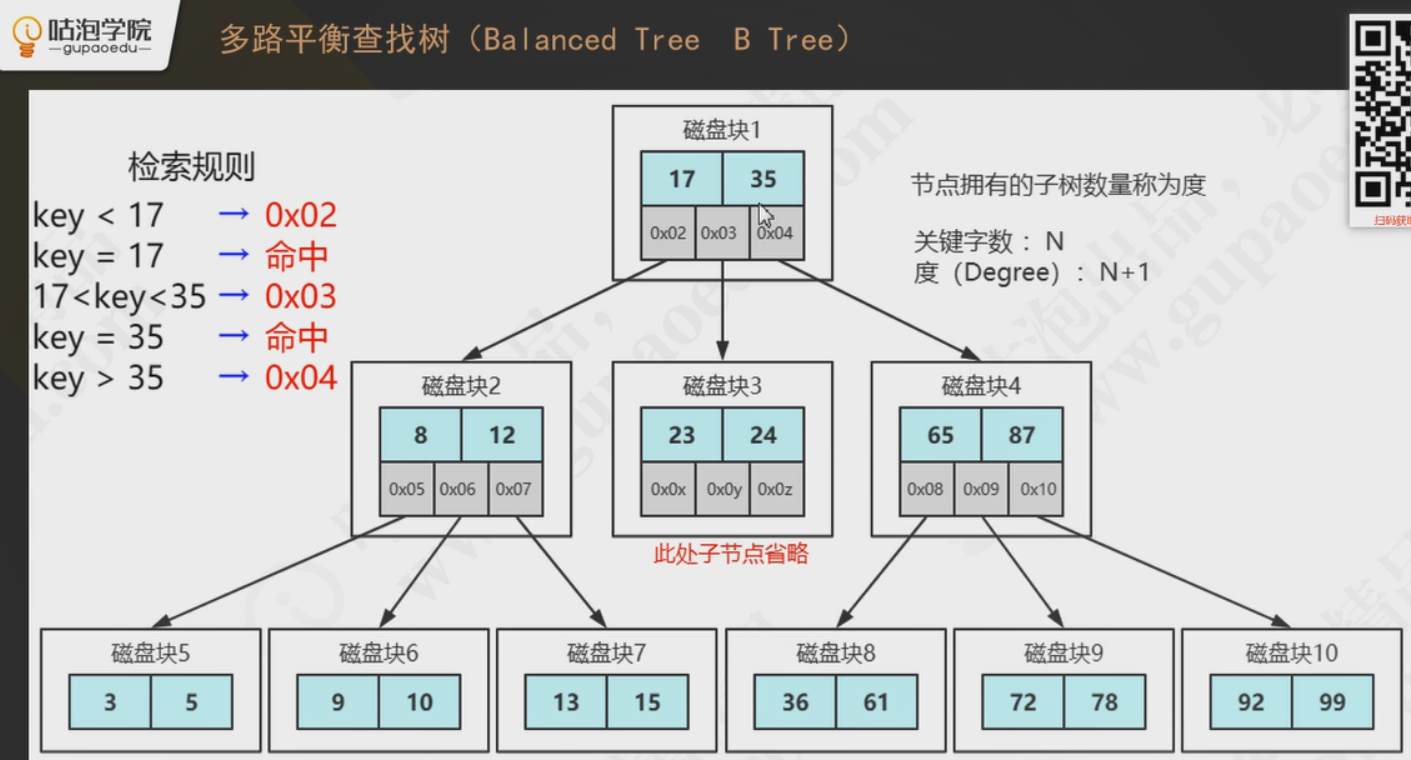
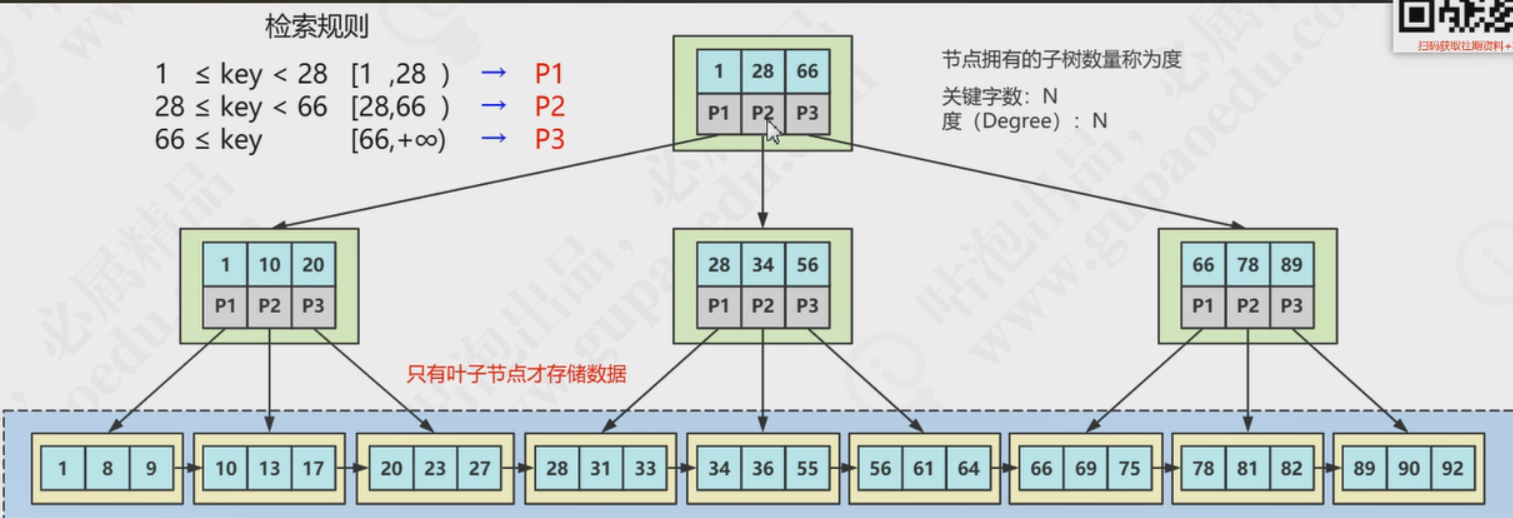
B+树是加强版的多路平衡查找树,算是B树的加强版,1.他的关键字数量和度(分叉)是相等的,所以存的东西更多了,可以进一步的降低我们的深度;2.他在根节点和支节点都不会存放数据(只存了键值和左右子树的指针),只有叶子节点才存储数据;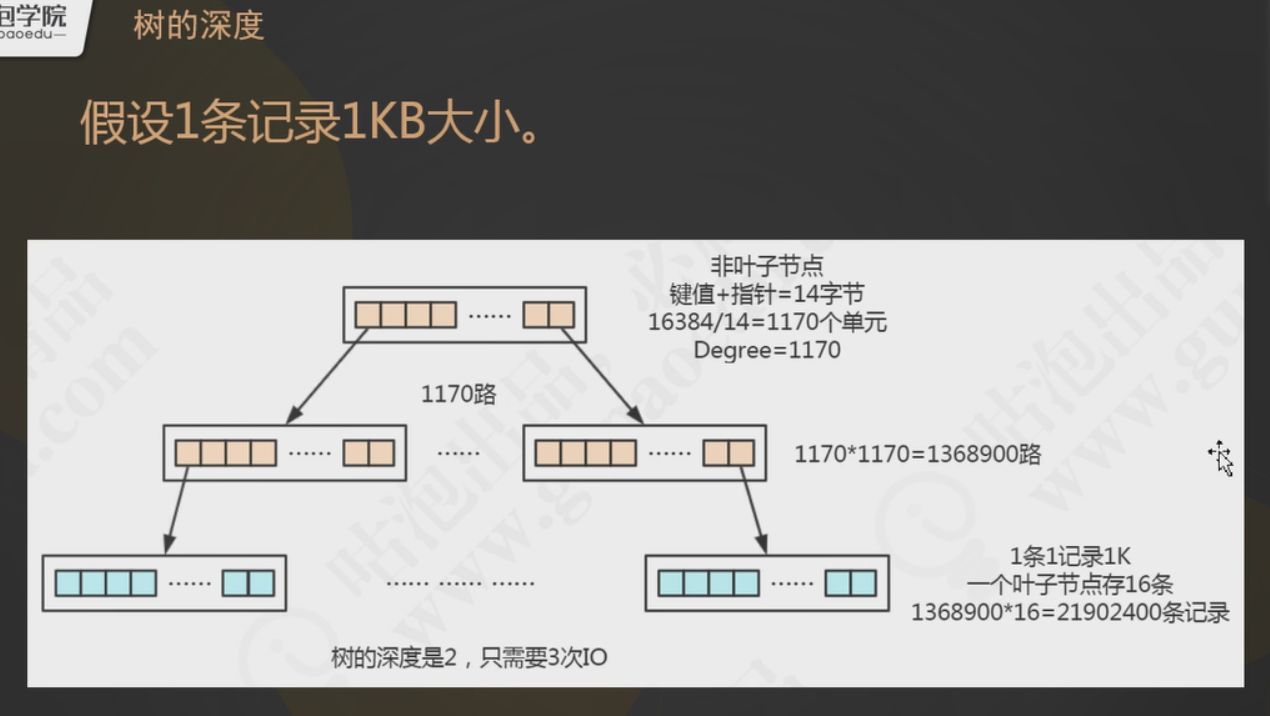
B+树的特点:
1.B树解决了ALV的深度问题,这点在B+树上得到了更好的体现,毕竟他只在叶子节点存储数据,根支上能存的东西更多;
