- 引言
- 1.elasticsearch基本概念
- 2.linux ES的安装(elasticsearch-7.3.2)
- 3.elasticsearch-head 的安装
- 4.kibana的安装
- 写请求原理
- 5.RESTful API
- 6.中文分词
- 7.全文搜索
- 8.Elasticsearch集群
- 一台机器搭建集群(一)
- 一台机器搭建集群(二)
- ElasticStack日志收集
- 数据导入
引言
什么是elasticsearch?
ElasticSearch是一个分布式,高性能、高可用、可伸缩的搜索和分析系统
什么是Elastic Stack?
Elastic Stack,前身缩写是ELK,就是ElasticSearch + LogStash + Kibana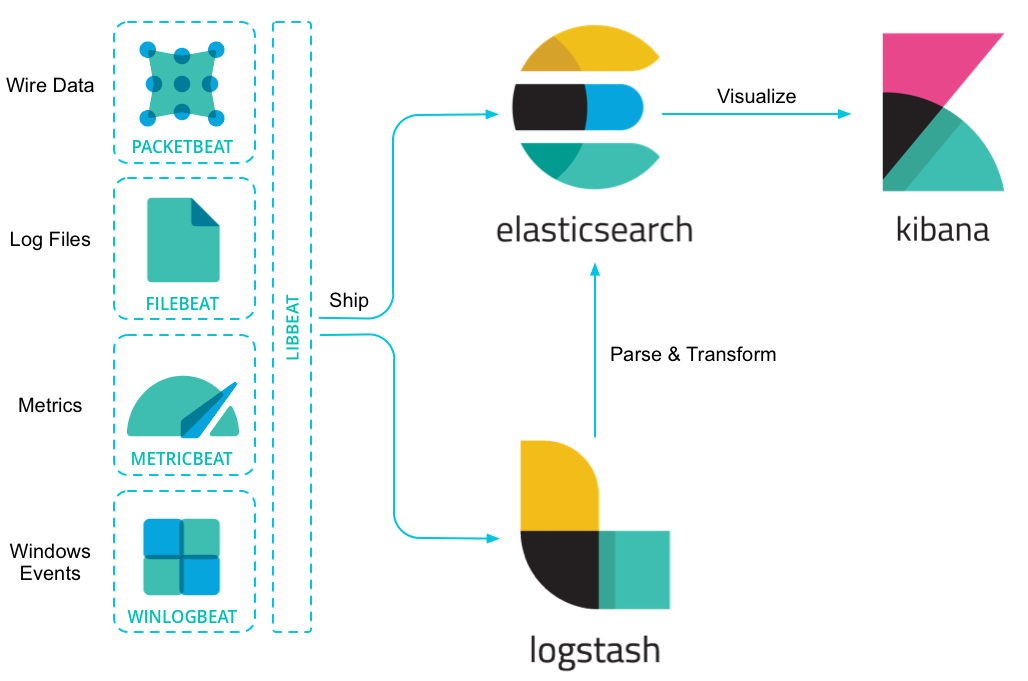
ES的使用场景:
- 网上商场,搜索商品.
- ES配合logstash,kibana,日志分析.
为什么要使用elasticsearch?
假设用数据库做搜索,当用户在搜索框输入“四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
1.elasticsearch基本概念
近实时(NRT)
ES是一个近实时的搜索引擎(平台),代表着从添加数据到能被搜索到只有很少的延迟。(大约是1s)
文档
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单元。可以把文档理解为关系型数据库中的一条记录。文档会被序列化成json格式,保存在Elasticsearch中。同样json对象由字段组成,给个字段都有自己的类型(字符串,数值,布尔,二进制,日期范围类型)。当我们创建文档时,如果不指定类型,Elasticsearch会帮我们自动匹配类型。每个文档都一个ID,你可以自己指定,也可以让Elasticsearch自动生成。json格式,支持数组/嵌套,在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
索引
索引是具有某种相似特性的文档集合。例如,您可以拥有客户数据的索引、产品目录的另一个索引以及订单数据的另一个索引。索引由一个名称(必须全部是小写)标识。在单个集群中,您可以定义任意多个索引。Index体现了逻辑空间的概念,每个索引都有自己的mapping定义,用于定义包含文档的字段名和字段类型。Index体现了物理空间的概念,索引中的数据分散在shard上。可以将其暂时理解为 MySql中的 database。
索引的mapping和setting
- mapping:定义文档字段的类型
- setting:定义不同数据的分布
类型
一个索引可以有多个类型。例如一个索引下可以有文章类型,也可以有用户类型,也可以有评论类型。在一个索引中不能再创建多个类型,在以后的版本中将删除类型的整个概念。
从6.0开始,type已经被逐渐废弃。在7.0之前,一个index可以设置多个types。7.0开始一个索引只能创建一个type(_doc)
节点
节点是一个Elasticsearch实例,本质上就是一个java进程,节点也有一个名称(默认是随机分配的),当然也可以通过配置文件配置,或者在启动的时候,-E node.name=node1指定。此名称对于管理目的很重要,因为您希望确定网络中的哪些服务器对应于ElasticSearch集群中的哪些节点。
在Elasticsearch中,节点的类型主要分为如下几种:
- master eligible节点:
每个节点启动后,默认就是master eligible节点,可以通过node.master: false 禁止
master eligible可以参加选主流程,成为master节点
当第一个节点启动后,它会将自己选为master节点
每个节点都保存了集群的状态,只有master节点才能修改集群的状态信息 - data节点
可以保存数据的节点。负责保存分片数据,在数据扩展上起到了至关重要的作用 - Coordinating 节点
负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
每个节点默认都起到了Coordinating node的职责
开发环境中一个节点可以承担多个角色,生产环境中,建议设置单一的角色,可以提高性能等
分片
索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。例如,占用1TB磁盘空间的10亿个文档的单个索引可能不适合单个节点的磁盘,或者速度太慢,无法单独满足单个节点的搜索请求。
为了解决这个问题,ElasticSearch提供了将索引细分为多个片段(称为碎片)的能力。创建索引时,只需定义所需的碎片数量。每个分片(shard)本身就是一个完全功能性和独立的“索引”,可以托管在集群中的任何节点上。
为什么要分片?
- 它允许您水平拆分/缩放内容量
- 它允许您跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量
如何分配分片以及如何将其文档聚合回搜索请求的机制完全由ElasticSearch管理,并且对作为用户的您是透明的。主分片数在索引创建时指定,后续不允许修改,除非Reindex
分片副本
在随时可能发生故障的网络/云环境中,非常有用,强烈建议在碎片/节点以某种方式脱机或因任何原因消失时使用故障转移机制。为此,ElasticSearch允许您将索引分片的一个或多个副本复制成所谓的副本分片,简称为副本分片。
为什么要有副本?
