引文
点击率预估系统最早是由谷歌实现,并应用在其搜索广告系统。在看到这一大杀器为谷歌带来滚滚财源之后,其他公司也纷纷效仿。直到今日,大大小小的“互联网广告公司”,都宣称自己掌握了基于人工智能的精准定向,实际上大多讲的就是这个点击率预估系统。而点击率预估的应用场景也从最开始的搜索广告,扩展到展示广告、信息流广告等等广告形态,甚至于在商品推荐系统中都能看到其踪影。
点击率预估系统的核心是机器学习算法,不过我们也应该知道,算法所处理的对象往往是抽象的,是优雅的,而现实中的任务却是具体的,充满缺陷的。那么如何用抽象的算法来解决具体的业务问题,是本文所要介绍的内容。本文会分成日志系统、特征工程、模型选择与训练、在线服务四个部分,主要介绍点击率预估系统的数据流程以及系统框架。而模型与算法原理、模型调优、在线学习这些主题,本文只做简要介绍或不涉及。
1. 日志系统
点击率预估用到的是监督学习算法,所以我们需要由日志来提供如下表形式的数据。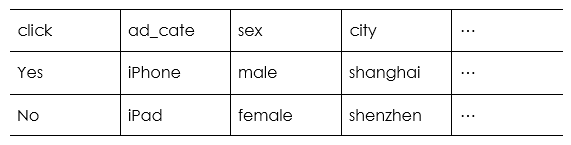
这里面的每一行,都是一次广告展示的完整记录。其记录了这次广告展示所对应的广告、用户、上下文三类特征,以及用户对这次广告展示的行为反馈,即是否点击了广告。
但是实际上,用户访问一个网站或App而触发广告请求时,在服务器会生成一条日志,广告曝光、点击的上报又各自产生了相应的日志。对于这些各自独立的日志,我们要把他们关联起来,把广告的请求、展示、点击三个事件串起来,才能形成上述提到的记录形式。为实现这一点,对每个广告请求,我们要为其生成唯一的id,并在后续的曝光和点击上报时,将这一id一起上报,再通过这一id来关联日志。具体的日志关联过程,可以采取离线批处理(如MapReduce),也可以采用流式处理(如Spark Streaming),这个根据业务情况酌情选择。前面提到,处理之后的记录包含广告、用户、上下文三类特征,那么在打印日志时,特别是请求日志,需要注意将相关信息打印完备。
2. 特征工程
点击率预估算法处理是数字形式的输入,所以在日志处理完之后,需要通过特征工程来将文本形式的信息转换成数字形式的信息,即建立索引。建立索引有两种常见做法,一是对特征简单计数,一是对特征取值做哈希处理。如果采用简单计数,需要将所有特征都枚举出来,这在日志量和特征空间庞大的时候会是一个问题。而采用哈希处理则相对简单,而且有一些团队通过哈希碰撞的方式来缩小特征空间,降低训练难度,不过这个做法是否不影响预测性能是因业务而异的。如果接入的是线性模型,那么在建索引时还需要对分类类型特征做one-hot编码。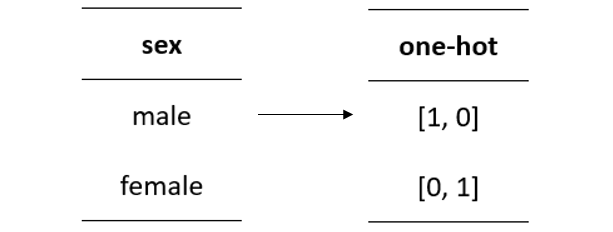
在建索引之前,还有很多事情要做。有一些特征并不会在日志中出现,比如统计数据,这些特征需要通过各种id去做关联。日志中往往会存在一些异常值,比如说有一些刷单数据,或是特征取值明显偏离正常范围,我们需要对这些数据做过滤。
而对于实值特征,往往会做归一化或是离散化(如果使用线性模型),以免由于实值特征取值范围严重偏离[0,1]区间,而给模型训练和预测带来困难。样本中的特征还有可能获取不到观测值,或者是观测值出现次数过少,对于这些情况,可以赋予缺省值。
而有些特征的覆盖率太低,则可以选择放弃。如果想要为线性模型引入非线性,则需要做交叉特征设计,这是一件很依赖领域知识的事情。总之,特征工程这件事情,花样很多。
我们知道,广告的点击率一般是显著低于50%的,会存在样本不平衡的问题。那么对于这个问题,我们可以采用负例欠采样的处理方式。
通过观察不同欠采样比例下的模型预测性能,可以获取最佳的采样比例。欠采样方法有可能导致丢失一些负例的信息,对于这个问题,可以尝试[1]所提出的Easy Ensemble,就是对负例进行N次不重复的随机采样,并分别与所有正例组成N个训练集,分别训练出N个模型,然后对预测值做平均。这个做法简单有效,不过对于在线服务来说,N个模型就意味着N倍的计算量,需要权衡这个做法的收益。
3. 模型选择与训练
点击率预估算法,最经典的莫过于LR(Logistic Regression,逻辑回归),作为一个线性模型,他的特点是易实现,易解释,还有Google背书提出FTRL(Follow The [Proximally] Regularized Leader)优化算法,再说他能够给“特征工程师”提供存在感:)。
近年来的趋势是FM(Factorization Machine)/FFM(Field-aware Factorization Machine),DNN(深度神经网络)。
FM算法为各个特征生成一个Embedding Vector,并且通过不同特征对应的Embedding的内积来表达交叉特征,这对于训练样本稀疏的交叉特征有明显更好的学习能力。FFM则是对FM的一小步改进,他为每个特征生成的Embedding不只有一个,而是根据不同的互作用field生成不同的Embedding,这里的field指的是一个特征在one-hot编码之前所属的分类类型特征[2]。
FFM算法因为在Kaggle比赛中连续两次取胜而引起关注,有趣的是,第一次比赛中台大的团队使用了FFM并取胜之后,第二次比赛各个团队也都纷纷使用该算法。FFM在在线服务中的尝试以及效果的提升也已有相关报道[3,4]。
至于DNN,按Bing团队的说法:在各种使用DNN的尝试中,其带来的效果提升都是marginal的,而其对计算机资源的消耗则大幅增加,而且在线效果并不稳定[5]。当然了,有些公司确实在点击率预估的生产环境中使用了DNN,甚至提供了云服务,对于他们是否也碰到前面所述的问题,是否有从DNN中获得不那么marginal的提升,我很感兴趣。
