从搭建到配置流程(基于单体的架构,集群在配置文件要修改的地方会说清楚)
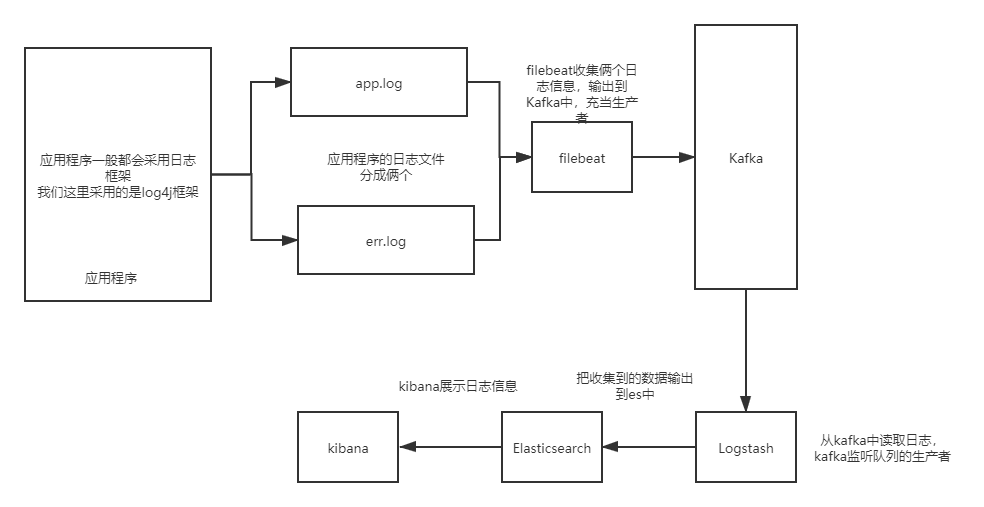
搭建应用服务 :
日志收集采用log4j收集项目日志
项目地址 简单明了的项目地址
Kafka的安装
从Kafka的官网下载Kafka的压缩包到/opt 目录
tar -zxvf kafka_2.12-0.11.0.0.tgz -C /usr/local/kafka-2.12 cd /usr/local/kafka-2.12 vi config/server.properties
需要修改的地方
port=9092host.name=IP地址advertised.host.name=IP地址#我指定了logs地址log.dirs=/usr/local/kafka_2.12/kafka-logszookeeper.connect=101.132.35.66:2181
启动
./kafka-server-start.sh -f /usr/local/kafka_2.12/config/server.properties 看到最后停止就有start的或者success就表示启动成功 后台启动 nohup ./kafka-server-start.sh -f /usr/local/kafka_2.12/config/server.properties &
filebeat的安装
去Elasticsearch官网下载时可以找到filebeat的版本下载,最好跟EKL版本一样
把下载的压缩包上传到服务器上的/opt目录下 解压到 /usr/local/ tar -zxvf filebeat-6.8.4-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/filebeat-6.8.4-linux-x86_64/ 看到filebeat.yml
添加下面这段配置,如果粘贴过去格式乱了最好先在本地环境写好yml然后上传到filebeat目录下面
###################### Filebeat Configuration Example #########################
filebeat.prospectors:
- input_type: log #名字可以随意,标识
paths:
## app-服务名称.log, 为什么写死,防止发生轮转抓取历史数据
#我们的应用服务会放在 /usr/local/应用程序,他会在同级生成logs目录,就是该目录
- /usr/local/logs/app-collector.log
#定义写入 ES 时的 _type 值
document_type: "app-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 1000 # 最大的行数 合并的最大行数 (一般是合并异常信息)
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: app-log-collector ## 按服务划分用作kafka topic
evn: dev
- input_type: log # 也可以随意
paths:
# 跟上面一样的解释
- /usr/local/logs/error-collector.log
document_type: "error-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: error-log-collector ## 按服务划分用作kafka topic
evn: dev
