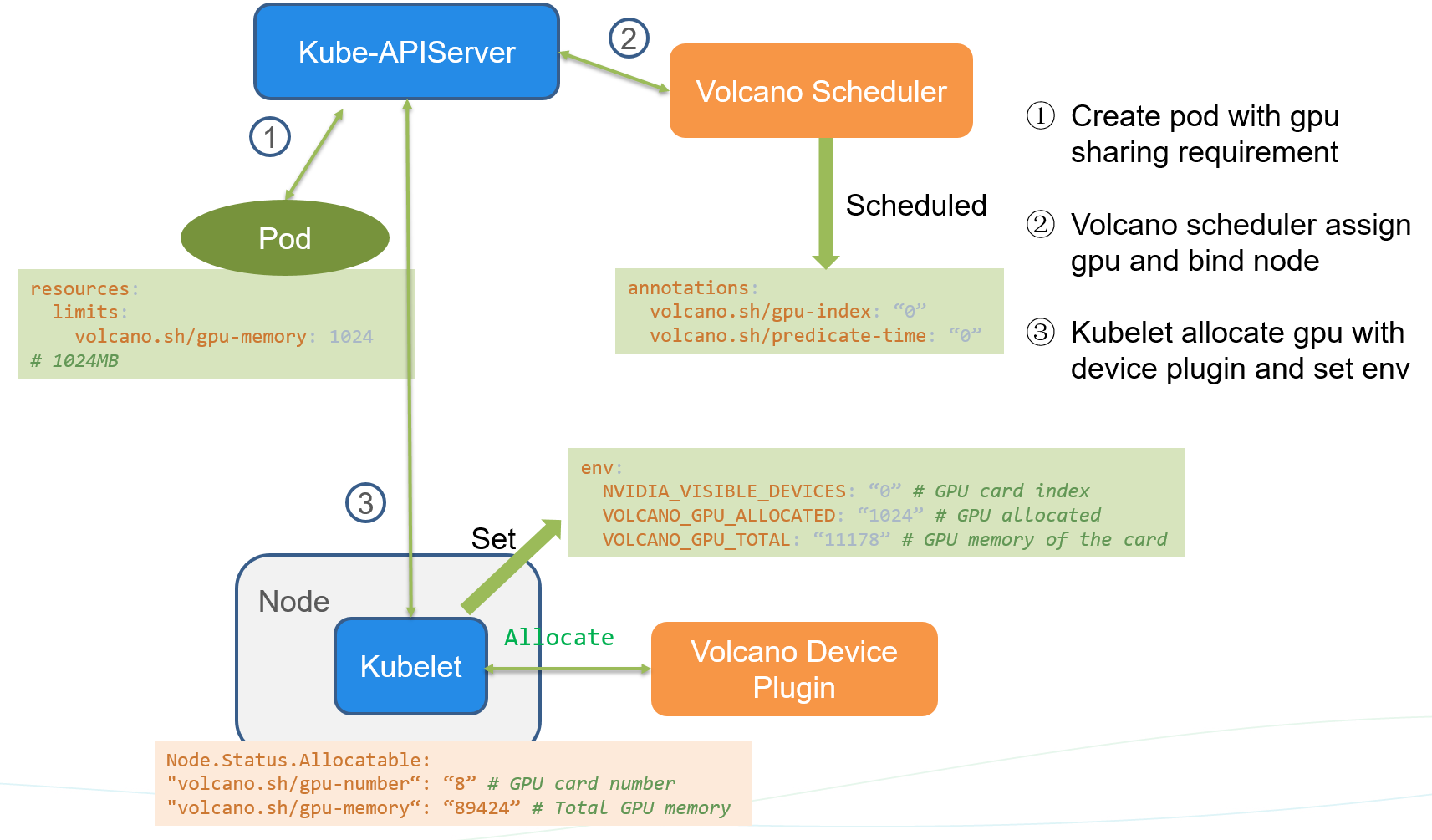
Volcano 调度器分配共享GPU流程梳理
获取节点GPU信息
节点GPU信息
安装volcano-device-plugin每个节点在增加两个资源描述信息volcano.sh/gpu-number 记录显卡数目,volcano.sh/gpu-memory 记录显存单元数目。例如24G显存显卡,切分单元是1G, gpu-memory 为 24
| YAML apiVersion: v1 kind: Node metadata: # ……. spec: allocatable: cpu: 127900m ephemeral-storage: “48294789041” hugepages-1Gi: “0” hugepages-2Mi: “0” memory: 263686056Ki pods: “110” volcano.sh/gpu-memory: “240” volcano.sh/gpu-number: “10” capacity: cpu: “128” ephemeral-storage: 51175Mi hugepages-1Gi: “0” hugepages-2Mi: “0” memory: 264050600Ki pods: “110” volcano.sh/gpu-memory: “240” # 可分配显存单元数目 volcano.sh/gpu-number: “10” # 显卡数目 |
|---|
初始化节点GPU信息
GPU 信息结构够体 valcano/pkg/scheduler/device_info
| Go // GPUDevice include gpu id, memory and the pods that are sharing it. type GPUDevice struct { // GPU ID ID int // The pods that are sharing this GPU PodMap map[string]*v1.Pod // 记录当前使用GPU的pod // memory per card Memory uint // (volcano.sh/gpu-memroy) / (volcano.sh/gpu-number) } |
|---|
节点初始化 valcano/pkg/scheduler/node_info.go
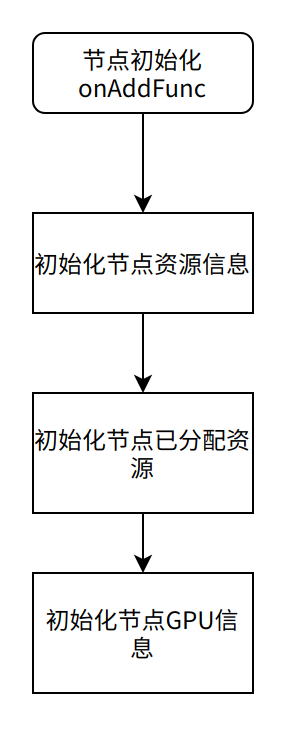
初始化节点GPU代码
GPU信息存在在map里面的
| Go
// NodeInfo is node level aggregated information.
type NodeInfo struct {
Name string
Node *v1.Node