2.他的扫库扫表能力更强了,因为如果全表扫描拿完整数据的话,他只需要遍历叶子节点就可以了;
3.磁盘读写能力更强,他把所有的存储数据都放在叶子节点上,那么我们的内节点里面就可以存储更多的键值、指针数据,所以他的IO深度会更低,磁盘读写能力更强;
4.排序能力更强,他的叶子节点本来就是有序的数组,基于索引去order by或者使用大于小于去查的时候自然效率就更高;
5.效率也更加稳定 。所有的数据都在叶子节点上,对于任意数据的查找都是要经过相同次数的IO;
备注:
详细也可以看这篇文章:https://blog.csdn.net/itguangit/article/details/82153891
顺便说下红黑树一般用于内存的数据结构中,B+树一般是磁盘的数据结构中
拓展:存储引擎
存储引擎:决定我们数据的管理方式,常见的有Innodb、mylsam、archive、memory等;
看实际使用情况,如果是把我们的数据放到内存中,可以使用memory的存储引擎;如果是归档的历史数据,不怎么查询(没必要用索引) 这个时候就可以用archive的存储引擎;如果数据的增删改查很多,实时级别很高,要支持索引,支持外键等,这个时候就要用我们的innodb的存储引擎了;
myIsam的存储引擎:
主键索引,他会把完整的磁盘地址放在B+树的叶子节点上,我们通过树找到相应的磁盘地址,在去磁盘中找相应的数据信息,在myISAM中,他的主键索引和辅助索引的检索方式一模一样;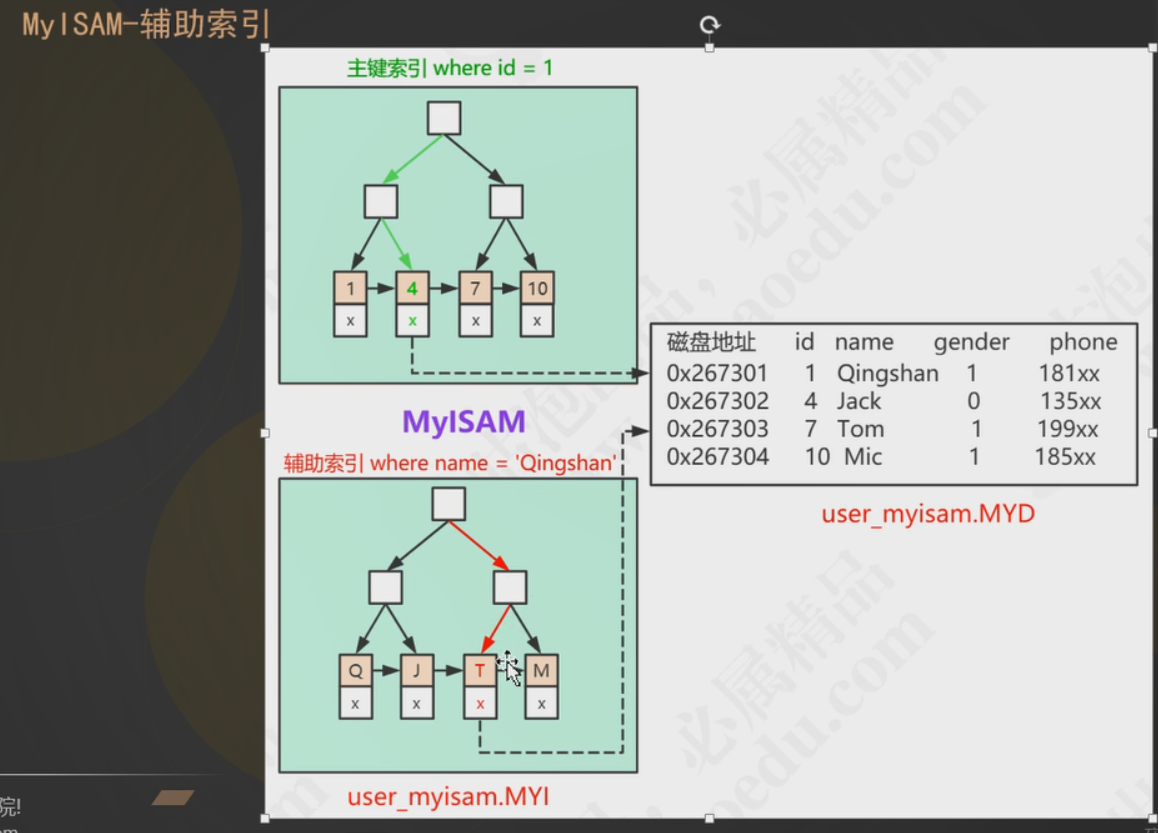