- 当分片/节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始/主分片所在的节点上。
- 允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,每个索引可以分割成多个分片。索引也可以零次(意味着没有副本)或多次复制。复制后,每个索引将具有主分片(从中复制的原始分片)和副本分片(主分片的副本)。
可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您还可以随时动态更改副本的数量。您可以使用收缩和拆分API更改现有索引的分片数量,建议在创建索引时就考虑好分片和副本的数量。
默认情况下,ElasticSearch中的每个索引都分配一个主分片和一个副本,这意味着如果集群中至少有两个节点,则索引将有一个主分片和另一个副本分片(一个完整副本),每个索引总共有两个分片。
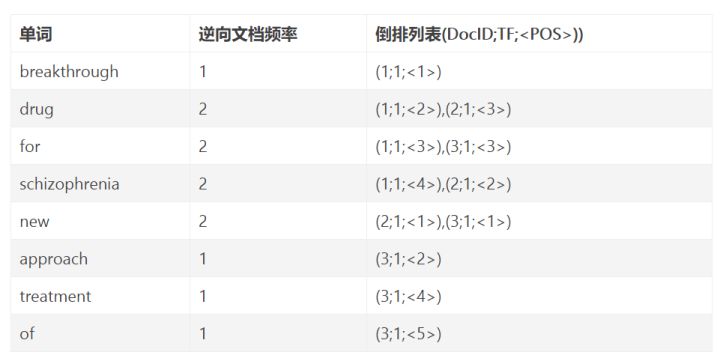
倒排索引

- DocID:出现某单词的文档ID
- TF(词频):单词在该文档中出现的次数
- POS:单词在文档中的位置
2.linux ES的安装(elasticsearch-7.3.2)
1.下载elasticsearch-7.3.2 tar包 下载地址https://www.elastic.co/cn/downloads/elasticsearch
2.上传到linux,解压 tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz
3.进入解压后的 elasticsearch-7.3.2文件夹的bin目录下 执行./elasticsearch
执行结果如下: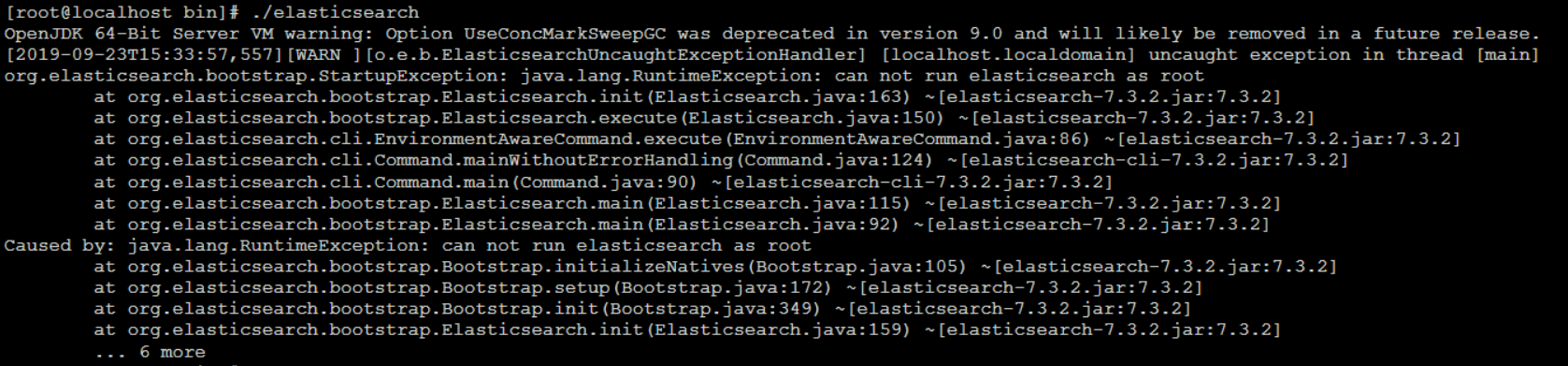
这个错误,是因为使用root用户启动elasticsearch,elasticsearch是不允许使用root用户启动的
在6.xx之前,可以通过root用户启动。但是发现黑客可以透过elasticsearch获取root用户密码,所以为了安全性,在6版本之后就不能通过root启动elasticsearch
解决方案如下:
groupadd taibai
useradd taibai -g taibai
cd /opt [elasticsearch-7.3.2所在路径]
chown -R taibai:taibai elasticsearch-7.3.2
修改配置
1、调整jvm内存大小(机器内存够也可不调整)
vim config/jvm.options
-Xms512m
-Xmx512m
2、修改network配置,支持通过ip访问
vim config/elasticsearch.yml
cluster.name=luban
node.name=node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: [“node-1”]
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
vm最大虚拟内存,max_map_count[65530]太低,至少增加到[262144]
vim /etc/sysctl.conf
vm.max_map_count=655360
sysctl -p 使配置生效
descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
最大文件描述符[4096]对于elasticsearch进程可能太低,至少增加到[65536]
vim /etc/security/limits.conf
* soft nofile 65536* hard nofile 131072* soft nproc 2048* hard nproc 4096* 所有用户nofile - 打开文件的最大数目noproc - 进程的最大数目soft 指的是当前系统生效的设置值hard 表明系统中所能设定的最大值
max number of threads [2048] for user [tongtech] is too low, increase to at least [4096]
用户的最大线程数[2048]过低,增加到至少[4096]
vim /etc/security/limits.d/90-nproc.conf
* soft nproc 4096
启动:
su taibai
cd /opt/elasticsearch-7.3.2/bin
./elasticsearch 或 ./elasticsearch -d (以后台方式运行)
注意:注意开放端口或者关闭防火墙(centos7)
- 查询防火墙状态:firewall-cmd —state
- 关闭防火墙:systemctl stop firewalld.service
- 开启防火墙: systemctl start firewalld.service
- 禁止firewall开机启动:systemctl disable firewalld.service
安装成功: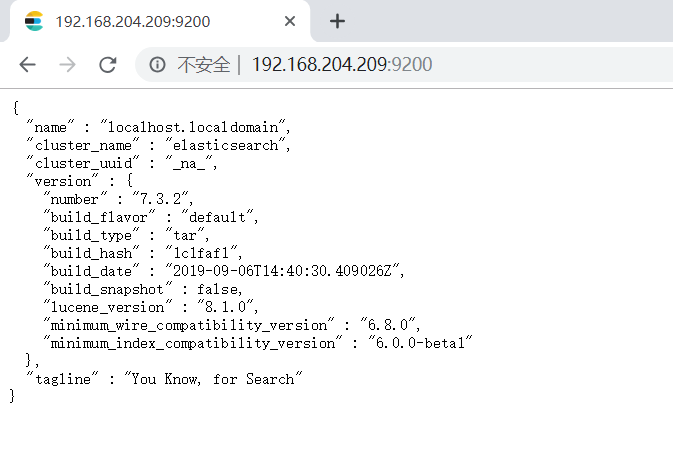
3.elasticsearch-head 的安装
google应用商店下载插件安装(需翻墙):

4.kibana的安装
1.下载kibana-7.3.2-linux-x86_64.tar.gz https://www.elastic.co/cn/downloads/kibana
2.上传至linux系统中并解压 tar -zxvf kibana-7.3.2-linux-x86_64.tar.gz
3.vim kibana-7.3.2-linux-x86_64/config/kibana.yml
server.port: 5601server.host: "0.0.0.0"i18n.locale: "zh-CN"
4.cd kibana-7.3.2-linux-x86_64/bin
5, ./kibana —allow-root
6.访问kibana
写请求原理
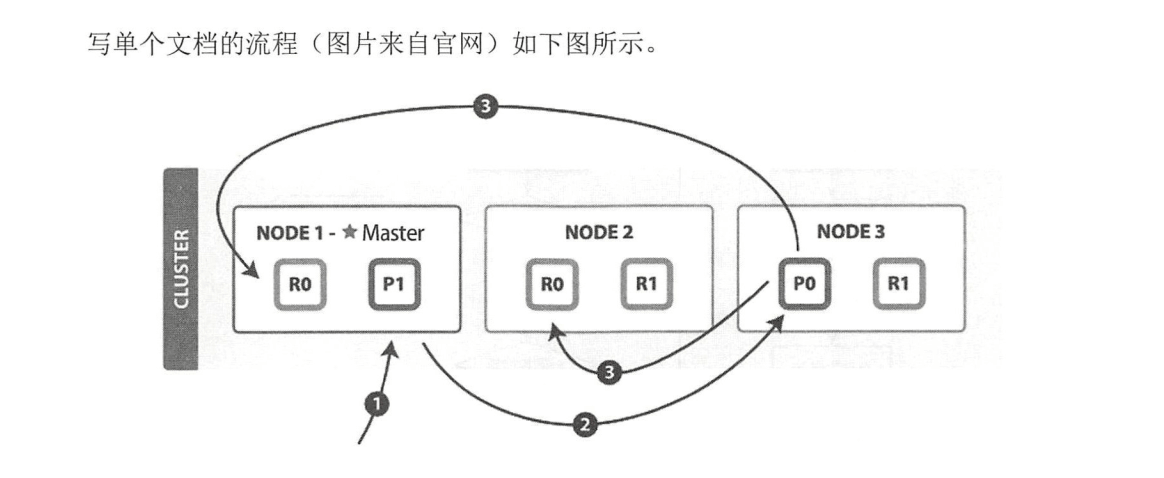
以下是写单个文档所需的步骤:
(1 )客户端向 NODE I 发送写请求。
(2)检查Active的Shard数。
(3) NODEI 使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片 0 的主分片位于 NODE3 ,因此请求被转发到 NODE3 上。
( 4 ) NODE3 上的主分片执行写操作 。 如果写入成功,则它将请求并行转发到 NODE I 和
NODE2 的副分片上,等待返回结果 。当所有的副分片都报告成功, NODE3 将向协调节点报告
成功,协调节点再向客户端报告成功 。
在客户端收到成功响应时 ,意味着写操作已经在主分片和所有副分片都执行完成。
1. 为什么要检查Active的Shard数?
ES中有一个参数,叫做wait_for_activeshards,这个参数是Index的一个setting,也可以在请求中带上这个参数。这个参数的含义是,在每次写入前,该shard至少具有的active副本数。假设我们有一个Index,其每个Shard有3个Replica,加上Primary则总共有4个副本。如果配置wait_for_activeshards为3,那么允许最多有一个Replica挂掉,如果有两个Replica挂掉,则Active的副本数不足3,此时不允许写入。
这个参数默认是1,即只要Primary在就可以写入,起不到什么作用。如果配置大于1,可以起到一种保护的作用,保证写入的数据具有更高的可靠性。但是这个参数只在写入前检查,并不保证数据一定在至少这些个副本上写入成功,所以并不是严格保证了最少写入了多少个副本。
在以前的版本中,是写一致性机制,现被替换为wait_for_activeshards
one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
quorum:要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
写一致性的默认策略是 quorum,即多数的分片(其中分片副本可以是主分片或副分片)在
写入操作时处于可用状态。
put /index/type/id?consistency=quorumquroum = int( (primary + number_of_replicas) / 2 ) + 1
| 参数 | 简 介 |
|---|---|
| version | 设置文档版本号。主要用于实现乐观锁 |
| version_type | 详见版本类型 |
| op_type | 可设置为 create 。 代表仅在文档不存在时才写入 。 如果文档己存在,则写请求将失败 |
| routing | ES 默认使用文档 ID 进行路由,指定 routing 可使用 routing 值进行路由 |
| wait_for_active_shards | 用于控制写一致性,当指定数量的分片副本可用时才执行写入,否则重试直至超时 。默认为 l , 主分片可用 即执行写入 |
| refresh | 写入完毕后执行 refresh ,使其对搜索可见 |
| timeout | 请求超时时间 , 默认为 l 分钟 |
