虚拟内存
程序越复杂,那么进程对内存的需求就会越大,且从安全角度考虑,进程间使用内存需要隔离
交换(Swap)
允许一部分进程使用内存,不使用内存的进程数据先保存在磁盘,等轮到某个进程执行的时候,尝试为其开辟一块空闲内存区域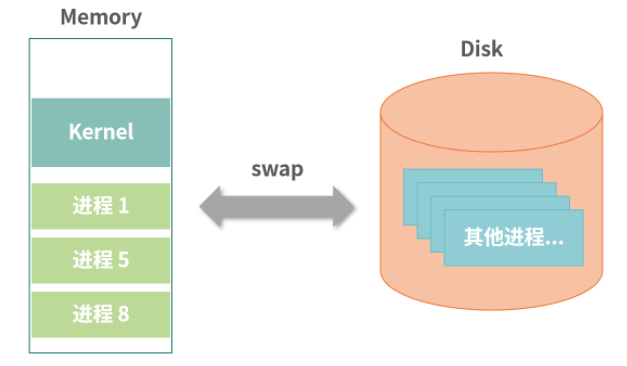
缺陷:内存碎片化:来回切换进程使用、回收内存时,产生空白内存缝隙,导致性能下降
分页
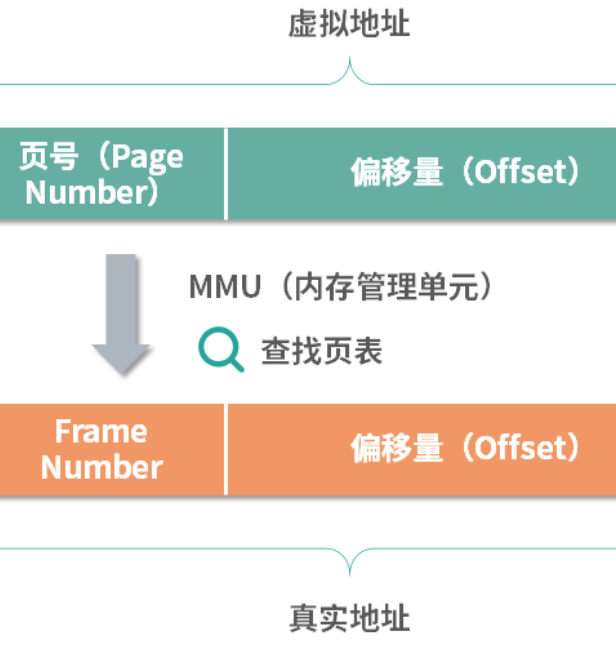
你可以把虚拟地址看成由页号和偏移量组成,把物理地址看成由 Frame Number 和偏移量组成。在 CPU 中有一个完成虚拟地址到物理地址转换的小型设备,叫作内存管理单元(Memory Management Unit(MMU)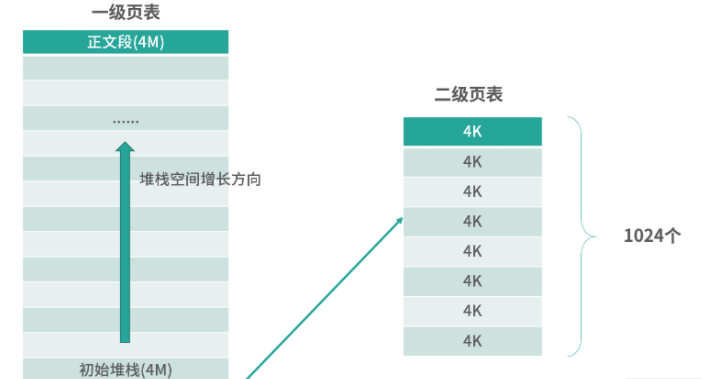
在程序执行的时候,指令中的地址都是虚拟地址,虚拟地址会通过 MMU,MMU 会查询页表,计算出对应的 Frame Number,然后偏移量不变,组装成真实地址。然后 MMU 通过地址总线直接去访问内存。所以 MMU 承担了虚拟地址到物理地址的转换以及 CPU 对内存的操作这两件事情
MMU(内存管理单元)
当 CPU 需要执行一条指令时,如果指令中涉及内存读写操作,CPU 会把虚拟地址给 MMU,MMU 自动完成虚拟地址到真实地址的计算;然后,MMU 连接了地址总线,帮助 CPU 操作真实地址
这样的设计,就不需要在编写应用程序的时候担心虚拟地址到物理地址映射的问题。我们把全部难题都丢给了操作系统——操作系统要确定MMU 可以读懂自己的页表格式。所以,操作系统的设计者要看 MMU 的说明书完成工作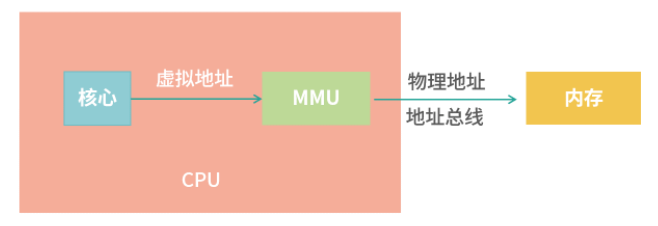
总之,低频使用的页保存虚拟内存中,高频使用的页保存到真实内存中
TLB (转置检测缓冲区)
作用就是根据输入的 Page Number,找到 Frame Number,每个缓存行可以看作一个映射,TLB 的缓存行将 Page Number 映射到 Frame Number,通常我们设计这种基于缓存行(Cache Line)的缓存有 3 种映射方案:
- 全相联映射(全部遍历)
- 直接映射(哈希表,核心要解决TLB Miss问题,类似LRU置换算法,将高频缓存持久化)
- n路组相连映射(组相连允许一个虚拟页号映射固定n个位置)
所谓相联(Associative),讲的是缓存条目和缓存数据之间的映射范围。如果是全相联,那么一个数据,可能在任何条目。如果是组相联(Set-Associative),意味对于一个数据,只能在一部分缓存条目中出现(比如前 4 个条目)
大内存分页
内存回收(GC)
进程内存使用过多,有很多无效内存占用,如果被占满,系统性能将就会雪崩式下降,解决办法:
- 引用计数(如果有对象引用则+1,没有计数为0,容易产生碎片,相互引用时容错能力差)
- Root Tracing算法(查找引用链路,从根集合利用DFS或者BFS遍历所有子节点,例如标记清除、三色标记)
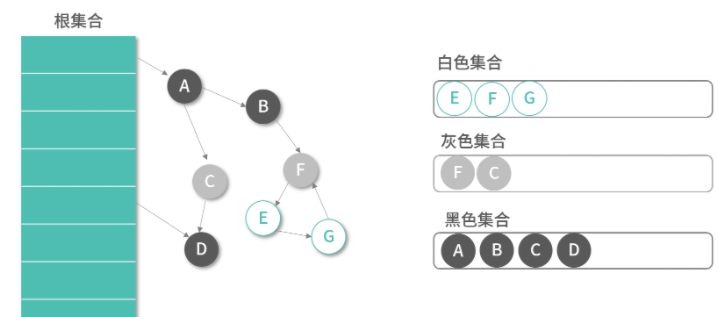
通常选择 GC 会有实时性要求(最大容忍的暂停时间),需要从是否为高并发场景、内存实际需求等维度去思考。在选择 GC 的时候,复杂的算法并不一定更有效。下面是一些简单有效的思考和判断:
- 如果你的程序内存需求较小,GC 压力小,这个时候每次用双色标记-清除算法,等彻底标记-清除完再执行应用程序,用户也不会感觉到多少延迟。双色标记-清除算法在这种场景可能会更加节省时间,因为程序简单
- 对于一些对暂停时间不敏感的应用,比如说数据分析类应用,那么选择一个并发执行的双色标记-清除算法的 GC 引擎,是一个非常不错的选择。因为这种应用 GC 暂停长一点时间都没有关系,关键是要最短时间内把整个 GC 执行完成
- 如果内存的需求大,同时对暂停时间也有要求,就需要三色标记清除算法,让部分增量工作可以并发执行
- 如果在高并发场景,内存被频繁迭代,这个时候就需要生代算法。将内存划分出不同的空间,用作不同的用途
- 如果实时性要求非常高,就需要选择专门针对实时场景的 GC 引擎,比如 Java 的 Z

若有收获,就点个赞吧
0 人点赞
