1.若干定义
一个图(graph) 是由顶点(vertex)集合
是由顶点(vertex)集合 和边(edge)(通常使用e表示)集合
和边(edge)(通常使用e表示)集合 组成。每一条边就是一个点对
组成。每一条边就是一个点对 ,其中
,其中 。有时也把边称为弧(arc)。顶点的个数称为图的阶(order),通常使用使用n表示,边的个数称为图的边数(size) 通常用m表示。
。有时也把边称为弧(arc)。顶点的个数称为图的阶(order),通常使用使用n表示,边的个数称为图的边数(size) 通常用m表示。
G的顶点集V可能是无限的,顶点集为无限集或有无限条边的图称为无限图。与之相比顶点和边集为有限集的图称为有限图
简单图 :每条边都连接两个不同的顶点且没有两条不同的边连接一对相同顶点的图。
有向边(directed edge): 每条边有一个方向。
有向图(directed graph):带有有向边的图
有向图的基图(ground graph):忽略有向图所有边的方向,得到的无向图称为该有向图的基图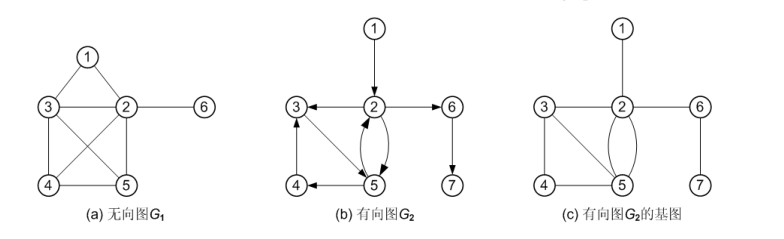
完全图(complete graph): 如果无向图中任何一对顶点之间都有一条边,这种无向图称为完全图
有向完全图(directed complete graph):如果有向图中任何一对顶点u和v,都存在
稀疏图(sparse graph):边或弧的个数相对较少的图称为稀疏图,
相对较少的定义是 远小于n*(n-1)或者 小于nlog(n)
稠密图(dense graph): 边或弧的数目相对较多的图(接近于完全图或者有向完全图)。
在无向图 中,如果(u,v)是E(G)中的元素,即(u,v)是图中的一条无向边,则称顶点u与顶点v互为邻接顶点(adjacent vertex),边(u,v)依附于(attach to)顶点u和v;或称边(u,v)与顶点u和v相关联(incident).
中,如果(u,v)是E(G)中的元素,即(u,v)是图中的一条无向边,则称顶点u与顶点v互为邻接顶点(adjacent vertex),边(u,v)依附于(attach to)顶点u和v;或称边(u,v)与顶点u和v相关联(incident).
邻接边(adjacent edge): 有一个共同顶点的两条不同边。
在有向图 中,如果(u,v)是E(G)中的元素,即(u,v)是图中的一条有向边,则称顶点u邻接到(adjacent to) 顶点v,顶点v邻接自(adjacent from)顶点u。边
中,如果(u,v)是E(G)中的元素,即(u,v)是图中的一条有向边,则称顶点u邻接到(adjacent to) 顶点v,顶点v邻接自(adjacent from)顶点u。边
度数(degree): 一个顶点u的度数是与他相关联的边的数目,记作deg(u);