| pipeline | 指定事先创建好的 pipeline 名称 |
写入Primary完成后,为何要等待所有Replica响应(或连接失败)后返回
在更早的ES版本,Primary和Replica之间是允许异步复制的,即写入Primary成功即可返回。但是这种模式下,如果Primary挂掉,就有丢数据的风险,而且从Replica读数据也很难保证能读到最新的数据。所以后来ES就取消异步模式了,改成Primary等Replica返回后再返回给客户端。
因为Primary要等所有Replica返回才能返回给客户端,那么延迟就会受到最慢的Replica的影响,这确实是目前ES架构的一个弊端。之前曾误认为这里是等wait_for_active_shards个副本写入成功即可返回,但是后来读源码发现是等所有Replica返回的。
如果Replica写入失败,ES会执行一些重试逻辑等,但最终并不强求一定要在多少个节点写入成功。在返回的结果中,会包含数据在多少个shard中写入成功了,多少个失败了
5.RESTful API
1.创建空索引
PUT /taibai{"settings": {"number_of_shards": "2", //分片数"number_of_replicas": "0", //副本数"write.wait_for_active_shards": 1}}修改副本数PUT taibai/_settings{"number_of_replicas" : "2"}
2.删除索引
DELETE /taibai
3.插入数据
//指定idPOST /taibai/_doc/1001{"id":1001,"name":"张三","age":20,"sex":"男"}//不指定id es帮我们自动生成POST /taibai/_doc{"id":1002,"name":"三哥","age":20,"sex":"男"}
4.更新数据
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新
PUT /taibai/_doc/1001{"id":1009,"name":"太白","age":21,"sex":"哈哈"}
4.1局部更新:
其实es内部对partial update的实际执行和传统的全量替换方式是几乎一样的,其步骤如下
- 内部先获取到对应的document;
- 将传递过来的field更新到document的json中(这一步实质上也是一样的);
- 将老的document标记为deleted(到一定时候才会物理删除);
- 将修改后的新的document创建出来
POST /taibai/_update/1001{"doc":{"age":23}}
替换和更新的不同:替换是每次都会去替换,更新是有新的东西就更新,没有新的修改就不更新,更新比替换的性能好
5.删除数据
DELETE /taibai/_doc/1001
6.0根据id搜索数据
GET /taibai/_doc/6_h43W0BdTjVHQ-cgnv2
6.1搜索全部数据
GET /taibai/_search 默认最多返回10条数据POST /bank/_search{"query": { "match_all": {} },"sort": [{"属性名": {"order": "asc"}}]}took Elasticsearch运行查询需要多长时间(以毫秒为单位)timed_out 搜索请求是否超时_shards 搜索了多少碎片,并对多少碎片成功、失败或跳过进行了细分。max_score 找到最相关的文档的得分hits.total.value 找到了多少匹配的文档hits.sort 文档的排序位置(当不根据相关性得分排序时)hits._score 文档的相关性评分(在使用match_all时不适用)
6.2关键字搜索数据
GET /taibai/_search?q=age:23 查询年龄等于23的
6.3DSL搜索
POST /taibai/_search{"query" : {"match" : { //查询年龄等于23的"age" : 23}}}//查询地址等于mill或者laneGET /bank/_search{"query": { "match": { "address": "mill lane" } }}//查询地址等于(mill lane)的GET /bank/_search{"query": { "match_phrase": { "address": "mill lane" } }}//注意:match 中如果加空格,那么会被认为两个单词,包含任意一个单词将被查询到//match_parase 将忽略空格,将该字符认为一个整体,会在索引中匹配包含这个整体的文档。
POST /taibai/_search //查询年龄大于20 并且性别是男的{"query": {"bool": {"filter": {"range": {"age": {"gt": 20}}},"must": {"match": {"sex": "男"}}}}}
6.4高亮显示
POST /taibai/_search //这里会分词搜索{"query": {"match": {"name": "张三"}},"highlight": {"fields": {"name": {}}}}
6.5聚合
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-aggregations.html
avg :平均值
max:最大值
min:最小值
sum:求和
例如:查询平均年龄 (如果不指定size等于0,则还会返回10条数据)
POST /bank/_search{"aggs": {"taibai": { //自定义名字"avg": { //什么类型"field": "age" //那个字段}}},"size": 0}
使用脚本
POST /bank/_search{"aggs": {"taibai": {"avg": {"script": {"source": "doc.age.value"}}}},"size": 0}
cardinality : 去重统计
例如:
POST /bank/_search{"aggs": {"taibai": {"cardinality": {"field": "age"}}},"size": 0}
extended_stats扩展统计聚合
POST /bank/_search{"aggs": {"taibai": {"extended_stats": {"field": "age"}}},"size": 0}
value_count值计数统计
可以理解为统计个数
terms词聚合
基于某个field,该 field 内的每一个【唯一词元】为一个桶,并计算每个桶内文档个数。默认返回顺序是按照文档个数多少排序。
POST /bank/_search{"aggs": {"taibai": {"terms": {"field": "age"}}},"size": 0}
top_hits最高匹配权值聚合
获取到每组前n条数据,相当于sql 中Top(group by 后取出前n条)。它跟踪聚合中相关性最高的文档
POST /bank/_search{"aggs": {"taibai": {"terms": {"field": "age"},"aggs": {"count": {"top_hits": {"size": 3}}}}},"size": 0}
range范围
POST bank/_search{"aggs": {"group_by_age": {"range": {"field": "age","ranges": [{"from": 20,"to": 30},{"from": 30,"to": 40},{"from": 40,"to": 50}]}}},"size": 0}
6.6查询响应
如果使用浏览器工具去查询,返回的json没有格式化,可在后面加参数pretty,返回格式化后的数据
http://192.168.204.209:9200/taibai/_doc/_fiK3W0BdTjVHQ-c0HvY?pretty
6.7指定响应字段
GET /taibai/_doc/9_iK3W0BdTjVHQ-czHuE?_source=id,name //只返回id和name字段
6.8去掉元数据
GET /taibai/_source/9_iK3W0BdTjVHQ-czHuE还可以去掉元数据并且返回指定字段GET /taibai/_source/9_iK3W0BdTjVHQ-czHuE?_source=id,name
6.9判断文档是否存在
HEAD /taibai/_doc/9_iK3W0BdTjVHQ-czHuE
7.批量操作
语法实例
POST _bulk{ "index" : { "_index" : "test", "_id" : "1" } }{ "field1" : "value1" }{ "delete" : { "_index" : "test", "_id" : "2" } }{ "create" : { "_index" : "test", "_id" : "3" } }{ "field1" : "value3" }{ "update" : {"_id" : "1", "_index" : "test"} }{ "doc" : {"field2" : "value2"} }