Innodb存储引擎:
主键索引,他的数据就是索引,索引就是数据,他把完整的数据放在了树的叶子节点上,注意:完整的数据只会放在主键索引的B+树里面。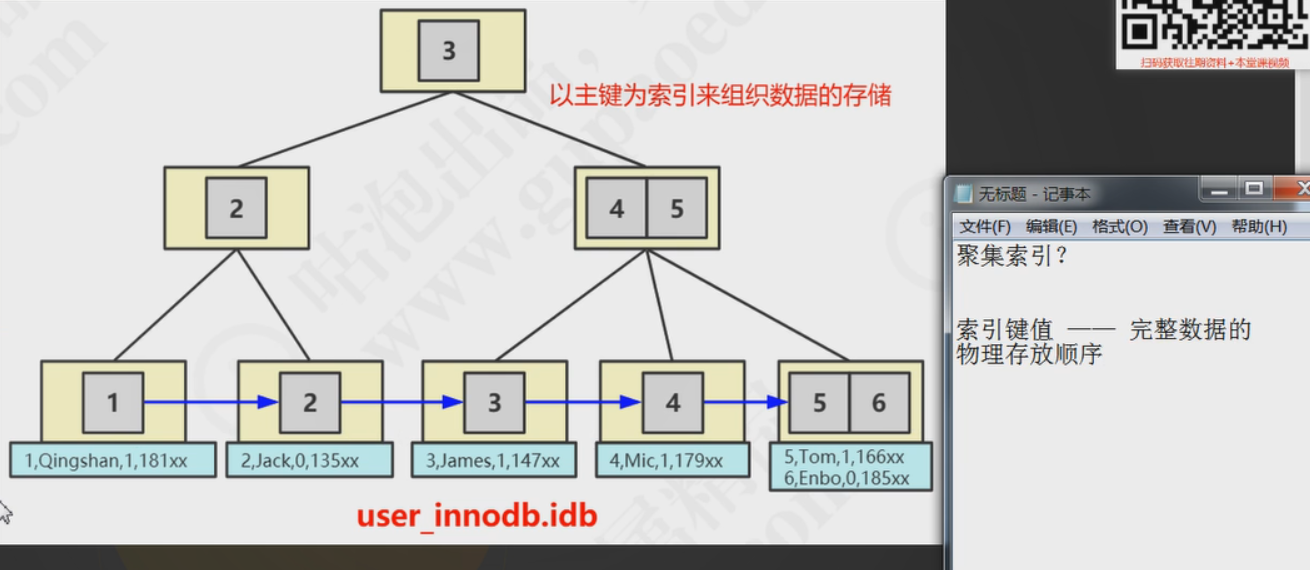
辅助索引的话要怎么拿到完整数据呢?辅助索引的叶子节点上存放的是自己的这个字段的值以及对应主键的值,然后通过主键索引去主键索引的B+树里面去查找相应的完整数据返回给客户端。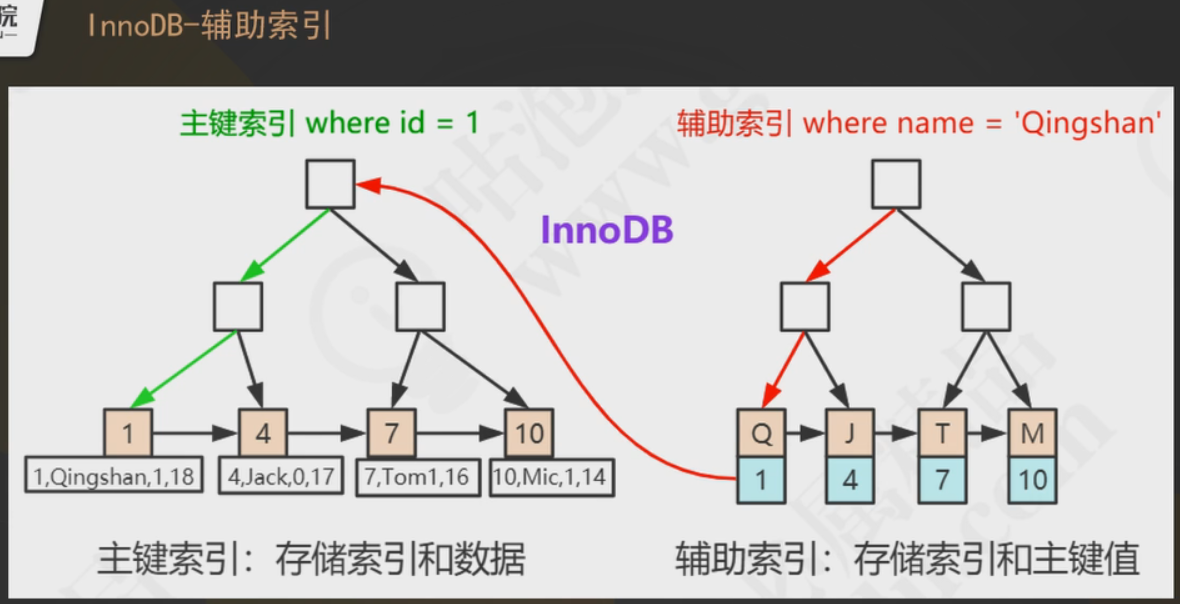
如果没有主键索引怎么办? 看下面的拓展,聚集索引那里。
