慢查询基础:优化数据访问
- 是否向数据库请求了不需要的数据
- 查询不需要的数据(如在分页展示时,只取前10条数据,使用limit)
- 多表关联时返回了全部列(只取出需要的列)
- 总是取出全部列(慎用*)
- 重构查询的方式
- 一个复杂的查询还是多个简单的查询
- 切分查询(如线上环境需要定情清理大量数据,可以根据id分区间删除)
- 分解关联查询
SELECT * FROM userINNER JOIN role ON role.userId = user.id- 对上面两句进行拆分成两条语句
- 对缓存的效率更高
- 减少锁竞争
查询执行的基础
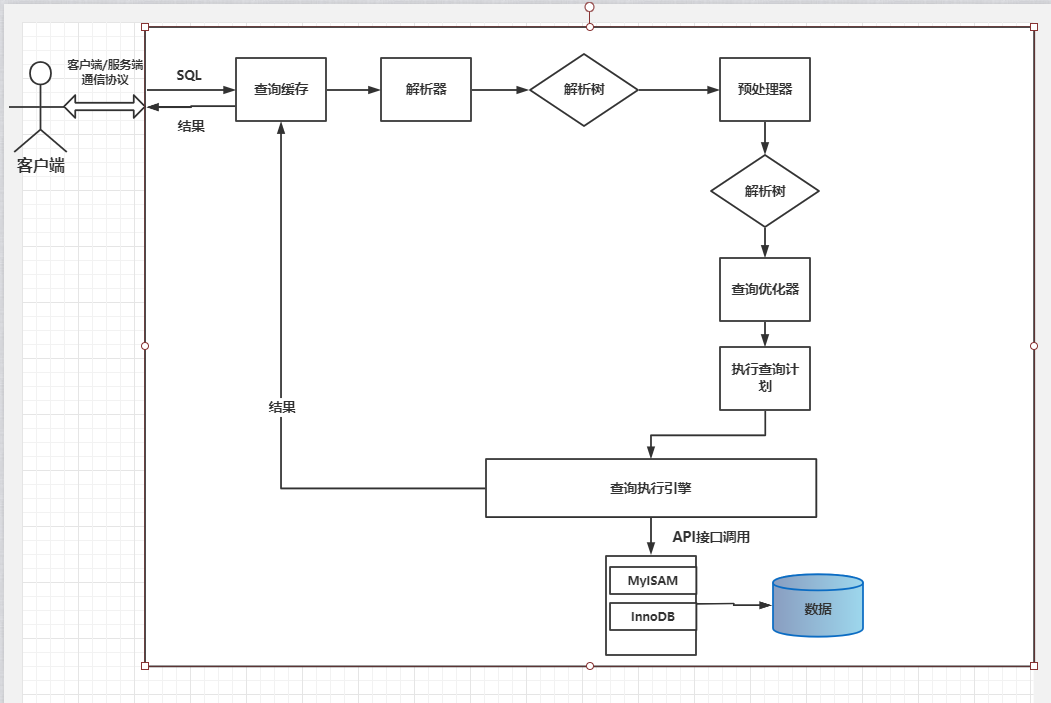
- MySQL客户端/服务器通信协议
- “半双工”,要么服务器向客户端发送数据,要么由客户端向服务器发送数据。
- 查询缓存
- 在解析一个语句之前,如果缓存是打开的,先检查这个查询是否命中查询缓存中的数据,会通过一个对大小写敏感的哈希查找来实现。
- 查询优化处理
- 很复杂。。。
- 查询执行引擎
- MySQL将生成对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询
- 返回给客户端
MySQL查询优化器的局限性
- 关联子查询
SELECT * FROM user WHERE id IN (SELECT userId FROM role WHERE name = 'admin');- 我们以为上面的查询会这样执行:
SELECT userId FROM role WHERE name = 'admin';result-> 1,2,3SELECT * FROM user WHERE id IN (1,2,3);
- 其实不是这样的,由于优化器的作用,上面的查询会被改写成下面这样
SELECT * user WHERE EXISTS (SELECT * FROM role WHERE name = 'admin' AND role.userId = user.id);- 由于需要关联外面的
user.id,如果外面的表数据量很大的话,这个查询会非常糟糕
- 改为以下
SELECT * FROM user INNER JOIN role ON role.user = user.id WHERE role.name ='ADMIN';
- UNION的限制
(SELECT name FROM user) UNION ALL (SELECT name FROM renter) limit 20;- 改写为
(SELECT name FROM user limit 10) UNION ALL (SELECT name FROM renter limit 10);
- 最大值和最小值优化
SELECT MIN(id) FROM user WHERE name = 'zzz';- 改写为
SELECT id FROM user USE INDEX(PRIMARY) WHERE name = 'zzz';
优化特定类型的查询
- 优化COUNT()查询
- COUNT(列名)会丢弃掉该列为NULL的值,而COUNT(*)不会丢弃为NULL的值

若有收获,就点个赞吧
0 人点赞