7.1批量查询
如果,某一条数据不存在,不影响整体响应,需要通过found的值进行判断是否查询到数据。
POST /taibai/_mget{"ids" : [ "8fiK3W0BdTjVHQ-cxntK", "9fiK3W0BdTjVHQ-cy3sI" ]}
7.2批量插入
POST _bulk{ "create" : { "_index" : "taibai", "_id" : "3" } }{"id":2002,"name":"name1","age": 20,"sex": "男"}{ "create" : { "_index" : "taibai", "_id" : "4" } }{"id":2003,"name":"name1","age": 20,"sex": "男"}
7.3批量删除
POST _bulk{ "delete" : { "_index" : "taibai", "_id" : "8PiK3W0BdTjVHQ-cxHs1" } }{ "delete" : { "_index" : "taibai", "_id" : "6vh43W0BdTjVHQ-cHXv8" } }
7.4批量修改
POST _bulk{ "update" : {"_id" : "4", "_index" : "taibai"} }{ "doc" : {"name" : "太白"} }{ "update" : {"_id" : "3", "_index" : "taibai"} }{ "doc" : {"name" : "太白"} }
8.分页查询
GET /taibai/_search?size=1&from=2 size: 结果数,默认10 from: 跳过开始的结果数,默认0
分页一
浅分页,它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询
GET /bank/_search{"sort": [{"age": {"order": "desc"}}],"size": 1000,"from": 0}
分页二
scroll 深分页,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景
- scroll=5m表示设置scroll_id保留5分钟可用。
- 使用scroll必须要将from设置为0。
- size决定后面每次调用_search搜索返回的数量
GET /bank/_search?scroll=5m{"size": 20,"from": 0,"sort": [{"_id": {"order": "desc"}}]}会返回一个:"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAB9AWTVIyY1pKcmhUT0dBT1FXLU5ueHdDQQ=="以后调用:GET _search/scroll{"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAABMIWTVIyY1pKcmhUT0dBT1FXLU5ueHdDQQ==","scroll": "5m"}删除scroll_idDELETE _search/scroll/DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAABMIWTVIyY1pKcmhUT0dBT1FXLU5ueHdDQQ==删除所有scroll_idDELETE _search/scroll/_all注意:根据官方文档的说法,scroll是非常消耗资源的,所以一个建议就是当不需要了scroll数据的时候,尽可能快的把scroll_id显式删除掉。scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个 scroll_id 不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
分页三
search_after 深分页,是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。但是需要注意,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。使用search_after必须要设置from=0。
GET /bank/_search{"size": 20,"from": 0,"sort": [{"_id": {"order": "desc"}}]}拿到返回最后一条数据的_idGET /bank/_search{"size": 20,"from": 0,"sort": [{"_id": {"order": "desc"}}],"search_after": [980]}
9.映射
前面我们创建的索引以及插入数据,都是由Elasticsearch进行自动判断类型,有些时候我们是需要进行明确字段类型的,否则,自动判断的类型和实际需求是不相符的。
自动判断的规则如下:
| JSON type | Field type |
|---|---|
| Boolean: true or false | “boolean” |
| Whole number: 123 | “long” |
| Floating point: 123.45 | “double” |
| String, valid date: “2014-09-15” | “date” |
| String: “foo bar” | “string” |
创建明确类型的索引:
PUT /goods{"settings": {"number_of_replicas": 0,"number_of_shards": 1},"mappings": {"properties": {"id": {"type": "long"},"sn": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word"},"price": {"type": "double"},"num": {"type": "integer"},"alert_num": {"type": "integer"},"image": {"type": "keyword"},"images": {"type": "keyword"},"weight": {"type": "double"},"create_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"update_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"spu_id": {"type": "keyword"},"category_id": {"type": "integer"},"category_name": {"type": "text","analyzer": "ik_smart"},"brand_name": {"type": "keyword"},"spec": {"type": "text","analyzer": "ik_max_word"},"sale_num": {"type": "integer"},"comment_num": {"type": "integer"},"status": {"type": "integer"}}}}
添加一个字段到现有的映射
PUT /luban/_mapping{"properties": {"isold": { //字段名"type": "keyword", //类型"index": false}}}
更新字段的映射
除了支持的映射参数外,您不能更改现有字段的映射或字段类型。更改现有字段可能会使已经建立索引的数据无效。如果您需要更改字段映射,创建具有正确映射一个新的索引和重新索引的数据转换成指数。重命名字段会使在旧字段名称下已建立索引的数据无效。而是添加一个alias字段以创建备用字段名称。
查看索引的映射
GET /luban/_mapping
查看指定字段的映射信息
GET /luban/_mapping/field/name
10.结构化查询
10.1term查询
term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型):
POST /taibai/_search{"query" : {"term" : {"age" : 20}}}
10.2terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去
做匹配:
POST /taibai/_search{"query" : {"terms" : {"age" : [20,27]}}}
10.3range查询
range 过滤允许我们按照指定范围查找一批数据:
gt :: 大于
gte :: 大于等于
lt :: 小于
lte :: 小于等于
POST /taibai/_search{"query": {"range": {"age": {"gte": 20,"lte": 22}}}}
10.4exists查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL 条件
包含这个字段就返回返回这条数据
POST /taibai/_search{"query": {"exists": {"field": "name"}}}