拓展:
什么是聚集索引,为什么使用自增ID,索引的本质到底是什么,为什么存在最左前缀原则,一条sql到底什么时候走索引,什么时候走全表扫描?
聚集索引:索引的键值与完整数据的物理存放顺序一致的时候,如字典里面,字是按拼音排序的,目录有拼音,笔画,部首,所以在这个字典中,拼音的索引就是聚集索引。
所以在Innodb中,1.如果创建主键索引,那主键索引就是聚集索引,2.如果没有主键索引,那么他会将第一个键值中没有null值的唯一索引作为聚集索引。3.如果没有主键索引也没有唯一索引,那么他将使用一个隐藏的列(rowid)将其作为聚集索引。其他的索引都是非聚集索引。
索引的创建和使用原则:列的离散度,离散度越高,越适合创建索引。 离散度低的字段没有必要去创建索引。
联合索引:ALTER TABLE user_innodb(表名) add INDEX comidx_name_phone(索引名称) (name,phone) (对应的字段)。
联合索引最左匹配原则:他是基于最左边的数据的值去构建我们的B+树的结构,联合索引他的B+树是一个复合的结构。他只有用到最左边的字段开始查询的时候他才能用到我们的索引。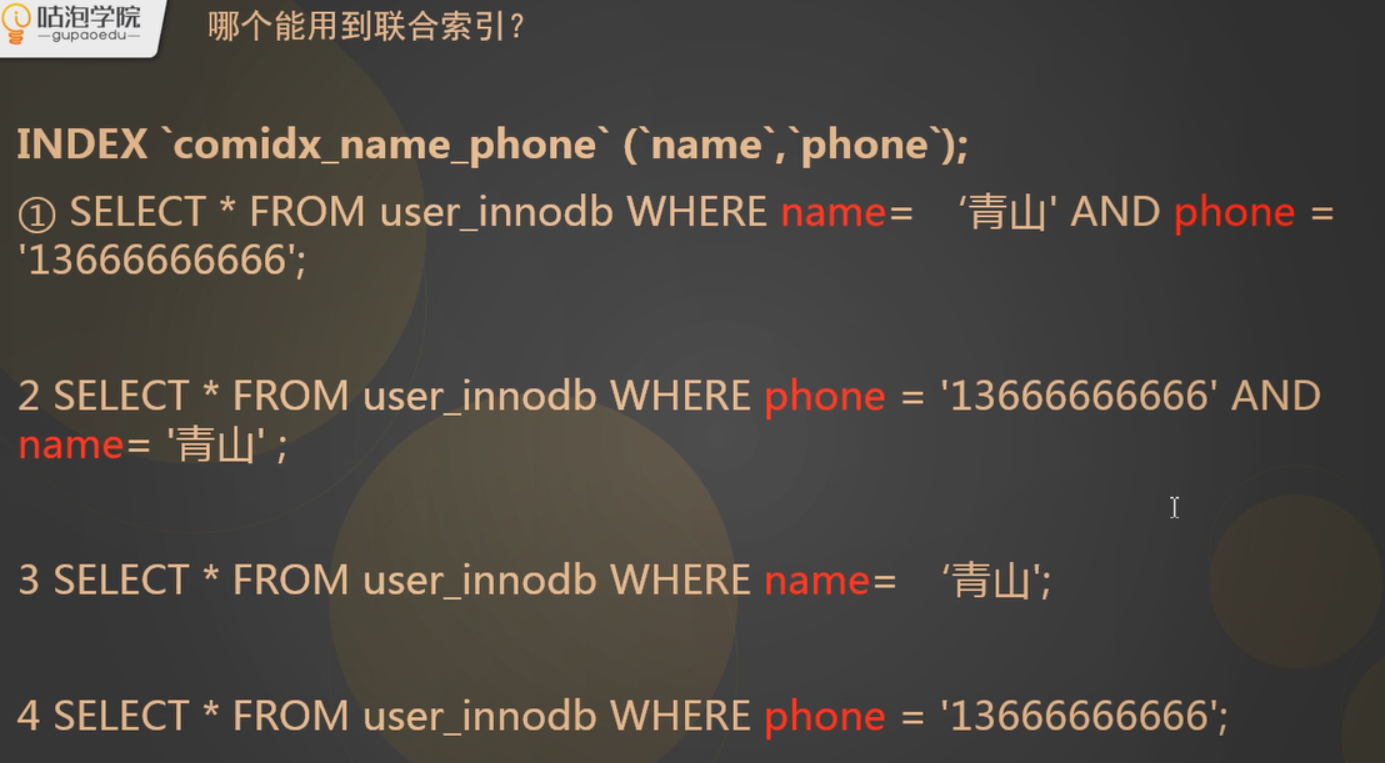
上图中。1、2 、3都可以用到我们的联合索引;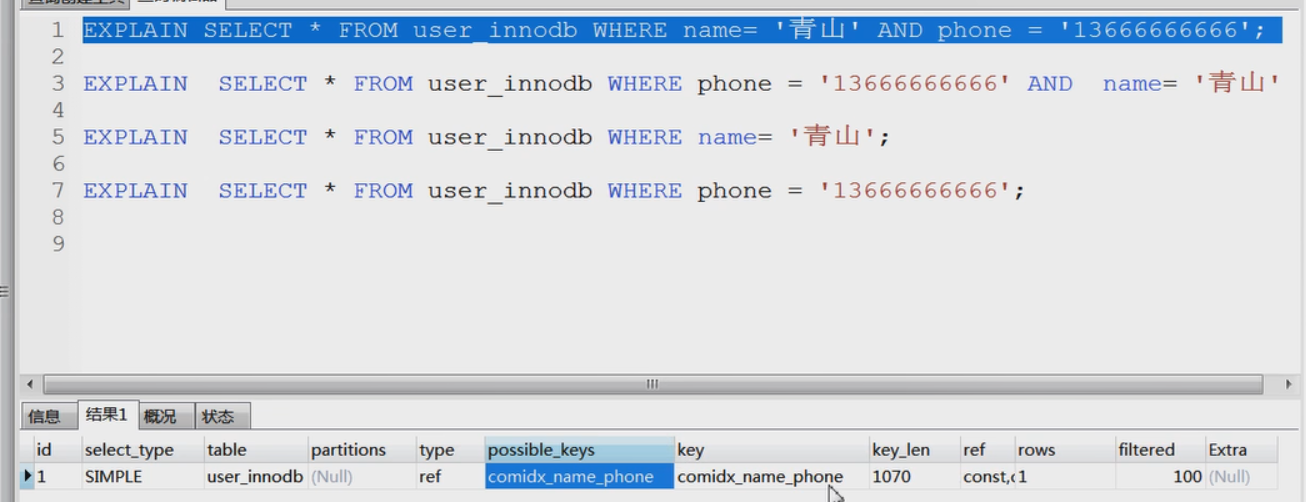
回表和覆盖索引?
