指标背后: 置信阈值
在分类模型中,每个预测都分配有一个置信度分数,这个数值衡量模型在多大程度上确定预测的类别是正确的。分数阈值是确定给定分数何时转换为是或否决策的数字;也就是说,分数为该值时,您的模型表示“是的,这个置信度分数足够高,可以得出这个客户将在明年购买一件外套的结论。”

如果分数阈值较低,那么您的模型的分类可能会出错。 因此,分数阈值应根据给定用例来确定。
预测结果
应用分数阈值后,模型所做的预测可分为四类。要理解这些类别,我们再次假设一个夹克的二元分类模型。 在这个例子中,正类别(模型尝试预测的内容)是客户“会”在明年购买夹克。
- 真正例:模型对正类别的预测正确。模型正确预测到顾客购买了夹克。
- 假正例:模型对正类别的预测错误。模型预测客户会购买夹克,但他们没有。
- 真负例:模型对负类别的预测正确。模型正确预测到客户没有购买夹克。
- 假负例:模型对负类别的预测错误。模型预测客户不会购买夹克,但他们买了。

精确率和召回率
精确率和召回率指标有助于您了解模型捕获信息的精准度以及遗漏的信息量。
- 精确率是指正确预测的正类别所占的比例。 在所有客户购买的预测中,实际购买的比例占多少?
- 召回率是模型正确预测的具有此标签的行所占的比例。在本可以识别的所有客户购买中,实际识别出的比例占多少?
根据您的用例,您可能需要针对精确率或召回率进行优化。
精确率和召回率:一场拔河比赛
要全面评估模型的有效性,必须同时检查精确率和召回率。遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。请观察下图来了解这一概念,该图显示了电子邮件分类模型做出的 30 项预测。分类阈值右侧的被归类为“垃圾邮件”,左侧的则被归类为“非垃圾邮件”。
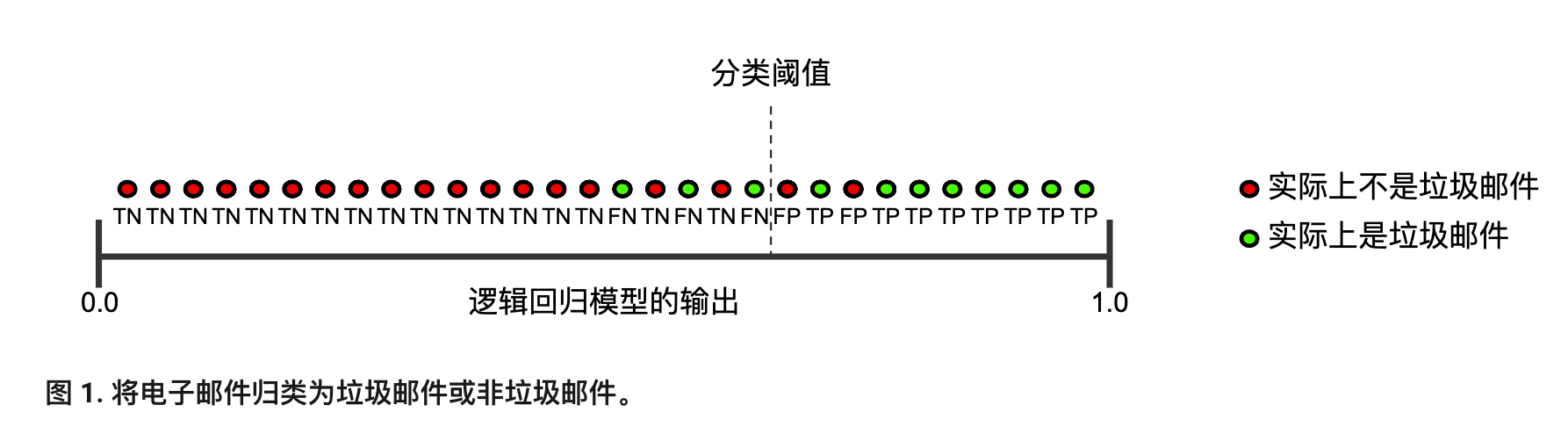

