目录结构
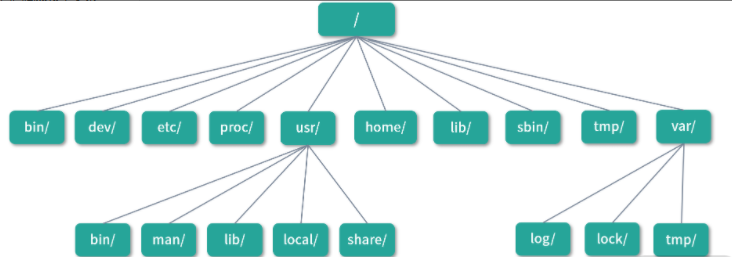
- 最顶层的目录称作根目录, 用/表示。/目录下用户可以再创建目录,但是有一些目录随着系统创建就已经存在,接下来我会和你一起讨论下它们的用途。
- /bin(二进制)包含了许多所有用户都可以访问的可执行文件,如 ls, cp, cd 等。这里的大多数程序都是二进制格式的,因此称作bin目录。bin是一个命名习惯,比如说nginx中的可执行文件会在 Nginx 安装目录的 bin 文件夹下面。
- /dev(设备文件) 通常挂载在devtmpfs文件系统上,里面存放的是设备文件节点。通常直接和内存进行映射,而不是存在物理磁盘上。
- 值得一提的是其中有几个有趣的文件,它们是虚拟设备。
- /dev/null是可以用来销毁任何输出的虚拟设备。你可以用>重定向符号将任何输出流重定向到/dev/null来忽略输出的结果。
- /dev/zero是一个产生数字 0 的虚拟设备。无论你对它进行多少次读取,都会读到 0。
- /dev/ramdom是一个产生随机数的虚拟设备。读取这个文件中数据,你会得到一个随机数。你不停地读取这个文件,就会得到一个随机数的序列。
- /etc(配置文件),/etc名字的含义是and so on……,也就是“等等及其他”,Linux 用它来保管程序的配置。比如说mysql通常会在/etc/mysql下创建配置。再比如说/etc/passwd是系统的用户配置,存储了用户信息。
- /proc(进程和内核文件) 存储了执行中进程和内核的信息。比如你可以通过/proc/1122目录找到和进程1122关联的全部信息。还可以在/proc/cpuinfo下找到和 CPU 相关的全部信息。
- /sbin(系统二进制) 和/bin类似,通常是系统启动必需的指令,也可以包括管理员才会使用的指令。
- /tmp(临时文件) 用于存放应用的临时文件,通常用的是tmpfs文件系统。因为tmpfs是一个内存文件系统,系统重启的时候清除/tmp文件,所以这个目录不能放应用和重要的数据。
- /var (Variable data file,,可变数据文件) 用于存储运行时的数据,比如日志通常会存放在/var/log目录下面。再比如应用的缓存文件、用户的登录行为等,都可以放到/var目录下,/var下的文件会长期保存。
- /boot(启动) 目录下存放了 Linux 的内核文件和启动镜像,通常这个目录会写入磁盘最头部的分区,启动的时候需要加载目录内的文件。
- /opt(Optional Software,可选软件) 通常会把第三方软件安装到这个目录。以后你安装软件的时候,可以考虑在这个目录下创建。
- /root(root 用户家目录) 为了防止误操作,Linux 设计中 root 用户的家目录没有设计在/home/root下,而是放到了/root目录。
- /home(家目录) 用于存放用户的个人数据,比如用户lagou的个人数据会存放到/home/lagou下面。并且通常在用户登录,或者执行cd指令后,都会在家目录下工作。 用户通常会对自己的家目录拥有管理权限,而无法访问其他用户的家目录。
- /media(媒体) 自动挂载的设备通常会出现在/media目录下。比如你插入 U 盘,通常较新版本的 Linux 都会帮你自动完成挂载,也就是在/media下创建一个目录代表 U 盘。
- /mnt(Mount,挂载) 我们习惯把手动挂载的设备放到这个目录。比如你插入 U 盘后,如果 Linux 没有帮你完成自动挂载,可以用mount命令手动将 U 盘内容挂载到/mnt目录下。
- /svr(Service Data,,服务数据) 通常用来存放服务数据,比如说你开发的网站资源文件(脚本、网页等)。不过现在很多团队的习惯发生了变化, 有的团队会把网站相关的资源放到/www目录下,也有的团队会放到/data下。总之,在存放资源的角度,还是比较灵活的。
/usr(Unix System Resource) 包含系统需要的资源文件,通常应用程序会把后来安装的可执行文件也放到这个目录下,比如说
文件系统实现原理
FAT 的设计简单高效,通过内存中一个类似链表的结构,实现对文件的管理,如果你要自己管理一定的空间,可以优先考虑这种设计
- inode 的设计在内存中创造了一棵树状结构,对文件、目录进行管理,并且索引到磁盘中的数据。这是一种经典的数据结构,这种思路会被数据库设计、网络资源管理、缓存设计反复利用
日志文件系统——日志结构简单、容易存储、按时间容易分块,这样的设计非常适合缓冲、批量写入和故障恢复,如NTFS、Ext3
索引
数据库要经常和磁盘与内存打交道,为了提升性能,通常需要自己去构建类似文件系统的结构。那么数据库如何利用磁盘空间设计索引?
