什么是堆
(二叉)堆是一个数组,他可以被看成一个近似的完全二叉树,树上的每个节点对应数组中的一个元素,除了最底层外,该树是完全充满的而且是从左向右填充。
表示堆的数组A包括两个属性:A.length 给出数组元素的个数。A.heapSize 表示有多少个堆元素存储在该数组中,也就是说,虽然A[0…,A.legnth]可能都存有数据,但只有A[0…A.heapSize]中存放的是堆的有效元素,这里 0<=A.heapSize<=A.length。该树的根节点是A[0]。 这样给定一个结点的下标i,我们很容易计算得到它的父节点,左孩子和右孩子的下标:
#define parent(i) abs(i - 1) / 2 //父节点#define left(i) 2 * i + 1 //左孩子#define right(i) 2 * i + 2 //右孩子
为什么多+1或者-1,是 因为我们的根节点是放在0位置上,不是1位置 在算法导论和 数据结构和算法c 中是从1开始

二叉堆可以分为两种形式:最大堆和最小堆。
最大堆:
除了根节点之外所有的节点i都要满足:A[parent(i)]>=A[i] 。也就是说某个节点的值至多和其父节点一样大,堆内最大的元素存放在根节点中
最小堆:
和最大堆相反,除了根节点之外所有的节点i都要满足:A[parent(i)]<=A[i] 堆内最小的元素存放在根节点中
在堆排序算法中使用 最大堆,最小堆通常用于优先队列
struct Heap;typedef struct Heap *heap;struct Heap{unsigned int capacity;unsigned int size;/* data */int *arr;};
堆的基本操作
插入
为将一个元素X插入到堆中,我们在下一个空闲的位置创建一个空穴,否则该堆将不是完全树。如果X可以放在该空穴而不破坏堆的序,那么插入完成。否则我们把空穴的父节点上的元素移入该穴中,这样朝着根的方向上行一步。继续该过程直到X能被放入到该穴中为止。如下图所示:
这种一般的策略叫做上滤(percolate up);新元素在堆中上滤到正确的位置
void insert(int data, heap h){int i;if (isFull(h)){printf("heap is full \n");return;}for (i = h->size++; i > 0 && h->arr[parent(i)] < data; i = parent(i)){h->arr[i] = h->arr[parent(i)];}h->arr[i] = data;}
删除
删除有两种,一种是删除最大元素,或者删除最小元素
删除最小元:
当删除一个最小元时,在根节点产生了一个空穴,由于堆中少了一个元素,因此堆中最后一个元素x就必须移动到该堆的某个地方,如果X可以被放到空穴中,那么删除完成。不过一般不可能,我们需要将空穴的两个儿子中较小者移入空穴,这样就把空穴向下推了一层,然后重复这个步骤直到X可以被放入空穴中,如下图: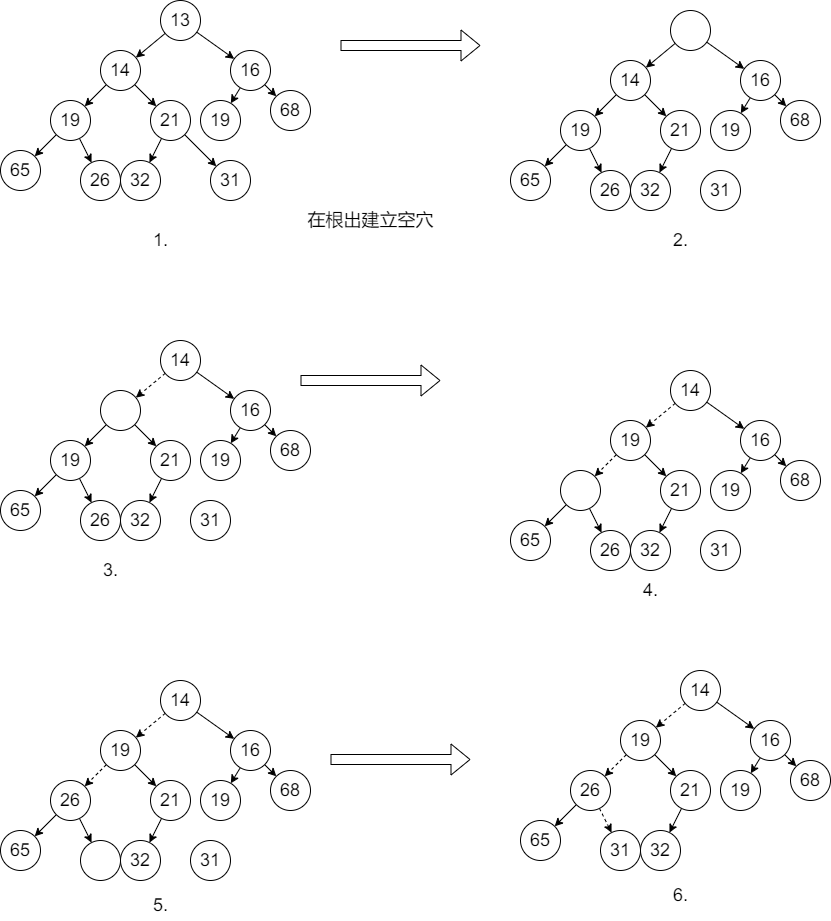
这中一般的策略叫做下滤(percolate down).
// 删除最大值void deleteMax(heap h){int i, child;if (isEmpty(h)){printf("heap is empty \n");return;}int max = h->arr[0];int last = h->arr[h->size - 1];h->size--;for (i = 0; left(i) < h->size; i = child){child = left(i); // 指向 左孩子if (child != h->size && h->arr[child + 1] > h->arr[child]) // 如果右孩子大于左孩子,则指向右孩子{child++;}if (last < h->arr[child]){h->arr[i] = h->arr[child];}else{break;}}h->arr[i] = last;};
构建堆
一般是将n个关键值一人一个顺序放入树中,保持结构特性。
// 创建堆void build_max_heap(int arr[], int size) //size 堆的大小{for (int i = size / 2; i >= 0; i--){/* code */perDown(arr, size, i);}};// 如果 子节点中有一个节点值大于当前值 就交换 并用子节点位置开启下一次递归void perDown(int *arr, int size, int i){int leftIndex = left(i);int rightIndex = right(i);int largest = i;if (leftIndex < size && arr[leftIndex] > arr[largest]){largest = leftIndex;}if (rightIndex < size && arr[rightIndex] > arr[largest]){largest = rightIndex;}if (i != largest){swap(&arr[i], &arr[largest]);perDown(arr, size, largest);}};
堆排序
堆排序算法先利用build_max_heap 构建最大堆。因为数组中最大元素在下标为0的地方,通过将根节点和最后一个节点进行互换,这个时候如果我们去掉堆中的最后一个节点(通过减少堆的大小实现)。剩余节点中,原来根节点的孩子节点仍是最大堆,而新的根节点可能违背最大堆的性质,我们为了维护最大堆的性质,就要调用perDown构建新的最大堆。堆排序算法就是重复这个过程,直到堆的大小为1。
// 堆排序void heapSort(int arr[], int size){build_max_heap(arr, size);for (int i = size - 1; i > 0; i--){/* code */swap(&arr[0], &arr[i]);perDown(arr, i, 0);}};

若有收获,就点个赞吧
0 人点赞
