注:本文大部分文字摘抄《Akka 实战:快速构建高可用分布式应用》中内容,但此书中所用的akka版本比较老,所以本文中的代码是本文作者基于最新版本的akka以及官网所实现。
文中涉及到的所有Demo都在github上 网页地址为:https://github.com/boomblog/AkkaDemo clone地址为:https://github.com/boomblog/AkkaDemo.git
线程调度
调度器(Dispatcher)
在akka中,Actor是运行在一个线程池上的,每个线程会不停的处理不同Actor所接收到的不同消息,并且线程池会根据Actor以及消息的变化而动态的调整线程数。
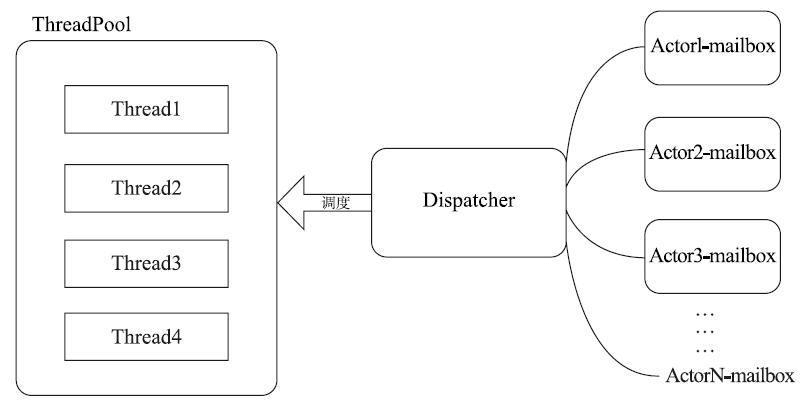
在 Akka 中,Actor 的任务(消息)由 Dispatcher 进行分配并执行,所以它基本上是整个系统吞吐量的最关键因素。在实际项目中,Actor可能需要处理各种不同类型的任务,有的任务耗时长,或者长时间阻塞,而有的任务则处理较快,不会造成阻塞,大部分时候,我们会将这两类任务做线程资源上的隔离,即分配不同的 Dispatcher 处理它们,此时可以避免由于某类任务耗尽线程而让其他请求等待的情况。
执行器(Executor)
Executor 为 Dispatcher 提供了执行异步任务的策略,它的实现方式有如下两种:
- thread-pool-executor :基于普通的线程池,它有一个工作队列,当线程空闲时会从队列中获取任务并执行。
- fork-join-executor :基于工作窃取的线程池,它的工作思路是把大的计算任务拆分成小的任务然后并行执行,最后合并结果。当某个线程的任务队列里没有任务时,会主动从其他线程的任务队列中「窃取」任务。一般认为,fork-join 的性能更佳,这也是 Akka 的默认选项。
配置调度器
每个 ActorSystem 都有一个默认的 Dispatcher 配置项,并且使用 fork-join 作为默认的 Executor 配置,假如需要自定义 Dispatcher ,则可以进行如下配置:
my-forkjoin-dispatcher {type = Dispatcherexecutor = "fork-join-executor"# 配置fork-join线程池fork-join-executor {parallelism-min = 3parallelism-factor = 3.0parallelism-max = 15}throughput = 1}
Dispatcher 之 fork-join-executor 配置说明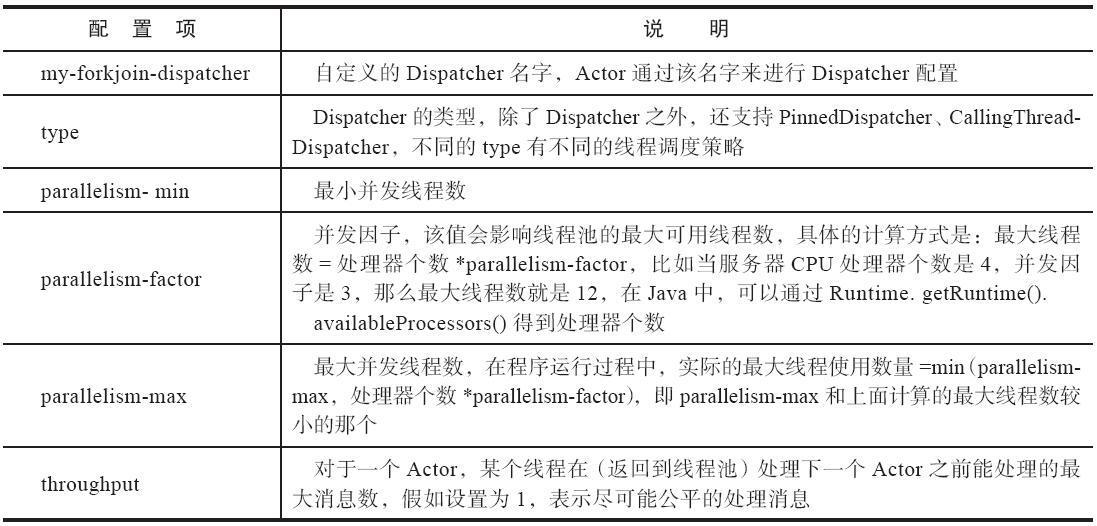
thread-pool-executor 的配置与 fork-join-executor 非常类似:
my-threadpool-dispatcher {# dispatcher类型type = Dispatcherexecutor = "thread-pool-executor"# 配置线程池thread-pool-executor {# 最小线程数core-pool-size-min = 2# 并发使用的最大线程数=处理器*因子core-pool-size-factor = 3.0# 最大线程数core-pool-size-max = 15}throughput = 1}
使用调度器
Actor 使用 Dispatcher 有两种方式:代码和配置。
代码示例如下:
ActorRef ref = system.actorOf(Props. create(ActorDemo. class).withDispatcher( "my-forkjoin-dispatcher"), "actorDemo");
假如不想硬编码使用 Dispatcher ,可以通过如下方式,给某个 Actor 配置一个 Dispatcher :
akka.actor.deployment {/actorDemo {dispatcher = my-forkjoin-dispatcher}}
PinnedDispatcher
PinnedDispatcher 是另外一种 Dispatcher 类型,它会为每个 Actor 提供只有一个线程的线程池,该线程池为 Actor 独有。当 Actor 处理比较耗时、阻塞的操作时,使用 Pinned-Dispatcher 将会非常有效。
PinnedDispatcher 的配置如下:
my-pinned-dispatcher {executor = "thread-pool-executor"type = PinnedDispatcher}
大部分时候,PinnedDispatcher 会和 thread-pool-executor 一起使用。
虽然说 PinnedDispatcher 可以避免由于阻塞导致系统整体吞吐率的下降,但是过多地使用它也可能会导致服务器资源耗尽,在使用 Akka 的过程中,我们需要尽量避免阻塞的情况。
CallingThreadDispatcher
CallingThreadDispatcher只做测试用。
邮箱
当我们在给一个 Actor 发送消息时,并不是直接依赖 API 之间的传参方式,而是会把消息先发送到 Actor 的邮箱(mailbox)里面,然后 Actor 会从自己的邮箱里取出这些消息。Actor 中的邮箱是一个队列结构,所有发送过来的消息都会在该队列进行排队,在默认情况下,它遵循先进先出(FIFO)的模式,假如需要改变这种默认处理方式,需要自定义邮箱或消息队列。
消息处理顺序
