1.概述
索引可以理解为一个利于遍历搜索,独立于存储数据的一种数据结构,通常通过数据中的某一列来进行映射。索引的最终目的就是为了提高查询效率,是一种以空间换时间的解决思路。
在mysql中,索引的数据结构为B+树,而在mongo中,索引的数据结构为B-树
2.B-树
B-树又称为B树。与B+树不同,B树每个节点中都存储数据,B树的数据结构如下图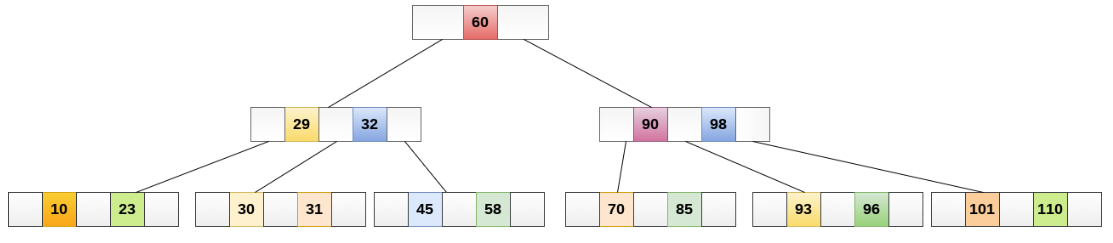
B树具有以下特点
- 一个节点可以存储N个数据,那么节点具有N+1个子树
- 每层数据都是从左至右逐步递增
- 该节点的左子树,数据都小于该节点,右子树都大于该节点,中间子树介于节点值之间
- B树中每个节点即存储索引也存储数据
那么为什么Mongo选择B树作为索引,而不是B+树?
B+树因为只有叶子节点存储数据,因此当需要查询的数据处于较深的层级时,需要多次的磁盘IO。但是因为B+树的叶子节点之间通过单向指针链接成了一个链表,因此B+树对于范围查询的支持更好,并且相对来说更加节省存储空间。
B树相比较B+树来说,对于范围查询效率不如B+树,但是对于等值或者说非跨节点的范围查询,因为索引和数据存在一起,因此磁盘IO的次数要少很多,效率要优于B+树。在极端情况下,时间复杂度=O1
再说回数据库层面,mongo本身是一个非关系型数据库,通常来说如果使用嵌入式数据模型存储,那么相对来说单次查询的比率要多于范围查询,因此选择B树作为索引的数据结构。而Mysql作为一个关系型数据库,范围查询的比率相对来说要多于单次查询,因此选择B+树作为索引的数据结构
3.索引
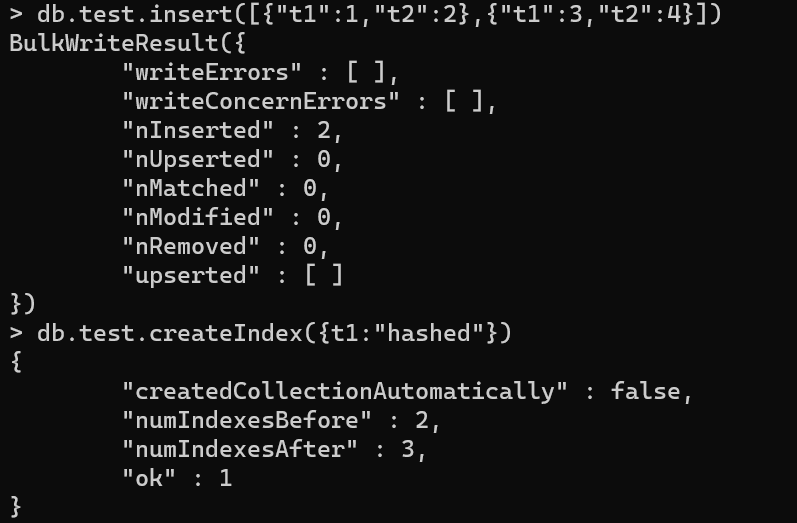
MongoDB 中索引的类型大致包含单键索引、复合索引、多键值索引、地理索引、全文索引、 散列索引等,下面简单介绍各类索引的用法。
查看索引
- 查看一个集合中的全部索引:db.${collectionName}.getIndexes()
查看一个集合中的索引大小:db.${collectionName}.totalIndexSize()。如果索引使用了前缀压缩,那么得到的是压缩后的大小
删除索引
db.${collectionName}.dropIndex(${IndexName})
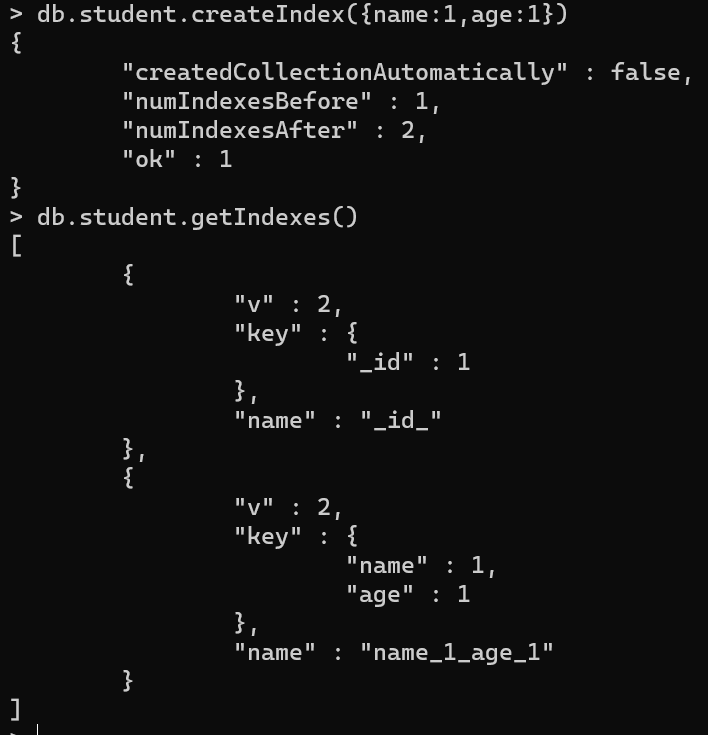
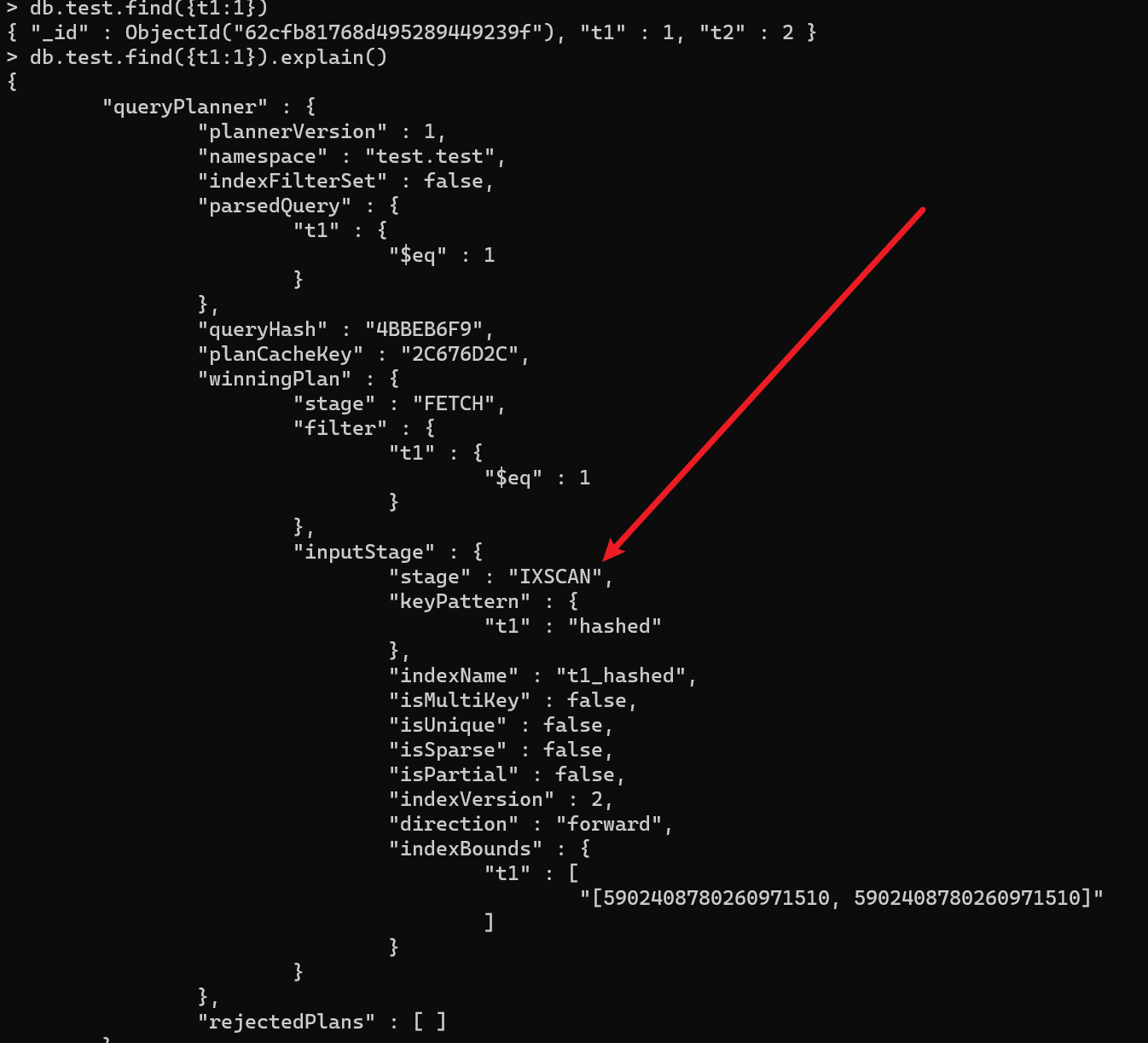
单键索引
概念
与mysql类似,就是在单一的数据列上建立索引,在mongo中可以理解为在单一键值上创建索引。在默认情况下,所有集合在 _id 字段上都有一个索引
注意点