行、列存储
行存储:优点很明显,更新快、单条记录的数据集中,适合事务。但缺点也很明显,查询慢
- 列存储:优势在查询和聚合运算
二叉搜索树
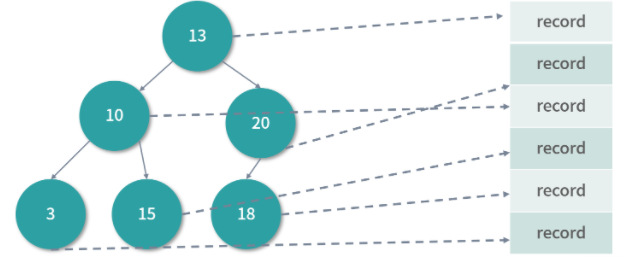
二叉搜索树是一个天生的二分查找结构,每次查找都可以减少一半的问题规模。而且二叉搜索树解决了插入新节点的问题,因为二叉搜索树是一个跳跃结构,不必在内存中连续排列。这样在插入的时候,新节点可以放在任何位置,不会像线性结构那样插入一个元素,所有元素都需要向后排列B树 & B+树
二叉搜索树解决了连续结构插入新元素开销很大的问题,同时又保持着天然的二分结构。但是,当需要索引的数据量很大,无法在一个磁盘 Block 中存下整棵二叉搜索树的时候。每一次递归向下的搜索,实际都是读取不同的磁盘块。这个时候二叉搜索树的开销很大。
试想一个一万亿条订单的表,进行 40 次查找找到答案,在内存中不是问题,要考虑到 CPU 缓存有 90% 以上的命中率(当然前提是内存足够大)。通常情况下我们没有这么大的内存空间,如果 40 次查找发生在磁盘上,也是非常耗时的。那么有没有更好的方案呢?
一个更好的方案,就是继续沿用树状结构,利用好磁盘的分块让每个节点多一些数据,并且允许子节点也多一些,树就会更矮。因为树的高度决定了搜索的次数。
B树
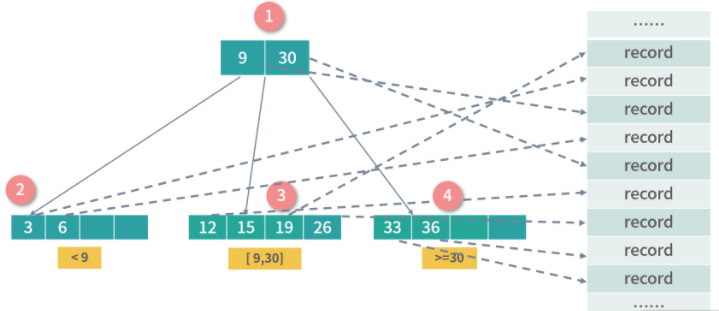
B-Tree 是一种递归的搜索结构,与二叉搜索树非常类似。不同的是,B 树中的父节点中的数据会对子树进行区段分割。比如上图中节点 1 有 3 个子节点,并用数字 9,30 对子树的区间进行了划分。
上图中的 B 树是一个 3-4 B 树,3 指的是每个非叶子节点允许最大 3 个索引,4 指的是每个节点最多允许 4 个子节点,4 也指每个叶子节点可以存 4 个索引。上面只是一个例子,在实际的操作中,子节点有几十个、甚至上百个索引也很常见,因为我们希望树变矮,好减少磁盘操作。
B 树的每个节点是一个索引条目(例如:一个 <订单 ID,序号> 的组合),如果是行数据库可以索引到一条存储在磁盘上的记录。
B+树(继承B树)
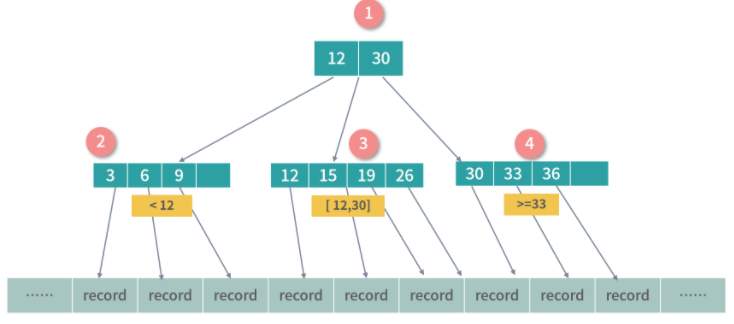