output.kafka:
enabled: true
#Kafka地址
hosts: ["192.168.11.51:9092"]l
topic: '%{[fields.logtopic]}' #写入到的topic名称 上面的属性定义了
partition.hash:
reachable_only: true
compression: gzip #压缩日志上传
max_message_bytes: 1000000
required_acks: 1
logging.to_files: true
然后就可以可以启动filebeat了
可以先检查配置文件是否正确 ./filebeat -c filebeat.yml -configtest ## Config OK 表示没有问题 _ 后台启动 nohup ./filebeat &
前台启动 ./filebeat &
怎么测试filebeat是否能成功读取呢,把应用程序在/usr/local/目录下面启动
然后访问地址的 项目的地址 ip:9099/index 或者 ip:9099/err 然后去Kafka的 自己配置的Kafka的log目录去看就会发现有 error-log-collector-0 或者app-log-collector-0会有字节大小就说明配置生效了filebeat能读取日志文件输出到Kafka上面了
Logstash安装
从Elasticsearch 官网上面下载 6.8.4的版本
把下载来的Logstash 解压到 /usr/local/logstash-6.8.4 进入 logstash-6.8.4
创建一个自己配置文件的目录 mkdir sync-kafka vim logstash-kafka.conf
## multiline 插件也可以用于其他类似的堆栈式信息,比如 linux 的内核日志。
input {
kafka {
## app-log-服务名称
topics_pattern => "app-log-.*"
bootstrap_servers => "192.168.8.170:9092" #kafka地址
codec => json #输出格式json
consumer_threads => 1 ## 增加consumer的并行消费线程数 优化之一 Logstash开启多少个线程消费
decorate_events => true
#auto_offset_rest => "latest"
group_id => "app-log-group" #kafka的分组
}
kafka {
## error-log-服务名称
topics_pattern => "error-log-.*"
bootstrap_servers => "192.168.8.170:9092"
codec => json
consumer_threads => 1
decorate_events => true
#auto_offset_rest => "latest"
group_id => "error-log-group"
}
}
filter {
## 时区转换 es的时间问题所以我们得时间转换不然日志输出会有问题,我们比es的时间慢半个小时 东八区
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"
}
#filebeat 中定义的 [fields][logtopic] 字段属性
if "app-log" in [fields][logtopic]{
grok {