// The state of node<br /> State NodeStateAllocatable *Resource<br /> Capability *Resource<br /> // .....<br /> GPUDevices map[int]*GPUDevice<br /> // .....<br /> }<br /> <br /> // NewNodeInfo is used to create new nodeInfo object<br />func NewNodeInfo(node *v1.Node) *NodeInfo {<br /> nodeInfo := &NodeInfo{<br /> Releasing: EmptyResource(),<br /> Pipelined: EmptyResource(),<br /> Idle: EmptyResource(),<br /> Used: EmptyResource(),Allocatable: EmptyResource(),<br /> Capability: EmptyResource(),OversubscriptionResource: EmptyResource(),<br /> Tasks: make(map[TaskID]*TaskInfo),GPUDevices: make(map[int]*GPUDevice),<br /> }<br /> // ....<br /> } |
| —- |
| Go func (ni NodeInfo) setNodeGPUInfo(node v1.Node) { if node == nil { return } // VolcanoGPUResource = “volcano.sh/gpu-memroy” memory, ok := node.Status.Capacity[VolcanoGPUResource] if !ok { return } totalMemory := memory.Value() // VolcanoGPUNumber = “volcano.sh/gpu-number” res, ok := node.Status.Capacity[VolcanoGPUNumber] if !ok { return } gpuNumber := res.Value() if gpuNumber == 0 { klog.Warningf(“invalid %s=%s”, VolcanoGPUNumber, res.String()) return } // 调度器不可以获取显卡UID, 使用显卡index,显存也是默认每张显卡一样,显存大小不一致 // 节点也是不能使用解决方案的 memoryPerCard := uint(totalMemory / gpuNumber) for i := 0; i < int(gpuNumber); i++ { // 初始化每张GPU卡显存信息 ni.GPUDevices[i] = NewGPUDevice(i, memoryPerCard) } } |
|---|
更新节点信息
当节点状态修改,资源分配信息改变以后,触发Node OnUpdate。更新节点资源分配信息
