Prometheus简介
Prometheus是一个开源监控系统,它前身是SoundCloud的警告工具包。从2012年开始,许多公司和组织开始使用Prometheus。该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。目前它是一个独立的开源项目,且不依赖与任何公司。 为了强调这点和明确该项目治理结构,Prometheus在2016年继Kurberntes之后,加入了Cloud Native Computing Foundation。
特征
Prometheus的主要特征有:
- 多维度数据模型
- 灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自主的
- 以HTTP方式,通过pull模型拉去时间序列数据
- 也通过中间网关支持push模型
- 通过服务发现或者静态配置,来发现目标服务对象
-
组件
Prometheus生态包括了很多组件,它们中的一些是可选的:
主服务Prometheus Server负责抓取和存储时间序列数据
- 客户库负责检测应用程序代码
- 支持短生命周期的PUSH网关
- 基于Rails/SQL仪表盘构建器的GUI
- 多种导出工具,可以支持Prometheus存储数据转化为HAProxy、StatsD、Graphite等工具所需要的数据存储格式
- 警告管理器
- 命令行查询工具
- 其他各种支撑工具
多数Prometheus组件是Go语言写的,这使得这些组件很容易编译和部署。
架构
下面这张图说明了Prometheus的整体架构,以及生态中的一些组件作用:
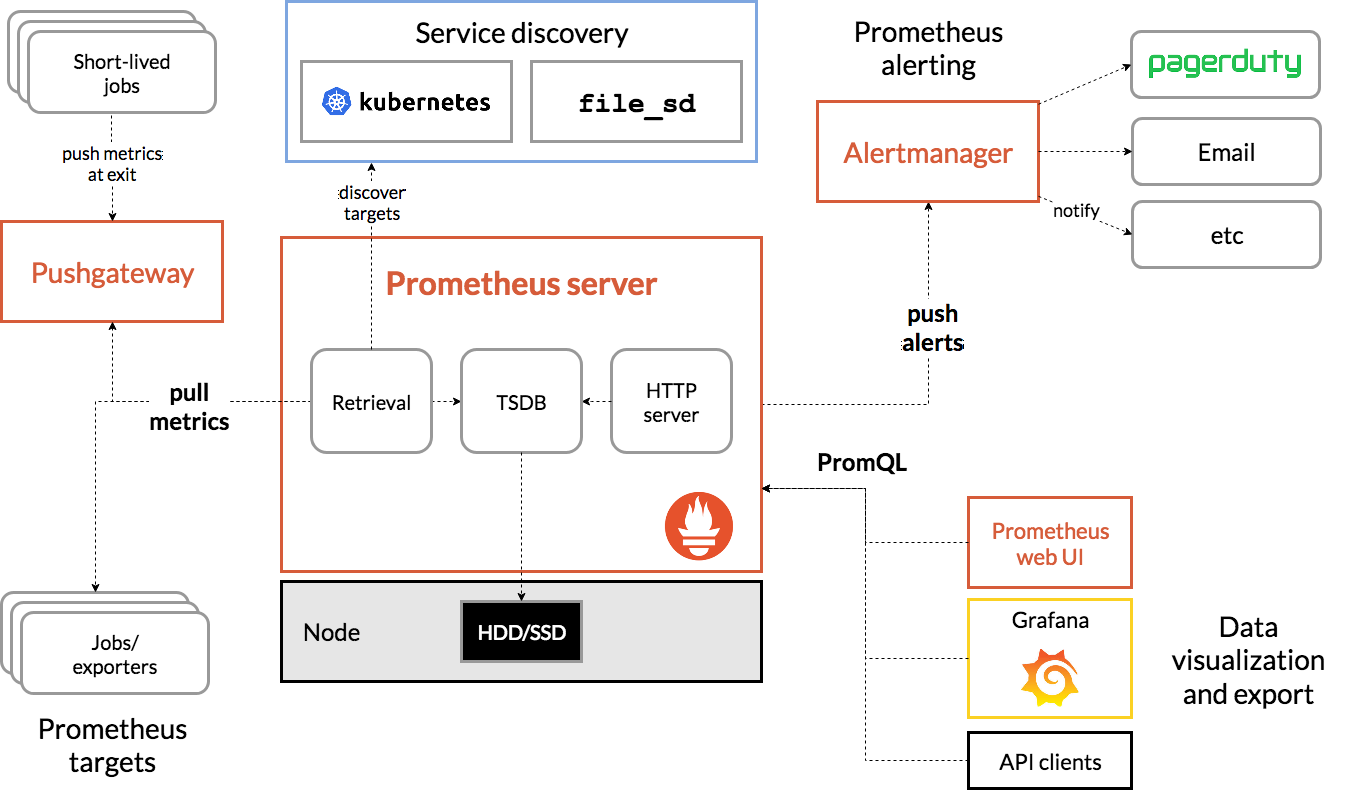
Prometheus服务,可以直接通过目标拉取数据,或者间接地通过中间网关拉取数据。它在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中,PromQL和其他API可视化地展示收集的数据。