10.5 match查询
match 查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析 match 一下查询字符;如果用 match 下指定了一个确切值,在遇到数字,日期,布尔值或者 not_analyzed 的字符串时,它将为你搜索你
给定的值:
POST /taibai/_search{"query" : {"match" : {"name" : "三个小矮人"}}}match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于term的精确搜索,match是分词匹配搜索
10.6 bool查询
bool 查询可以用来合并多个条件查询结果的布尔逻辑,它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and 。
must_not :: 多个查询条件的相反匹配,相当于 not 。
should :: 至少有一个查询条件匹配, 相当于 or 。
这些参数可以分别继承一个查询条件或者一个查询条件的数组:
POST /taibai/_search{"query": {"bool": {"must": {"term": {"sex": "男"}},"must_not": {"term": {"age": "29"}},"should": [{"term": {"sex": "男"}},{"term": {"id": 1003}}]}}}
10.7过滤查询
查询年龄为20岁的用户。
POST /taibai/_search{"query": {"bool": {"filter": {"term": {"age": 20}}}}}
批量导入测试数据
该数据是使用www.json- http://generator.com/生成的,因此请忽略数据的实际值和语义,因为它们都是随机生成的。您可以从这里下载示例数据集(accounts.json)。将其提取到当前目录,然后按如下方式将其加载到集群中:
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@accounts.json"
官方文档练习案例:
1.给指定id加点年龄(age)
2.执行match_all操作,并按帐户余额降序对结果进行排序,并返回前10个
3.如何从搜索中返回两个字段,即帐号和余额
4.返回帐户为20的
5.返回地址中包含“mill”的所有帐户
6.返回地址中包含“mill”或“lane”的所有帐户
7.返回地址中包含“mill”和“lane”的所有帐户
8.地址中既不包含“mill”也不包含“lane”的所有帐户
9.返回所有40岁但不居住在ID的人(state不等于ID)的账户
10.使用bool查询返回余额在20000到30000之间的所有帐户,包括余额。换句话说,我们希望找到余额大于或等于20000,小于或等于30000的账户
11.按状态(state)对所有帐户进行分组,然后返回按count降序排列的前10个
12.按状态计算平均帐户余额(同样只针对按count降序排列的前10个状态)
13.基于之前(12)的聚合,我们现在按降序对平均余额排序
14.按照年龄等级(20-29岁,30-39岁,40-49岁)分组,然后按性别分组,最后得到每个年龄等级,每个性别的平均账户余额
POST /bank/_update/1{"script": "ctx._source.age+=5"}GET /bank/_search{"query": {"match_all": {}},"sort": [{"balance": {"order": "desc"}}]}GET /bank/_search{"query": {"match_all": {}},"_source": ["account_number","balance"]}GET /bank/_search{"query": {"match": {"account_number": "20"}}}GET /bank/_search{"query": {"match": {"address": "mill"}}}GET /bank/_search{"query": {"match": {"address": "mill lane"}}}GET /bank/_search{"query": {"bool": {"must": [{"match": {"address": "mill"}},{"match": {"address": "lane"}}]}}}GET /bank/_search{"query": {"bool": {"must_not": [{"match": {"address": "mill"}},{"match": {"address": "lane"}}]}}}GET /bank/_search{"query": {"bool": {"must": [{"term": {"age": {"value": 40}}}],"must_not": [{"match": {"state": "ID"}}]}}}GET /bank/_search{"query": {"bool": {"must": [{"range": {"balance": {"gte": 20000,"lte": 30000}}}]}}}GET /bank/_search{"aggs": {"status_group": {"terms": {"field": "state.keyword"}}},"size": 0}GET /bank/_search{"aggs": {"status_group": {"terms": {"field": "state.keyword"},"aggs": {"balance_avg": {"avg": {"field": "balance"}}}}},"size": 0}GET /bank/_search{"aggs": {"status_group": {"terms": {"field": "state.keyword","order": {"balance_avg": "asc"}},"aggs": {"balance_avg": {"avg": {"field": "balance"}}}}},"size": 0}GET /bank/_search{"aggs": {"age_range": {"range": {"field": "age","ranges": [{"from": 20,"to": 30},{"from": 30,"to": 40},{"from": 40,"to": 50}]},"aggs": {"gender_group": {"terms": {"field": "gender.keyword"},"aggs": {"balance_avg": {"avg": {"field": "balance"}}}}}}},"size": 0}
6.中文分词
6.0 Analyzer 的组成
- Character Filters (针对原始文本处理,例如,可以使用字符过滤器将印度阿拉伯数字( )转换为其等效的阿拉伯语-拉丁语(0123456789))
- Tokenizer(按照规则切分为单词),将把文本 “Quick brown fox!” 转换成 terms [Quick, brown, fox!],tokenizer 还记录文本单词位置以及偏移量。
- Token Filter(将切分的的单词进行加工、小写、刪除 stopwords,增加同义词)
6.1elasticsearch内置分词器
| Standard | 默认分词器 按词分类 小写处理 |
|---|---|
| Simple | 按照非字母切分,非字母则会被去除 小写处理 |
| Stop | 小写处理 停用词过滤(the,a, is) |
| Whitespace | 按空格切分 |
| Keyword | 不分词,当成一整个 term 输出 |
| Patter | 通过正则表达式进行分词 默认是 \W+(非字母进行分隔) |
| Language | 提供了 30 多种常见语言的分词器 |
6.2分词api
POST /_analyze{"analyzer":"standard","text":"tai bai"}POST /_analyze{"analyzer":"standard","text":"决战到天亮"}
英文分词 一般以空格分隔,中文分词的难点在于,在汉语中没有明显的词汇分界点,如果分隔不正确就会造成歧义。
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
6.3ik分词器安装
IK分词器 Elasticsearch插件地址:https://github.com/medcl/elasticsearch-analysis-ik
1.下载对应版本的zip包https://github.com/medcl/elasticsearch-analysis-pinyin/releases
2.可在Windows解压好,在plugins下创建pinyin文件夹
3.将解压内容放置在pinyin文件夹,重启
4.ik插件安装完成
5.测试中文分词器效果
POST /_analyze{"analyzer": "ik_max_word", 或者 //ik_smart"text": "决战到天亮"}