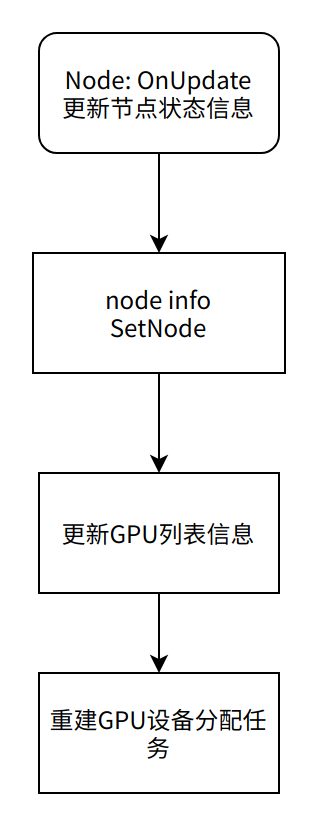
更新GPU设备列表:
| Go func (ni NodeInfo) setNodeGPUInfo(node v1.Node) { if node == nil { return } // VolcanoGPUResource = “volcano.sh/gpu-memroy” memory, ok := node.Status.Capacity[VolcanoGPUResource] if !ok { return } totalMemory := memory.Value() // VolcanoGPUNumber = “volcano.sh/gpu-number” res, ok := node.Status.Capacity[VolcanoGPUNumber] if !ok { return } gpuNumber := res.Value() if gpuNumber == 0 { klog.Warningf(“invalid %s=%s”, VolcanoGPUNumber, res.String()) return } memoryPerCard := uint(totalMemory / gpuNumber) // 节点更新是由于GPU数目变化,而且数目变少的时候出现问题 // 更新时候没有重置GPUDevices,例如gpu数目由10 下降到 9,id没有由原理【0 - 9】, // 下降 【0 - 8】 for i := 0; i < int(gpuNumber); i++ { // 初始化每张GPU卡显存信息 ni.GPUDevices[i] = NewGPUDevice(i, memoryPerCard) } } |
|---|
| 注意 当节点GPU损坏以后,通过nvidia屏蔽以后,如果重新启动,节点GPU数目减少,调度更新GPU信息时候,高值的index残留在map里面,导致调度到不存在设备上错误pod出现UnexpectedAdmissionError 错误 提交到社区 https://github.com/volcano-sh/volcano/pull/2215 |
|---|
选择节点GPU指派pod上
如果Pod包含volcano.sh/gpu-momory 并且调度器支持 share GPU 走下面流程
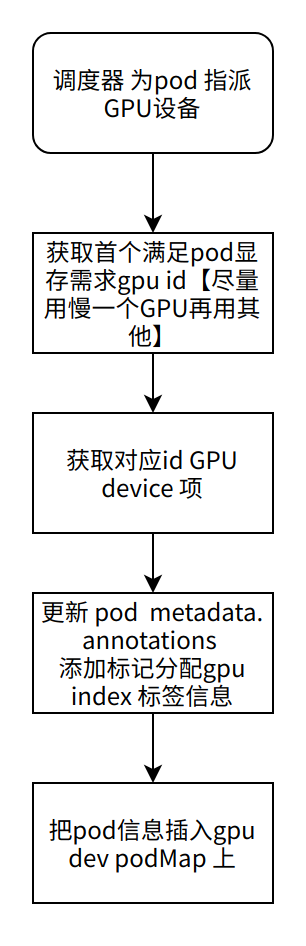
代码如下:
pkg/scheduler/plugins/predicates/predicates.go
| Go
func (pp predicatesPlugin) OnSessionOpen(ssn framework.Session) {
// ……..
// Register event handlers to update task info in PodLister & nodeMap
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
// ……..