Actor 既可以存在于本地,也可以存在于远程的某个节点,并且它也可以和任何其他节点的 Actor 进行消息通信,有可能一个 Actor 会接收来自不同 Actor 的消息,此时该 Actor 并不能保证某个消息一定排在另一个的前面或后面,但是对于从同一个 Actor 发过来的多个消息,它能保证串行的顺序。
默认邮箱配置
Akka 对邮箱提供了专门的配置项,即默认邮箱配置( default-mailbox),比如邮箱类型( mailbox-type )、邮箱容量( mailbox-capacity )、入队超时时间( mailbox-push-timeout-time )等,它看起来是这样的:
akka.actor.default-mailbox {mailbox-type = "akka.dispatch.UnboundedMailbox"mailbox-capacity = 1000mailbox-push-timeout-time = 10s}
当我们不对邮箱做任何配置时,都会采用上面这个 default-mailbox 的默认配置。下面来看看这几个配置的具体含义。
- mailbox-type :邮箱类型,分为有界(Bounded)和无界(Unbounded),Akka 默认采用 UnboundedMailbox ,表示不限制邮箱队列的大小;
- mailbox-capacity :邮箱容量,定义了有界邮箱(BoundedMail )的大小,该值只能是正数;
- mailbox-push-timeout-time :入队超时时间,主要是指 push 一个消息到有界邮箱的队列的超时时限。假如为负数,则表示无限超时。
UnboundedMailbox 主要依赖于java.util.concurrent.ConcurrentLinkedQueue 来实现,从名字就可以看出来,它是一个基于链表的队列结构,并且遵循 FIFO(先进先出)。具体来讲就是,使用该队列时,新加的元素会被放在队列的尾部,而取元素时会从头部开始。另外,它通过 CAS 无锁算法来保证多线程下的安全,性能上有很大优势。
内置邮箱
除了默认的 UnboundedMailbox 邮箱之外,Akka 还提供其他多种类型的邮箱,以满足不同场景的需要。在 Akka 中,邮箱主要分为两大类:Unbounded 和 Bounded。Unbounded 表示无界,即邮箱没有容量上的限制;Bounded 表示有界,即邮箱有容量上的限制。大部分无界邮箱都是非阻塞的,而对于有界邮箱来讲,当消息数量达到邮箱容量,并且 mailbox-push-timeout-time 配置成非 0 时,会产生阻塞。
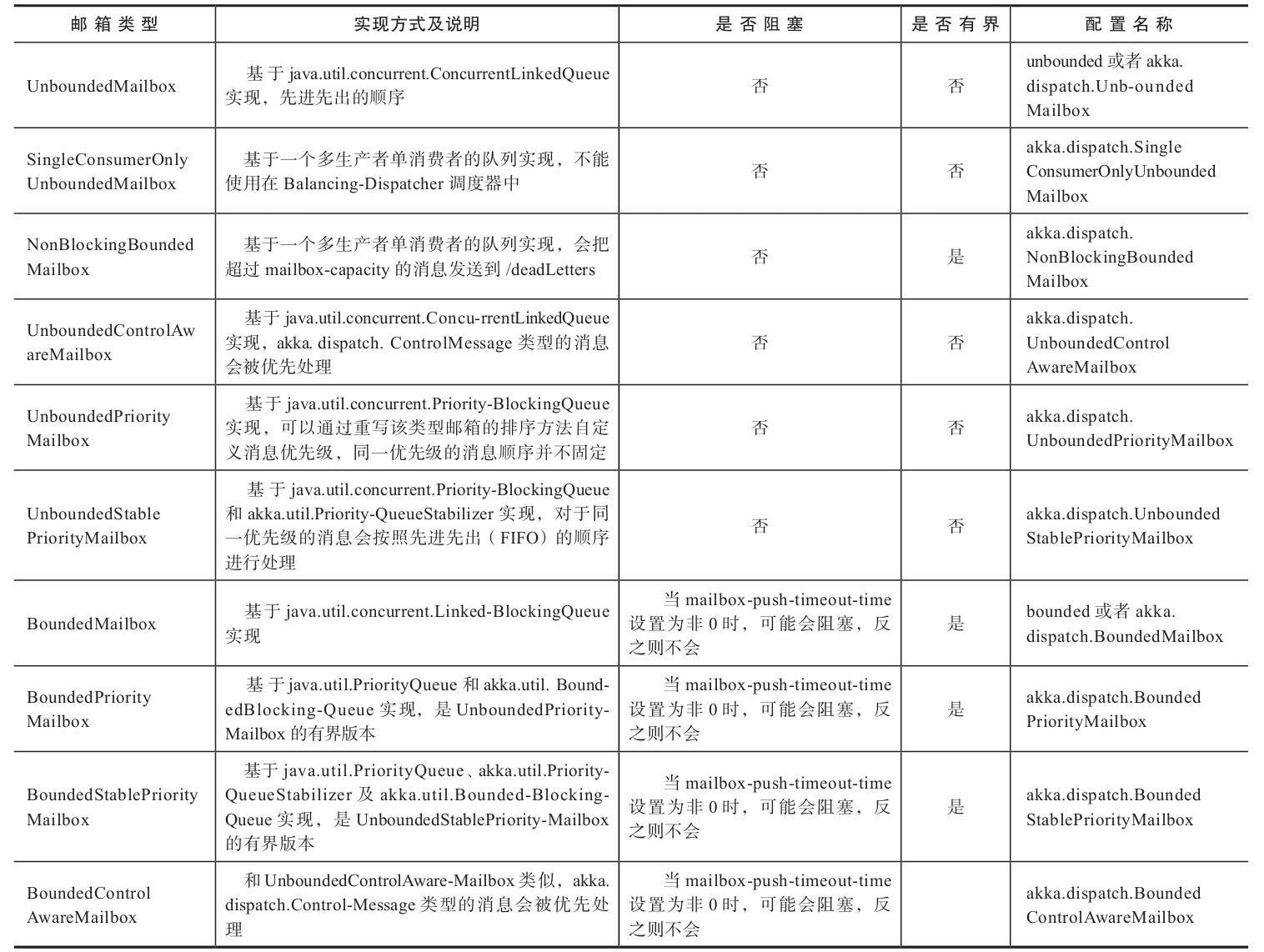
自定义优先级
