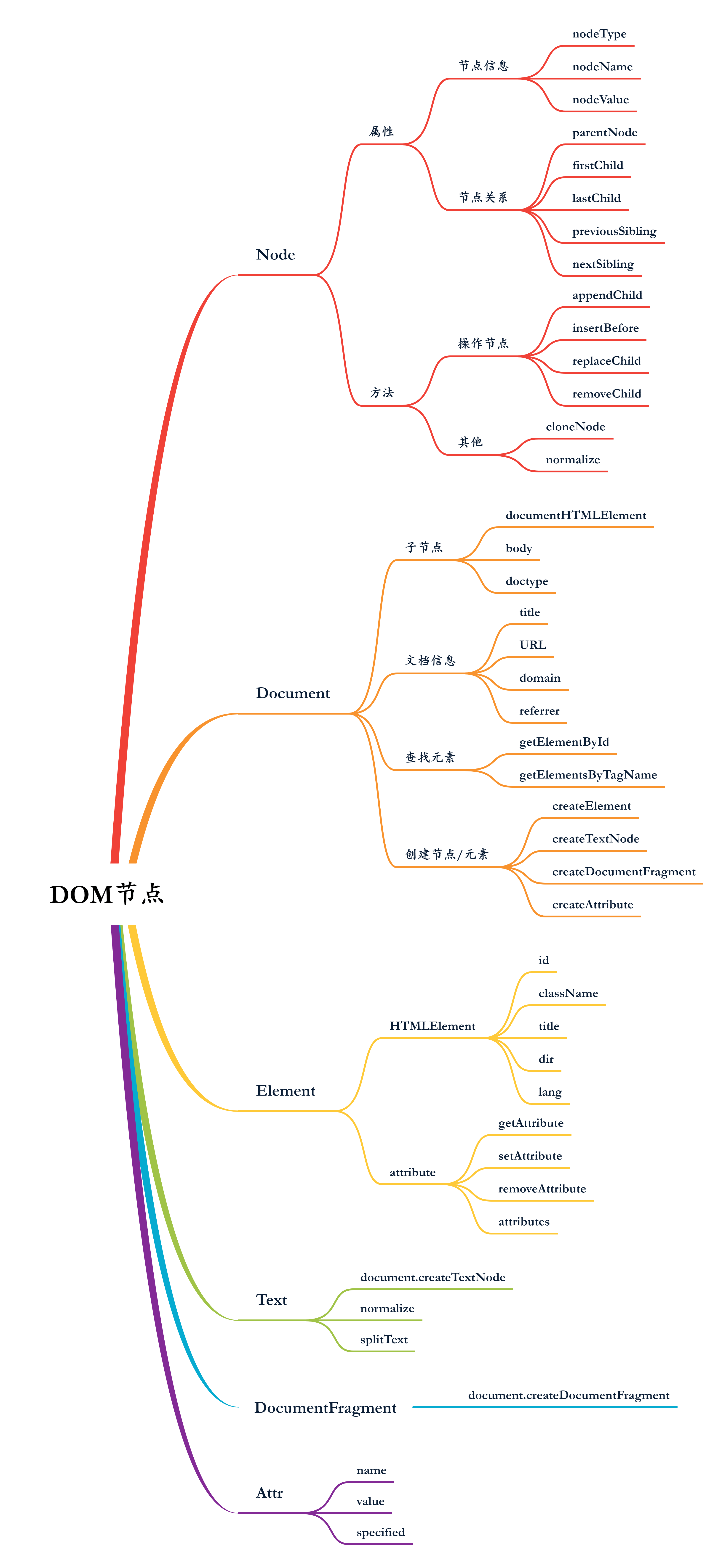
DOM 的全称为 Document Object Model,翻译为对象文本模型,它是一个针对于 HTML 的 API,它将 HTML 文档描绘为一棵层次化的树,DOM 规范了操作这个文档树的规范,例如添加、删除、移动等等操作。所有的浏览器都实现了(除了早版本的 IE) DOM 规范,这意味着开发人员在所有的浏览器中写的代码都是一样,不同为每一个浏览器写着不同的代码(这就是标准带来的好处)。
下面给出了 HTML 文档翻译成 DOM 树的例子