在创建单建索引时可以指定升序或降序。但是对于单字段索引和排序操作,索引键的排序顺序(即升序或降序)无关紧要,因此在使用sort()进行排序时,对于单列索引,无论正序还是倒序都会使用索引
语句
db.collection.createlndex ( { key: 1 } ) //1 为升序,-1 为降序
验证
复合索引
概念
与mysql一致,mongo同样支持在多个键值上创建索引,并且mongo中的复合索引同样遵循最左原则。并且复合索引在使用过程中,不同于单列索引,索引的顺序也会影响到具体索引的使用。
注意点
复合索引最多只能包含31个字段
索引的顺序主要的影响出现在使用sort()方法时,复合索引的排序使用遵循以下的示例顺序
假设当前在键值 k1,k2上创建了符合索引,其中k1在前,k2在后.。两个键值都升序排列。那么索引的数据结构应该是这样的。只有k1有序时,k2才有序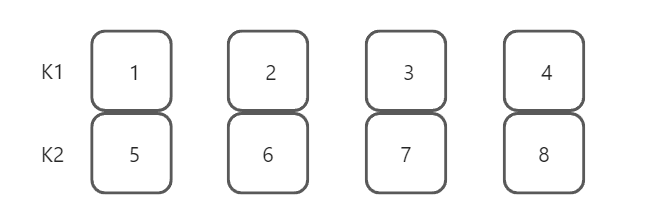
因此在使用sort()时,具有以下观点k1在前,k2在前,且都为升序的情况下,索引生效
- k1在前,k2在前,且都为降序的情况下,索引生效
- k1在前,k2在前,顺序相反的情况下,索引不生效
-
语句
db.collection.createlndex ( { key1: 1,key2:1,…… } ) //1 为升序,-1 为降序
验证
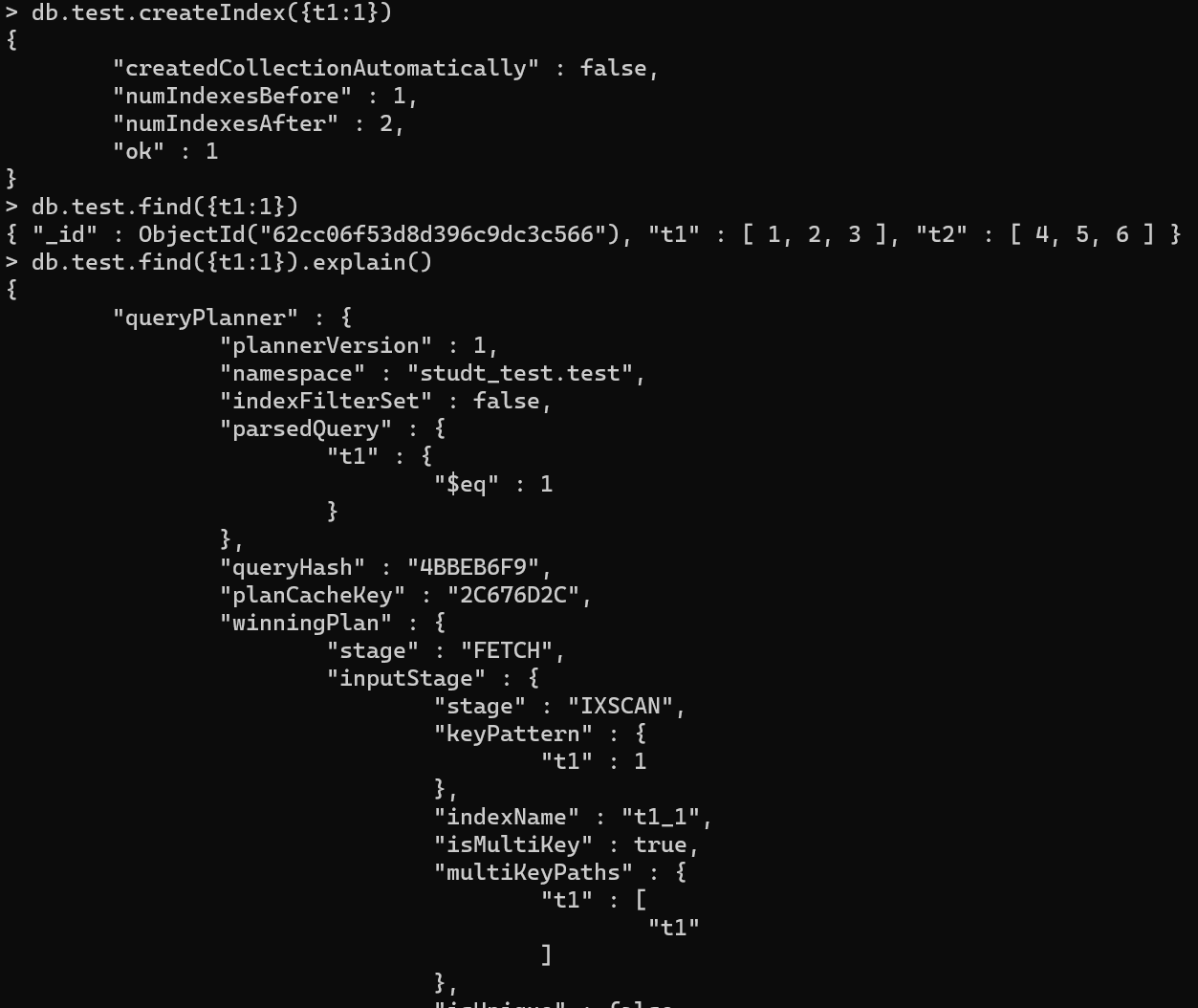
多键值索引
概念
在mongo中,因为文档的数据持久化形式为BSON,因此存在值数据类型为数组的键,在这些键上建立的索引,成为多键值索引
注意点
需要注意的是,如果一个复合索引中包含多个数组键,那么索引会创建失败,如下图:

且经过测试,多键值索引只对当前层级数组有效,对递归层级无效语句
db.collection.createlndex ( { key: 1 } ) //1 为升序,-1 为降序
验证
地理位置索引(2d)
概念
mongo中,地址位置索引可以直接用于位置距离计算和查询。查询结果默认将会由近到远排序,且查询结果也包含目标点对象、距离目标点的距离等信息。
通常用于获取一个地址指定距离内的目标地址,或者计算点对点之间的距离
使用2d index 能够将数据作为2维平面上的点存储起来, 在MongoDB 2.2以前 推荐使用2d index索引。注意点
语句
create.${collectionName}.createIndexes(${fieldName}:”2d”)
验证
存储测试数据
