MySQL逻辑架构图
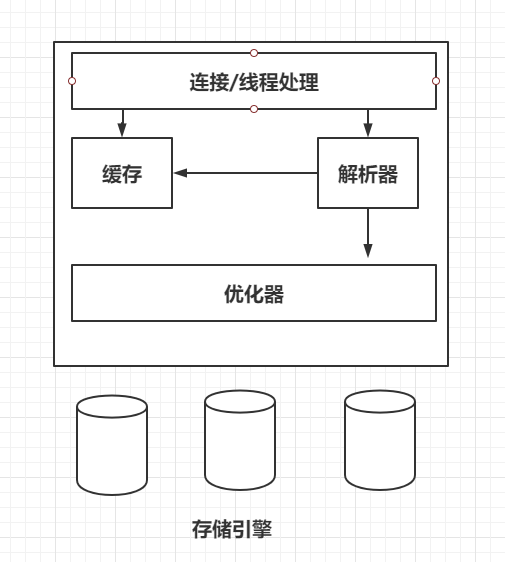
- 最上层的服务并不是MySQL特有的,大多数基于网络的客户端/服务器的工具或者服务器都有类似的架构,比如连接处理、授权认证、安全等。
- 第二层是MySQL中比较有意思的部分,大多数MySQL的核心功能都在这一层,包括查询解析、分析、优化、缓存以及部分内置函数都在这一层,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、试图等。
- 第三层包括了存储引擎。存储引擎负责MySQL中数据的存储和提取。每一个存储引擎各有优劣。服务器通过API与存储引擎进行通信。存储引擎包括了几十个底层函数,用于执行诸如“开始一个事务”等操作。但存储引擎不会去解析SQL,只是简单的相应上层服务器的请求。
事务
- 原子性(atomicity)
- 一个事务必须被视为一个不可分割的最小单元,整个事务中的操作要么全部成功提交,要么全部失败回滚。对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
- 一致性(consistency)
- 数据库总是从一个一致性状态转移到另一个一致性状态。
- 隔离性(isolation)
- 通常来说,一个事务所作的修改在最终提交以前,对其他事务是不可见的。
- 持久性(durability)
- 一旦事务提交,所作的修改将会永久保存在数据库中。
隔离级别
- READ UNCOMMITTED(读未提交)
- 在读未提交级别,事务的修改,即使没有提交,对其他的事务也都是可见的,事务可以读取为提交的数据,这也可以被称为脏读。
- READ COMMITED(读已提交)
- 在读已提交级别,一个事务开始,只能“看见”已经提交的事务所作的修改。换句话说,一个事务开始从开始到提交之前,所做的任何修改对其他事务都是不可见的。这个级别也会导致不可重复读的问题。
- REPEATABLE(可重复读)
- 该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另一个幻读的问题。幻读是指当某一个事务在读取某个范围内的记录时,另外一个事务又在该范围里插入新的记录,当之前的事务再次读取某个范围内的记录时,会产生“幻行”。InnoDB通过多版本并发控制解决了幻读的问题。
- SERIALIZABLE(串行化)
- 最高隔离级别,它通过强制事务串行执行,避免了前面说的幻读问题,但在并发环境下,性能较差。
死锁
- 死锁是指两个或多个事务在统一资源上互相占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能会产生死锁。多个事务同时锁定一个资源时,也有可能产生死锁。
- 事务1:
START TRANSACTION;UPDATE user SET name = 'mck' WHERE id = '1';UPDATE user SET name = 'zzz' WHERE id = '2';COMMIT;
- 事务2:
START TRANSACTION;UPDATE user SET name = 'mck' WHERE id = '2';UPDATE user SET name = 'zzz' WHERE id = '1';COMMIT;
- 如果凑巧,两个事务都执行到了第一条语句,同时也锁定了改行的数据,当执行第二条时,却发现该行已经被对方锁定,同时又需要对方释放锁,就会陷入死循环。除非有外部介入才可能解除死锁。
- 为了解决这个问题,数据库系统实现了各种死锁检测机制和死锁超时机制。比如InnoDB存储引擎,如果检测到了循环依赖,并立即返回一个错误。并对持有最少行级排他锁的事务进行回滚。
- 事务1:
多版本并发控制
- MySQL中大多数事务性存储引擎实现的并不是简单的行级锁。基于对多并发性能的考虑,它们一般都实现了多版本并发控制,但各自的实现机制不尽相同,因为MVCC并没有一个统一的标准。
- 可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定了必要的行。
- MCVV的实现是保存了数据在某个时间点的快照来实现的,也就是说,不管需要执行行多少时间,每个事务看到的数据是一致的。
- 下面通过InnoDB的简化版行为来说明MVCC是如何工作的
- InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的,这两个列一个保存了行的创建时间,一个保存的删除时间(过期时间)。当然存储的不是实际的时间,而是系统版本号。每个开始的事务,会使系统版本号递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。下面看下在REPEATABLE READ隔离级别下,MVCC是如何操作的。
SELECT- InnoDB会根据以下两个条件检查每行记录:
- InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于当前事务的系统版本号),这样可以保证事务读取的行,要么是在事务开始前已经存在的,要么是当前事务自身插入或者修改的。
- 行的删除版本要么未定义,要么大于当前事务版本号。这样可以确保事务读取到的行,在事务开始之前未被删除。
- InnoDB会根据以下两个条件检查每行记录:
INSERT- InnoDB为新插入的每一行保存当前事务的系统版本号为行版本号。
DELETE- InnoDB为删除的每一行保存当前事务的系统版本号作为删除标识。
UPDATE- InnoDB为插入一行新纪录,保存当前事务的系统版本号为行版本号,同时保存当前系统版本号到原来的行作为删除标志。
- 保存这两个额外的系统版本号,使大多数操作都可以不用加锁。
- MVCC只在读已提交和可重读两个隔离级别下工作。其他两个不兼容,在读未提交的级别下,数据行总是最新的,在串行化的级别下,所有的读取行都进行了加锁操作。
- InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的,这两个列一个保存了行的创建时间,一个保存的删除时间(过期时间)。当然存储的不是实际的时间,而是系统版本号。每个开始的事务,会使系统版本号递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。下面看下在REPEATABLE READ隔离级别下,MVCC是如何操作的。
MySQL的存储引擎
- InnoDB存储引擎
- MyISAM存储引擎
- CSV引擎
- CVS引擎可以在数据库运行时拷入或拷出文件,可以将Excel等电子表格的数据直接复制到MySQL的数据目录下,可以直接打开使用。因此,CVS引擎通常作为一种数据交换机制,非常有用。
- Memory引擎
- 如果需要快速的访问,且这些数据不会变化,重启后丢失也没有关系。Memory基于内存,减少了磁盘IO,Memory表的结构在重启以后还会保留,但表数据会丢失,常作为映射或查找,如市和邮政编码的映射等。
- 等等…

若有收获,就点个赞吧
0 人点赞