## 表达式,这里对应的是Springboot输出的日志格式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if "error-log" in [fields][logtopic]{
grok {
## 表达式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
}
## 测试输出到控制台:
output {
stdout { codec => rubydebug }
}
## elasticsearch:
output {
if "app-log" in [fields][logtopic]{
## es插件
elasticsearch {
# es服务地址
hosts => ["192.168.8.170:9200"]
# 用户名密码
# user => "elastic"
# password => "123456"
## 索引名,+ 号开头的,就会自动认为后面是时间格式:
## javalog-app-service-2019.01.23
index => "app-log-%{[fields][logbiz]}-%{index_time}"
# 是否嗅探集群ip:一般设置true;http://192.168.8.170:9200/_nodes/http?pretty
# 通过嗅探机制进行es集群负载均衡发日志消息
sniffing => true
# logstash默认自带一个mapping模板,进行模板覆盖
template_overwrite => true
}
}
if "error-log" in [fields][logtopic]{
elasticsearch {
hosts => ["192.168.8.170:9200"]
user => "elastic"
password => "123456"
index => "error-log-%{[fields][logbiz]}-%{index_time}"
sniffing => true
template_overwrite => true
}
}
}
配置完成,启动Logstash
到 logstash的bin目录下面启动 ./logstash -f /usr/local/logstash-6.8.4/sync-kafka-logs/logstash-kafka.conf &
等logstash启动就可以看到控制台输出 收集到Kafka的日志输出了
Elasticsearch安装
Kibana安装
从es的官网下载对应的6.8.4的版本下载 Kibana-6.8.4链接下载
把下载的压缩包上传到 /opt目录下面
tar -zxvf kibana-6.8.4-linux-x86_64.tar.gz -C /usr/local/ cd /usr/local/kibana/config 修改下面的 kibana.yml文件
配置文件添加该配置
server.host: "192.168.8.170"
elasticsearch.hosts: ["http://192.168.8.170:9200"]
#elasticsearch.username: "user" 有账号就添加账号
#elasticsearch.password: "pass" 有密码就添加密码
到bin 目录启动 nohup ./kibana
到kibana页面的 management的页面绑定索引管理
就可以看到日志数据在kibana上面展示了
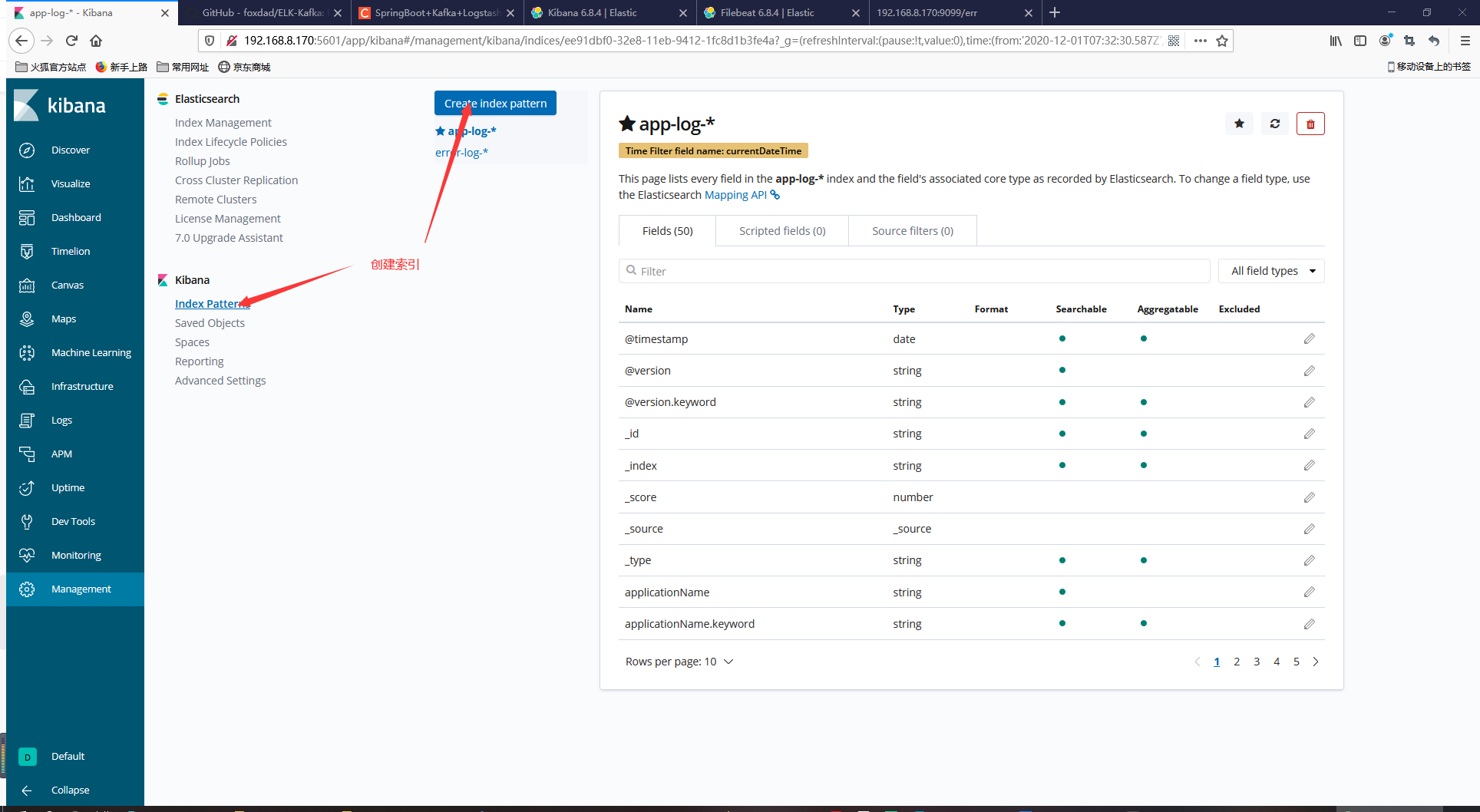
我们之前的索引操作是 err-log-服务名 所以我们匹配的就是 err-log-*下的所有匹配了

若有收获,就点个赞吧
0 人点赞