db.dc2.insert({name:"北京",loc:[39.26,115.25]})db.dc2.insert({name:"大同",loc:[112.34,39.03]})db.dc2.insert({name:"太原",loc:[111.3,37.27]})db.dc2.insert({name:"湖南",loc:[24.38,108.47]})
建立2d地理位置索引

db.dc2.createIndex({loc:”2d”})
- 给定经纬度范围查询
db.dc2.find({loc:{$near:[115.24,29.26]}})
如图,检索出了北京以及湖南两个坐标点
同时我们可以使用$maxDistance限制最大距离进行查询。$maxDistance单位为度半径
db.dc2.find({loc:{$near:[39.26,115,24],$maxDistance:1}})
:::info
当索引形式为2d时,$maxDistance的单位为1度,1度约等于111km
当索引形式为2dsphere,$maxDistance的单位为1m
:::
如图我们指定了查询最远距离为1弧度,最终只得到了一个坐标点
地理位置索引(2dSphere)
概念
mongo除了支持2d平面的地理索引,同样支持立体球面的地理索引。
2dsphere index 支持球体的查询和计算,同时它支持数据存储为GeoJSON 和传统坐标。3.0版本以上推荐使用此索引
注意点
建立2dsphere索引的键值对存储格式存在两种:[经度,纬度]或GeoJson格式
GeoJson格式说明点击这里
一般来说我们需要存储用户坐标点的信息,坐标点的信息的格式为
{"type":"Point","coordinates":[100,0]}
其中,GeoJson使用的是wgs84的坐标规范。
推荐一个好玩的项目:点击这里(可以将wgs84坐标转换为百度、高德等坐标规范)
语句
create.${collectionName}.createIndexes(${fieldName}:”2dsphere”)
常规查询
使用$nearSphere进行查询
查询条件示例
{"location":{"$nearSphere":{"$geometry":{"type":"Point","coordinates":[118.783799,31.979234]}}}}
同样,我们也可以指定最远距离进行查询
{"location":{"$nearSphere":{"$geometry":{"type":"Point","coordinates":[118.783799,31.979234]},"$maxDistance":3000}}}
聚合查询
按照离我最近排序,除了使用 $nearSphere 查询外,我们还可以使用 aggregate 来实现。
