环境:
Flume 1.9.0+cdh6.3.2
HDFS 3.0.0+cdh6.3.2
背景:
最近数仓的同事对经Flume采集的数据利用MR引擎计算导致任务报错,查看失败的Map端日志如下:
Error: java.io.IOException: java.io.IOException: java.io.EOFException: Unexpected end of input stream at org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderNextException(HiveIOExceptionHandlerChain.java:121) at org.apache.hadoop.hive.io.HiveIOExceptionHandlerUtil.handleRecordReaderNextException(HiveIOExceptionHandlerUtil.java:77) at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.doNextWithExceptionHandler(HadoopShimsSecure.java:232) at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.next(HadoopShimsSecure.java:142) at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.moveToNext(MapTask.java:205) at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.next(MapTask.java:191) at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:52) at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:465) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168) Caused by: java.io.IOException: java.io.EOFException: Unexpected end of input stream at org.apache.hadoop.hive.io.HiveIOExceptionHandlerChain.handleRecordReaderNextException(HiveIOExceptionHandlerChain.java:121) at org.apache.hadoop.hive.io.HiveIOExceptionHandlerUtil.handleRecordReaderNextException(HiveIOExceptionHandlerUtil.java:77) at org.apache.hadoop.hive.ql.io.HiveContextAwareRecordReader.doNext(HiveContextAwareRecordReader.java:365) at org.apache.hadoop.hive.ql.io.CombineHiveRecordReader.doNext(CombineHiveRecordReader.java:116) at org.apache.hadoop.hive.ql.io.CombineHiveRecordReader.doNext(CombineHiveRecordReader.java:43) at org.apache.hadoop.hive.ql.io.HiveContextAwareRecordReader.next(HiveContextAwareRecordReader.java:116) at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileRecordReader.doNextWithExceptionHandler(HadoopShimsSecure.java:229) … 11 more Caused by: java.io.EOFException: Unexpected end of input stream at org.apache.hadoop.io.compress.DecompressorStream.decompress(DecompressorStream.java:165) at org.apache.hadoop.io.compress.DecompressorStream.read(DecompressorStream.java:105) at java.io.InputStream.read(InputStream.java:101) at org.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:182) at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:218) at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176) at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:255) at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:48) at org.apache.hadoop.hive.ql.io.HiveContextAwareRecordReader.doNext(HiveContextAwareRecordReader.java:360) … 15 more

问题定位:
“Unexpected end of input stream at” 关键字在这里,表示”输入流的意外结束” ,OK这里去zcat 上图Map Task中读取的文件,这里也提示“意外的文件结束”:
接下来看看Flume写到HDFS的文件为什么会缺失,首先查看Flume Agent的日志:
2021-01-26 21:46:36,981 INFO org.apache.flume.sink.hdfs.BucketWriter: Creating hdfs://nameservice1/user/hive/warehouse/ods.db/ods_ebike_report_json_day_append/event_day= 20210126/olap-flume-2.xxx.com.1611590400190.gz.tmp
2021-01-26 22:27:36,437 INFO org.apache.hadoop.hdfs.DataStreamer: Exception in createBlockOutputStream blk_1252864269_179191614 java.io.IOException: Got error, status=ERROR, status message , ack with firstBadLink as 10.xx.xx.216:9866 at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:134) at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:110) at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1778) at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1679) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716) 2021-01-26 22:27:36,437 WARN org.apache.hadoop.hdfs.DataStreamer: Abandoning BP-197609424-10.100.XXX-XX-XXXX012421057:blk_1252864269_179191614 2021-01-26 22:27:36,479 WARN org.apache.hadoop.hdfs.DataStreamer: Excluding datanode DatanodeInfoWithStorage[10.xx.xx.216:9866,DS-6fd6f773-dcf8-4eec-839a-eaad8dd9a065,DISK] 2021-01-26 22:27:36,479 WARN org.apache.hadoop.hdfs.DataStreamer: DataStreamer Exception java.io.IOException: Unable to create new block. at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1694) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716) 2021-01-26 22:27:36,479 WARN org.apache.hadoop.hdfs.DataStreamer: Could not get block locations. Source file “/user/hive/warehouse/ods.db/ods_ebike_report_json_day_append/event_day=20210126/olap-flume-2.xxx.com.1611590400190.gz.tmp” - Aborting…block==null 2021-01-26 22:27:36,482 WARN org.apache.hadoop.hdfs.DFSClient: Error while syncing java.io.IOException: Could not get block locations. Source file “/user/hive/warehouse/ods.db/ods_ebike_report_json_day_append/event_day=20210126/olap-flume-2.xxx.com.1611590400190.gz.tmp” - Aborting…block==null at org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1477) at org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1256) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:667) 2021-01-26 22:27:36,484 ERROR org.apache.flume.sink.hdfs.AbstractHDFSWriter: Error while trying to hflushOrSync!