在有向图中顶点的度数等于该顶点的出度和入度之和, 顶点u的出度(outdegree) 是以u为起始顶点的有向边(即从顶点u出发的有向边)的数目,记作od(u), 顶点u的入度(indegree) 是以u为终点的有向边(即进入到顶点u的有向边)的数目,记作id(u), 顶点u的度数 : deg(u) = od(u)+id(u)
定理 在有向图和无向图中 所有顶点度数的总和等于边数的两倍
偶点和奇点:度数为偶数的顶点称为偶点(even vertex) 度数为奇数的顶点称为奇点(odd vertex) 推论:每个图都有偶数个奇点
路径(path):路径是两个节点之间的边序列
有向图中的路径必须考虑边的方向,称之为有向路径。路径的长度是路径所包含的边数。如果路径经过的顶点不重复,称为简单路径
路径的的长度:路径中边的数目
回路:开始顶点和结束顶点均为同一顶点的路径。
简单回路 : 除了第一个和最后一个顶点外,没有顶点重复的回路
连通性
在无向图中,若顶点u到顶点v有路径,则称顶点u和顶点v是连通的。如果无向图中任意一对顶点都是连通的,则称此图是连通图(connected graph); 相反如果一个无向图不是连通图,则称为非连通图(disconnected graph)
如果一个无向图不是连通的,则其极大连通子图称为连通分量(connected component);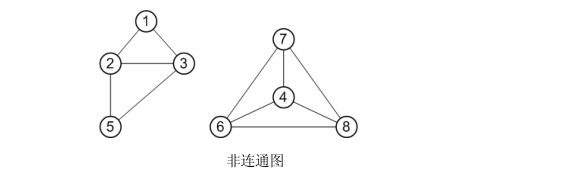
在有向图中。若每一对顶点u和v,既存在从u到v的路径,也存在从v到u的路径,则成为强连通图。
权值(weight):某些图的边具有与它相关的数,称为权值,这些权值可以表示一个顶点到另一顶点的距离,花费的代价,所需时间等。
加权图(weighted graph):如果一个图中的所有边都具有权值,则称其为加权图或者网络(net)
根据网络中的边是否具有方向性,又可以分为有向网和无向网
2.图的存储表示
2.1 邻接矩阵
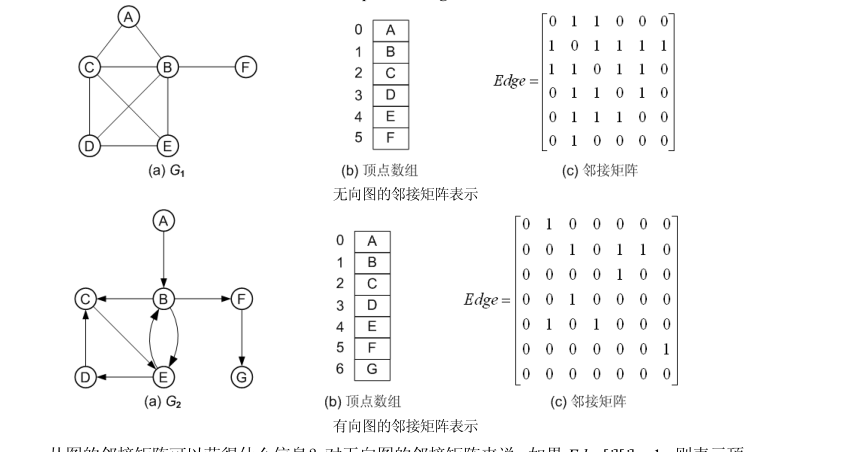
1.有向图和无向图的邻接矩阵
在邻接矩阵的存储方法中,除了提个记录各个顶点信息的顶点数组外,还有一个表示各个顶点之间关系的矩阵,称为邻接矩阵(adjacency matrix) ,设 是一个具有n个顶点的图,则图的邻接矩阵是一个n*n的二维数组,记作A = [
是一个具有n个顶点的图,则图的邻接矩阵是一个n*n的二维数组,记作A = [ ],则它的定义为:
],则它的定义为:
2.2 邻接表
对于G=(V,E)来说,其邻接表表示由一个包含|V|条链表的数组adj所构成,每个结点有一条链表,对于每个结点 ,邻接链表adj[u]包含所有与结点u之间有边相连的结点v
,邻接链表adj[u]包含所有与结点u之间有边相连的结点v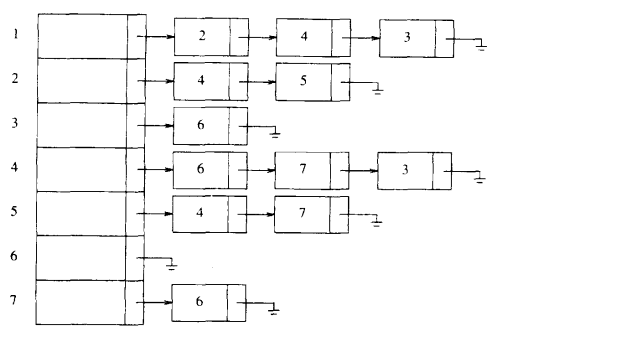
在大部分实际应用中顶点都有名字而不是数字,所以必须提供从名字到数字的映射,完成这个工作做容易的方法是使用散列表