if predicate.gpuSharingEnable && api.GetGPUResourceOfPod(pod) > 0 {
nodeInfo, ok := ssn.Nodes[nodeName]
if !ok {
klog.Errorf(“Failed to get node %s info from cache”, nodeName)
return
}
id := predicateGPU(pod, nodeInfo)<br /> if id < 0 {<br /> klog.Errorf("The node %s can't place the pod %s in ns %s", pod.Spec.NodeName, pod.Name, pod.Namespace)<br /> return<br /> }<br /> dev, ok := nodeInfo.GPUDevices[id]<br /> if !ok {<br /> klog.Errorf("Failed to get GPU %d from node %s", id, nodeName)<br /> return<br /> }<br /> patch := api.AddGPUIndexPatch(id)<br /> pod, err := kubeClient.CoreV1().Pods(pod.Namespace).Patch(context.TODO(), pod.Name, types.JSONPatchType, []byte(patch), metav1.PatchOptions{})<br /> if err != nil {<br /> klog.Errorf("Patch pod %s failed with patch %s: %v", pod.Name, patch, err)<br /> return<br /> }<br /> dev.PodMap[string(pod.UID)] = pod<br /> klog.V(4).Infof("predicates with gpu sharing, update pod %s/%s allocate to node [%s]", pod.Namespace, pod.Name, nodeName)<br /> }node.AddPod(pod)<br /> klog.V(4).Infof("predicates, update pod %s/%s allocate to node [%s]", pod.Namespace, pod.Name, nodeName)<br /> },<br />} |
| —- |
统计GPU显存使用量
每个gpu结构体下都有一个PodMap, 通过统计PodMap所以pod 所以资源,遍历pod所以containers,统计volcano.sh/gpu-memory 总数。
pkg/scheduler/api/device_info.go
| Go
// getUsedGPUMemory calculates the used memory of the device.
// 遍历gpu podMap 所有pod
func (g *GPUDevice) getUsedGPUMemory() uint {
res := uint(0)
for _, pod := range g.PodMap {
if pod.Status.Phase == v1.PodSucceeded || pod.Status.Phase == v1.PodFailed {
continue
} else {
gpuRequest := GetGPUResourceOfPod(pod)
res += gpuRequest
}
}
return res
}
// GetGPUResourceOfPod returns the GPU resource required by the pod.
// 遍历pod 下所以 container
func GetGPUResourceOfPod(pod *v1.Pod) uint {
var mem uint
for _, container := range pod.Spec.Containers {
mem += getGPUResourceOfContainer(&container)
}
return mem
}
// getGPUResourceOfPod returns the GPU resource required by the container.
// 获取conteinr下gpu-memory 使用量