document 节点是每一个文档的根节点,HTML 文档中的元素都会被转化为 DOM 树中的节点。
Node
DOM 规定了一个 Node 类型的接口,DOM 树上的节点都实现了该类型,因此所有的节点都有着 Node 接口中规定的属性和方法,下面我们就具体介绍一下 Node 类型。
节点信息
虽然 HTML 元素以及文本内容都会被转化为节点,但是明显 document 节点,HTML 元素节点,以及文本节点等等它们之间的地位是不一样的,这意味着虽然大家都是 Node 类型的对象,但是却有着不同,每个节点都有着自己的类型,而 nodeType 属性正是用来表明节点类型的。
nodeType 的值为数字类型,根据 nodeType 的值不同,节点类型分为 12 种,如下
- Node.ELEMENT_NODE(1)
- Node.ATTRIBUTE_NODE(2)
- Node.TEXT_NODE(3)
- Node.CDATA_SECTION_NODE(4)
- Node.ENTITY_REFERENCE_NODE(5)
- Node.ENTITY_NODE(6)
- Node.PROCESSING_NODE(7)
- Node.COMMENT_NODE(8)
- Node.DOCUMENT_NODE(9)
- Node.DOCUMENT_TYPE_NODE(10)
- Node.DOCUMENT_FRAGMENT_NODE(11)
- Node.NOTATION_NODE(12)
看到上面罗列的一大堆节点类型,你内心肯定已经吓尿了,但是上面列出来的节点类型并不是每个都很重要,有的这辈子可能都不会遇到,在本篇文章中只会讲解常用的几种节点类型。
上面这些 Node 常量,与后面对应括号中的数字的值相等,如
Node.ELEMENT_NODE == 1; // true
除了 nodeType 属性以外,我们还可以通过 nodeName 和 nodeValue 来了解节点的信息,这两个属性具体的取值,与具体的节点类型有关,不同类型的 Node 节点,取值有所不同,在后面介绍具体的节点类型时,将会提到它们。
节点关系
DOM 树借鉴了家庭族谱的概念,使用父亲、孩子、兄弟等亲属关系来描述节点之间的关系,我们将对如下 DOM 树来描述节点之间的关系

每一个节点都有一个 childNodes 属性,它保存着它的所有子节点,该属性是一个 NodeList 对象,它是一个类数组,我们可以通过数字下标来访问父节点中的某个子节点,但它不是真正的数组。
对于上图来说,div 节点的 childNodes 就是由它的三个子节点 span h1 img 组成的 NodeList,我们可以通过下标是获取它的子节点,例如
div.childNodes[0] ==> spandiv.childNodes[1] ==> h1div.childNodes[2] ==> img
每个节点都有一个 parentNode,该属性的值是该节点的父节点,例如对于上图,span h1 img 的父节点都是 div 节点,即
span.parentNode == h1.parentNode == img.parentNode == div;
通过节点的 previousSibling 和 nextSibling 属性可以访问该节点的兄弟节点,正如它们名字所暗示的那样,previousSibling 是表示该节点的前节点,nextSibling 表示该节点后一个节点,如果该节点没有前一个节点,那么 previousSibling 的取值为 null,对于 nextSibling 也是同理,如下
h1.previousSibling == span;h1.nextSibling == img;img.nextSibling == null; // img 后面没有节点,所以 nextSibling 属性值为 null
每个节点都有 firstChild 和 lastChild 属性,它们的值分别代表的是该节点的第一个孩子节点和最后一个孩子节点,如果该节点没有子节点,那么这两个属性的值为 null,如下
div.firstChild == span;div.lastChild == img;span.firstChild == null;
每个节点都有一个 ownerDocument 属性,该属性指向该节点所在文档的 document 节点。
下图形象的展示了节点之间的关系