在很多场景下,我们可能希望 Actor 可以根据设置好的优先级来处理消息,这些优先级通常和业务逻辑有关。为了能够自定义优先级,我们需要继承 PriorityMailbox 类并重写优先级规则,然后把该邮箱类型配置到配置文件,或者让 Actor 通过 withMailbox 的方式关联该邮箱。
具体例子看github代码。
前面介绍的优先级队列,可以对整个消息进行排序,基本上能满足大部分需求。而对于有些比较特殊的关键消息,我们可能希望它每次都能拥有更高的优先级,这些消息通常来讲都是一些控制指令。Akka提供了一种ControlAwareMailbox邮箱类型,可以让实现了ControlMessage接口的消息拥有最高优先级。
Actor使用邮箱的多种方式
除开上面使用的withMailbox方式外,还可以在配置文件中配置:
akka.actor.deployment {/priorityActor {mailbox = msgprio-mailbox}}
dispatcher 会通过邮箱进行消息调度,所以我们可以把邮箱配置在dispatcher 上,然后让 Actor 关该 dispatcher ,配置如下:
my-msgprio-dispatcher {type = Dispatchermailbox-type = "com.luban.akka.vip.高级.MsgPriorityMailBox"#其他dispatcher配置在此省略}
为了让 Actor 自动拥有某个特定类型的邮箱,可以让该 Actor 实现RequiresMessageQueue 接口,并且设置接口泛型为该邮箱队列的语义接口。
接口和邮箱类型对应关系为:
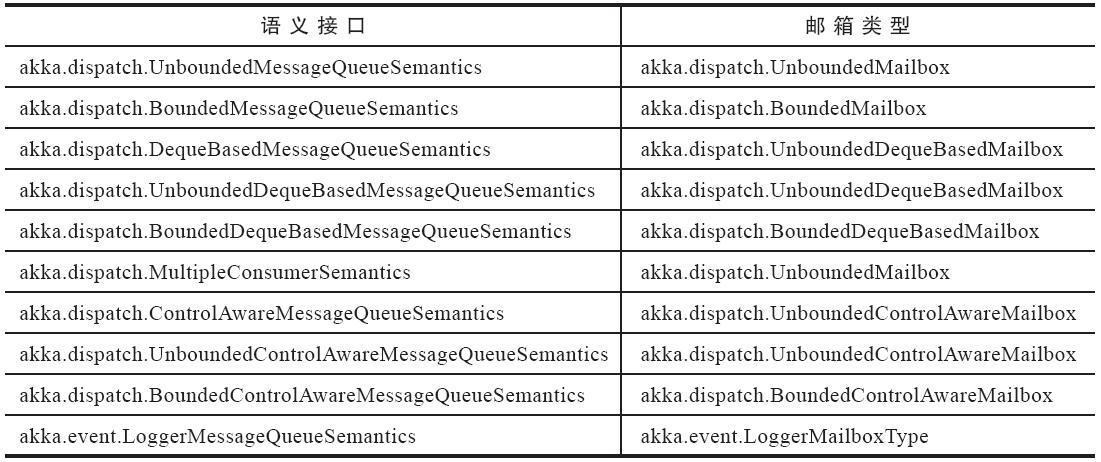
自定义邮箱
如果我们想跟精细化的控制邮箱里的消息,那么我们需要自定义邮箱。
自定义邮箱分为两步:
- 定义一个邮箱队列(实现MessageQueue 接口)
- 定义邮箱类型(实现 MailboxType 接口
消息路由
Router表示路由器,Routee表示路由目标,消息先进入路由器,然后通过不同的转发策略转发给路由目标。
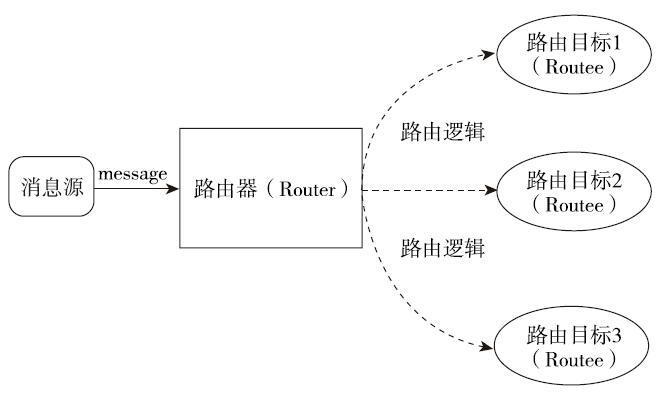
路由Actor
路由 Actor 有两种模式:pool 和 group。
- pool 的方式表示路由器 Actor 会创建子 Actor 作为其 Routee 并对其监督和监控,当某个 Routee 终止时将其移除出去;
- group 的方式表示可以将 Routee 的生产方式放在外部(不必自包含),然后路由器 Actor 通过路径(path)对这些目标进行消息发送。
Pool 方式
使用 pool 方式定义的路由 Actor 会自动将 Routee 创建为自己的子级,这种层级关系在最开始就自动存在,不必通过 getContext.actorOf 的方式来指定.