为了达到最高的效率,实战中我们往往使用的是一种继承于 B 树设计的结构,称为 B+ 树。B+ 树只有叶子节点才映射数据,下图中是对 B 树设计的一种改进,节点 1 为冗余节点,它不存储数据,只划定子树数据的范围。你可以看到节点 1 的索引 Key:12 和 30,在节点 3 和 4 中也有一份。总之,B+ 树的插入和删除效率更高。
HDFS(Hadoop Distributed File System分布式文件系统)
分布式文件系统通过网络将不同的机器、磁盘、逻辑分区等存储资源利用起来,提供跨平台、跨机器的文件管理。通过这种方式,我们可以把很多相对廉价的服务器组合起来形成巨大的存储力量,如Google的BigTable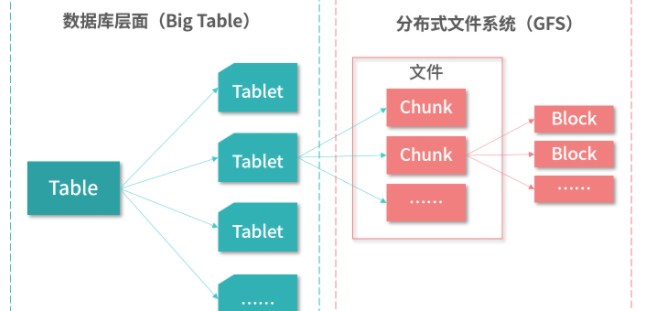
容灾备份
为了保证可用性,我们增加了备用节点待命,随时替代活动节点。为了达成这个目标。有 3 类数据需要同步。
- 数据节点同步给主节点的日志。这类数据由数据节点同时同步给活动、待命节点
- 活动节点同步给待命节点的操作记录。这类数据由活动节点同步给日志节点,再由日志节点同步给待命节点。日志又至少有 3 态机器的集群保管,每个上放一个日志节点
- 记录节点本身状态的数据(比如节点有没有心跳)。这类数据存储在分布式应用协作引擎上,比如 ZooKeeper
有了这样的设计,当活动节点发生故障的时候,只需要迅速切换节点即可修复故障。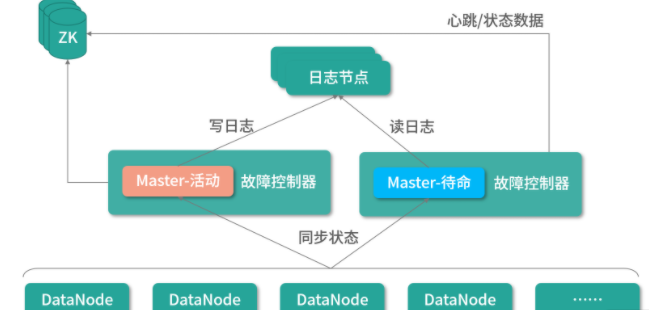
总结
- 理解虚拟文件系统的设计,理解在一个目录树结构当中,可以拥有不同的文件系统——一切皆文件的设计。基于这种结构,设备、磁盘、分布式文件系、网络请求都可以是文件
- 将空间分块管理是一种高效的常规手段。方便分配、方便回收、方便整理——除了文件系统,内存管理和分布式文件系统也会用到这种手段
- 日志文件系统的设计是重中之重,日志文件系统通过空间换时间,牺牲少量的读取性能,提升整体的写入效率。除了单机文件系统,这种设计在分布式文件系统和很多数据库当中也都存在
- 分层架构:将数据库系统、分布式文件系搭建在单机文件管理之上——知识是死的、思路是活的。希望你能将这部分知识运用到日常开发中,提升自己系统的性能

若有收获,就点个赞吧
0 人点赞
