skiplists.pdf
跳表是一种概率数据结构。它允许在有n个元素的有序序列中拥有以O(logn)的搜索复杂度和O(logn)的插入复杂度。跳表拥有和红黑树和avl树近似的效率,但跳表简单和更少的空间占用
Skip lists are a probabilistic data structure that seem likely to supplant balanced trees as the implementation method of choice for many applications. Skip list algorithms have the same asymptotic expected time bounds as balanced trees and are simpler, faster and use less space. — William Pugh, Concurrent Maintenance of Skip Lists (1989)
跳表的本质是对链表的扩展,普通链表的节点只有一个下一个节点的引用,而跳表有多个下一个节点的引用
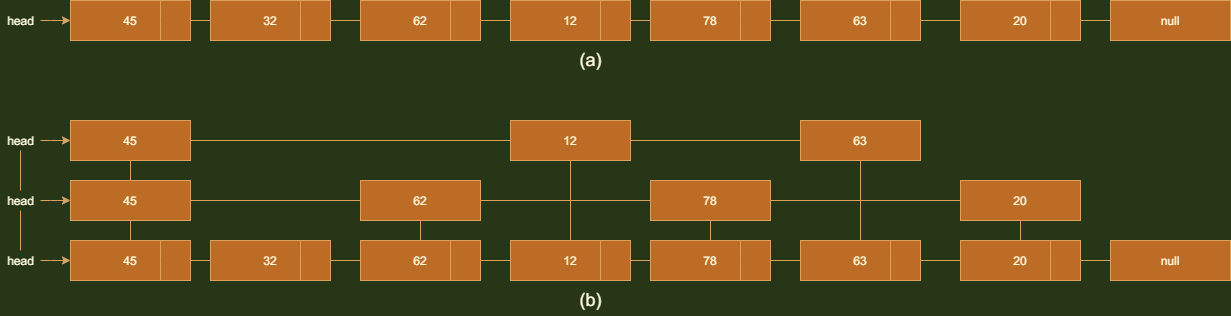
比如,我要找63 在普通链表中需要查找6次,而跳表需要3次。
/*** 跳表**/#ifndef SKIP_LIST_H#define SKIP_LIST_H#include <stdlib.h>#include <stdio.h>struct skip_list_node;struct skip_list;typedef char *dup;typedef struct skip_list_node *snode;typedef struct skip_list *slist;struct skip_list_node{// 动态指针数组用于跳表节点,大小运行时决定snode *forward;// 节点值dup value;unsigned int level;// 节点keyint key;};struct skip_list{snode header;unsigned int level;int size;};// 产生一个新的随机 levelint sk_random_level();// 最大层级const int SKIPLIST_MAX_LEVEL = 32;// 概率 1/4const float SKIPLIST_P = 0.25;snode new_node(int level, const int key, const dup value);slist new_list();// 插入void insert(slist list, const int key, const dup value);// 搜索dup search(slist list, const int key);// 删除int delete (slist list, const int key);void sk_dump(slist list);// 产生一个新的随机 level 来自redis 实现int sk_random_level(){int level = 1;while (((random() & 0xFFFF) < (SKIPLIST_P * 0xFFFF)) && level < SKIPLIST_MAX_LEVEL){level += 1;}return level;};snode new_node(int level, const int key, const dup value){snode node = (snode)malloc(sizeof(struct skip_list_node));node->forward = (snode *)malloc(sizeof(snode) * (level + 1));node->value = value;node->key = key;node->level = level;return node;};slist new_list(){slist list = (slist)malloc(sizeof(struct skip_list));list->level = 1;list->size = 0;list->header = new_node(SKIPLIST_MAX_LEVEL, 0, NULL);for (size_t i = 0; i <= SKIPLIST_MAX_LEVEL; i++){list->header->forward[i] = NULL;}return list;};// 插入void insert(slist list, const int key, const dup value){snode update[SKIPLIST_MAX_LEVEL + 1];snode x = list->header;int i;for (i = list->level; i > 0; i--){while (x->forward[i] && x->forward[i]->key < key){x = x->forward[i];}update[i] = x;}x = x->forward[1];if (x && x->key == key){x->value = value;}else{int level = sk_random_level();if (level > list->level){for (int i = list->level + 1; i <= level; i++){update[i] = list->header;}list->level = level;}x = new_node(level, key, value);for (i = 1; i <= level; i++){x->forward[i] = update[i]->forward[i];update[i]->forward[i] = x;}list->size += 1;}};// 搜索dup search(slist list, const int key){if (list != NULL){snode x = list->header;for (int i = list->level; i > 0; i--){while (x && x->forward[i] && x->forward[i]->key < key){x = x->forward[i];}}x = x->forward[1];if (x && x->key == key){return x->value;}}return NULL;};// 删除int delete (slist list, const int key){snode update[SKIPLIST_MAX_LEVEL + 1];snode x = list->header;int i;for (i = list->level; i > 0; i--){while (x->forward[i] && x->forward[i]->key < key){x = x->forward[i];}update[i] = x;}x = x->forward[1];// 找到了对应的节点if (x && x->key == key){for (int i = 1; i <= list->level; i++){if (update[i]->forward[i] != x){break;}update[i]->forward[i] = x->forward[i];}free(x);while (list->level > 1 && list->header->forward[list->level] == NULL){list->level -= 1;}return 0;}return 1;};void sk_dump(slist list){if (list != NULL){snode x = list->header;printf("level = %d \n", list->level);printf("size = %d \n", list->size);while (x && x->forward[1] != NULL){x = x->forward[1];printf("key => %d, value => %s forward:", x->key, x->value);printf("[ ");for (int i = x->level; i > 0; i--){if (x->forward[i]){printf("%d ", x->forward[i]->key);}}printf("]\n");}}};#endif //SKIP_LIST_H

若有收获,就点个赞吧
0 人点赞