6.4拼音分词器
1.下载对应版本的zip包https://github.com/medcl/elasticsearch-analysis-pinyin/releases
2.可在Windows解压好,在plugins下创建pinyin文件夹
3.将解压内容放置在pinyin文件夹,重启
6.5自定义分词器
接受参数
| tokenizer | 一个内置的或定制的tokenizer。(必需) |
|---|---|
| char_filter | 一个可选的内置或自定义字符过滤器数组。 |
| filter | 一个可选的内置或定制token过滤器数组。 |
PUT my_index{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"type": "custom","tokenizer": "standard","char_filter": ["html_strip" //过滤HTML标签],"filter": ["lowercase", //转小写"asciifolding" //ASCII-折叠令牌过滤器 例如 à to a]}}}}}POST my_index/_analyze{"analyzer": "my_custom_analyzer","text": "Is this <b>déjà vu</b>?"}
创建一个中文+拼音的分词器(中文分词后拼音分词)
PUT my_index{"settings": {"analysis": {"analyzer": {"ik_pinyin_analyzer": {"type": "custom","tokenizer": "ik_smart","filter": ["pinyin_max_word_filter"]},"ik_pingying_smark": {"type": "custom","tokenizer": "ik_smart","filter": ["pinyin_smark_word_filter"]}},"filter": {"pinyin_max_word_filter": {"type": "pinyin","keep_full_pinyin": "true", #分词全拼如雪花 分词xue,hua"keep_separate_first_letter": "true",#分词简写如雪花 分词xh"keep_joined_full_pinyin": true #分词会quanpin 连接 比如雪花分词 xuehua},"pinyin_smark_word_filter": {"type": "pinyin","keep_separate_first_letter": "false", #不分词简写如雪花 分词不分词xh"keep_first_letter": "false" #不分词单个首字母 如雪花 不分词 x,h}}}}}PUT /my_index/_mapping{"properties": {"productName": {"type": "text","analyzer": "ik_pinyin_analyzer", #做文档所用的分词器"search_analyzer":"ik_pingying_smark" #搜索使用的分词器}}}POST /my_index/_doc{"productName": "雪花啤酒100L"}GET /my_index/_search{"query": {"match": {"productName": "雪Hua"}}}
7.全文搜索
7.1构建数据
PUT /test{"settings": {"index": {"number_of_shards": "1","number_of_replicas": "0"}},"mappings": {"properties": {"age": {"type": "integer"},"email": {"type": "keyword"},"name": {"type": "text"},"hobby": {"type": "text","analyzer": "ik_max_word"}}}}POST _bulk{ "create" : { "_index" : "test","_id": "1000"} }{"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}{ "create" : { "_index" : "test","_id": "1001"} }{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"}{ "create" : { "_index" : "test","_id": "1002"} }{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"}{ "create" : { "_index" : "test","_id": "1003"} }{"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、篮球"}{ "create" : { "_index" : "test","_id": "1004"} }{"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影、羽毛球"}
7.2单词搜索
POST /test/_search{"query": {"match": {"hobby": "音乐"}},"highlight": {"fields": {"hobby": {}}}}
7.3多词搜索
//搜索包含音乐和篮球的POST /test/_search{"query": {"match": {"hobby": "音乐 篮球"}},"highlight": {"fields": {"hobby": {}}}}//搜索包含音乐还有篮球的(and)POST /test/_search{"query": {"match": {"hobby": {"query": "音乐 篮球","operator": "and"}}},"highlight": {"fields": {"hobby": {}}}}GET /goods/_search{"query": {"bool": {"must": [{"range": {"price": {"gte": 1000,"lte": 2000}}},{"match": {"name": "2018女鞋"}},{"match": {"spec": "红色 黑色"}}],"must_not": [{"match": {"spec": "蓝色"}}]}}}//在Elasticsearch中也支持这样的查询,通过minimum_should_match来指定匹配度,如:70%;POST /test/_search{"query": {"match": {"hobby": {"query": "游泳 羽毛球","minimum_should_match": "70%"}}},"highlight": {"fields": {"hobby": {}}}}
7.4组合搜索
//搜索结果中必须包含篮球,不能包含音乐,如果包含了游泳,那么它的相似度更高。POST /test/_search{"query": {"bool": {"must": {"match": {"hobby": "篮球"}},"must_not": {"match": {"hobby": "音乐"}},"should": [{"match": {"hobby": "游泳"}}]}},"highlight": {"fields": {"hobby": {}}}}//默认情况下,should中的内容不是必须匹配的,如果查询语句中没有must,那么就会至少匹配其中一个。当然了,也可以通过minimum_should_match参数进行控制,该值可以是数字也可以的百分比。//minimum_should_match为2,意思是should中的三个词,至少要满足2个POST /test/_search{"query": {"bool": {"should": [{"match": {"hobby": "游泳"}},{"match": {"hobby": "篮球"}},{"match": {"hobby": "音乐"}}],"minimum_should_match": 2}},"highlight": {"fields": {"hobby": {}}}}
7.5权重
搜索关键字为“游泳篮球”,如果结果中包含了“音乐”权重为10,包含了“跑步”权重为2。
POST /test/_search{"query": {"bool": {"must": {"match": {"hobby": {"query": "游泳篮球","operator": "and"}}},"should": [{"match": {"hobby": {"query": "音乐","boost": 10}}},{"match": {"hobby": {"query": "跑步","boost": 2}}}]}},"highlight": {"fields": {"hobby": {}}}}
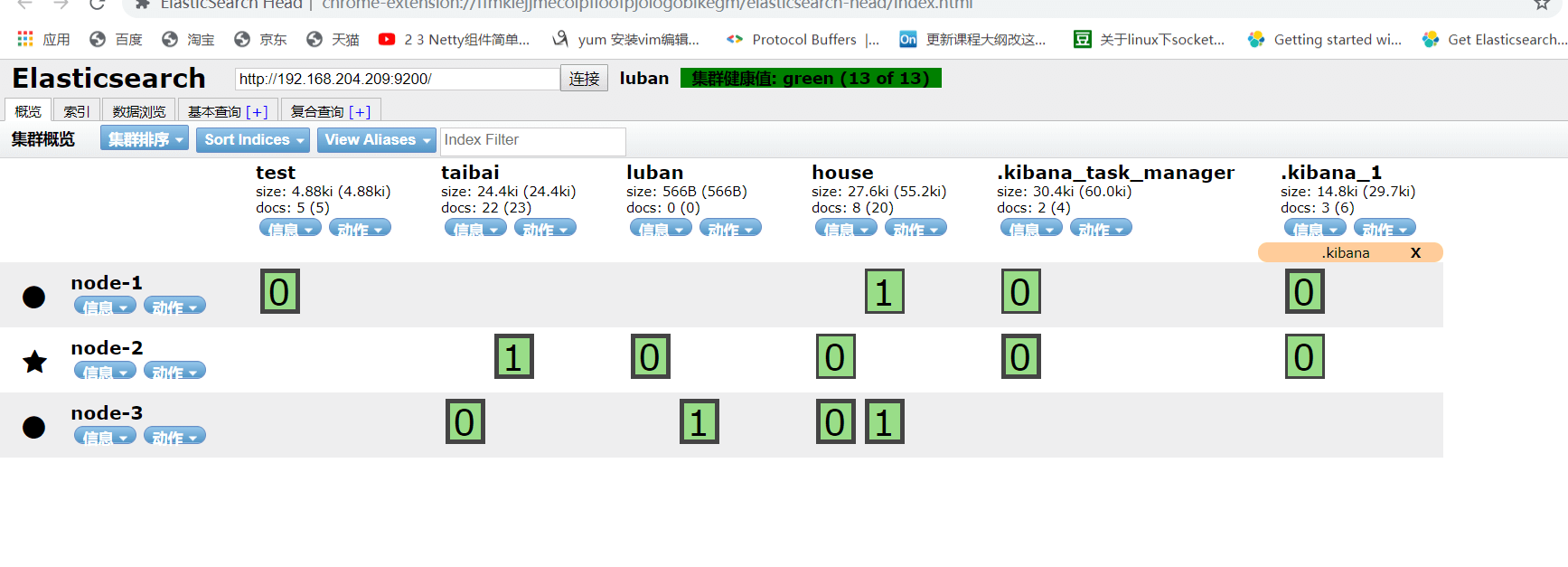
8.Elasticsearch集群