使用 aggregate 有两个好处。
- 我们在进行排序的后,可以返回两点之间的距离。
- 我们可以进行更为复杂的排序,例如我们可以先根据某个字段进行排序,然后该字段相同的情况下再根据距离排序。
使用 aggregate 查询时,我们还可以返回两点之间的距离,其中 distanceField 可以对距离字段进行重命名。
查询条件示例:具体$geoNear可选参数参考这里
{"$geoNear":{"near":{"type":"Point","coordinates":[118.783799,31.979234]},"distanceField":"distance","spherical":true,"maxDistance":15000,"query":{"address":{"$regex":"安"}}}}
验证
存储测试数据
db.test.insert({"address": "南京 禄口国际机场", "location": {"type": "Point", "coordinates": [118.783799, 31.979234]}})db.test.insert({"address": "南京 浦口公园", "location": {"type": "Point", "coordinates": [118.639523, 32.070078]}})db.test.insert({"address": "南京 火车站", "location": {"type": "Point", "coordinates": [118.803032, 32.09248]}})db.test.insert({"address": "南京 新街口", "location": {"type": "Point", "coordinates": [118.790611, 32.047616]}})db.test.insert({"address": "南京 张府园", "location": {"type": "Point", "coordinates": [118.790427, 32.03722]}})db.test.insert({"address": "南京 三山街", "location": {"type": "Point", "coordinates": [118.788135, 32.029064]}})db.test.insert({"address": "南京 中华门", "location": {"type": "Point", "coordinates": [118.781161, 32.013023]}})db.test.insert({"address": "南京 安德门", "location": {"type": "Point", "coordinates": [118.768964, 31.99646]}})
