注:本文大部分文字摘抄《Akka 实战:快速构建高可用分布式应用》中内容,但此书中所用的akka版本比较老,所以本文中的代码是本文作者基于最新版本的akka以及官网所实现。
文中涉及到的所有Demo都在github上 网页地址为:https://github.com/boomblog/AkkaDemo clone地址为:https://github.com/boomblog/AkkaDemo.git
定时调度—Scheduler
Scheduler有两种:scheduleOnce 和 scheduler。
scheduleOnce表示延迟一段时间后执行,且只执行一次;
scheduler表示延迟后定时执行,并且可以取消定时执行。
Scheduler对象需要通过 Actor.scheduler()得到,它在整个 Actor 系统内都是单例的。
实际上,在 Actor 系统启动后,会读取 akka.scheduler.implementation 这个配置项,默认获取到的Scheduler 正是由此生成,当然,你也可以自定义该实现。
处理并发结果—Future
**使用 Future 的最简单方式就是通过 Patterns.ask 方法接收一个 Future 对象,然后使用同步或异步的方式去处理消息。同步的方式主要是通过Await.wait方法阻塞等待返回值来实现,异步主要通过各种回调函数实现。需要注意的是:在实现消息传递时,我们必须考虑到超时带来的影响。
public class FutureDemo {static class FutureActor extends AbstractActor {@Overridepublic Receive createReceive() {return receiveBuilder().matchAny(msg -> {Thread.sleep(4000);getSender().tell("reply", getSelf());}).build();}}public static void main(String[] args) {ActorSystem system = ActorSystem.create("sys");ActorRef ref = system.actorOf(Props.create(FutureActor.class), "fuActor");Timeout timeout = new Timeout(Duration.create(3, "seconds"));Future<Object> future = Patterns.ask(ref, "hello future", timeout);try {// Await同步获取响应,如果超时了则会抛出java.util.concurrent.TimeoutExceptionString replymsg = (String) Await.result(future, timeout.duration());System.out.println(replymsg);} catch (Exception e) {e.printStackTrace();}}}
假如要异步处理消息,则需要显式地依赖 ExecutionContext 对象,并且调用回调函数。Future 提供的回调函数有:onComplete 、onSuccess和 onFailure ,它们分别表示完成、成功、失败的处理,下面是示例代码:
future.onSuccess(new OnSuccess<Object>() {@Overridepublic void onSuccess(Object msg) throws Throwable {System.out.println("receive: " + msg);}}, system.dispatcher());future.onFailure(new OnFailure() {@Overridepublic void onFailure(Throwable ex) throws Throwable {if (ex instanceof AskTimeoutException) {System.out.println("超时异常");} else {System.out.println("其他异常 " + ex);}}}, system.dispatcher());future.onComplete(new OnComplete<Object>() {@Overridepublic void onComplete(Throwable failure, Object success) throws Throwable {if (failure != null) {System.out.println("异常");} else {System.out.println(success);}}}, system.dispatcher());
当成功获取消息时,会进入 onSuccess 回调函数,并且将消息传给OnSuccess 方法;当出现异常时(比如超时),会进入 onFailure 回调函数,并且将异常传给 onFailure 方法,除了这两个函数外,还可以使用onComplete 函数,它相当于把 onSuccess 和 onFailure 的功能整合在一起。
事件总线
事件总线就是观察者模式,实现了基于发布—订阅的消息流处理。
在 Akka 中,事件总线被抽象成 EventBus 类型,它拥有发布(publish)、订阅(subscribe)、取消订阅( unsubscribe )等功能。具体来讲,一个完整的消息总线的过程是:发布者将 Event 发布到 EventBus上,事件订阅者( Subscriber )将会接收到相应的通知消息,通常来讲,订阅者会是一个 Actor,它通过原有的 onReceive 方法接收该消息。在这个过程中,还有一个概念非常重要,那就是 Classifier ,它用来描述一个事件分类,不同事件类型将有不同的订阅者,EventBus 将会通过 Classifier 来选择订阅者并向其发送消息。常见的 Classifier 有 LookupClassification 、SubchannelClassification 等,前者指定匹配的事件分类,由每个类别维护一个订阅者列表,后者可以匹配层级的事件分类。
Akka扩展机制