192.168.204.209 elasticsearch.yml
cluster.name: lubannode.name: node-1node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9200#参数设置一系列符合主节点条件的节点的主机名或 IP 地址来引导启动集群。cluster.initial_master_nodes: ["node-1"]# 设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接)discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]# 该参数就是为了防止”脑裂”的产生。定义的是为了形成一个集群,有主节点资格并互相连接的节点的最小数目。discovery.zen.minimum_master_nodes: 2# 解决跨域问题配置http.cors.enabled: truehttp.cors.allow-origin: "*"
192.168.204.203 elasticsearch.yml
cluster.name: lubannode.name: node-3node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9200cluster.initial_master_nodes: ["node-1"]discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]discovery.zen.minimum_master_nodes: 2http.cors.enabled: truehttp.cors.allow-origin: "*"
192.168.204.108 elasticsearch.yml
cluster.name: lubannode.name: node-2node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9200cluster.initial_master_nodes: ["node-1"]discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]discovery.zen.minimum_master_nodes: 2http.cors.enabled: truehttp.cors.allow-origin: "*"
启动后效果
一台机器搭建集群(一)
注意修改jvm.options
elasticsearch-7.3.2_node1
cluster.name: lubannode.name: node-1node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9200transport.port: 9300cluster.initial_master_nodes: ["node-1"]discovery.seed_hosts: ["192.168.204.209:9300", "192.168.204.209:9301","192.168.204.209:9302"]discovery.zen.minimum_master_nodes: 2http.cors.enabled: truehttp.cors.allow-origin: "*"
elasticsearch-7.3.2_node2
cluster.name: lubannode.name: node-2node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9201transport.port: 9301cluster.initial_master_nodes: ["node-1"]discovery.seed_hosts: ["192.168.204.209:9300", "192.168.204.209:9301","192.168.204.209:9302"]discovery.zen.minimum_master_nodes: 2http.cors.enabled: truehttp.cors.allow-origin: "*"
elasticsearch-7.3.2_node3
cluster.name: lubannode.name: node-3node.master: truenode.data: truenetwork.host: 0.0.0.0http.port: 9202transport.port: 9302cluster.initial_master_nodes: ["node-1"]discovery.seed_hosts: ["192.168.204.209:9300", "192.168.204.209:9301","192.168.204.209:9302"]discovery.zen.minimum_master_nodes: 2http.cors.enabled: truehttp.cors.allow-origin: "*"
分别启动:
./elasticsearch -p /tmp/elasticsearch_9200_pid -d./elasticsearch -p /tmp/elasticsearch_9201_pid -d./elasticsearch -p /tmp/elasticsearch_9202_pid -d
一台机器搭建集群(二)

新建目录:
注意赋予权限
chown -R taibai:taibai ES
分别启动:
./elasticsearch -d -E node.name=node-1 -E http.port=9200 -E transport.port=9300 -E path.data=/ES/data/node1 -E path.logs=/ES/logs/node1./elasticsearch -d -E node.name=node-2 -E http.port=9201 -E transport.port=9301 -E path.data=/ES/data/node2 -E path.logs=/ES/logs/node2./elasticsearch -d -E node.name=node-3 -E http.port=9202 -E transport.port=9302 -E path.data=/ES/data/node3 -E path.logs=/ES/logs/node3
https://blog.csdn.net/jiankunking/article/details/65448030
https://blog.csdn.net/lixiaohai_918/article/details/89569611
查看插件命令:./elasticsearch-plugin list
下载插件命令:./elasticsearch-plugin install analysis-icu
ElasticStack日志收集
1.安装filebeat
新建xxx.yml
filebeat.inputs:- type: logenabled: truepaths:- /taibai/logs/*.logoutput.logstash:hosts: ["192.168.204.209:5044"]#output.console:# pretty: true# enable: true#filebeat.inputs:# tags: ["web"] #添加自定义tag,便于后续的处理# fields: #添加自定义字段# from: taibai# fields_under_root: true #true为添加到根节点,false为添加到子节点中
启动 ./filebeat -e -c 配置文件名 -e输出到标准输出,默认输出到syslog和logs下 -c 指定配置文件
2.安装logstash
新建xxx.conf
input {beats {port => "5044"}}filter {mutate {split => {"message"=>","}}mutate {add_field => {"log" => "%{[message][0]}""userId" => "%{[message][1]}""visit" => "%{[message][2]}""date" => "%{[message][3]}"}}mutate {convert => {"log" => "string""userId" => "integer""visit" => "string""date" => "string"}}}output {elasticsearch {hosts => [ "192.168.204.209:9200"]}}#output {# stdout { codec => rubydebug }#}
启动: ./logstash -f 配置文件名
数据导入
1.使用logstash 导入数据
1.安装解压logstash
2.在conf目录下新建mysql.conf