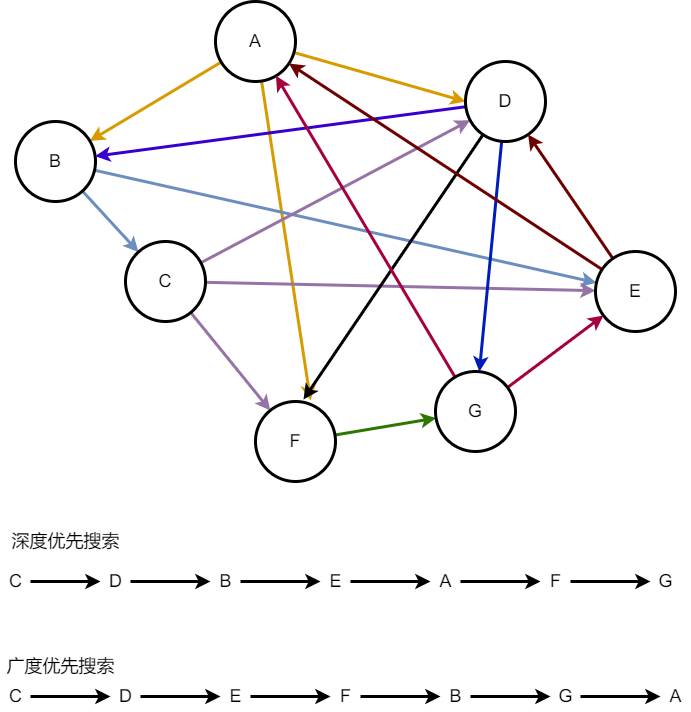
深度优先搜索
深度优先搜索的特点是:在第一次碰到一个顶点时立即处理这个顶点并访问这个顶点的所有还没有被访问的邻接顶点
typedef struct adjacency_matrix *graph;struct adjacency_matrix{// 存储数据的矩阵指针int **matrixs;// 矩阵的大小int size;};// 深度优先搜索 辅助函数void dfs_internal(const graph g, int vertex, int *visited){if (visited[vertex - 1])return;visited[vertex - 1] = 1;printf("-----vertex = %d \n", vertex);for (int i = 0; i < g->size; i++){if (!visited[i] && isEdge(g, vertex - 1, i)){dfs_internal(g, i + 1, visited);}}};// 深度优先搜索void dfs(const graph g, int vertex){int *visited = (int *)malloc(sizeof(int) * g->size);memset(visited, 0, sizeof(int) * g->size);dfs_internal(g, vertex, visited);free(visited);};
广度优先搜索
广度优先搜索就是访问给定的顶点v的所有邻接顶点,接着访问与v的邻接顶点所有邻接的顶点(跳过那些已经访问过的顶点)
// 广度优先搜索void bfs(const graph g, int vertex){if (g != NULL){int *visited = (int *)malloc(sizeof(int) * g->size);memset(visited, 0, sizeof(int) * g->size);queue q = queue_new();enqueue(q, intdup(vertex));while (!isEmpty(q)){int *v = (int *)dequeue(q);int row = *v - 1;if (!visited[row]){visited[row] = 1;printf("-----vertex = %d \n", *v);for (int i = 0; i < g->size; i++){if (!visited[i] && isEdge(g, row, i)){enqueue(q, intdup(i + 1));}}}free(v);}queue_free(q);q = NULL;free(visited);}};

若有收获,就点个赞吧
0 人点赞
