背景
一个任务需要最小实例数目,任务实例数目。最小实例数目满足了,这个任务就可以正常启动。实例数目用户期望实例数目。如果当资源足够情况启动任务所要求实例,当资源满了,如果满足最小实例数目,任务按照最低要求调度
同一队列上调度
例如在queue1,CPU限制10核,reclaimable: false 不可以伸缩。配置如下:
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:name: queue1spec:weight: 1reclaimable: falsecapability:cpu: 10 #cpu 最大使用个数
job1任务最小满足个数为5, 最大运行个数10。每个pod使用1CPU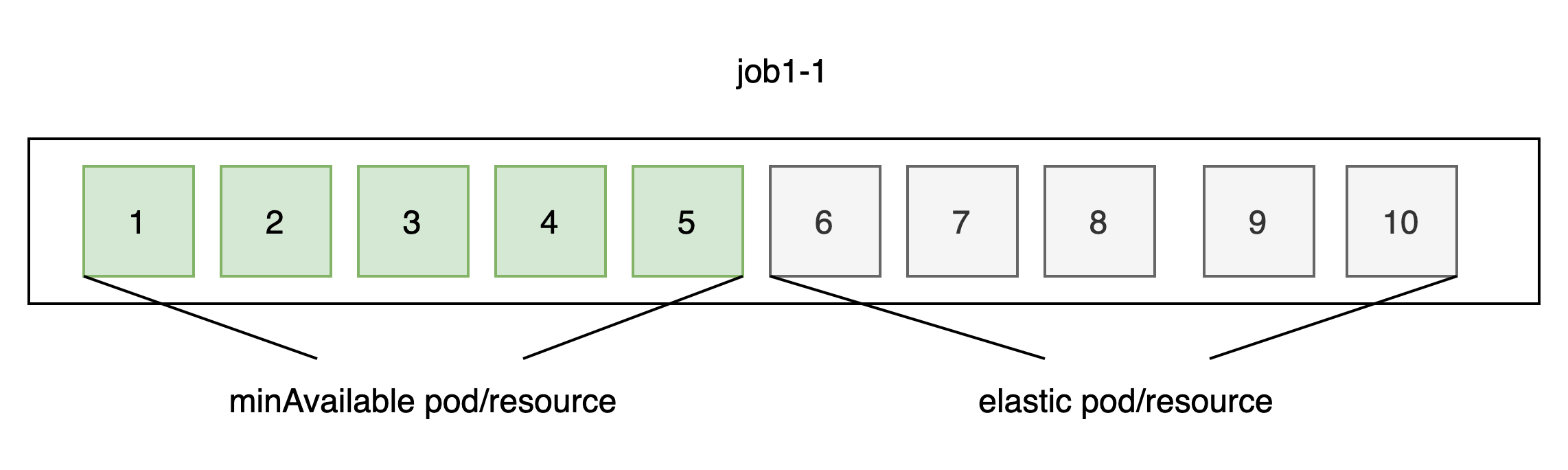
apiVersion: batch.volcano.sh/v1alpha1kind: Jobmetadata:name: job1spec:minAvailable: 5schedulerName: volcanoqueue: queue1tasks:- replicas: 10name: task1template:spec:containers:- image: nginxname: job1-workersresources:requests:cpu: "1"limits:cpu: "1"
job2 同样配置。
apiVersion: batch.volcano.sh/v1alpha1kind: Jobmetadata:name: job2spec:schedulerName: volcanoqueue: queue1minAvailable: 5tasks:- replicas: 10name: task1template:spec:containers:- image: nginxname: job2-workersresources:requests:cpu: "1"limits:cpu: "1"
同时提交job1,job2
job1和job2总最大CPU需求是20, 大于queue 10 cpu限制,按照最低需求启动这两个job。最低需求5个。queue1有足够资源调度两个任务,各启最小配置。
$ cp job1.yaml job2.yaml minAvailable-same-queue/$ cd minAvailable-same-queue/$ kubectl apply -f ./$ kubectl get pod -n defaultNAME READY STATUS RESTARTS AGEjob1-task1-0 0/1 Pending 0 18mjob1-task1-1 1/1 Running 0 18mjob1-task1-2 1/1 Running 0 18mjob1-task1-3 0/1 Pending 0 18mjob1-task1-4 1/1 Running 0 18mjob1-task1-5 1/1 Running 0 18mjob1-task1-6 1/1 Running 0 18mjob1-task1-7 0/1 Pending 0 18mjob1-task1-8 0/1 Pending 0 18mjob1-task1-9 0/1 Pending 0 18m....job2-task1-0 1/1 Running 0 18mjob2-task1-1 0/1 Pending 0 18mjob2-task1-2 1/1 Running 0 18mjob2-task1-3 1/1 Running 0 18mjob2-task1-4 0/1 Pending 0 18mjob2-task1-5 0/1 Pending 0 18mjob2-task1-6 1/1 Running 0 18mjob2-task1-7 0/1 Pending 0 18mjob2-task1-8 1/1 Running 0 18mjob2-task1-9 0/1 Pending 0 18m
增加队列的资源
调整queue1,增加两个核,看看运行任务变化
$ kubectl edit queue queue1apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:creationTimestamp: "2021-12-22T06:57:56Z"generation: 1name: queue1resourceVersion: "43629640"selfLink: /apis/scheduling.volcano.sh/v1beta1/queues/queue1uid: 44940e23-804e-4bcf-941e-12f07d149c37spec:capability:cpu: 12reclaimable: falseweight: 1status:reservation: {}running: 2state: Open
保存以后观察pod变化
$ kubectl get podNAME READY STATUS RESTARTS AGEjob1-task1-0 0/1 Pending 0 28mjob1-task1-1 1/1 Running 0 28mjob1-task1-2 1/1 Running 0 28mjob1-task1-3 0/1 Pending 0 28mjob1-task1-4 1/1 Running 0 28mjob1-task1-5 1/1 Running 0 28mjob1-task1-6 1/1 Running 0 28mjob1-task1-7 0/1 Pending 0 28mjob1-task1-8 0/1 Pending 0 28mjob1-task1-9 0/1 ContainerCreating 0 28m...job2-task1-0 1/1 Running 0 28mjob2-task1-1 0/1 Pending 0 28mjob2-task1-2 1/1 Running 0 28mjob2-task1-3 1/1 Running 0 28mjob2-task1-4 0/1 Pending 0 28mjob2-task1-5 0/1 Pending 0 28mjob2-task1-6 1/1 Running 0 28mjob2-task1-7 0/1 ContainerCreating 0 28mjob2-task1-8 1/1 Running 0 28mjob2-task1-9 0/1 Pending 0 28m