创建2dsphere索引
db.test.createIndex({“location”:”2dsphere”})
near方法测试
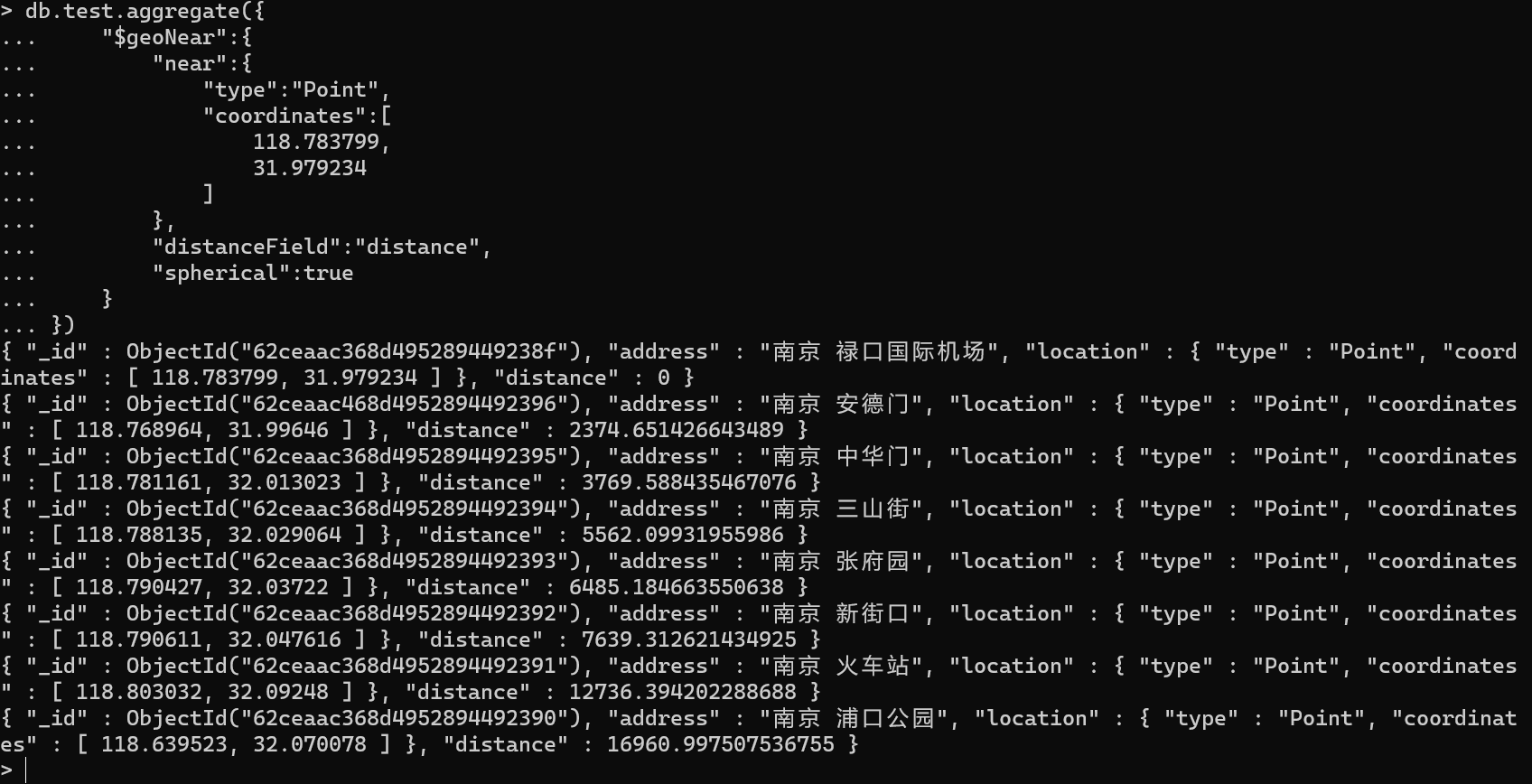
{"$geoNear":{"near":{"type":"Point","coordinates":[118.783799,31.979234]},"distanceField":"distance","spherical":true}}
如图:使用聚合查询可以看到点对点之间的距离信息,单位为米
点距离方法测试
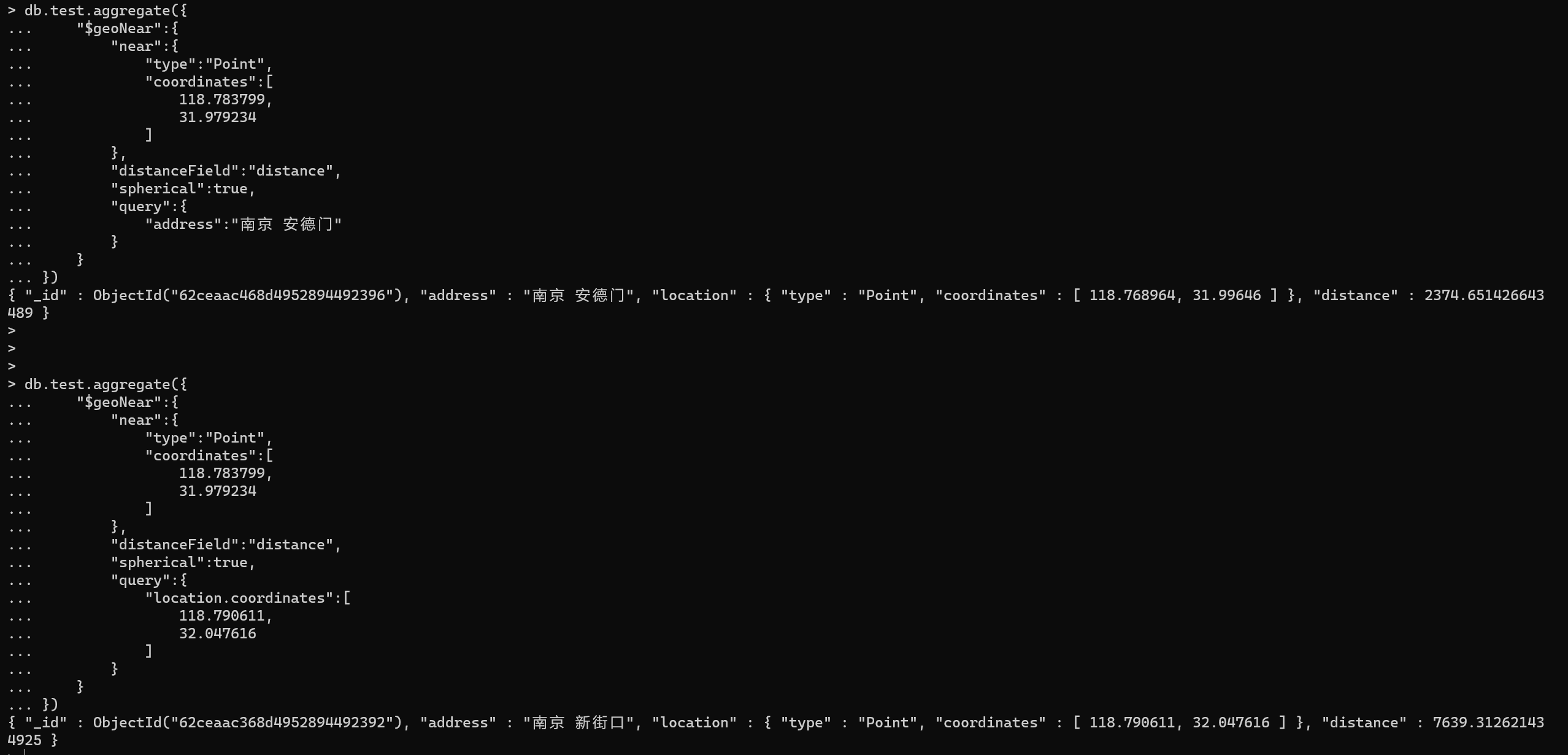
{"$geoNear":{"near":{"type":"Point","coordinates":[118.783799,31.979234]},"distanceField":"distance","spherical":true,"query":{"address":"南京 安德门"}}}
{"$geoNear":{"near":{"type":"Point","coordinates":[118.783799,31.979234]},"distanceField":"distance","spherical":true,"query":{"location.coordinates":[118.790611,32.047616]}}}
如图,可以通过$geoNear的query项进行数据的筛选,从而准确获取点对点之间的距离
地理位置索管道符详解
$geoIntersects
定义:指出与查询位置相交的文档。
- 支持的索引:2dsphere
参数:$geometry (仅支持 2dsphere 索引,指定GeoJSON格式的几何图形)
$geoWithin
定义:指出完全包含在某个区域的文档。
- 支持的索引:2dsphere、2d
- 参数:
- $box(仅支持 2d 索引,查询出矩形范围内的所有文档)
- $center(仅支持 2d 索引,查询出圆形范围内的所有文档)
- $polygon (仅支持 2d 索引,查询出多边形范围内的所有文档)
- $centerSphere(支持 2d 索引和 2dsphere 索引,查询出球面圆形范围内的所有文档)
- $geometry (仅支持 2dsphere 索引,指定GeoJSON格式的几何图形)
$near