input {jdbc {jdbc_driver_library => "/opt/mysql-connector-java-5.1.47.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://47.94.158.155:3306/test?serverTimezone=UCT"jdbc_user => "taibai"jdbc_password => "aq1sw2de"schedule => "* * * * *" #每分钟执行clean_run => truejdbc_default_timezone => "Asia/Shanghai"statement => "select id,sn,`name`,price,num,alert_num,image,images,weight,DATE_FORMAT(update_time,'%Y-%m-%d %T') as update_time,DATE_FORMAT(create_time,'%Y-%m-%d %T') as create_time,spu_id,category_id,category_name,brand_name,spec,sale_num,comment_num,`status` from goods where update_time>:sql_last_value and update_time<NOW() order by update_time desc"}}filter {ruby {code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"}ruby {code => "event.set('@timestamp',event.get('timestamp'))"}mutate {remove_field => ["timestamp"]}# ruby {# code => "event.set('update_time', event.get('update_time').time.localtime + 8*60*60)"# }# ruby {# code => "event.set('create_time', event.get('create_time').time.localtime + 8*60*60)"# }}output {elasticsearch{hosts => ["192.168.204.209"]index => "goods"document_id => "%{id}"}}
schedule
| 5 1-3 * | 从一月到三月每天早上5点的每一分钟都会执行。 |
|---|---|
| 0 | 会在每天每小时的第0分钟执行。 |
| 0 6 * America/Chicago | 每天早上6点(UTC/GMT -5)执行。 |
上课问题解释:上课时演示增加一条数据之后,导入到Elasticsearch数据是有的,但是有几个字段没有数据,可以发现没数据的几个字段是这条数据后面的几个字段,是因老师是在Navicat 直接添加,然而后面那几个字段可以为空,所以数据被添加到了数据库。总结来说就是前面添加了一条数据,没有后面那三个字段,后面我写那三个字段的时候相当于修改,然而修改我又没修改最后修改的时间字段(正常情况修改了数据需要修改最后更新时间字段),所有我们的sql查询不到我们修改的数据,导致elasticsearch中那条数据有几个字段没有
2.canal
1.mysql开启binlog日志
重启:service mysqld restart
2.安装启动canal_deployer
1.上传到linux,解压
2.修改canal_deployer/conf/example/instance.properties
## mysql serverIdcanal.instance.mysql.slaveId = 1234#position info,需要改成自己的数据库信息canal.instance.master.address = 127.0.0.1:3306canal.instance.master.journal.name =canal.instance.master.position =canal.instance.master.timestamp =#canal.instance.standby.address =#canal.instance.standby.journal.name =#canal.instance.standby.position =#canal.instance.standby.timestamp =#username/password,需要改成自己的数据库信息canal.instance.dbUsername = canalcanal.instance.dbPassword = canalcanal.instance.defaultDatabaseName =canal.instance.connectionCharset = UTF-8#table regexcanal.instance.filter.regex = .\*\\\\..\*
启动:bin/startup.sh
关闭:bin/stop.sh
3.安装canal_adapter
1.上传解压
2.修改canal_adapter/conf/application.yml
canal.conf:canalServerHost: 127.0.0.1:11111batchSize: 500syncBatchSize: 1000retries: 0timeout:mode: tcpsrcDataSources:defaultDS:url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=trueusername: rootpassword: 121212canalAdapters:- instance: examplegroups:- groupId: g1outerAdapters:-key: exampleKeyname: es6 # or es7hosts: 127.0.0.1:9300 # es 集群地址, 逗号分隔properties:mode: transport # or rest # 可指定transport模式或者rest模式# security.auth: test:123456 # only used for rest modecluster.name: elasticsearch # es cluster name
adapter将会自动加载 conf/es 下的所有.yml结尾的配置文件
3.修改适配器表映射文件
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值outerAdapterKey: exampleKey # 对应application.yml中es配置的keydestination: example # cannal的instance或者MQ的topicgroupId: # 对应MQ模式下的groupId, 只会同步对应groupId的数据esMapping:_index: mytest_user # es 的索引名称_type: _doc # es 的type名称, es7下无需配置此项_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配# pk: id # 如果不需要_id, 则需要指定一个属性为主键属性# sql映射sql: "select a.id as _id, a.name as _name, a.role_id as _role_id, b.role_name as _role_name,a.c_time as _c_time, c.labels as _labels from user aleft join role b on b.id=a.role_idleft join (select user_id, group_concat(label order by id desc separator ';') as labels from labelgroup by user_id) c on c.user_id=a.id"# objFields:# _labels: array:; # 数组或者对象属性, array:; 代表以;字段里面是以;分隔的# _obj: object # json对象etlCondition: "where a.c_time>='{0}'" # etl 的条件参数commitBatch: 3000 # 提交批大小
sql支持多表关联自由组合, 但是有一定的限制:
- 主表不能为子查询语句
- 只能使用left outer join即最左表一定要是主表
- 关联从表如果是子查询不能有多张表
- 主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)
- 关联条件只允许主外键的’=’操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
- 关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id 必须出现在主select语句中
Elastic Search的mapping 属性与sql的查询值将一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射.
4.bin目录下启动
**

若有收获,就点个赞吧
0 人点赞