2021-01-26 22:27:36,484 WARN org.apache.flume.sink.hdfs.HDFSEventSink: HDFS IO error java.io.IOException: Could not get block locations. Source file “/user/hive/warehouse/ods.db/ods_ebike_report_json_day_append/event_day=20210126/olap-flume-2.xxx.com.1611590400190.gz.tmp” - Aborting…block==null
at org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1477)at org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1256)at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:667)2021-01-26 22:27:37,485 ERROR org.apache.flume.sink.hdfs.AbstractHDFSWriter: Unexpected error while checking replication factor
java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.flume.sink.hdfs.AbstractHDFSWriter.getNumCurrentReplicas(AbstractHDFSWriter.java:169)at org.apache.flume.sink.hdfs.AbstractHDFSWriter.isUnderReplicated(AbstractHDFSWriter.java:88)at org.apache.flume.sink.hdfs.BucketWriter.shouldRotate(BucketWriter.java:636)at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:576)at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)at java.lang.Thread.run(Thread.java:748)Caused by: java.io.IOException: Could not get block locations. Source file “/user/hive/warehouse/ods.db/ods_ebike_report_json_day_append/event_day=20210126/olap-flume-2.xxx.com.1611590400190.gz.tmp” - Aborting…block==null
at org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1477)at org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1256)at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:667)
通过标红的日志大概得知Flume通过 10.xx.xx.216:9866 不能创建新的数据块导致该文件写入异常,10.xx.xx.216 这台机器是DataNode,9866 是DataNode的 XCeiver 协议的端口,究竟什么原因导致的该DataNode异常呢?我们再来看下DataNode当时的状态,发现收发器以及线程数在当时飙升: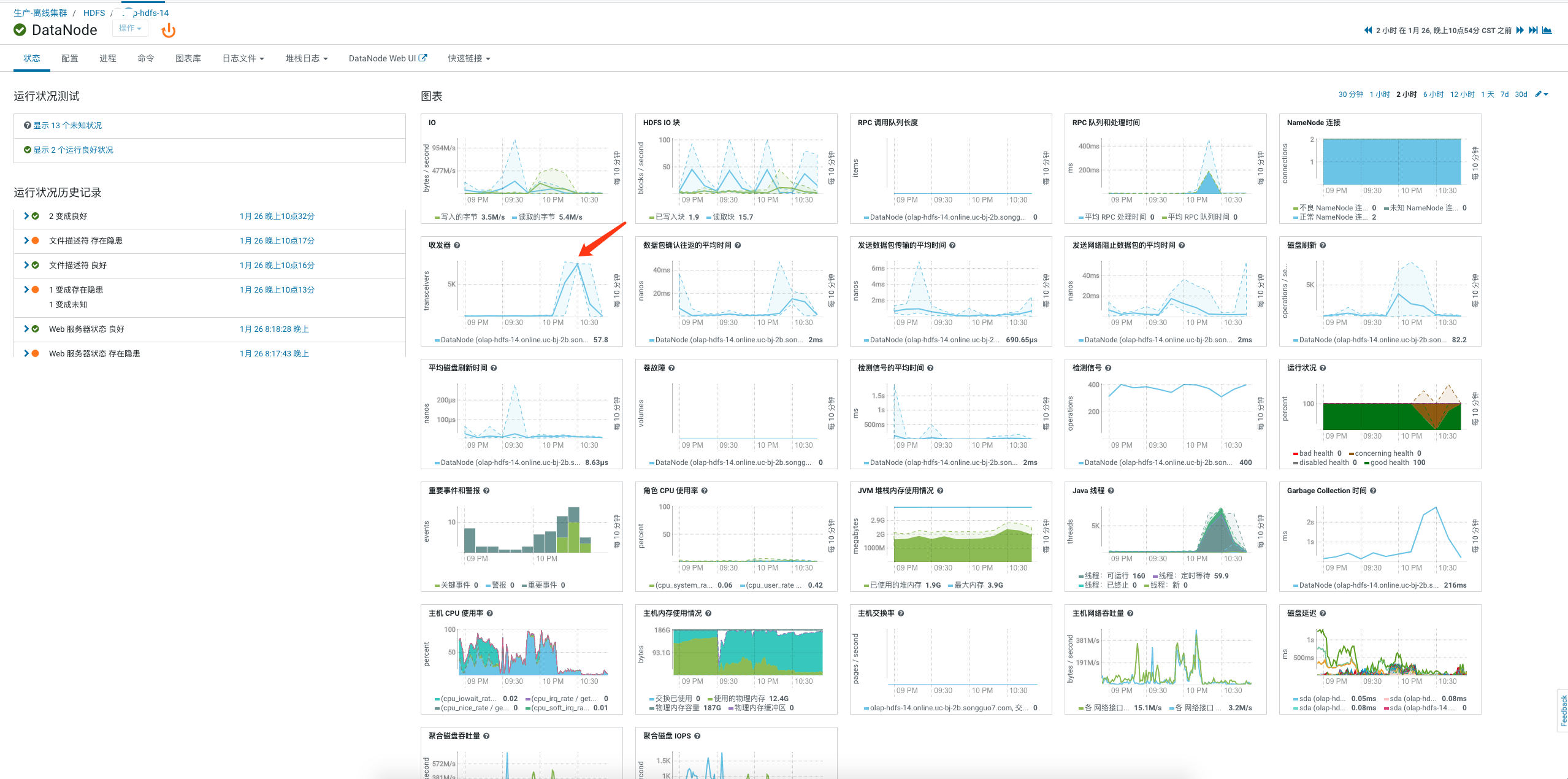
DataNode的块统计数据,发现当时存在大量的块被删除;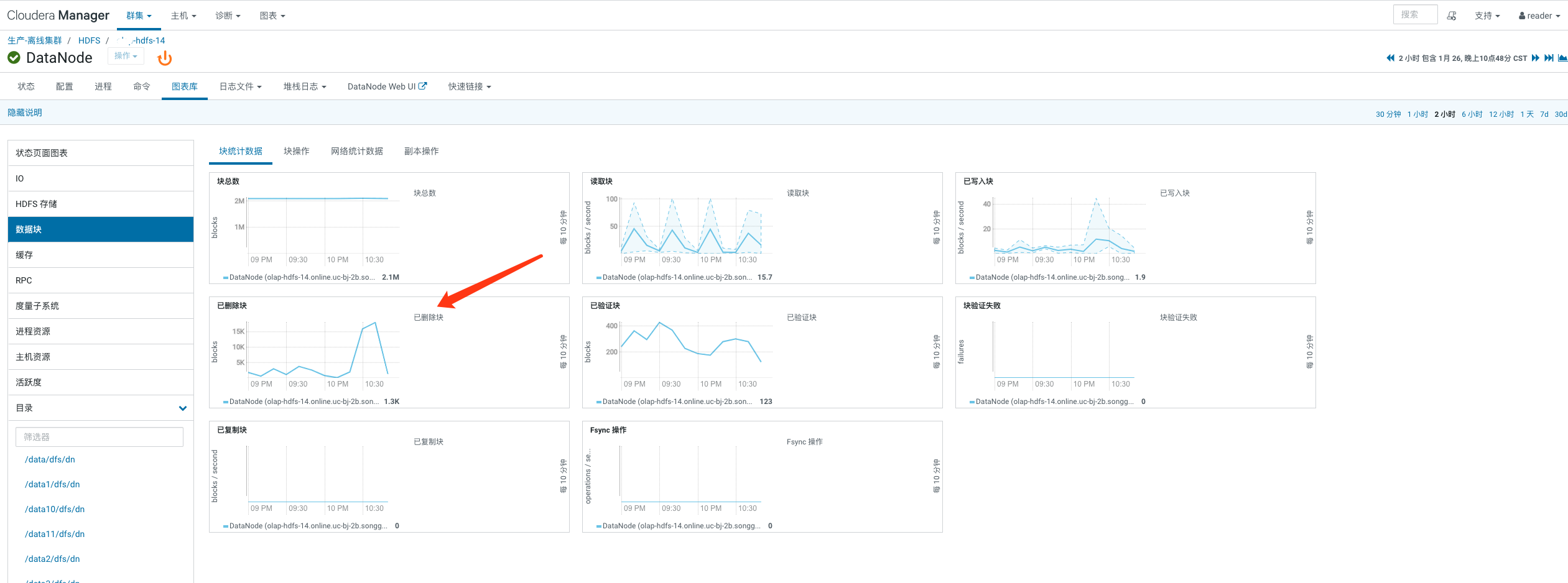
继续再看看为什么会有大量的块被删除呢?结合当时的Yarn报警发现一个任务异常,查看该任务的HQL:
with t1 as (select * from table_a WHERE event_day <= '20210126')insert overwrite table table_b partition (event_day)select xxx from t1
我们看到HQL中有insert overwrite操作,结下来我们看下insert overwrite执行过程中产生的 “.hive-staging_hive_xxx” 目录解释:
通过spark-sql、hive-sql、hue等提交select或者insert overwrite等sql到hive时,会产生该目录,用于临时存放执行结果,比如insert overwrite会将结果暂存到该目录下,待任务结束,将结果复制到hive表中
其中HQL大概的逻辑是这样的,通过读取表A对表B进行insert overwrite,注意 event_day <= ‘20210126’ 这个条件很要命,因为这样会将表A中所有的分区数据读取后写入表B,而表A所有分区的数据非常多紧接着导致HQL执行过程中HDFS大量的临时文件被创建&删除,接下来我们看下Yarn任务日志里创建临时文件的情况,可以看到397653这个数字还是非常庞大的;
最终元凶找到了,HQL在执行过程中创建的临时文件多达39w,也就是这39w个数据块创建+删除请求造成的DataNode异常;
解决方式:
修复文件
#zcat 损坏的文件输出到新的文件zcat olap-flume-2.xxx.com.1611590400190.gz > olap-flume-2.xxx.com.1611590400190_repair#发现最后一行不是一个完整的json,将其删除vim olap-flume-2.xxx.com.1611590400190_repair重新压缩成.gzgzip olap-flume-2.xxx.com.1611590400190_repair
后续思考:
短期通过Hive使用规范来避免突增的块删除,长期应建立HQL健康检测系统对提交的HQL进行检查,通过检查后再提交到Hive;
参考文档:

若有收获,就点个赞吧
0 人点赞