job1, job2 elastic pod 分别增加了一个
减少队列资源
调整queue1,增加两个核,看看运行任务变化
$ kubectl edit queue queue1apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:creationTimestamp: "2021-12-22T06:57:56Z"generation: 1name: queue1resourceVersion: "43629640"selfLink: /apis/scheduling.volcano.sh/v1beta1/queues/queue1uid: 44940e23-804e-4bcf-941e-12f07d149c37spec:capability:cpu: 8reclaimable: falseweight: 1status:reservation: {}running: 2state: Open
保存以后观察pod变化
$ kubectl get podNAME READY STATUS RESTARTS AGEjob1-task1-0 0/1 Pending 0 35mjob1-task1-1 1/1 Running 0 35mjob1-task1-2 1/1 Running 0 35mjob1-task1-3 0/1 Pending 0 35mjob1-task1-4 1/1 Running 0 35mjob1-task1-5 1/1 Running 0 35mjob1-task1-6 1/1 Running 0 35mjob1-task1-7 0/1 Pending 0 35mjob1-task1-8 0/1 Pending 0 35mjob1-task1-9 1/1 Running 0 35m...job2-task1-0 1/1 Running 0 35mjob2-task1-1 0/1 Pending 0 35mjob2-task1-2 1/1 Running 0 35mjob2-task1-3 1/1 Running 0 35mjob2-task1-4 0/1 Pending 0 35mjob2-task1-5 0/1 Pending 0 35mjob2-task1-6 1/1 Running 0 35mjob2-task1-7 1/1 Running 0 35mjob2-task1-8 1/1 Running 0 35mjob2-task1-9 0/1 Pending 0 35m
注意: POD 启动以后减少队列资源不会触发退出pod
不同队列上调度
先后提交job1, job2
在两个队列连分别提交两个job, 看看抢占资源效果。这次使用gpu资源进行调度
Queue1
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:name: queue1spec:weight: 1reclaimable: true
Queue2:
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:name: queue2spec:weight: 1reclaimable: true
系统显卡资源:
$ nvidia_smiThu Dec 23 09:56:28 2021+-----------------------------------------------------------------------------+| NVIDIA-SMI 470.63.01 Driver Version: 470.63.01 CUDA Version: 11.4 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A || 0% 23C P8 11W / 350W | 2MiB / 24268MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+| 1 NVIDIA GeForce ... Off | 00000000:41:00.0 Off | N/A || 0% 23C P8 10W / 350W | 2MiB / 24268MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+| 2 NVIDIA GeForce ... Off | 00000000:A1:00.0 Off | N/A || 0% 23C P8 8W / 350W | 2MiB / 24268MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+| 3 NVIDIA GeForce ... Off | 00000000:C1:00.0 Off | N/A || 0% 23C P8 11W / 350W | 2MiB / 24268MiB | 0% Default || | | N/A |+-------------------------------+----------------------+----------------------+$ kubectl describe nodes...volcano.sh/gpu-memory: 97072volcano.sh/gpu-number: 4...