Akka 提供了一种非常好的扩展组件的方式,即 Akka Extensions (扩展)。实际上,Akka 内部有很多组件就是基于扩展实现的,比如 TypedActor 、序列化、集群指标等。
TypedActor使用
在 Akka 中,Actor 主要分为两类:AbstractActor(老版本叫UntypedActor) 和 TypedActor 。AbstractActor 更能体现经典 Actor 模型的优势,所以更加常用。而TypedActor 的使用方式比较接近 OOP,即通过接口——实现类和函数调用的方式来驱动任务的执行。
public class TypedActorDemo {public interface UserService {public void saveUser(String id, String user);public Future<String> findUserForFuture(String id);public Option<String> findUserForOpt(String id);public String findUser(String id);}static class UserServiceImpl implements UserService {private static Map<String, String> map = new ConcurrentHashMap<String, String>();// 当方法无返回值(即 void)的时候,底层会采用 ActorRef.tell 的方式来调用,执行方式为异步;@Overridepublic void saveUser(String id, String user) {map.put(id, user);}// 当方法返回 scala.concurrent.Future 时,会以 Patterns.ask 的方式来调用,然后将结果值包装到 Future 里并返回,它的执行方式也是异步@Overridepublic Future<String> findUserForFuture(String id) {return Futures.successful(map.get(id));}// 当方法返回 akka.japi.Option 时,会以 Patterns.ask 的方式来调用,但是程序会一直阻塞,直到有返回值。假如返回值为 null,它会被包装成 Option.None 类型;@Overridepublic Option<String> findUserForOpt(String id) {return Option.some(map.get(id));}// 当方法返回其他类型时,就和普通方法一样,程序会一直阻塞,直到有返回值。@Overridepublic String findUser(String id) {return map.get(id);}}public static void main(String[] args) {ActorSystem system = ActorSystem.create("sys");TypedActorExtension typeActorExtension = TypedActor.get(system);UserService userService = typeActorExtension.typedActorOf(new TypedProps<UserServiceImpl>(UserService.class, UserServiceImpl.class));System.out.println("userService: " + userService);//异步执行?userService.saveUser("1", "afei");//异步执行Future<String> fu = userService.findUserForFuture("1");fu.onSuccess(new OnSuccess() {@Overridepublic void onSuccess(Object result) throws Throwable {System.out.println("The future user is:" + result);}}, system.dispatcher());//阻塞直到有返回值Option<String> opt = userService.findUserForOpt("1");System.out.println("The Opt user is:" + opt.getClass());//阻塞直到有返回值String user = userService.findUser("1");System.out.println("The user is: " + user);}}
自定义扩展
Akka 的扩展需要依赖 Extensions API ,它包含两个概念:Extension和 ExtensionId 。Extension 表示一个可用的扩展组件,它对每一个ActorSystem 都是唯一的,即每次通过同一个 ActorSystem 得到的Extension 对象都是同一个。ExtensionId 是用来创建及查找 Extension 的组件,将其配置在*.conf 中可以让 ActorSystem 在创建阶段加载 Extension 。
接下来我们将要演示的示例场景是:某个 ActorSystem 需要和外界做 RPC 调用,而远程服务地址和端口是可配置的。
首先,我们需要在application.conf 文件中定义配置项:
akkademo{server=serverdemo.ioport=1234}
该配置包含 RPC 的 server 地址以及端口,它们会在加载时传入Extension 对象,Extension 的实现如下:
static class RPCExtension implements Extension {private String server;private int port;public RPCExtension(String server, int port) {this.server = server;this.port = port;}//模拟RPC调用public void rpcCall(String cmd) {System.out.println("call " + cmd + "-->" + server + ":" + port);}}