精确率指的是被标记为垃圾邮件的电子邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比:
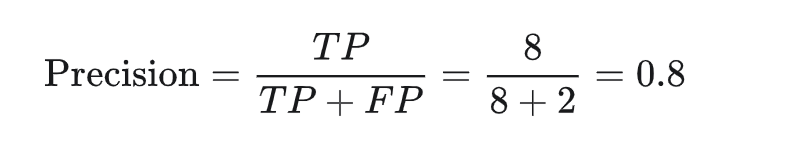
召回率指的是实际垃圾邮件中正确分类的电子邮件所占的百分比,即图 1 中阈值线右侧的绿点所占的百分比: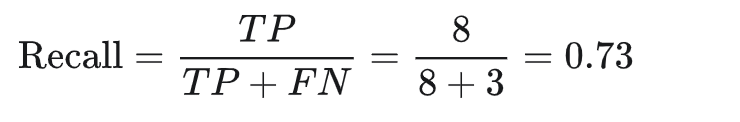
图 2 显示了提高分类阈值产生的效果。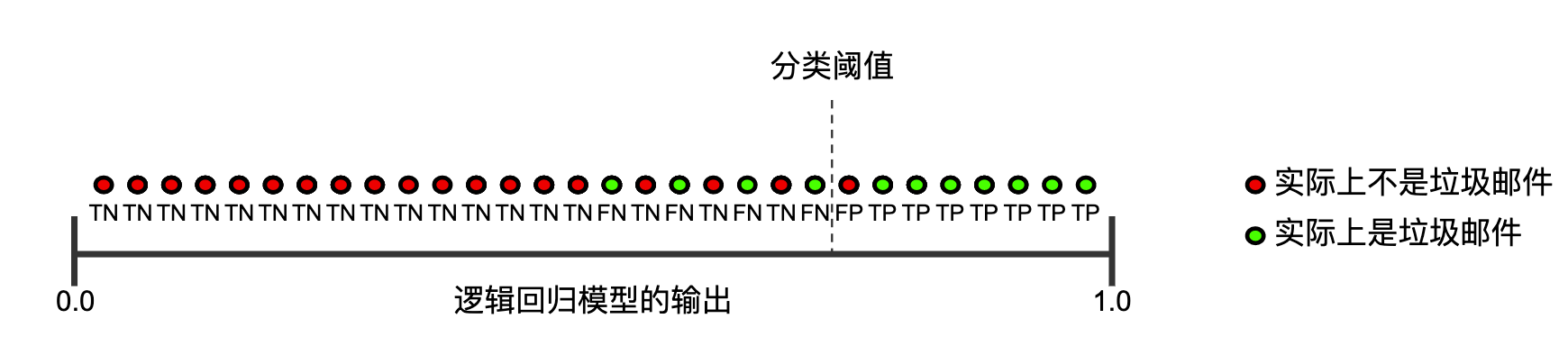
假正例数量会减少,但假负例数量会相应地增加。结果,精确率有所提高,而召回率则有所降低:
相反,图 3 显示了降低分类阈值(从图 1 中的初始位置开始)产生的效果。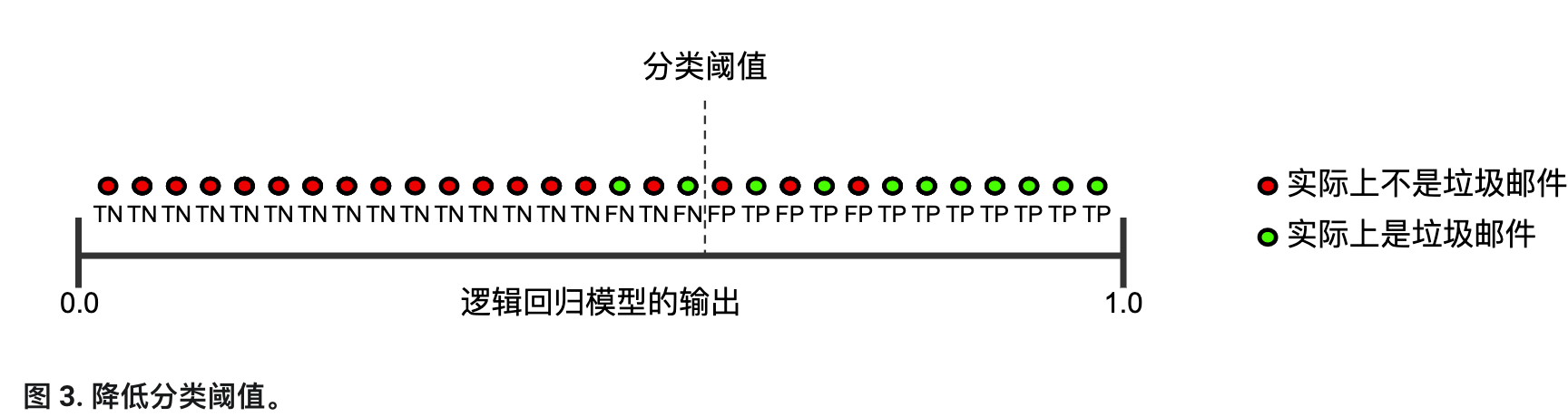