4 张卡每张卡24268MiB
按照要求每个queue可以占用2张卡, 2*24268MiB 显存,由于是动态配置,资源足够情况各个队列分配超过weight资源。例如Job1占用4卡资源,yaml如下:
job1.yaml
apiVersion: batch.volcano.sh/v1alpha1kind: Jobmetadata:name: job1spec:minAvailable: 2schedulerName: volcanoqueue: queue1tasks:- replicas: 4name: task1template:spec:containers:- image: nginxname: job1-workersresources:requests:cpu: "1"limits:cpu: "1"volcano.sh/gpu-memory: "24268"
job1: minAvailable2: 调度器按照minAvailable2最低要求分配资源job1, 如果资源满足调度启动POD, 如果不满足最低要,任务无法执行,先考虑其他任务了。
$ kubectl apply -f job1.yaml$ kubectl get podNAME READY STATUS RESTARTS AGEjob1-task1-0 1/1 Running 0 5m40sjob1-task1-1 1/1 Running 0 5m40sjob1-task1-2 1/1 Running 0 5m40sjob1-task1-3 1/1 Running 0 5m40s
然后再启动job2, job2是使用queue2进行调度的
apiVersion: batch.volcano.sh/v1alpha1kind: Jobmetadata:name: job2spec:schedulerName: volcanoqueue: queue2minAvailable: 2tasks:- replicas: 4name: task1template:spec:containers:- image: nginxname: job2-workersresources:requests:cpu: "1"limits:cpu: "1"volcano.sh/gpu-memory: "24268"
提交job2.yaml
$ kubectl apply -f job2.yaml$ kubectl get podNAME READY STATUS RESTARTS AGEjob1-task1-0 1/1 Running 0 7m36sjob1-task1-1 1/1 Running 0 7m36sjob1-task1-2 1/1 Running 0 7m36sjob1-task1-3 1/1 Running 0 7m36sjob2-task1-0 0/1 Pending 0 6sjob2-task1-1 0/1 Pending 0 6sjob2-task1-2 0/1 Pending 0 6sjob2-task1-3 0/1 Pending 0 6s$ kubectl describe vcjob job2...Warning PodGroupPending 65s (x3 over 65s) vc-controller-manager PodGroup default:job2 unschedule,reason: 2/4 tasks in gang unschedulable: pod group is not ready, 2 minAvailable, 4 Pending; Pending: 1 Unschedulable, 3 Undetermined...
调度器不会主动驱逐job1任务实例,让job2占资源,但是可以手动关闭job1两个任务, job1-task1-0,job1-task1-1:
$ kubectl delete pod job1-task1-0 job1-task1-1$ kubectl get podNAME READY STATUS RESTARTS AGEjob1-task1-0 0/1 Pending 0 13sjob1-task1-1 0/1 Pending 0 5sjob1-task1-2 1/1 Running 0 117mjob1-task1-3 1/1 Running 0 117mjob2-task1-0 0/1 ContainerCreating 0 110mjob2-task1-1 0/1 Pending 0 110mjob2-task1-2 0/1 ContainerCreating 0 110mjob2-task1-3 0/1 Pending 0 110m
由于queue1超配资源,释放连个pod以后,刚好到job2启动最少gpu资源,调度有些启动job2两个pod。

若有收获,就点个赞吧
0 人点赞