接下来聊聊模型集成。通过模型集成来降低预测的偏差或方差,是机器学习中的通用做法。集成方法有stacking、cascading、boosting等等,而大名鼎鼎的GBDT就是boosting的产物,这里要聊的模型集成都跟GBDT有关系。前面提到Kaggle比赛的获胜者用了FFM,其实他们使用了模型集成,具体做法是GBDT+FFM,将GBDT的输出接入到FFM的输入特征,这个做法很可能是受启发于Facebook提出的GBDT+LR。Facebook提出这个方法,是基于这样的考虑:在特征工程中往往需要做两件事情,一是将实值特征打散,一是生成交叉特征,而他们注意到GBDT恰好可以自动完成这两件事情[6]。这个集成模型是一个cascading的做法。我最近注意到另外一个很有意思的做法,则是基于boosting的。这个做法本质上也是GBDT,但是与通常的GBDT不同的是,其第一个分类器不是决策树,而是用其他模型来代替,比如LR、NN、DNN等等,然后在这个基础上再用决策树做boosting。这个做法从Bing的实验结果来看效果的提升是非常明显的[5]。
讲了这么多的模型,那么我从零开始搭建系统,应该选哪一个呢?我个人比较信赖所谓“AK-47”原则,就是在实现一个东西的时候,应该首先选择简单有效的方式。那么基于这个原则我们应该首先考虑单模型,即LR、GBDT、FM/FFM等模型。而在这里面,我个人倾向于选择FFM,这个模型把我们从交叉特征的艺术创造中解放出来,其有效性已有多方背书,还可以online-training。要说有什么缺点,一个是容易过拟合,一个是相对LR、FM消耗更多资源。对付第一个问题用early-stopping,而第二个问题,在这个DNN都可以上的年代,多消耗点资源就消耗吧。当然,最好把LR、GBDT这些也弄上做baseline,再说这里面很多说不准,效果这东西得试试才知道。
聊完模型,来聊聊训练。训练时,我们需要为模型的性能确定指标,通过性能指标来选择最合适的模型。最常用的是AUC(Area Under ROC Curve),指的是ROC(Receiver Operating Characteristic)曲线下的面积,衡量的是对于不同广告的排序质量,这也恰恰是大多广告点击率系统最关心的。除此之外还有LogLoss、RIG(衡量点击率预估值的准确率)、Utility(衡量模型带来的收益提升)等等指标,可以根据业务需求酌情选取。不同的模型都有各自的超参数需要去做调优,这里不做展开。
**
**
4. 在线服务
在线服务有三个关键环节,分别是分流实验、特征转换和pCTR(predicted click through rate,预估点击率)计算,这里分段简要介绍。
点击率预估系统往往需要做线上实验来验证模型的效果,所以在线服务首先需要一个实验层来对流量进行配置,将流量分发给不同的模型,并且跟踪不同模型的实时效果。需要注意的是,良好的离线效果并不意味着线上效果就一定好。
特征转换对应的是离线处理时的特征工程环节,是为了将广告请求的数据转换成模型的输入特征。在特征转换的过程中,往往从广告请求中拿到的特征并不全,还需要去做进一步的关联。互联网广告一般对实时性要求比较高,而pCTR计算环节已经是计算密集的,为了提高响应速度,在特征转换环节应该减少甚至避免IO带来的延迟,所以这些关联信息最好提前加载到应用内存或者缓存中,并通过定时任务进行更新。
通过特征转换得到的输入特征,会交给pCTR计算模块去做最后的计算,这个模块加载了训练好的模型。模型的训练都会以一定的频率进行(甚至是一直在进行,即所谓在线学习),而训练好的模型也都会以一定的频率更新到线上,以便计算模块及时利用到较新的信息。那么计算模块应该妥当设计,使其能够对模型进行热更新而不影响服务。模型本身由于采样的问题,或是模型自身的局限,还会带来预测值的整体偏差,这个偏差对于需要进行竞价的业务会产生影响,这种情况下计算模块还需要对预测值进行校准。
写在最后
与点击率预估类似的还有转化率预估,这两者是相通的,区别在于预测目标不一样。
点击率预估是一个很大的话题,本文也只是对这个话题的一点介绍,篇幅所限,很多问题只是浮光掠影而过,作者后面会选择其中一些主题再行展开成文。由于本人经验所限,文中所述难免存在错误或纰漏,各位看官不吝批评指正。
[1] Liu et al., (2008). Exploratory Undersampling for Class-Imbalance Learning.
[2] Juan et al., (2016). Field-aware Factorization Machines for CTR Prediction.
[3] Juan et al., (2017). Field-aware Factorization Machines in a Real-world Online Advertising System.
[4] del2z et al., (2016). 深入FFM原理与实践.
[5] Ling et al., (2017). Model Ensemble for Click Prediction in Bing Search Ads.
[6] He et al., (2014). Practical Lessons from Predicting Clicks on Ads at Facebook.

若有收获,就点个赞吧
0 人点赞