操作节点
Node 接口提供了几个方法用以操作节点,包括添加节点,删除节点,移动节点等等。
appendChild
该方法接收一个参数,为 Node 类型的节点,而该方法的作用就是将接收的节点添加为最后一个节点

此时新添加的节点为最后一个节点,即
div.lastChild == a;
如果添加的节点是已经存在于文档树中的,那么此时会将该节点移动到最后一个节点,假设有如下的 DOM 树,现在我们将节点 img 添加到 div 的子节点中,那么此时就相当于将 h2 下的 img 移动到 div 下

任何一个节点都只能有一个父节点。
insertBefore
appendChild 方法是将节点插入到最后面,而 insertBefore 则是将节点插入到某个节点之前,所以该方法接收两个参数,第一个参数是要插入的节点,我们将这个节点插入到第二个参数表示的节点的前面

同理,如果添加的节点也在文档树种,那么会将该节点移动,任何一个节点都不可能有两个父节点。
removeChild
removeChild 是用来删除节点的,该方法接收一个参数,就是你要删除的节点,被删除的节点将会作为返回值返回,如下图

被删除的节点仍然属于文档树,但是在文档树中已经没有了它的位置。
replaceChild
replaceChild 参数是用一个节点替换一个节点,所以该方法接收两个参数,新的节点以及被替换的节点

其他方法
cloneNode
cloneNode 方法从名字可以看出,该方法是将自己克隆一份,并返回。复制后的节点归文档所有,但是没有为该节点指定父节点。
该方法接收一个 bool 类型的参数,当传入为 false 时,表示的是浅复制,当传入的参数为 true 时,表示的是深复制。浅复制只会复制当前节点,不会复制该节点的子节点,而深复制不仅会复制当前节点,并且会复制当前节点下面的子节点。举一个例子,假设有这个一个 HTML 结构
<ul><li></li><li></li><li></li></ul>
当我们对 ul 进行复制,如果是浅复制
let newUl = ul.cloneNode(false);
那么 newUl 为
<ul></ul>
里面没有任何的内容,但是如果是深复制的话,则会将其子节点(以及子节点的子节点)也复制过来
let newUl = ul.cloneNode(true);
这时 newUl 为
<ul><li></li><li></li><li></li></ul>
normalize
该方法是用来处理节点中的文本节点,它会将空白节点删除,以及将连续的两个文本节点合并为一个文本节点