精准与召回的平衡
对于同一策略模型,同一阈值,可以统计出一组确定的精准率和召回率。调整参数,遍历0-1之间的所有阈值,就可以画出每个阈值下的关系点,从而得到一条曲线,称之为P-R曲线。
(召回率也叫查全率,精确率也叫查准率)
通过曲线发现,召回率和精准率相互制约,此起彼伏,所以只能找二者之间的平衡点。这时需要引入F值评估:F-Score(也称F-Measure),它是Precision和Recall加权调和平均数,[0,1],值越大表示效果越好。
F1 Score:召回率和精确率同等重要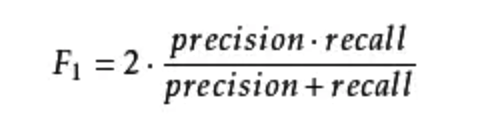
但往往我们对召回率和精准率的权重要求是不同的,这是我们需要用到 Fβ Score。
- F2:召回率的重要程度是准确率的2倍
- F0.5:召回率的重要程度是准确率的一半

整体评估模型表现:ROC&AUC
前文介绍了R\P\A\F值,但它仅能评估单点效果而无法衡量策略的整体效果,于是我们再引入ROC(Receiver Operating Characteristic)、AUC(Area Under Curve),它是一套成熟的整体策略评估方法。
先引入两个指标,这两个指标是ROC、AUC可以无视样本中T、F不平衡的原因。
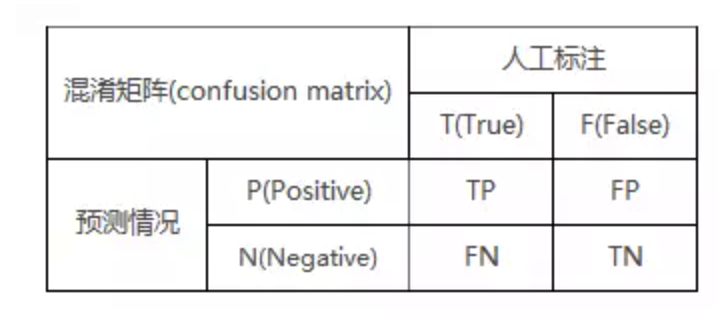
- 真正率(TPR)=TP/(TP+FN),在“真”样本里预测正确的样本;
- 假正率(FPR)=FP/(FP+TN),在“假”样本里预测错误的样本。
设横坐标是FPR、纵坐标是TPR,每个点都描绘了在某一确定阈值下模型中真正的P和错误的P之间的关系,遍历0-1的所有阈值,绘制一条连续的曲线,这就是ROC曲线。
如果我们遍历阈值,多次回归模型绘制出ROC曲线上的点,这种做法非常低效。因此我们可以用另外一种方法来代替ROC,即AUC,计算曲线下的面积。
如上图虚线,若我们将对角线连接,它的面积正好是0.5,代表模型完全随机判断,P/N概率均为50%。若ROC曲线越陡,AUC就越接近正方形,面积越接近1,代表效果越好。所以,AUC的值一般都介于0.5-1之间。
MAP
除了考虑召回结果整体准确率之外,有时候还需要考虑召回结果的排序。于是我们要提起MAP(Mean Average Precision)。
先说说AP的计算,假设这N个样本中有M个正例,那么我们会得到M个Recall值(1/M, 2/M, …, M/M),如下图,N个样本里有6个正例,有6个Recall值:1/6, 2/6, …, 6/6,对于每个Recall值,我们可以计算出对于这个正例最大Precision,然后对这6个Precision取平均即得到最后的AP值。计算方法如下:
AP衡量的是学出来的模型在给定类别上的好坏,而MAP衡量的是学出的模型在所有类别上的好坏,得到AP后MAP的计算就变得很简单了,就是取所有AP的平均值。
小结
以上是从统计指标角度理解模型学习的评估。

若有收获,就点个赞吧
0 人点赞