用非主键索引去查数据时,如果select的列不包含在索引中的时候,会存在回表的问题,可以看上面辅助索引的图。所以在结果集里,如果只需要一个值,那么就结果集就只写那个值最好。
select 要查的列已经包含在使用的索引中的时候就是覆盖索引,出现覆盖索引的话就不会出现回表的情况。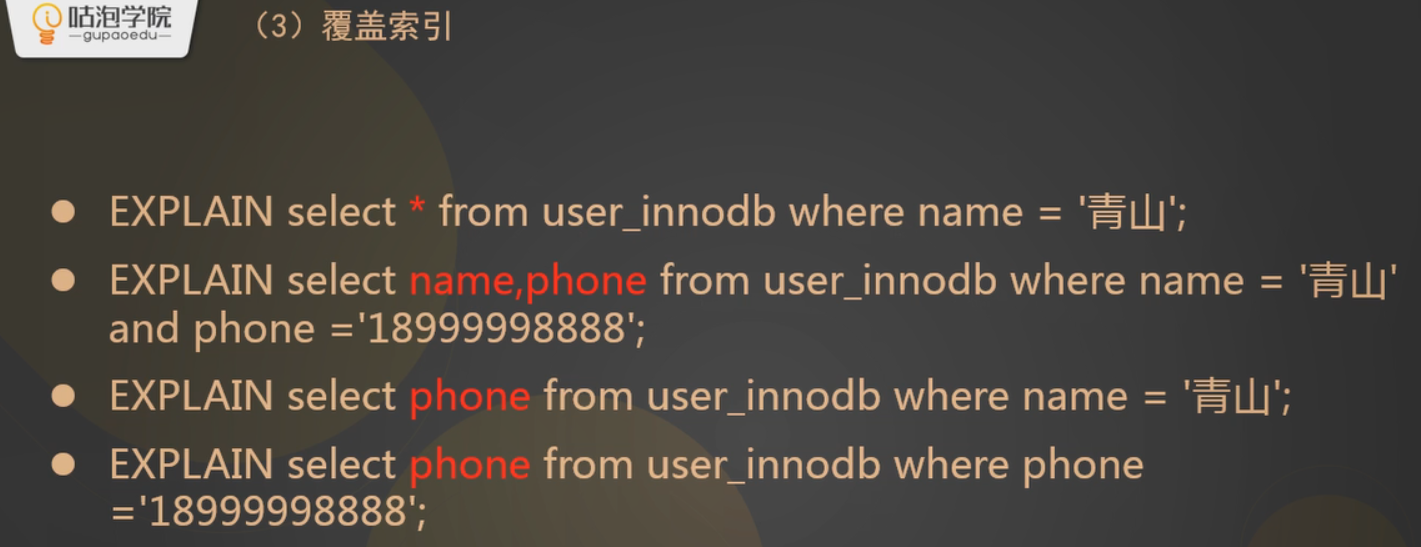
看上面的几个方式,2,3,4都会使用覆盖索引,视频110分钟左右,4本来不会用到索引的情况,因为这里我们只创建了联合索引,他违反了联合索引的最左匹配原则,但是实际操作的时候被我们的优化器优化了,为了不回表,强行用了那个联合索引实现了覆盖索引,应该是优化器觉得用右边那个比回表的代价小一点吧。
注意:我们不要在索引列使用函数或者表达式、计算;不要让索引列做字段转换,字符串列该加引号要加引号(切记);like前面不要加%。以上三种都会导致优化器不走索引。
在数据库中,最终用不用索引,是优化器说了算,所以有时候not in 和<>也可能用到,但是语句中特别是索引列能不出现not in 和<>还是不要出现比较好。
优化器规则:基于成本和开销的优化器,基于规则的优化器
20200518-20200522面试
web容器的监听器、过滤器和servlet的加载顺序?
