1. 参考介绍:
Guided Attentive Feature Fusion for Multispectral Pedestrian Detection
用于多光谱行人检测的引导的注意力特征融合
- Intro: Univ Rennes 1, IRISA, France
- 期刊/会议: WACV 2021
2. 文章解读
2.1 整体介绍
In this paper, we propose a novel and fully adaptive multispectral feature fusion approach, named Guided Attentive Feature Fusion (GAFF).
文章设计了一种新型的自适应的多光谱特征融合方法,它是一种基于引导的注意力机制的特征融合方法(GAFF)。
文中设计一个特征融合模块由模态内注意力模块( intra-modality attention modules),模态间注意力模块(inter-modality attention modules)和 联合模块(intra- and inter-modality attention)组成。在充分利用模态内和模态间的注意力机制及其各自的损失函数的引导下(guidance,题目中的guided的由来,其实是利用掩膜来进行引导 ),作者认为该方法能动态地加权和融合多光谱特征。
2.2 方法分析
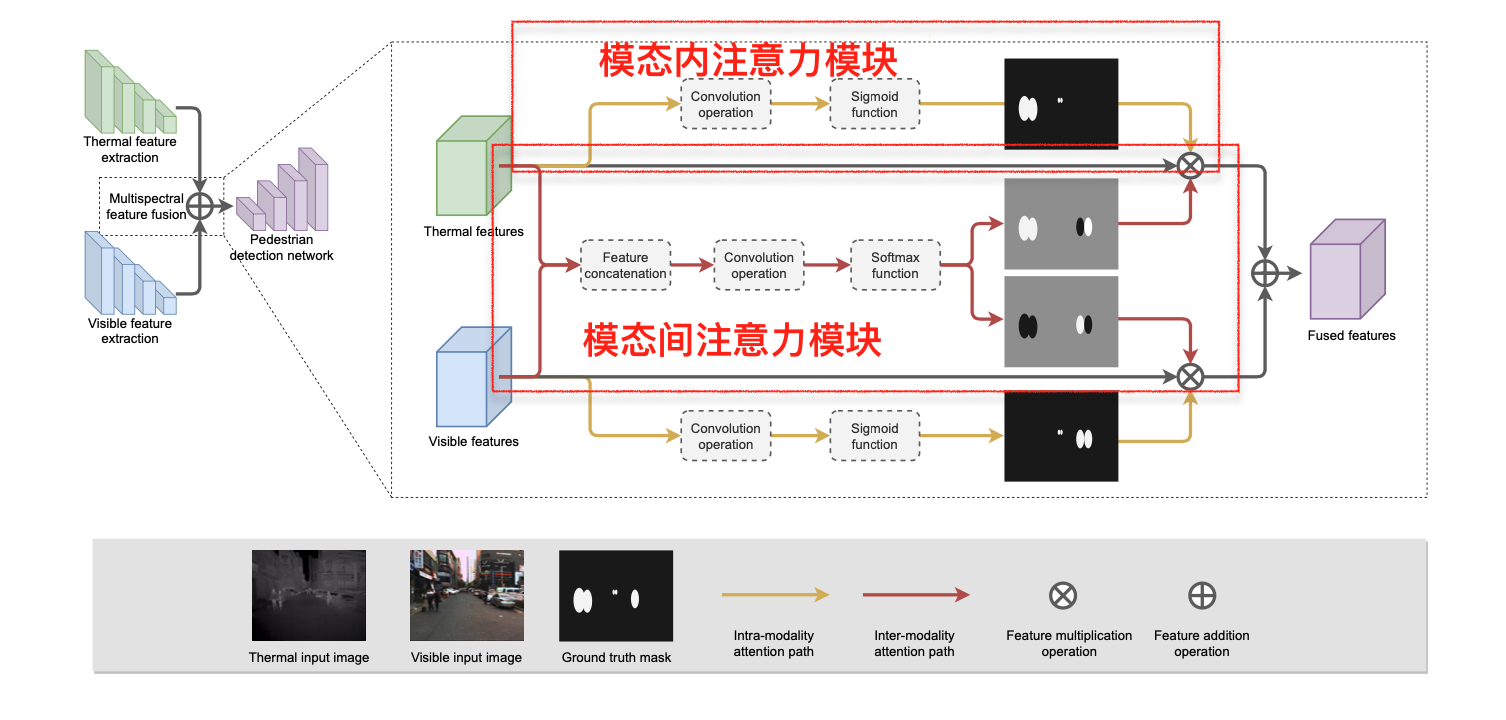
图1 GAFF的结构
作者提出的模块是在Retina网络的基础上开发的。设计的GAFF服务于可见光和红外两个骨干网络的输出特征融合,具体如图1。作者应该借鉴了 Residual Attention Network 的思路,将注意力掩膜当做是一个残差的形式。
Since GAFF only involves 3 convolution layers, the additional parameters and computation cost is low.
从图中可以发现GAFF其参数量很小,因为参数量只有三个卷积操作。
作者将图中黄色路径的称为模态内注意力模块,其主要作用是增强行人区域的特征(这部分类似特征增强)。红色的路径是模态间注意力模块,其主要作用是自适应地从两种模态中选择可靠的特征。
2.2.1 注意力模块(对应题目中的 Attentive)
融合特征(总体)公式表达式如下:
其中, 是GAFF最终的输出特征,
是GAFF最终的输出特征, 是热的混合特征输出,
是热的混合特征输出, 是可见光的混合特征输出。
是可见光的混合特征输出。
模态内注意力模块的表达式如下:

Superscripts ( or **) denote the thermal () or visible (**) modality;
or **) denote the thermal () or visible (**) modality;
denotes the elementwise multiplication;  represents the sigmoid function;
represents the sigmoid function;
represents a convolution operation to predict the intra-modality attention masks (pedestrian masks)  ;
;
and ** represent the original and enhanced features, respectively.
显然可以发现  的前面半部分就是模态内注意力模块的输出表达式。
的前面半部分就是模态内注意力模块的输出表达式。
模态间注意力模块的表达式如下:** 

Here,  denotes the softmax function;
denotes the softmax function; denotes the fea- ture concatenation operation;
denotes the fea- ture concatenation operation;  represents a convolution operation to predict the inter-modality attention mask
represents a convolution operation to predict the inter-modality attention mask  .
.
At each spatial position of the mask, the sum of  and
and  equals to 1.
equals to 1. 
也就是对于每一个mask中的位置(像素)都有两个值即 ,下标 i,j 代表掩膜每一个位置的值。
,下标 i,j 代表掩膜每一个位置的值。
However,in order to train this module, we should need **a costly ground truth information about the best pixel-level modality quality**.
紧接着文章需要解决的问题是,如果需要训练这个模态间注意力模块的话,如何给出像素级模态的质量的ground truth  。因为原图像分割的ground truth并没有直接给出关于如何在像素级上挑选模态的信息,因此需要进行构造。
。因为原图像分割的ground truth并没有直接给出关于如何在像素级上挑选模态的信息,因此需要进行构造。
Our solution to relieve the annotation cost is to assign labels according to the prediction of the pedestrian masks from the intra-modality attention module, i.e., we force the network to select one modality if its intra-modality mask prediction is better (i.e. closer to the ground truth pedestrian mask) than the other.
作者给出的解决办法是利用模态间注意力掩膜来解决,在该像素上谁的误差离原图像分割的ground truth小,并且两掩膜误差的差要大于一个阈值,那么那个模态在该像素点的掩膜值就为1,另一个模态的掩膜值就为0,也就是说该模态间质量gt掩膜是非1即0,但是如果在小于阈值就忽略,该掩膜像素不参与训练。

Here,  denotes the absolute function;
denotes the absolute function;  represents the error mask, defined by the L1 distance between the predicted intra-modality mask mintra and the ground truth intra-modality mask
represents the error mask, defined by the L1 distance between the predicted intra-modality mask mintra and the ground truth intra-modality mask  ;
;  is the ground truth mask for inter-modality attention (2 values at each mask position);
is the ground truth mask for inter-modality attention (2 values at each mask position);  is a hyper-parameter to be tuned.
is a hyper-parameter to be tuned.
显然可以发现 的后半部分就是模态间注意力模块的输出表达式。
2.2.2 loss 函数(对应题目中的 Guided)
文章的loss函数一共有三部分组成,原来单纯目标检测的loss,模态间loss和模态内loss:
 就是单纯的目标检测损失函数
就是单纯的目标检测损失函数 采用DICE loss的行人图像分割损失函数 (用于指导各模态对自身模态内特征的增强)
采用DICE loss的行人图像分割损失函数 (用于指导各模态对自身模态内特征的增强)
In order to introduce our specific guidance, we adopt the DICE [3] loss as the pedestrian segmentation loss.
 采用交叉熵损失函数(用于指导模态选择)
采用交叉熵损失函数(用于指导模态选择)
the cross-entropy loss as the modality selection loss

若有收获,就点个赞吧
0 人点赞
