https://blog.csdn.net/u014380165/article/details/79029309
TSN算法笔记
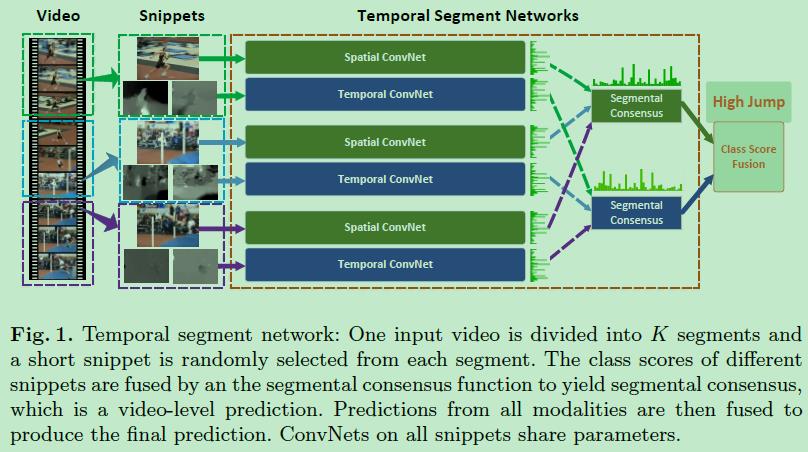
TSN总体来看,属于双流结构网络的一种拓展,主要解决双流结构网络对于长时间视频的行为判断问题和数据量较少的问题。
如下图所示,为作者的主要输入特征,如(原图、临帧差值、视觉光流场、反常光流场(此处可能有误))
直接引用自原博客:
网络部分是由双路CNN组成的,分别是spatial stream ConvNets和temporal stream ConvNets,这和双流网络文章中介绍的结构类似,在文中这两个网络用的都是BN-Inception(双流论文中采用的是较浅的网络:ClarifaiNet)
和双流网络一致,spatial stream ConvNets以单帧图像(原图)作为输入,而temporal stream ConvNets以一系列光流作为输入。从视频中稀疏采用得到多个片段在经过的spatial stream convnet和temporal convnet之后,通过每个片段对于动作分类的打分,综合考虑(文中Segmental Consensus用到的融合函数是均值函数)。
在输入softmax之前会将两条网络的结果进行合并,默认采用加权求均值的方式进行合并,文中用的权重比例是spatial:temporal=1:1.5。此外,图中的K个spatial convnet的参数是共享的,K个temporal convnet的参数也是共享的,实际用代码实现时只是不同的输入过同一个网络。
其损失函数如下所示。
也就是说G是一个长度为C的向量,表示一个video属于每个类别的得分。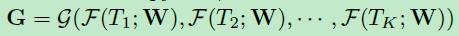
前面提到过为了防止过拟合,作者采取了多个措施,其中一个就是交叉预训练,预训练我们都很熟悉,以图像为输入的spatial ConvNets网络可以用在imagenet数据集上预训练的网络来初始化。而以光流作为输入的temporal stream ConvNets网络该怎么初始化呢?答案就是交叉预训练,交叉预训练其实是将图像领域的预训练模型迁移到光流领域。 另外一个是partial BN,冻结了除第一个BN层以外的所有BN层的均值和方差。
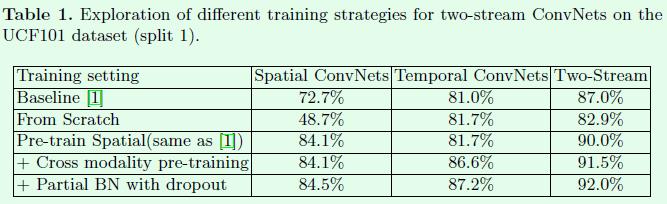
下表是关于不同训练策略下双流网络的效果对比。From Scratch 意为从零开始,从头起步。Cross modality pre-training 意为交叉预训练。Partial BN with dropout 中的 dropout 好像是随机失活,是通过每次训练时,随机使一半(或其它固定比例)的神经元停止工作来防止过拟合的,从理解上来看这使得权重训练的较为均匀。
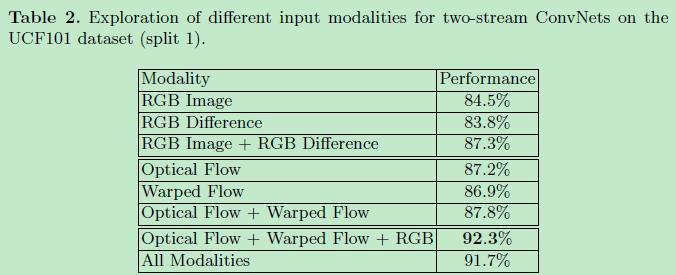
下表是关于网络的几种不同输入形式下two stream convnets的效果对比,数据集是UCF101。可以看到一般而言融合多种类型的输入可以达到更好的效果,尤其要利用光流信息。
下表是关于前面TSN公式中的不同g函数对实验结果的影响。最后文章采用的是average的融合方式。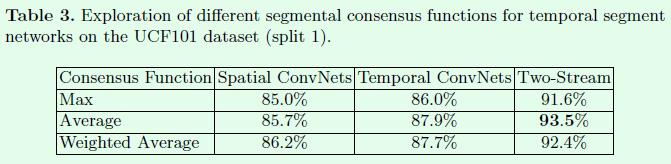
下表是总结本文的一些基于双流网络的改进效果。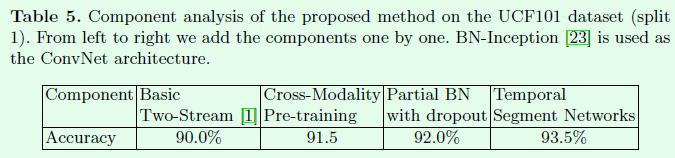
最后的图是作者对网络的可视化,个人感觉做的很不错。将两条网络,以及是否预训练的差异表达出来了。预训练后的网络显然可以提取到有效的特征信息。

若有收获,就点个赞吧
0 人点赞