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
适用场景
Prometheus在记录纯数字时间序列方面表现非常好。它既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控。对于现在流行的微服务,Prometheus的多维度数据收集和数据筛选查询语言也是非常的强大。
Prometheus是为服务的可靠性而设计的,当服务出现故障时,它可以使你快速定位和诊断问题。它的搭建过程对硬件和服务没有很强的依赖关系。不适用场景
Prometheus,它的价值在于可靠性,甚至在很恶劣的环境下,你都可以随时访问它和查看系统服务各种指标的统计信息。 如果你对统计数据需要100%的精确,它并不适用,例如:它不适用于实时计费系统
安装
#解压到/usr/local/目录下面
tar -vxf prometheus-2.21.0.linux-amd64.tar.gz -C /usr/local/
#修改名字
mv prometheus-2.21.0.linux-amd64 prometheus
#启动
/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
默认9090端口 ip:9090
安装常用的监控exporter
https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
#解压
tar -xvf node_exporter-0.17.0.linux-amd64.tar.gz -C /usr/local/
启动
/usr/local/node_exporter-0.17.0.linux-amd64/node_exporter &
redis监控直接在Grafana配置
Prometheus的yml配置文件
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'linux' #监控系统的状态
static_configs:
- targets: ['192.168.8.175:9100']
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.8.175:9090']
# - job_name: 'mysql'
# static_configs:
# - targets: ['192.168.8.175:9104']
Grafana
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
Grafana安装
#下载
wget https://dl.grafana.com/oss/release/grafana-7.1.5-1.x86_64.rpm
yum install grafana-7.1.5-1.x86_64.rpm -y
接着把grafana加入到系统服务,将服务启动
/sbin/chkconfig --add grafana-server
默认3000端口,如果端口被占用请修改
vim /etc/grafana/grafana.ini
修改配置文件中的 http_port=80 注意要把;号给去掉,这是注释
service grafana-server start
Grafana配置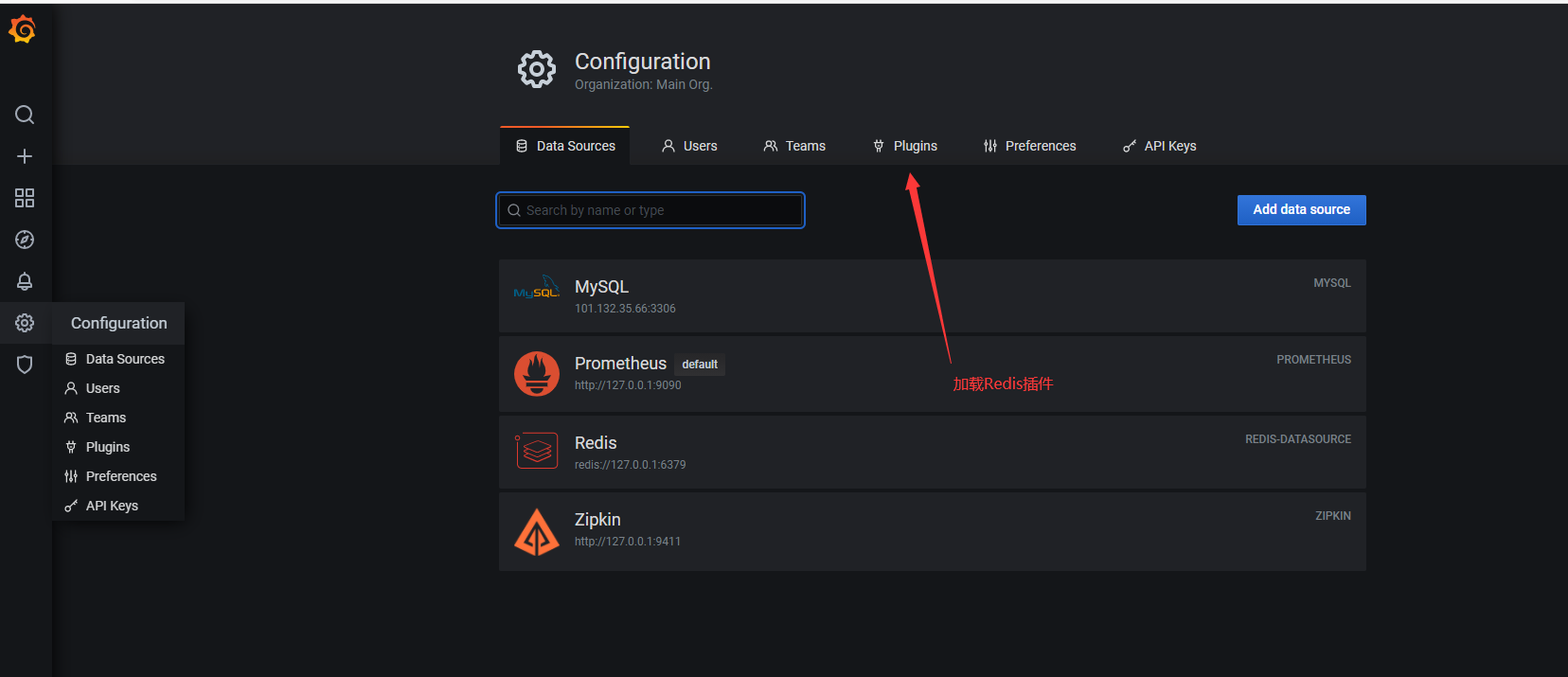
没有搜索到服务器执行
grafana-cli plugins install redis-datasource
配置数据源地址有密码就填写密码
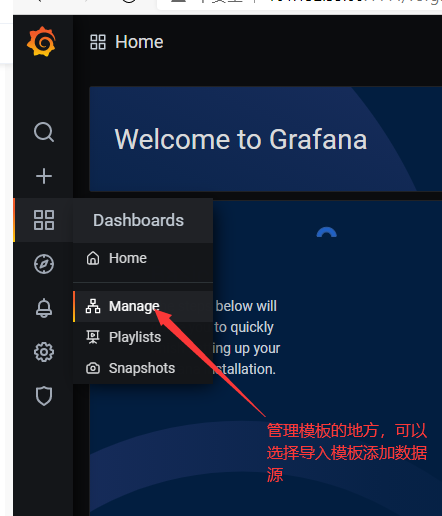
选择第二个
或者12766导入模板
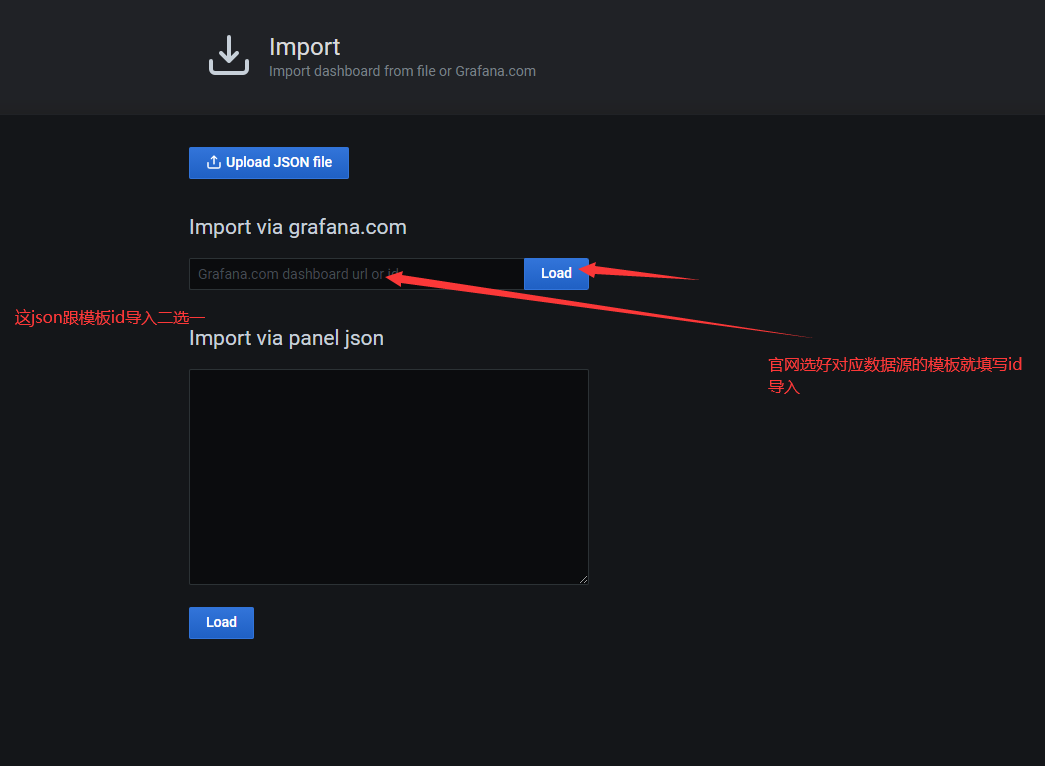
Grafana配置Prometheus

若有收获,就点个赞吧
0 人点赞