到这里,大家可能会有个疑问,假如此时 Routee 回复一个消息会怎样呢?到底该谁接收?
实际上,路由和 forward 一样,在整个消息转发的过程中并不会改变原始 sender,所以消息会被回复给最初的 sender。并且,在回复消息时可以让父 Actor(路由 Actor)成为自己的 sender,这样在某种程度上可以隐藏自己的相关信息。
对于 pool 方式来讲,另外一个需要注意的是:由于父监督原则,路由 Actor 承担着 Routee 的监督工作,当没有显式指定监督策略时,路由 Actor 默认会把失败上溯到上级。当路由 Actor 重启时,会重新创建 Routee(子级 Actor),并且在池中维护相同个数( nr-of-instances )的 actor;当所有的 Routee 被终止时,路由 Actor 也会停止(watch 它的生命周期,就可以收到它的 Terminated 消息)。
Group 方式
当我们需要单独(外部)创建 Routee 时,可以采用 group 方式。在使用 group 路由前,需要先定义 Routee-Actor ,然后将它们以 path 的形式配置起来,路由 Actor 会通过 path 列表来进行路由。下面是路由 Actor 的核心代码:
//定义RouteegetContext().actorOf(Props.create(WorkTask.class), "wt1");getContext().actorOf(Props.create(WorkTask.class), "wt2");getContext().actorOf(Props.create(WorkTask.class), "wt3");router=getContext().actorOf(FromConfig.getInstance().props(),"router");
在确定了 Aactor 的层级关系或者 path 之后,需要将它们配置到 conf 文件中:
akka.actor.deployment {/masterActor/router {router = round-robin-grouproutees.paths = ["/user/masterActor/wt1", "/user/masterActor/wt2","/user/masterActor/wt3"]}}
其中/ masterActor /router 表示路由器的 path,routees.paths 用来配置 Routee 的 path,并且本地和远程 Actor 都是支持的。假如希望这些 path 能更加动态地产生(或者依赖其他业务逻辑产生),可以使用编码的方式来实现,比如:
List<String> routeePaths = Arrays.asList("/user/masterActor/wt1", "/user/masterActor/wt2","/user/masterActor/wt3");router=getContext().actorOf(new RoundRobinGroup(routeePaths).props(),"router");
还有一点要注意的就是:group 方式并不限制 Routee 一定得在同一个层级下,比如当你想增加一个其他外部的 Actor 作为 Routee 时,仅仅需要将它的 path 配置在 routees.paths 中即可。
常见路由类型
为了满足不同场景的需求,Akka 提供了多种路由类型供我们使用,下表是部分路由类型的汇总说明。
部分路由类型的功能描述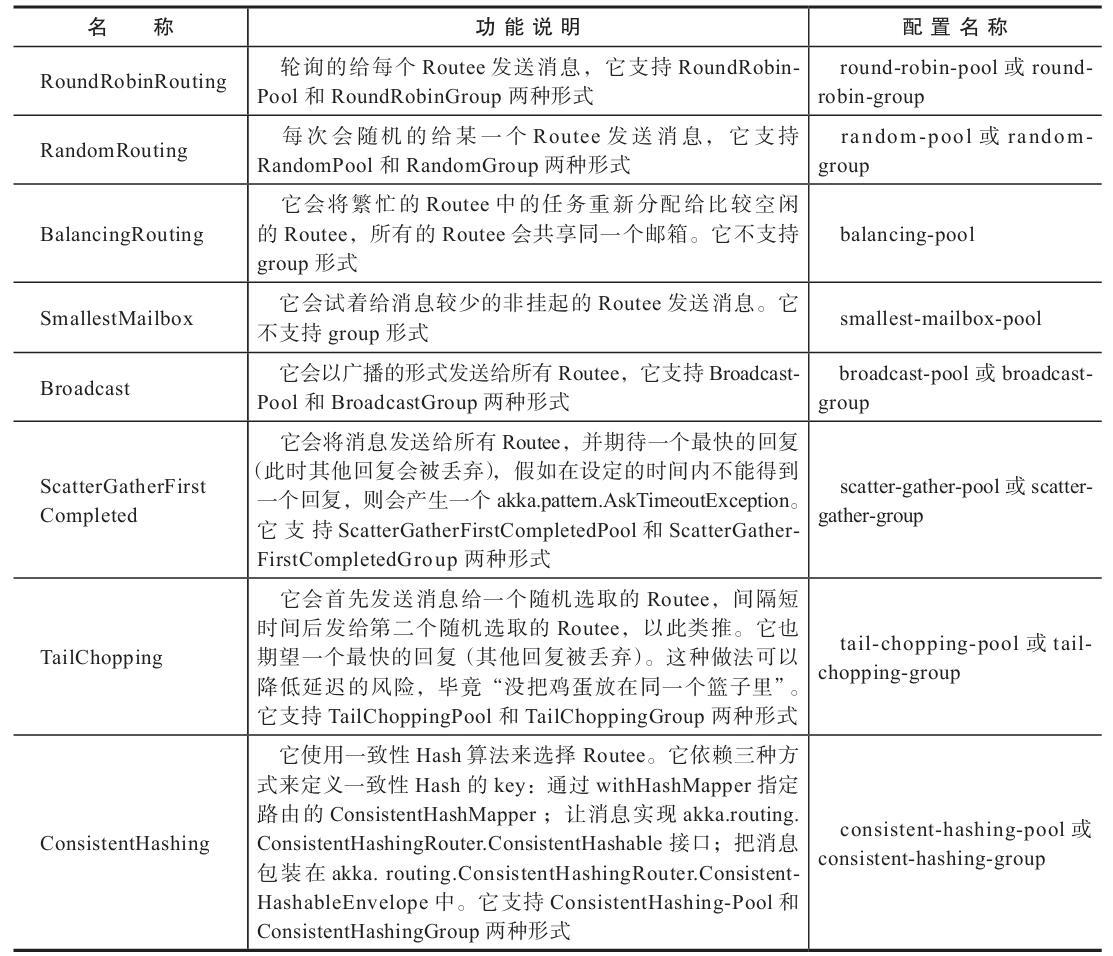
下面,我们来演示一下 Broadcast 、ScatterGatherFirstCompleted 和TailChopping 的具体用法。
广播 -Broadcast
广播路由器会给所有指定的 Routee 发送消息,即每个 Routee 会收到同样的消息。为了方便演示,我后面统一采用 Group 的形式来创建路由。
首先,可以定义任意两个 Routee-Actor ,用来接收路由过来的消息,核心代码如下:
static class Worker1 extends AbstractActor {@Overridepublic Receive createReceive() {return receiveBuilder().matchAny(msg -> {System.out.println("Worker1" + "-->" + msg);}).build();}}static class Worker2 extends AbstractActor {@Overridepublic Receive createReceive() {return receiveBuilder().matchAny(msg -> {System.out.println("Worker2" + "-->" + msg);}).build();}}
Worker 1 和 Worker 2 作为 Routee-Actor 存在,可以有任意多个。然后创建 Routee 和 Router:
static class RouterActor extends AbstractActor {private ActorRef router;@Overridepublic void preStart() throws Exception {getContext().actorOf(Props.create(Worker1.class), "wk1");getContext().actorOf(Props.create(Worker2.class), "wk2");router = getContext().actorOf(FromConfig.getInstance().props(), "routerActor");}@Overridepublic Receive createReceive() {return receiveBuilder().matchAny(msg -> {router.tell(msg, getSender());}).build();}}
然后做如下配置:
/broadcastGroupActor/routerActor {router = broadcast-grouproutees.paths = ["/user/broadcastGroupActor/wk1","/user/broadcastGroupActor/wk2"]}
用如下代码进行测试:
public static void main(String[] args) {ActorSystem system = ActorSystem.create("sys", ConfigFactory.load("router.conf"));ActorRef master = system.actorOf(Props.create(RouterActor.class), "broadcastGroupActor");master.tell("helloA", ActorRef.noSender());master.tell("helloB", ActorRef.noSender());}
运行代码,会得到如下结果:
Worker1-->helloAWorker1-->helloBWorker2-->helloAWorker2-->helloB
最快响应 -ScatterGatherFirstCompleted
ScatterGatherFirstCompleted 将消息发送给所有 Routee,并且会等待一个最快的响应,一旦收到一个响应回复,其他回复将会被丢弃。和之前介绍的所有路由一样,首先得定义 Routee,下面是部分演示代码:
getContext().actorOf(Props.create(Worker1.class), "wk1");getContext().actorOf(Props.create(Worker2.class), "wk2");router = getContext().actorOf(FromConfig.getInstance().props(), "routerActor");
Worker1、Worker2 分别是两个普通的Actor,用来接收消息并通过getSender().tell("响应"``,``getSelf());的方式回复消息。
ScatterGatherFirstCompleted 路由的本意是将一个业务处理(比如查询或计算)分发到不同的节点,让最快的节点处理并返回消息,以此降低延迟,提高吞吐率,但是假如在这个过程中发生错误,导致节点并不能正常返回消息,那么业务发起者是否需要一直等待呢?很显然不是。
ScatterGatherFirstCompleted 提供了 within 参数,用于设置最长等待时间,在这个时间段内,如果发起者不能收到任何一个正常回应,则会收到一个 timeout 的错误提示,下面是参考配置:
/scatterGatherGroupActor/routerActor {router = scatter-gather-grouproutees.paths = ["/user/scatterGatherGroupActor/wk1", "/user/scatterGatherGroupActor/wk2"]within = 3 seconds}
为了能接收到 Routee 返回的消息,可以采用 ask 的方式发起业务,然后通过 Future 回调的方式处理消息:
Future.onComplete 会异步执行,当它收到回复后,会通过onComplete 来处理异常和消息。大家可以自行在 Worker1、Worker2 的onReceive 方法中设置 sleep 代码,模拟耗时的操作,运行结果后会发现,你总是能接收到最快响应的消息。如果设置的 sleep 时间超过了 within 设置的时间,则会在 onComplete 中收到一个akka.pattern.AskTimeoutException ,此时 result 为 null。
完整代码看github.
随机-最快响应 -TailChopping
TailChopping 是一个比较有趣的路由类型,它会首先将消息发送给一个随机选取的 Routee,在延迟一小段时间后将消息发送给第二个随机选取的 Routee,以此类推。和 ScatterGatherFirstCompleted 类似,它也期望得到第一个响应并回给原始 sender,其他回复则被丢弃。
实际上,我们可以很方便地将上面 ScatterGatherFirstCompleted 的示例改造成 Tail-Chopping ,要做的仅仅是在配置文件中配置 router 类型和发给下一个随机 Routee 的消息的间隔时间,如:
/masterFirstActor/firstCompRouter {router = tail-chopping-grouproutees.paths = ["/user/masterFirstActor/fw1","/user/masterFirstActor/fw2"]within = 5 seconds# 发给下一个routee的时间间隔tail-chopping-router.interval = 1 seconds}
创建可修改容量的池
在之前的示例中,无论是通过配置还是硬编码,我们创建的都是固定容量的 pool,即该容量在程序运行时无法动态改变。有时候,我们可能更希望 pool 能够根据实际业务量动态的增加或降低容量,此时可以考虑使用 Resizer 和 OptimalSizeExploringResizer 功能。
Resizer
Resizer 可以根据路由的繁忙程度来决定增加还是降低 pool 的容量,当它发现处理消息的压力大于某个阈值时会增加容量,当它发现处理消息的压力小于某个阈值时则会降低容量。使用 Resizer 功能的方式比较简单,仅仅配置如下内容即可:
/roundRobinPoolRouterActor/routerActor {router = round-robin-poolresizer {lower-bound = 2upper-bound = 4messages-per-resize = 10}}
其中 lower-bound 和 upper-bound 分别表示最小和最大 routee 的数量。messages-per-resize 表示在每次执行 resize(修改容量)间隔期间所处理的消息数目。
OptimalSizeExploringResizer
OptimalSizeExploringResizer 会持续的对 pool 进行优化,以便让 pool 保持在一个最佳容量。一般认为,它比 Resizer 更耗内存。下面是它的核心配置:
/roundRobinPoolRouterActor/routerActor {router = round-robin-pooloptimal-size-exploring-resizer {enabled = onaction-interval = 3sdownsize-after-underutilized-for = 10hdownsize-ratio = 0.9}}
其中 action-interval 表示每次 resize 操作的间隔时间,downsize-after-underutilized-for 表示当所有 routee 都没有满额任务的持续时间超过这个时间长度时,就会将容量值降低到一个合理的值,该值也与 downsize-ratio 配置相关,比如说原本最高使用 20 个 routee,现在会降到 18 个。