- 定义:指出与查询位置从最近到最远的文档。
- 支持的索引:2dsphere、2d
- 参数:
- $maxDistance (支持 2dsphere 索引和 2d 索引,指定查询结果的最大距离)
- $minDistance (仅支持 2dsphere 索引,指定查询结果的最小距离。在4.0后支持 2d 索引)
- $geometry (仅支持 2dsphere 索引,指定GeoJSON格式的点)
备注:$minDistance 官方文档说仅支持 2dsphere 索引,但是实践证明 $minDistance 也支持 2d 索引,这里保留争议。
$nearSphere
定义:使用球面几何计算近球面的距离,指出与查询位置从最近到最远的文档。
- 支持的索引:2dsphere、2d
- 参数:
- $maxDistance (支持 2dsphere 索引和 2d 索引,指定查询结果的最大距离)
- $minDistance (仅支持 2dsphere 索引,指定查询结果的最小距离。在4.0后支持 2d 索引)
- $geometry (仅支持 2dsphere 索引,指定GeoJSON格式的点)
全文索引
概念
从 2.4 版本开始,MongoDB 开始支持全文检索功能,全文检索就是对文本中的每个词建立索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户,整个过程类似于通过字典中的检索字表查字的过程。
目前,MongoDB 支持大约 15 种语言的全文索引,例如 danish、dutch、english、finnish、french、german、hungarian、italian、norwegian、portuguese、romanian、russian、spanish、swedish、turkish 等。原理
通过上述支持语言可以看出,目前mongo全文索引本身并不支持中文查询。其本质是因为mongo的分词机制是依赖于空格进行分词,进而通过倒排索引机制实现的。
倒排索引的原理如下:
因此对于中文来说,只能通过一些分词原则,将理论上的按照单个文字分词修改为按照空格分词
目前有以下中文分词方法可进行操作
- 一元分词法:顾名思义将语句中的每个字都作为一个单词,例如:我喜欢”张钰玲”就会被拆分为”我 喜 欢 张 钰 玲”。这种分词方法优点就是简单,但是缺点也很显而易见,一个汉字对应的文档可能会很多,进而导致当高频汉字对应的文档数量过多时,计算交集的效率过低问题
- 二元分词法:很好理解就是每两个字进行一次分词,例如:”我喜欢张钰玲”就会被拆分为”我喜 喜欢 欢张 张钰 钰玲”。二元分词的情况下,每个单次对应的文档数量会相对应的减少,进而导致计算交集的效率提高。因此二元分词法的查询效率是要高于一元分词法的