Document
现在介绍文档的根节点 document,它的相关属性如下
| 属性 | 值 |
|---|---|
| nodeType | 9 |
| nodeName | #document |
| nodeValue | null |
文档信息
下面将介绍几个属性,这几个属性包含了文档的一些信息。
title
document.title 属性保存的是标签 <title> 中的内容,我们可以通过 document.title 获得文档的标题,也可以通过 document.title 来改变文档的标题
let originTitle = document.title; // 获得文档的标题document.title = "New Page Title"; // 为文档设置新的标题
下面的三个属性与网页的请求有关
| 属性 | 值 |
|---|---|
| URL | 页面完整的 URL,与 location.href 的值相同 |
| domain | 页面的域名 |
| referrer | 链接当当前网页的那个页面的 URL,如果没有来源页面,值为空字符串 |
查找元素
document 对象有三个方法可以获得文档树中的节点,它们分别是
- getElementById()
- getElementsByTagName()
- getElementsByName()
下面就将具体介绍这三个方法。
getElementById
该方法根据 id 值来获得文档树中的一个节点,例如对于下面的 HTML 代码
<div id="box"></div>
上面的 div 元素有一个 id 属性,它的值为 box,因此我们可以通过下面的代码来获得该节点
let box = document.getElementById("box");
需要注意的是,如果文档有多个节点它们的 id 相同,当我们使用 getElementById 去查找节点时,会返回第一个匹配的节点。
getElementsByTagName
该方法根据标签名来获得文档树中的节点,该方法返回一个 HTMLCollection,与 NodeList 类似,它也是一个类数组,我们可以通过下标来访问该对象包含的元素。
let images = document.getElementsByTagName("img"); // 获得文档中所以的 img 节点
我们获得 images 是一个 HTMLCollection 对象,它除了可以使用下标的形式获得集合中的元素,还可以通过 namedItem 来获得相应的元素,假设文档中有一个 img 如下
<img name="img1" src="" />
该 img 有一个 name 属性为 img1,那么我们可以通过下面的方式来获得该节点
images.namedItem("img1");
getElementByName
该方法是根据 name 属性来获得节点的,该方法返回的是一个 NodeList,一般这个方法是用来取得单选按钮,因为单选按钮必须拥有相同的 name 属性。假设有如下单选按钮
<input type="ratio" value="green" name="color" /><input type="ratio" value="red" name="color" /><input type="ratio" value="blue" name="color" />
我们可以通过下面的方法获得所以的单选按钮
document.getElementsByName("color");
创建节点
我们还可以通过 document 来创建其它类型的节点,如
- createElement
- createTextNode
- createDocumentFeagment
具体的信息将在后面进行介绍。
Element
Element 类型是 HTML 中的标签所表示的节点类型,如 div h1 标签,它是除 Document 类型外,最常使用的类型。Element 元素提供了对元素标签名、子节点以及 attribute 访问的能力。
有关 Element 类型的信息如下
| 属性 | 值 |
|---|---|
| nodeType | 1 |
| nodeName | 元素标签名(大写),如 DIV |
| nodeValue | null |
除了可以通过 nodeName 访问元素的标签名,还可以通过 tagName 访问元素的标签名,二者的返回值是一样的(使用后者主要是为了清晰起见)。
HTMLElement
所有的 HTML 元素都由 HTMLElement 表示,HTMLElement 继承自 Element,除此之外,还扩展了几个属性
| 属性 | 值 |
|---|---|
| id | 元素在文档中的唯一标识符 |
| className | 与元素的 class 属性对应 |
| title | 元素的附加信息 |
| lang | 元素内容的语言代码,很少使用 |
| dir | 元素的方向,默认为 ltr(从左往右),很少使用 |
attribute
下面将介绍有关操作元素 attribute 的有关方法及属性。与 attribute 有关的方法如下
- getAttribute
- setAttribute
- removeAttribute
这些方法可以对任何 attribute 进行使用,包括 HTMLElement 定义的 attribute 或者自己自定义的 attribute。有如下 HTML 代码
<div class="container" id="box"></div>
getAttribute 是用来获得节点的 attribute
let box = document.getElementById("box");let classValue = box.getAttribute("class"); // container
setAttribute 是用来来设置节点的 attribute,如果设置的 attribute,则会进行替换
box.setAttribute("class", "active");box.getAttribute("class"); // active
removeAttribute 是用来删除节点的 attribute
box.removeAttribute("class");
这个方法不仅会清楚 attribute,而且会将 attribute 从元素中彻底删除,所以这个方法不太常用。
除了通过上面的三个方法操作元素的 attribute,还可以通过元素的 attributes 属性来访问元素的 attribute,元素的 attributes 属性是一个 NamedNodeMap,它同 HTMLCollection 和 NodeList 一样,也是一个伪数组,其中存储的是一个个 Attr 节点(没错,元素的 attribute 也是一种节点);NamedNodeMap 提供以下方法来操作 attribute