func getGPUResourceOfContainer(container *v1.Container) uint {
var mem uint
if val, ok := container.Resources.Limits[VolcanoGPUResource]; ok {
mem = uint(val.Value())
}
return mem
} |
| —- |
选择合适GPU
获取pod需要gpu资源数量volcano.sh/gpu-memory , 计算所以gpu剩下内存资源,从0-n遍历找到合适gpu index。代码如下:
| Go
// predicateGPU returns the available GPU ID
func predicateGPU(pod v1.Pod, node api.NodeInfo) int {
gpuRequest := api.GetGPUResourceOfPod(pod)
allocatableGPUs := node.GetDevicesIdleGPUMemory()
for devID := 0; devID < len(allocatableGPUs); devID++ {<br /> availableGPU, ok := allocatableGPUs[devID]<br /> if ok {<br /> if availableGPU >= gpuRequest {<br /> return devID<br /> }<br /> }<br /> }return -1<br />} |
| —- |
一般先把当前节点首张显卡使用完毕以后,再用下面的一张显卡,除非第一张显卡不满足当前pod需要。
如果pod gpu 使用量大于一张显卡的显存,不能使用共享显卡,报错为没有一张符合要求。共享模式下,一个Pod最多只能分配1GPU显存容量。
调度器重启后恢复之前GPU调度信息
调度器如果更新以后,重新启动以后之前GPU调度信息是否能够恢复,GPU调度信息就是存在GPUDevices 列表的每个device 的 PodMap 字段能够通过k8s api 恢复这些数据。 目前看来这些数组是缓存在内存,没有存储到etcd里面的。
如果可以恢复,出现状态不同步时候,可以通过重新启动scheduler获取信息最新状态,如果不能同步,当然这些调度器不可以用。
恢复我们这边首先关注节点信息,以及pod信息,这两条线看看调度器调度数据恢复机制
Node 事件机制恢复
主要恢复节点资源信息,以及重新生成数据GPU 设备信息
pkg/scheduler/cache/cache.go
| Go func newSchedulerCache(config rest.Config, schedulerName string, defaultQueue string, nodeSelectors []string) SchedulerCache { // create informer for node information sc.nodeInformer = informerFactory.Core().V1().Nodes() sc.nodeInformer.Informer().AddEventHandlerWithResyncPeriod( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{}) bool { node, ok := obj.(v1.Node) if !ok { klog.Errorf(“Cannot convert to v1.Node: %v”, obj) return false } if !responsibleForNode(node.Name, mySchedulerPodName, c) { return false } if len(sc.nodeSelectorLabels) == 0 { return true } for labelName, labelValue := range node.Labels { key := labelName + “:” + labelValue if _, ok := sc.nodeSelectorLabels[key]; ok { return true } } klog.Infof(“node %s ignore add/update/delete into schedulerCache”, node.Name) return false }, Handler: cache.ResourceEventHandlerFuncs{ // 通过 nodeInfo 数据结构管理node, 可以参考新建、更新节点流程 AddFunc: sc.AddNode, UpdateFunc: sc.UpdateNode, DeleteFunc: sc.DeleteNode, }, }, 0, ) } |