特殊消息处理
正常情况下,发送给路由的消息都会按照指定的路由策略转发给 Routee,但是对于某些特殊的消息,它的处理方式可能有所不同。
Broadcast 消息
在前面我们介绍了Broadcast路由器,该类型的路由会给每个 Routee 发送相同的消息。实际上,我们还可以通过直接给某路由发送Broadcast 消息来实现类似的功能,比如:
router.tell(new Broadcast("broad cast"), ActorRef.noSender());
此时该路由会给所有 Routee 发送消息(该消息在发送时被Broadcast类包装,但接受者接收到的是原始的消息),并且这种行为与原本的路由策略无关。
PoisonPill 消息
正常情况下,给一个 Actor 发送 PoisonPill 消息后,该 Actor 会被终止,这对路由也是适用的。但是发送给路由的 PoisonPill 消息会直接被路由自己消化,而不会被转发给 Routee。对于 pool 类型的路由,或者其他含有层级关系的路由策略(即 Routee 被创建为某个 Router 的子级),当父级收到 PoisonPill 消息时,会在自己终止前先终止子级,子级会在处理完「手头」上的消息后正式终止,而邮箱队列里面的消息将得不到处理。通常来讲,这并不是一个好的终止策略(当然,除非是由于某些特殊需求而不得不这样做),更好的做法是:直接让 Routee 收到终止的消息,让它能在停止之前继续处理其他消息。这时候,前面介绍的 Broadcast 就能派上用场了,比如:
router.tell(new Broadcast(PoisonPill.getInstance()),ActorRef.noSender());
在给 Router 发送包装了 PoisonPill 的 Broadcast 消息后,每个 Routee 都会收到 PoisonPill 消息,此时 PoisonPill 会作为一个普通的消息进入邮箱队列,然后在所有现有消息处理完之后再来处理它,这样可以确保已有的消息都能得到处理。
和 PoisonPill 类似的另外一个消息类型是 Kill,它能杀死一个 Actor,同时子 Actor 也会被杀掉,对于路由来讲也会存在上述问题,所以建议将 Kill 包装在 Broadcast 中:
router.tell(new Broadcast(Kill.getInstance()), getSender());
其他管理类消息
管理类消息包括新增 Routee,删除 Routee,得到现有 Routee 列表等。


下面是部分演示代码:
Timeout timeout= new Timeout(Duration.create(10, "seconds"));//新增一个Routeeref.tell(new AddRoutee(new ActorRefRoutee(tmpRef)), ActorRef.noSender());//删除一个Routeeref.tell(new RemoveRoutee(new ActorRefRoutee(tmpRef)), ActorRef.noSender());//得到Routee列表Future<Object> fu=Patterns.ask(ref, GetRoutees.getInstance(), timeout);fu.onComplete(new OnComplete<Object>() {@Overridepublic void onComplete(Throwable err, Object result) throws Throwable {Routees rs=(Routees)result;List<Routee> listRoutees=rs.getRoutees();for(Routee r:listRoutees) {System.out.println("routee:"+r);}}}, system.dispatcher());
该代码有两点需要注意:
1)使用同一个 ActorRef 包装的两个 ActorRefRoutee ,实际上描述的还是一个 Routee;
2)新增或删除 Routee 这类操作可能并不会马上生效,需要在发送GetRoutees 消息后根据返回的 Routees 情况才能判断出来是否已经变更。

若有收获,就点个赞吧
0 人点赞