- 结巴中文分词:结巴中文分词是最流行的Python中文分词组件,它有一种搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。下面是引用自它项目主页的示例:

综上所述,mongo全文索引本身只支持空格形式的分词查询,因此可以通过各种分词算法,将中文语句分割成符合mongo分词模式的查询机制,进行查询。其实对于分词查询,使用ES是更好的选择
注意点
- 一个集合中,只能存在一个全文索引
-
语句
建立索引:db.${collectionName}.createIndex({${fieldName:”text”}})
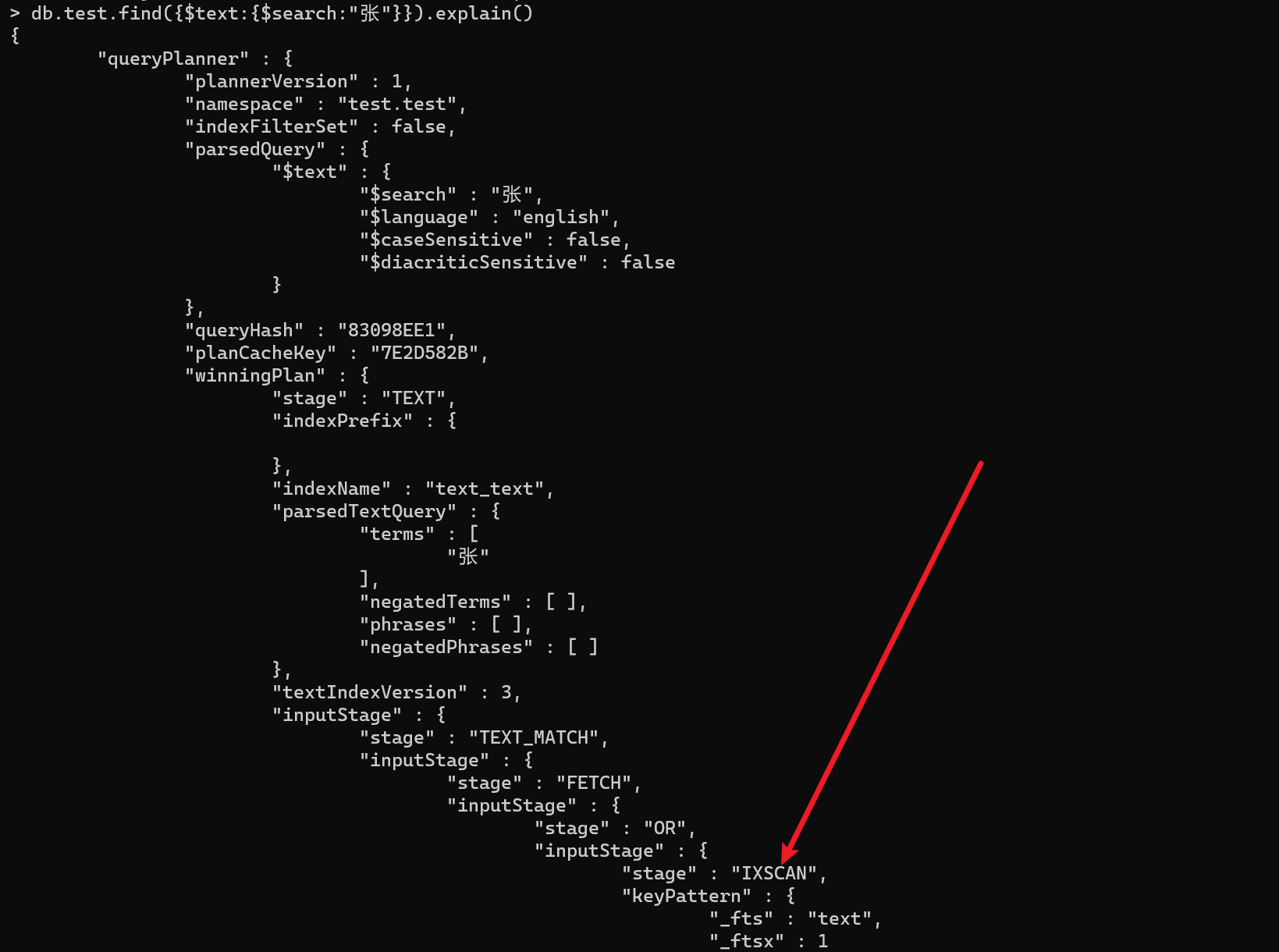
- 查询:db.${collectionName}.find({$text:{$search:”${fieldName}”}}})
聚合查询:db.test.aggregate({$match:{$text:{$search:”张”}}})
验证
存储测试数据
db.test.insert({"text":"我 叫 冯 铁 城"})db.test.insert({"text":"我 叫 张 钰 玲"})
建立全文索引
db.test.createIndex({text:”text”})
- 查询

散列索引
概念
哈希索引使用索引字段值的哈希来维护索引条目。
哈希索引可以用作哈希分片键来对数据进行分片。基于哈希的分片将字段的哈希索引用作分片键,以跨分片群集对数据进行分区。
使用哈希分片键对集合进行分片使数据分布更随机
通常来讲,我们可以在频繁进行等值查询的列上建立hash索引。因为hash索引的形式是天然支持等值查询并且效率也很快
注意
- MongoDB哈希索引在哈希之前将浮点数截断为64位整数。例如,哈希索引将为具有2.3、2.2和2.9的值的字段存储相同的值。为防止冲突,请勿对不能准确地转换为64位整数的浮点数使用哈希索引。
- MongoDB哈希索引不支持大于2^53的浮点值。
- MongoDB 4.2确保PowerPC上浮点值2^63的哈希值与其他平台一致。
- MongoDB不支持对数组列建立hash索引
不能创建具有哈希索引字段的复合索引,也不能在哈希索引上指定唯一约束(unique:true)
语句
create.${collectionName}.createIndex(${fieldName}:”hashed”)
验证
4.索引额外属性
唯一索引
唯一索引的功能和mysql中一样。可以理解为我们在某个单列索引或者复合索引上建立了唯一性,进而实现了集合中文档的唯一性。