- getNamedItem
- setNamedItem
- removeNamedItem
- item
前面三个方法都根据 Attr 节点的 nodeName 来访问(即 attribute 的名字)来操作 attribute,如
let attributes = box.attributes; // 获得 box 的 attributes 属性let classValue = attributes.getNamedItem("class"); // containerattributes.setNamedItem("class", "active");attributes.removeNamedItem("class");
最后一个方法是根据下标来获得 attributes 中的 Attr 节点,这个方法与通过数组下标的形式获得的结果是一样的
attributes.item(2) == attributes[2];
创建元素
创建元素是属于 document 对象的方法,我们使用 document.createElement 来创建一个元素节点,并且将该元素节点返回,例如
let div = document.createElement("div"); // 创建一个 div 元素节点div.id = "box";div.className = "container";
上面我们创建一个 div 节点元素,并且为该节点设置了 id 和 className(即 class 属性),我们可以通过 appendChild 将该节点添加到文档树中,如
document.body.appendChild(div);
Text
文本节点使用 Text 类型进行表示,它的相关信息如下
| 属性 | 值 |
|---|---|
| nodeType | 3 |
| nodeName | #text |
| nodeValue | 节点所包含的文本 |
Text 类型的节点没有子节点。我们可以使用下面的方法来操作节点
- appendData(text):向节点中添加文本 text
- deleteData(offset, count):从 offset 开始删除 count 个文本
- insertData(offset, text):在 offset 后插入文本 text
- replaceData(offset, count, text):从 offset 开始,将 count 个文本替换为 text
- splitText(offset):以 offset 为界,将文本分割为两个文本节点,并将第二个文本节点返回
- substringData(offset, count):取得从 offset 开始的 count 个文本
假设有下面的 HTML 代码
<div>Hello World</div>
div 元素节点中有一个文本节点,里面的文本内容为 Hello World
let text = div.firstChild; // Text 节点是 div 的第一个子节点text.appendData("!"); // Hello World!text.deleteData(0, 6); // 从 0 开始,删除 6 个字符 ==> World!text.insertData(0, "Hello "); // 在 0 前面插入文本, Hello_(_代表空格) => Hello World!text.replaceData(0, 5, "Hi"); // 从 0 开始将后 5 个字符替换为 Hi => Hi World!let newText = text.splitText(3); // 以 3 为界,分为两个文本节点 =>1. Hi_(_代表空格) 2. World!newText.substringData(0, 1); // W
我们可以通过 document 对象的 createTextNode 来创建一个文本节点,该方法接收一个参数,即文本节点所包含的文本
let text = document.createTextNode("JavaScript");
接着我们可以通过 appendChild 方法将该节点添加到文档树中。
DocumentFragment
在所有的节点中,只有 DocumentFragment 在文档中没有对应的标记。DOM 规定 DocumentFragment 是一种轻量级的文档,它可以包含和控制节点,但是不会真正的文档占用额外的资源,它的相关信息如下
| 属性 | 值 |
|---|---|
| nodeType | 11 |
| nodeName | #document-fragment |
| nodeValue | null |
一般将 DocumentFragment 当做一个仓库来使用,将要添加到文档树中的节点先添加到 DocumentFragment 中,因为如果大批量的向文档树种添加节点时,如果一个个像浏览器添加节点,就会导致浏览器反复渲染,如果我们将节点先添加到 DocumentFragment 中,然后在将 DocumentFragment 添加到文档树中,DocumentFragment 会将它包含的节点一次性添加到文档树(DocumentFragment 并不会被添加到文档树中),这样可以提高浏览器的性能。
我们可以通过 document.createDocumentFragment 来创建一个 DocumentFragment,有下面的一个 ul 节点,
<ul id="list"></ul>
我们需要将下面的节点添加到文档树中
<li>item1</li><li>item2</li><li>item3</li>
我们可以先将 li 元素添加到一个 DocumentFragment 中,然后在添加到文档数中,如下
let ul = document.getElementById("list");// 创建一个 DocumentFragmentlet fragment = document.createDocumentFragment();for(let i = 0; i < 3; i++) {let li = document.createElement("li");li.appendChild(document.createTextNode("item" + (i + 1)));fragment.appendChild(li);}ul.appendChild(fragment);

若有收获,就点个赞吧
0 人点赞