它实现了 Extension 接口,其他地方和普通 Java Class 无异。为了使该类对象能被 Actor-System 查找并绑定,需要再定义一个 ExtensionId 类型:
static class RPCExtProvider extends AbstractExtensionId<RPCExtension> {private static RPCExtProvider provider = new RPCExtProvider();@Overridepublic RPCExtension createExtension(ExtendedActorSystem system) {Config config = system.settings().config();String server = config.getString("akkademo.server");int port = config.getInt("akkademo.port");return new RPCExtension(server, port);}public static RPCExtProvider getInstance() {return provider;}}
该类继承了 AbstractExtensionId 并实现了 createExtension 方法,该方法主要用于 Extension 组件的创建,它的 ExtendedActorSystem 参数即当前环境下的 ActorSystem 对象引用,所以可以直接通过它来获取 Config 对象,进而读取配置信息。在使用它查找 Extension 时,需要调用AbstractExtensionId 提供的 get 方法:
RPCExtension rpcExt = RPCExtProvider.getInstance().get(system);rpcExt.rpcCall("hello");
当调用 get 方法时,RPCExtProvider.createExtension 会被自动调用一次,假如将该类配置在 akka.extensions 里,该方法会在 ActorSystem 创建阶段自动调用一次。
Akka Stream
实际项目中往往离不开对数据的操作,这些数据可能来自很多地方,比如文件、网络或者数据库,我们一般把这些地方叫作数据源。在得到这些数据后,我们通常需要对它们做诸如提取、转换的处理,然后将它们输出到某个目的地,或者展示给用户。在这个过程中,我们需要考虑一个很重要的问题:当数据源源不断地从外部「流」进来时,我们该如何利用有限的资源高效地处理它们。
Akka 的 Streams 模块为解决这类问题提供了很好的思路。Akka Streams 建立在现有的 Actor 模型之上,它将所有的处理过程抽象成异步&并行执行的函数,而数据将会在这些函数内流动并得到处理,这种做法极大提高了整个计算的效率。假如我们把数据的流向简单地理解成「输入——输出」,那么在一个「流」里,可能存在多个「输入——输出」的操作,这些操作可以作为独立的组件而存在,在你需要它们时,将它们一个个装配起来即可。从这点可以看出,Akka Streams 为我们提供了一个简洁并易于扩展的编程模型。Akka Streams 另外一个特点是它可以让程序在有限资源(内存)下高效地处理大量数据,这其中离不开对内部缓冲池的有效控制,假如把数据的两端看作生产者和消费者,那么当数据的消费速度跟不上生产速度时,它就会减慢生产速度,反之亦然,这个行为被称为「背压」(BackPressure ),它也是一个流量控制的手段。
Streams 组件
Akka Streams 的几个重要组件。
- Source:产生一个输出,它的下游在处理时会接收它的数据。
- Sink:需要一个输入,它通常是流处理的最后一个阶段。
- Flow:拥有一个输入和输出,它包含一些类似集合的操作,可以做一些数据转换、过滤等操作。
- RunnableGraph :当你拥有 Source、Sink 等结构后,还需要将它们连接在同一个管道上才能真正工作,此时我们需要构建一个RunnableGraph 对象,为最后的执行(run)做好准备工作。
一个流总是由 Source 开始,它是流的起点,也是数据的来源,你可以从集合或者文件等数据源中构建一个 Source,然后将其经过 Flow(可以有多个)的转换或过滤,最后使用 Sink 来进行最后的处理。
由于在 Akka 中,Streams 并不属于其核心模块,所以在使用它时需要先加入以下 maven 依赖:
<dependency><groupId>com.typesafe.akka</groupId><artifactId>akka-stream_2.13</artifactId><version>2.5.23</version></dependency>
一个简单代码样例:
ActorSystem system = ActorSystem.create("sys");// 数据来源、流的起点// Source 包括两个泛型:第一个泛型表示它产生的数据类型,第二个泛型表示运行时产生的其他辅助数据,假如没有则设置为 NotUsed。Source<Integer, NotUsed> source = Source.range(1, 5);// 定义sink,用来循环打印数据,此时Sink<Integer, CompletionStage<Done>> sink = Sink.foreach(System.out::println);// 使用sink操作数据,此时会创建出一个RunnableGraph对象RunnableGraph<NotUsed> graph = source.to(sink);// 当执行 RunnableGraph.run 方法时,需要传入一个 Materializer 对象,它主要用来给流分配 Actor 并驱动其执行。Materializer materializer = ActorMaterializer.create(system);graph.run(materializer);
构建Source
1. 从集合中构建 Source
