1. 参考文献
<br />**URL: **[https://arxiv.org/abs/1708.02002](https://arxiv.org/abs/1708.02002)<br />**Github: **offical
pytorch
refence: https://zhuanlan.zhihu.com/p/28527749
https://www.zhihu.com/question/293369755/answer/488355189
2. 内容解读
2.1 整体介绍
Motivation
Two-stage的检测器通常检测精度比较高,它是在RPN上的候选生成框(已经做过NMS过滤)的稀疏集合上面用了分类器。与之相反的,one-stage的方法是用在可能的object locations上面做常规、密集采样(比如YOLOv3在416×416的输入情况下,特征输出层为13×13,26×26,52×52,一共有batchsize×3×(13×13+26×26+52×52)个候选框),它具有更快速、更简单的特点,但是精度没有two-stage的方法高。作者探究这这种情况发生的原因,在训练时候出现前景背景**类别(也即正负样本)的不平衡(imbalance)是中心原因。作者提出重新构建了标准交叉熵损失来解决类别不均衡(class imbalance),这样它就能降低容易分类的样例的比重(well-classified examples)。这个方法专注训练在hard example的稀疏集合上,能够防止大量的easy negatives在训练中压倒训练器(overwhelming the detector)。
Meathod
Focal loss 其实对简单样本的进行惩罚的一种损失函数。是对标准的 Cross Entropy Loss(CE或者是二分类的BCE) 的一种改进。 Focal Loss对于简单样本(即网络认为概率比较大)设置比CE更小的loss。这里先介绍下BCE,CE,FL三种损失函数的表达式:
CE Loss 其实只统计预测正确(即网络预测类别与真实label的一致的损失,通过loss梯度下降来达到预测正确的概率趋近于1)
- Binary Cross Entropy Loss:

 means positive,
means positive,  means negative
means negative
Binary Cross Entropy Loss(**in pytorch):**
<br />  means batch size,  means a manual rescaling weight given to the loss of each batch element.BCEWithLogitsLoss(in pytorch):
This loss combines a Sigmoid layer and the BCELoss in one singleclass. This version is more numerically stable than using a plain Sigmoidfollowed by a BCELoss as, by combining the operations into one layer,we take advantage of the log-sum-exp trick for numerical stability.

 means Sigmoid function
means Sigmoid function
!!!这部分是多标签不是多类别!!!
It’s possible to trade off recall and precision by adding weights( ) to positive examples. In the case of multi-label classification the loss can be described as:
) to positive examples. In the case of multi-label classification the loss can be described as:
where:  is the class number (
is the class number ( for multi-label binary classification,
for multi-label binary classification,  for single-label binary classification),
for single-label binary classification), is the number of the sample in the batch and
is the number of the sample in the batch and  is the weight of the positive answer for the class .
is the weight of the positive answer for the class . increases the recall,
increases the recall,  increases the precision.
increases the precision.
- Cross Entropy Loss:

means class number,  means the possibility of ture label
means the possibility of ture label
可以发现其实CE和BCE的表达式的形式是一致的。
- Focal Loss:

The advantage of Focal Loss
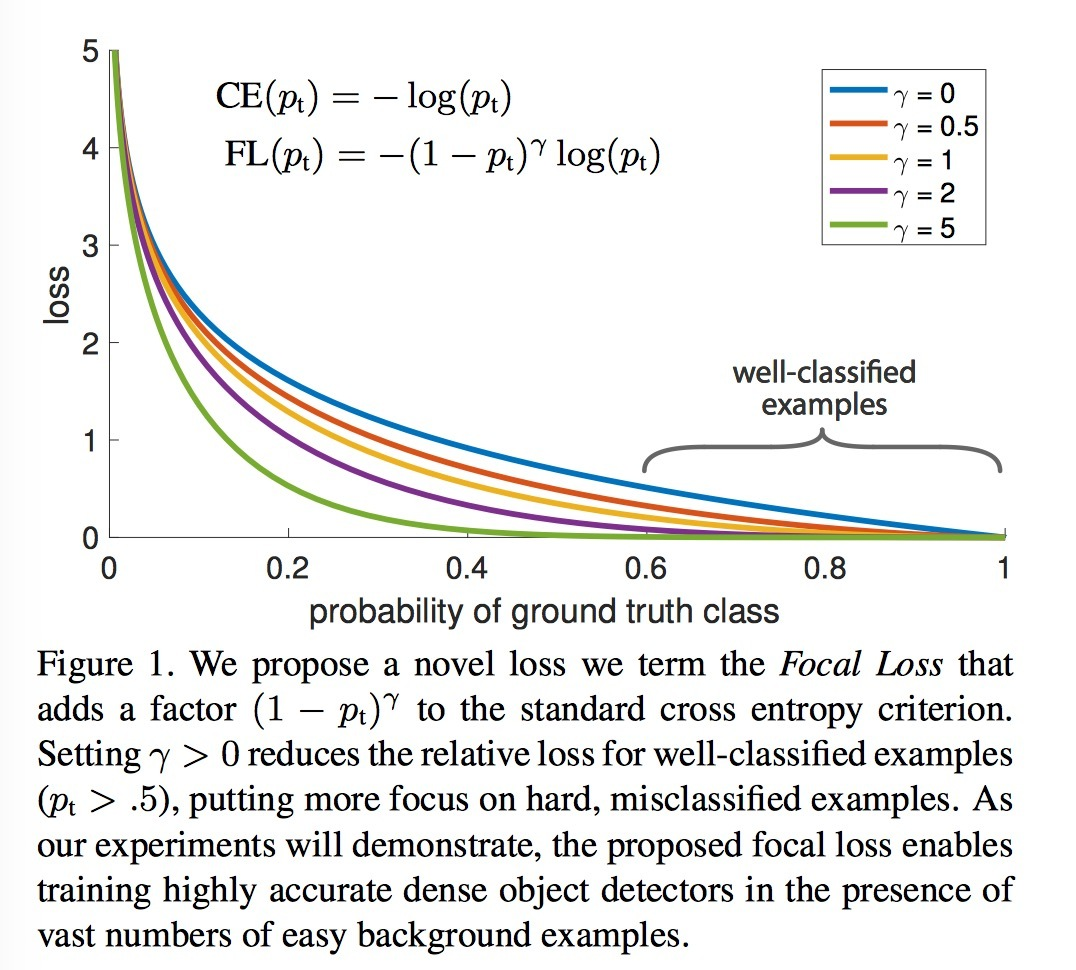
举个列子,如论文中的图1, 在p=0.6时, 标准的CE有较大的loss,Focal Loss只有相对较小的loss。这其实是对简单样本的权重更新的一种衰减(decay)。显然观察图我们会发现,Focal loss 在 值接近于1的时候,其loss远小于CE,使得网络的loss集中在hard misclassfied 样本中,继而使得网络专注于对困难例子的改善。另外当  , Focal Loss 退化为CE Loss,因此FL 是CE的泛化版本。
, Focal Loss 退化为CE Loss,因此FL 是CE的泛化版本。
Focal loss的属性:
- 当一个样例被误分类,那么
 ,那么调制因子
,那么调制因子  ,损失不被影响;当
,损失不被影响;当  ,调制因子
,调制因子  ,那么容易分类(well-classified)样本的权值就被调低了。
,那么容易分类(well-classified)样本的权值就被调低了。 - 专注参数
 平滑地调节了易分样本调低权值的比例。 增大能增强调制因子的影响,实验发现 取2最好。
平滑地调节了易分样本调低权值的比例。 增大能增强调制因子的影响,实验发现 取2最好。
直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。举例来说,当  时,一个样本被分类
时,一个样本被分类  的损失比CE小100倍((1-0.9)^2=100)。这样就增加了那些误分类(准确的说应该是正确类别概率低的情况)的重要性。
的损失比CE小100倍((1-0.9)^2=100)。这样就增加了那些误分类(准确的说应该是正确类别概率低的情况)的重要性。
此外论文中还引入另外一个超参数 (平衡因子),作用是用来平衡正负样本本身的比例不均,文中 取0.25,即正样本要比负样本占比小,这是因为负例易分,即 -balanced的Focal Loss的变体。
(平衡因子),作用是用来平衡正负样本本身的比例不均,文中 取0.25,即正样本要比负样本占比小,这是因为负例易分,即 -balanced的Focal Loss的变体。
Backpropagation
这里对Focal loss进行反向传播梯度计算。
YOLOv3 with Focal Loss
首先梳理一下YOLOV3的检测过程,看看哪个地方适用于 Focal Loss:
(1)对于所有 predict boxes,若其与所有的真实方框 IoU 小于 ignore_thresh,惩罚objectness,如果大于,不进行惩罚
(2)对于所有 true boxes,判断它的尺寸如何,该丢给哪一层检测(FPN 中的哪一层)
(3)得出了该哪一层检测后,找 true boxes 的中心点,并且找和它靠近的 predict boxes,指定它去学习 true box
(4)location,objectness,classification 项的调整
只有一个地方,就是(1)阶段, 待网络训练稳定后,一个 batch 中惩罚数和不惩罚数目的比例接近达到了300 : 1。这也是正常的,因为如果按照416的尺寸输入,yolov3 的 anchor 总数达到 (1313 + 2626 + 5252)3 = 10647 , 显然大部分预测框和true box的IoU怎么会大于 ignore_thresh(0.5 for VOC 0.7 for MS COCO)
针对第二点,YOLOv3在三个尺度上对每个目标都进行了预测。只是在三个不同的尺度上,每个groundtruth中心点落在的单元上的预设anchor做iou,找到最大iou的那个anchor来预测此目标,但是如果有别的目标也落在了此单元里,那么再根据比较iou大小,单元来选择预测哪个物体。(当然三个不同尺度上的anchor的大小也不一样,那么大目标落在52x52的某个单元后,其groundtruth与此层的anchor的iou肯定没有落在此单元的小目标的与此层anchor的iou大,所以也就决定了这一层的单元更倾向于预测小目标)
YOLO Loss = Location Loss + Objectness Loss + Classification Loss
这里用在Focal Loss 用在 Objectness Loss,因为只有在这里正负(前景和背景)样本极度不平均。
Orginal Loss

Focal Loss

若有收获,就点个赞吧
0 人点赞
