TSN可以看做是双流(two stream)系列的改进。
two stream表示两个并行的网络:spatial stream convnet 和 temporal stream convnet
spatial stream convnet 是从单帧中分类动作
temporal stream convnet 是从光流(optical flow)中提取动态特征
在这一点上,输入optical flow的效果要远远优于raw stacked frame
如图(c)所示表示一个optical flow(也许是一个displacement vector?)
每个optical flow 包含若干个channel的displacement vector(dt),通过第t帧与t+1帧图像对比得到,包括水平分量dtx和竖直分量dty,如下图中(d)与(e)所示。
因此一个L帧的视频会产生一个带有L个dt的optical flow(事实上好像是L-1个dt?),每个dt带有两个分量,即是说每个L帧的视频会产生一个带有2L个(事实上好像是2L-2个?)channel 的optical flow。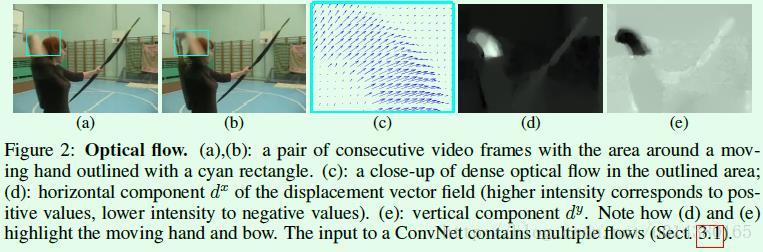
如果视频的宽w高h,那么总的来说,一个optical flow的size为 w×h×2L(个人觉得有可能是2L-2)
这个size即是temporal stream convnet的输入size
总的来看,temporal stream convnet 的输入的获取有两种方式
- optical flow stacking (光流堆积?)
trajectory stacking(轨道堆积?)
optical flow stacking 暂译为光流堆积
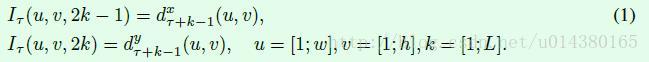
也就是说,对于Iτ而言,第u, v, 2k-1(k∈[1, L])个表示在 u, v 这一点横向 dtx,第u, v, 2k(k∈[1, L])表示在u, v这一点的竖直dty。
τ 似乎是一个开始的标记,标志第一个图片的编号索引,lτ 代表从 τ 开始,长度为L的视频的光流堆积。
- trajectory stacking 暂译为轨道堆积

pk 是 pk-1 加上 dk-1 位移后的得到坐标,基于此新坐标求取新坐标点的dt(直至超出界限?)如此说来即为数个displacement vector 前后相继联结而成。
如下图所示,其中左边为optical flow stacking,右边为trajectory stacking 等的图示。
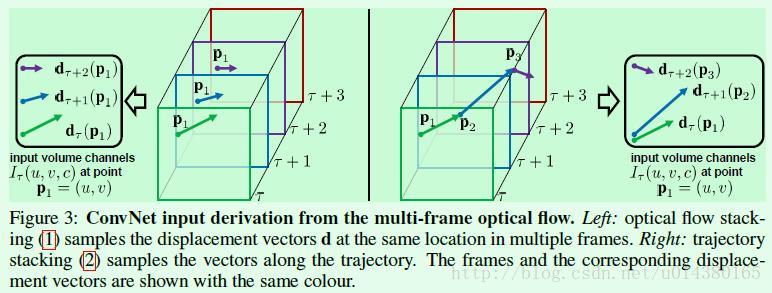
引用自:https://blog.csdn.net/u014380165/article/details/78756459
spatial stream convnet因为输入是静态的图像,因此其预训练模型容易得到(一般采用在ImageNet数据集上的预训练模型)。
temporal stream convnet的预训练模型就需要在视频数据集上训练得到,但是目前能用的视频数据集规模还比较小(主要指的是UCF-101和HMDB-51这两个数据集,训练集数量分别是9.5K和3.7K个video)。
因此作者采用multi-task的方式来解决。怎么做呢?首先原来的网络(temporal stream convnet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算HDMB-51数据集的分类输出,另一个用来计算UCF-101数据集的分类输出,这就是两个task。这两条支路有各自的loss,最后回传loss的时候采用的是两条支路loss的和。**(这段是什么意思?)**
optical flow stacking的效果在作者所述的文章中比trajectory stacking要好一些。

若有收获,就点个赞吧
0 人点赞