List<String> list = new ArrayList<String>();list.add("sh");list.add("bj");list.add("nj");Source<String,NotUsed> s1=Source.from(list);s1.runForeach(System.out::println, materializer);
2. 从 Future 中构建 Source
Source<String,NotUsed> s2=Source.fromFuture(Futures.successful("HelloAkka!"));
3. 重复生成元素,取前N个元素
// 重复的生成元素Source<String, NotUsed> s3 = Source.repeat("Hello");// 取出前5个s3.limit(5).runForeach(System.out::println, materializer);
4. 使用 FileIO API 从文件中构建 Source,可将文件内容作为流处理的输入
Source<ByteString, CompletionStage<IOResult>> source = FileIO.fromPath(Paths.get("demo_in.txt"));
构建 Sink
1. 使用 Sink 循环出每个元素。
Sink<Integer,CompletionStage<Done>> sink1=Sink.foreach(System.out::println);
2. 使用 Sink 做 fold 运算,该运算会将 fold 的第一个参数作为初始值传入后面函数中的 x,每次计算后将结果继续作为下一次计算的参数输入。runWith 会将 Source 和 Sink 连接起来并运行。
Sink<Integer, CompletionStage<Integer>> sink2 = Sink.fold(1, (x,y) -> x*y);CompletionStage<Integer> r1 = Source.range(1, 5).runWith(sink2,materializer);r1.thenAccept(System.out::println);// 1*2*3*4*5=120
3. 使用 Sink 做 reduce 运算,该运算和 fold 类似,不过没有初始参数。
Sink<Integer,CompletionStage<Integer>> sink3=Sink.reduce((x,y)->x+y);CompletionStage<Integer> r2= Source.range(1, 5).runWith(sink3,materializer);r2.thenAccept(System.out::println);// 1+2+3+4+5=15
4. 使用 FileIO API 构建输出流的 Sink,结合 Source 可以实现简单的文件复制功能。
Sink<ByteString, CompletionStage<IOResult>> sink = FileIO.toPath(Paths.get("demo_out.txt"));
构建 Flow
Flow 需要一个输入和输出,一般作为中间过程而存在,在一个流操作中,我们可以包装多个 Flow 一起使用

在使用时,Flow 组件通过调用 Source.via 方法附加在 Source 上,此时会构建一个新的 Source 对象,同时它也可以通过调用 Flow.to 方法附加在 Sink 上,此时会构建一个新的 Sink 对象。下面代码演示了这个过程:
Flow<String, Integer, NotUsed> flow = Flow.of(String.class).map(x -> {return Integer.parseInt(x) * 3;});Sink<Integer, CompletionStage<Done>> sink = Sink.foreach(System.out::println);//list是一个包含5个元素的集合,代码略...Source.from(list).via(flow).runWith(sink, materializer);
这段代码采用 via 方法将 Flow 组件附加在 Source 上,它实现的功能是:通过字符串集合构建出一个 Source 对象,然后将每个字符串取出来转换成数字并做相应计算,再使用 Sink.foreach 打印出来,其中转换的过程依赖于 Flow.map 方法来实现。如前面所说,我们也可以将 Flow 组件附加在 Sink 上以构建新的 Sink 组件,如:
Source.from(list).runWith(flow.to(sink), materializer);
通过这个例子还可以看出,流操作和集合非常相似,但是大家要注意,我们仍然不能把流等同于集合,它们之间有个很大的区别是:流的大小往往是未知的,无界的,而集合的大小一般都是已知的。所以在处理流时,你事先不需要知道要处理多少数据,生产者可能会源源不断地流入数据进来,流的底层能保证在有限的资源下处理「无限」的数据。所以实际上,它们的底层实现也是有很大区别的。
组合 Source、Sink
在前面的例子中,我们分别将 Flow 附加在 Source 和 Sink 上,由此创建了一个新的 Source 和 Sink 对象,实际上这个过程可以看成是一种「输入输出」的组合。
由于 Source 是一个产生输出的组件,当它和 Flow 组合时,会生成一个拥有输出的 Source;同理,由于 Sink 是一个需要输入的组件,当它和 Flow 组合时,会生成一个需要输入的 Sink,这两种情况在前面已经实现过,这里不再给出示例。下图中的第三种情况是 Sink 和 Source 组合,根据它们的结构特点,可以生成一个拥有输入输出的 Flow,下面还有示例代码:
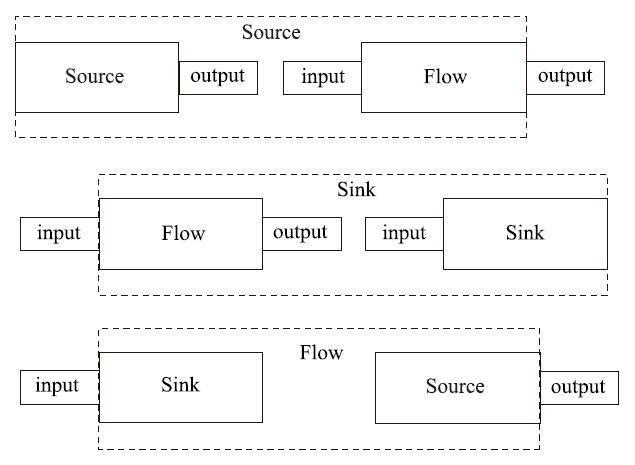
Flow<String, Integer, NotUsed> flow = Flow.fromSinkAndSource(Sink.foreach(System.out::println), Source.range(1, 3));
实际上,还有一种常见的情况是多个 Flow 的组合,这通过 Flow.via 方法实现,很显然,这种组合会生成一个 Flow 组件。
日志处理小项目参见github。

若有收获,就点个赞吧
0 人点赞