|---|
节点信息恢复以后,共享显卡分配情况需要通过pod信息恢复重新初始化。
Pod 事件机制恢复任务数据
k8s api 都是采用事件通知机制,可以新建pod informer 获取整个集群Pod增删改的事件。代码在
pkg/scheduler/cache/cache.go
| Go func newSchedulerCache(config rest.Config, schedulerName string, defaultQueue string, nodeSelectors []string) SchedulerCache { // … sc.podInformer = informerFactory.Core().V1().Pods() // … // create informer for pod information sc.podInformer.Informer().AddEventHandler( cache.FilteringResourceEventHandler{ FilterFunc: func(obj interface{}) bool { switch v := obj.(type) { case *v1.Pod: if !responsibleForPod(v, schedulerName, mySchedulerPodName, c) { if len(v.Spec.NodeName) == 0 { return false } if !responsibleForNode(v.Spec.NodeName, mySchedulerPodName, c) { return false } } return true default: return false } }, Handler: cache.ResourceEventHandlerFuncs{ // 添加事情: // 1. 启动时候可以获取所有已经创建pod, 可以用于启动获取历史数据 // 2. 运行期间:pod 新建 pod 都收到回调 AddFunc: sc.AddPod, // 处理Pod 状态更新 UpdateFunc: sc.UpdatePod, // 处理Pod 删除 DeleteFunc: sc.DeletePod, }, }) } |
|---|
系统启动时候,informer 收到系统所有Pod AddFunc, 通过这个函数,获取所有历史pod信息,可以初始化GPU分配列表。流程如下:
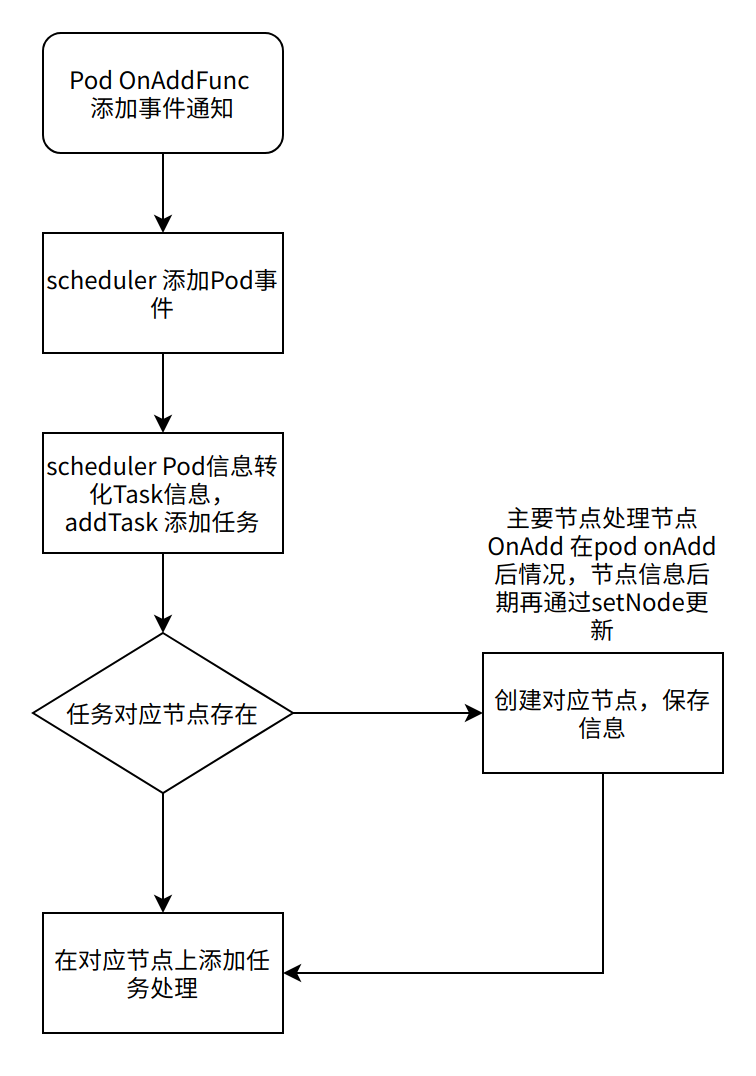
函数调用列表【pkg/scheduler/cache/eventhandlers.go】
sc.AddPod
sc.addPod [NewTaskInfon]
sc.AddTask [ , found := sc.Nodes[pi.NodeName]]
node.addTask
所以 node.addTask, 用户缓存node节点上所有任务,node所有pod。
NodeInfo 接口处理AddTask
调度器重新启动以后,通过Pod Add 事件能够获取当前系统所以pod信息,通过Pod信息格式化为Task信息,通过此接口保存Pod对应节点Task 列表,通过通过task Pod信息,统计各个显卡分配情况。pkg/scheduler/api/node_info.go
| Go
// NodeInfo is node level aggregated information.
type NodeInfo struct {
Name string
Node v1.Node
// ……
// 保存当前节点任务以及任务对应pod信息,节点所以pod转化任务结构保存
Tasks map[TaskID]TaskInfo
}
// If error occurs both task and node are guaranteed to be in the original state.
func (ni NodeInfo) AddTask(task TaskInfo) error {
if len(task.NodeName) > 0 && len(ni.Name) > 0 && task.NodeName != ni.Name {
return fmt.Errorf(“task <%v/%v> already on different node <%v>”,
task.Namespace, task.Name, task.NodeName)
}