监听器—>过滤器—>Servlet
如何防止别人恶意调用api接口?
1.验证码(最简单有效的防护),采用点触验证,滑动验证或第三方验证码服务,普通验证码很容易被破解;
2.频率,限制同设备,同IP等发送次数,单点时间范围可请求时长;
3.归属地,检测IP所在地是否与手机号归属地匹配;IP所在地是否是为常在地;
4.可疑用户,对于可疑用户要求其主动发短信(或其他主动行为)来验证身份;
5.黑名单,对于黑名单用户,限制其操作,API接口直接返回success,1可以避免浪费资源,2混淆黑户判断;
6.签名,API接口启用签名策略,签名可以保障请求URL的完整安全,签名匹配再继续下一步操作;
7.token,对于重要的API接口,生成token值,做验证;
8.https,启用https,https 需要秘钥交换,可以在一定程度上鉴别是否伪造IP;
9.代码混淆,发布前端代码混淆过的包;
10. 风控,大量肉鸡来袭时只能受着,同样攻击者也会暴露意图,分析意图提取算法,分析判断是否为恶意 如果是则断掉;异常账号及时锁定;或从产品角度做出调整,及时止损;
11.数据安全,数据安全方面做策略,攻击者得不到有效数据,提高攻击者成本;
12. 恶意IP库,https://threatbook.cn/,过滤恶意IP;
说说数据库死锁和解决办法?
所谓死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
产生死锁的四个条件:
1.互斥条件:一个资源每次只能被一个进程使用;
2.请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
3.不剥夺条件:进程已获得资源,在未使用完之前,不能强行剥夺;
4.循环等待条件:若干进程之间形成一个头尾相接的循环等待资源关系;
这四个有一个不成立的话就不会造成死锁,然后关键条件看第四个,即死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。那么对应的解决死锁问题的关键就是:让不同的session加锁有次序,即按同一顺序访问对象。除此之外,还可以通过避免事务中的用户交互,保持事务简短并在一个批处理中,使用低隔离级别等
http协议的报文头?
https://www.cnblogs.com/lmh001/p/9928517.html
进程之间通信的方式,乱码问题怎么处理?
常见的有webservice,httpclient,rpc通信。这里讲下httpclient,其实会出现乱码问题,只要是使用的格式不对,两边都设置成utf-8可以解决,假如对面不确定,传输过来后是乱码的,我们这边需要做相应的转码,转码的话一般是使用下面的来进行一些处理吧
java.net.URLDecoder.decode(xing, “UTF-8”);
java.net.URLDecoder.decode(name, “UTF-8”)
https://blog.csdn.net/u012465296/article/details/53036205
关于httpclient,之前公司诉转案的系统中使用的是这种通信方式,我们调用万达的接口,之前先new一个HttpPost(Post请求),传入相应的url地址,然后构造实体消息设置entity为utf-8,然后构造消息头(这里最好是先构造消息头)为”text/xml;charset=utf-8”(讲道理现在的消息头用”application/json;charset=UTF-8”)。new一个httpClient,将之前的post请求传入,然后拿到我们要的结果。代码如下图所示
除此之外,还可以设置Header method.setHeader(“Accept”, “application/json”);
使用连接池的好处?
①资源重用 (连接复用)
由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,增进了系统环境的平稳性(减少内存碎片以级数据库临时进程、线程的数量)
②更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池内备用。此时连接池的初始化操作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
③新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接技术。
④统一的连接管理,避免数据库连接泄露
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用的连接,从而避免了常规数据库连接操作中可能出现的资源泄露
synchronized锁方法和锁代码块的区别?
主要还是粒度上的区别

若有收获,就点个赞吧
0 人点赞