// 获取Podkey: namespace/podName
key := PodKey(task.Pod)
if _, found := ni.Tasks[key]; found {
return fmt.Errorf(“task <%v/%v> already on node <%v>”,
task.Namespace, task.Name, ni.Name)
}
// Node will hold a copy of task to make sure the status<br /> // change will not impact resource in node.<br /> ti := task.Clone()if ni.Node != nil {<br /> switch ti.Status {<br /> case Releasing:<br /> if err := ni.allocateIdleResource(ti); err != nil {<br /> return err<br /> }<br /> ni.Releasing.Add(ti.Resreq)<br /> ni.Used.Add(ti.Resreq)<br /> // 更新GPU列表,资源插入到gpuDevice.PodMap 中<br /> ni.AddGPUResource(ti.Pod)<br /> case Pipelined:<br /> ni.Pipelined.Add(ti.Resreq)<br /> default:<br /> if err := ni.allocateIdleResource(ti); err != nil {<br /> return err<br /> }<br /> ni.Used.Add(ti.Resreq)<br /> // 更新GPU列表,资源插入到gpuDevice.PodMap 中<br /> ni.AddGPUResource(ti.Pod)<br /> }<br /> }if ni.NumaInfo != nil {<br /> ni.NumaInfo.AddTask(ti)<br /> }// Update task node name upon successful task addition.<br /> task.NodeName = ni.Name<br /> ti.NodeName = ni.Name<br /> // 插入到Tasks, 便于<br /> ni.Tasks[key] = tireturn nil<br />} |
| —- |
GPU设备登记资源使用情况
GPU使用情况,把pod直接插入GPUDevices 对应index 显卡上
| Go // AddGPUResource adds the pod to GPU pool if it is assigned func (ni NodeInfo) AddGPUResource(pod v1.Pod) { gpuRes := GetGPUResourceOfPod(pod) if gpuRes > 0 { id := GetGPUIndex(pod) if dev := ni.GPUDevices[id]; dev != nil { dev.PodMap[string(pod.UID)] = pod } } } |
|---|
结论
显卡掉线处理
节点出现一个和多个显卡掉线,还是需要按照节点下线流程
配置节点不调度
| Bash $ kubectl cordon |
|---|
驱逐节点所有Pod
| Bash # 先确认模型镜像在其他节点存在,模型镜像可能有6GB,下载需要一段时间,迁移前确认镜像问题 $ kuberctl drain |
|---|
屏蔽有问题的显卡
| 原因 Volcano 共享GPU 使用 NVIDIA_VISIBLE_DEVICES: ‘gpu_index’ 使用索引控制容器可以对应GPU。如果下线GPU刚好在中部 屏蔽以后显卡 index 重新排列 模型使用末尾GPU POD后面重新启动无法获取对应index GPU错误 并且导致对应index后面GPU显存被过多POD使用问题 |
|---|
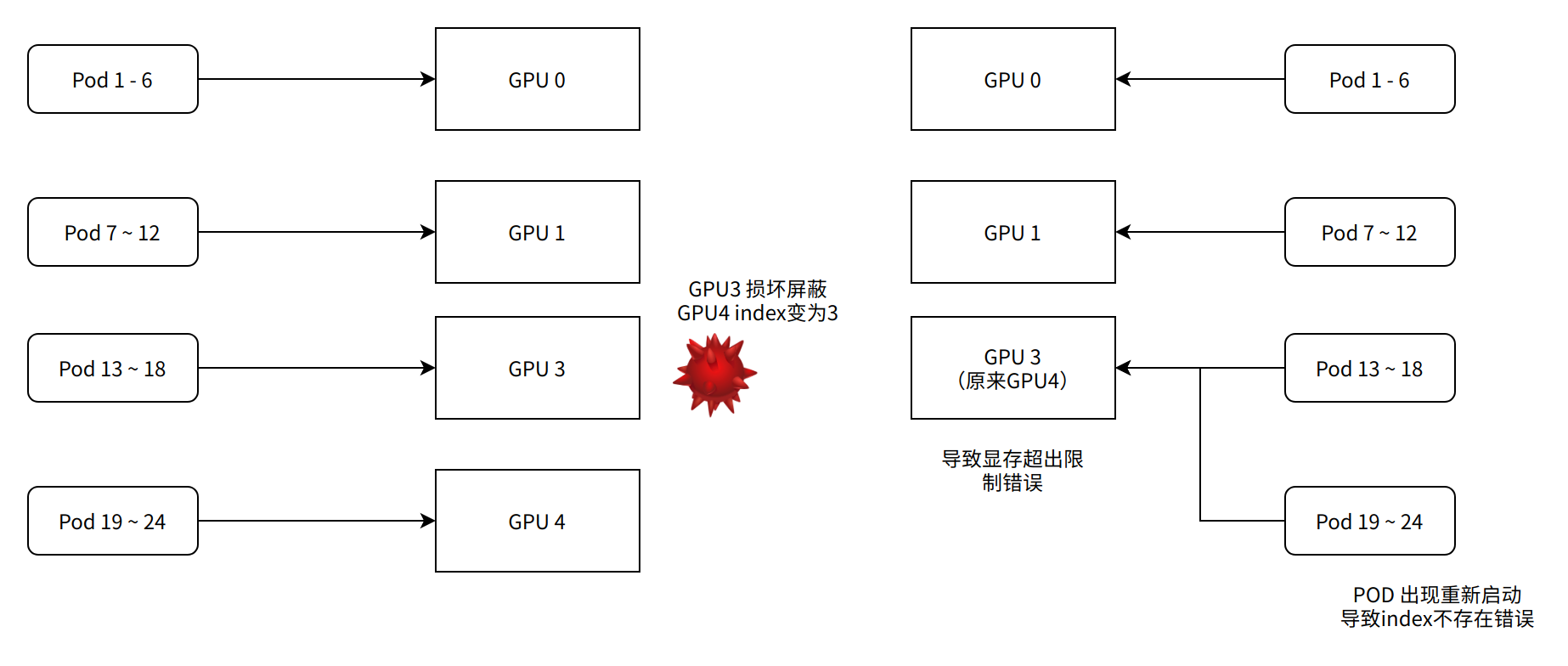
处理调度器同步问题
屏蔽显卡,显卡数目减少,对应id没有删除问题fix提交到社区,社区确认patch,如果没有合并可以先最新版本编译解决。
参考
代码: GitHub - volcano-sh/volcano: A Cloud Native Batch System (Project under CNCF)

若有收获,就点个赞吧
0 人点赞