具体语句:db.${collectionName}.createIndex({${fieldName}:1/-1},{unique:true})
具体验证过程如图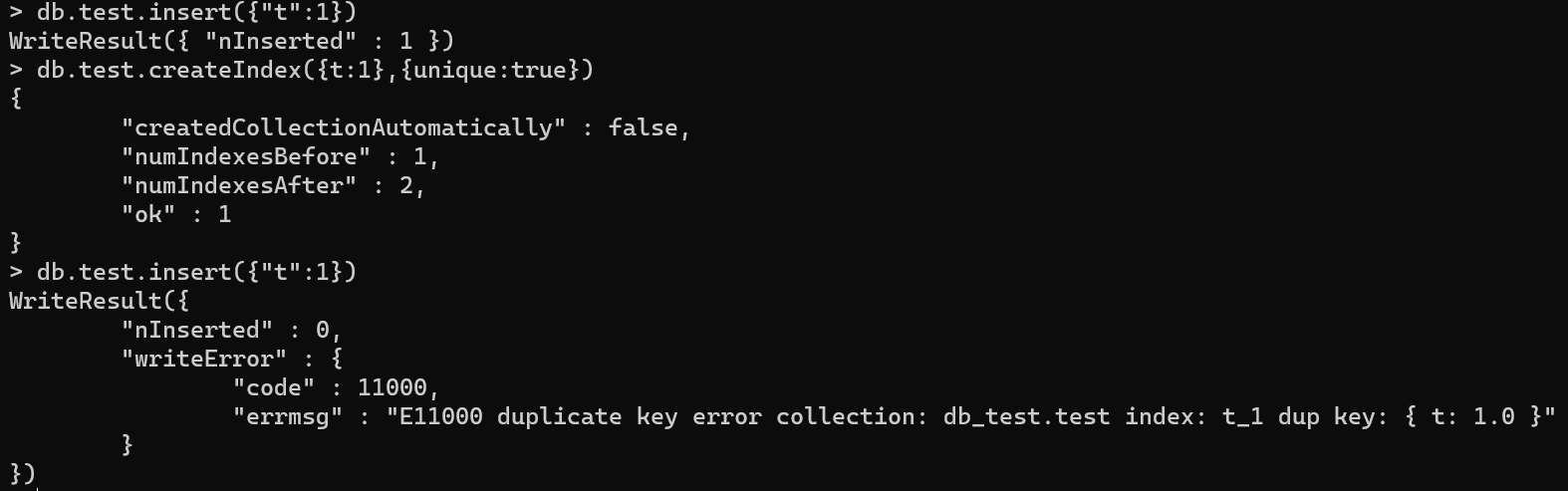
稀疏索引
存在以下场景
集合中存入一个文档,文档中有且只有一个t字段
- 在t字段建立单建索引,并设置了索引唯一性
- 此时存入一个文档,文档中且只有一个m字段
- mongo会默认为该文档创建t字段,并赋值为空
- 此时存入一个文档,文档中且只有一个m字段
- 那么,如果mongo会默认为该文档创建t字段,并赋值为空的话,就会出现t字段重复,重复的字段值为null
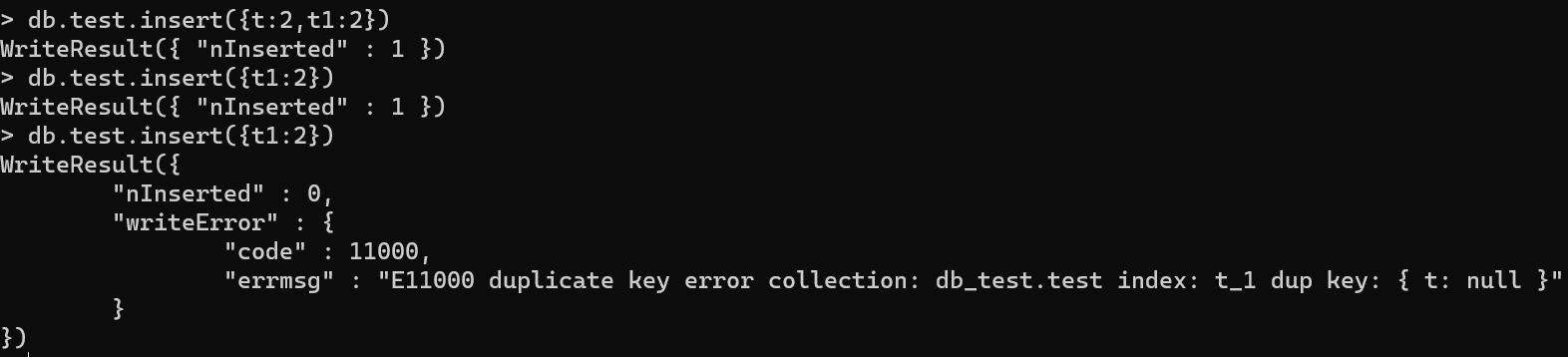
此时就需要引入稀疏索引的概念了
索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目,索引会跳过没有索引字段的文档。
可以将稀疏索引与唯一索引结合使用,以防止插入索引字段值重复的文档,并跳过索引缺少索引字段的文档。
具体语句:db.${collectionName}.createIndex({${fieldName}:1/-1},{unique:true,sparse:true})
具体验证过程如图:可以看到同时稀疏性不会报错了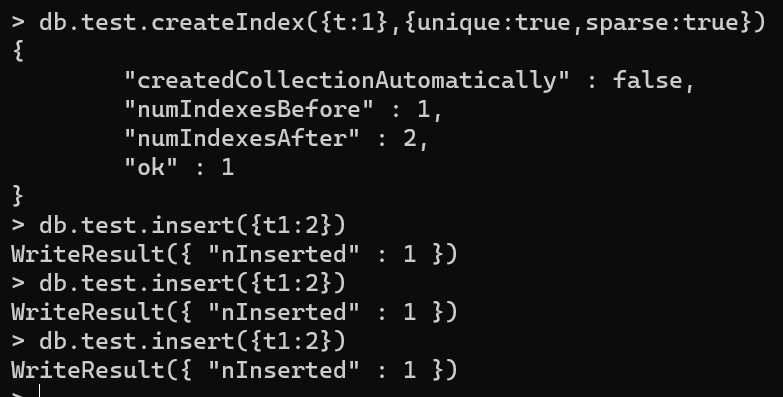
部分索引
在一个集合中,可能只有一部分的文档,适用于建立索引的场景,此时就可以通过部分索引来指定数据子集建立索引
部分索引具有以下特点:
- 部分索引仅对满足指定过滤器表达式的文档进行索引。通过在一个集合中为文档的一个子集建立索引。
- 部分索引具有更低的存储需求和更低的索引创建和维护的性能成本。3.2新版功能。
- 部分索引提供了稀疏索引功能的超集,应该优先于稀疏索引。
具体语句:db.${collectionName}.createIndex({${fieldName}:1/-1},{partialFilterExpression:{具体查询条件})
验证步骤
- 首先存入数据
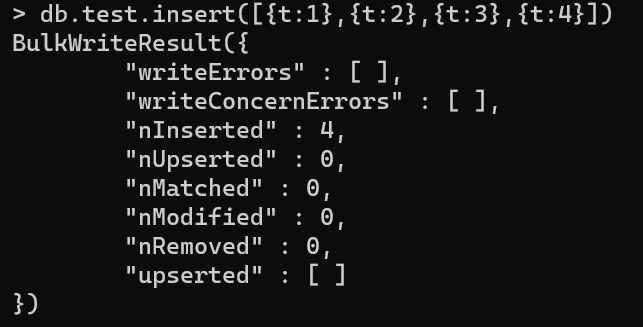
- 然后创建一个单建索引,并设置其部分性(只有t>2的文档,才建立索引)
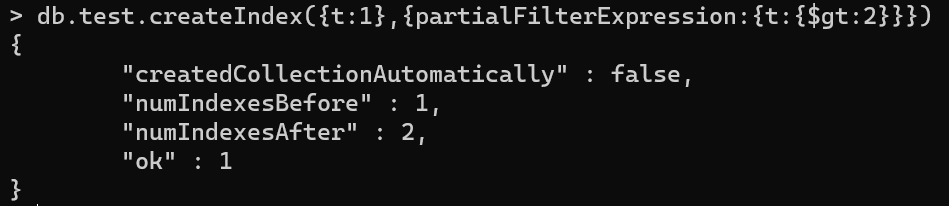
- 对符合条件的数据进行查询,如图,用到了索引
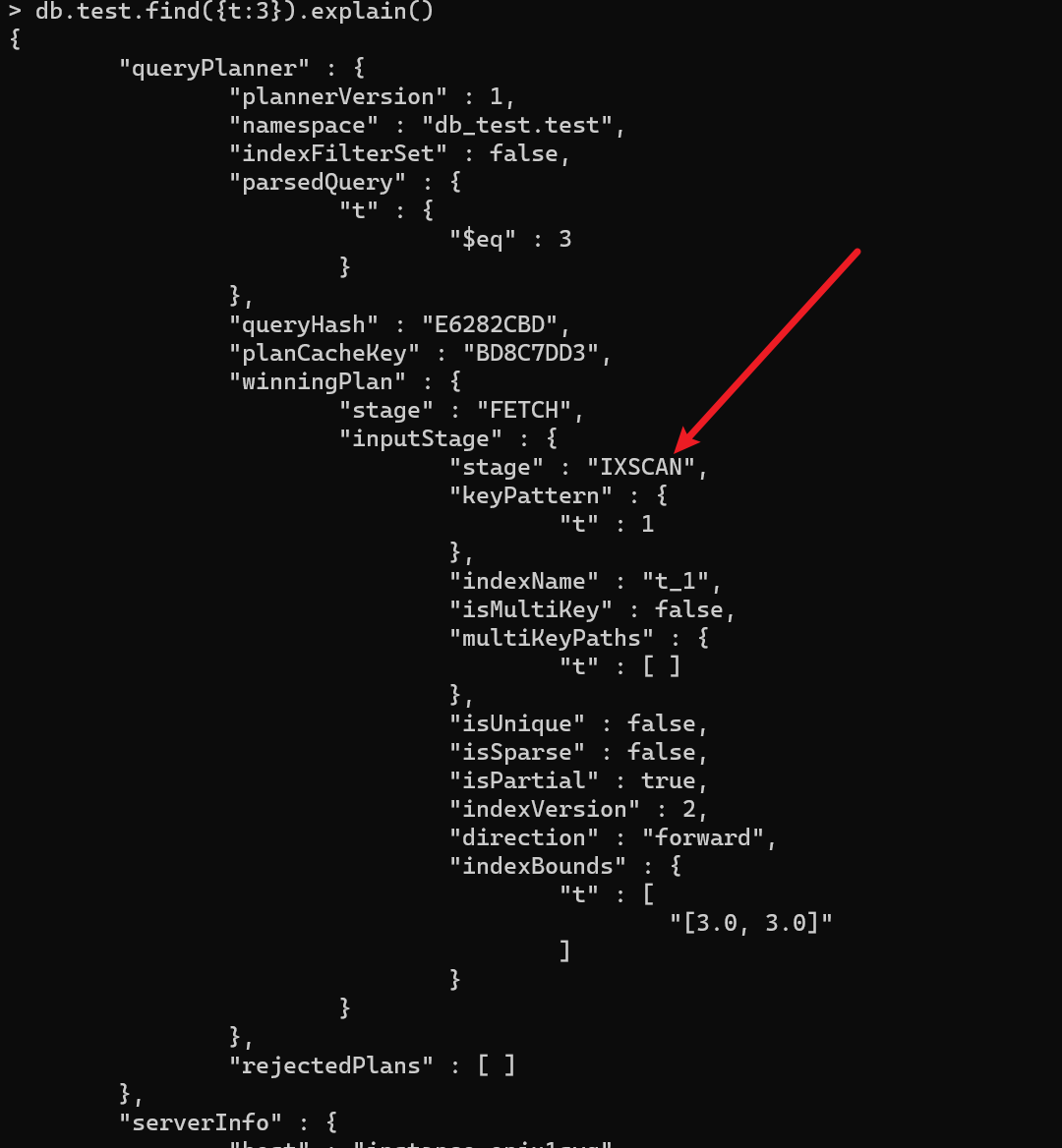
- 对不符合条件的数据进行查询,如图,没用到索引
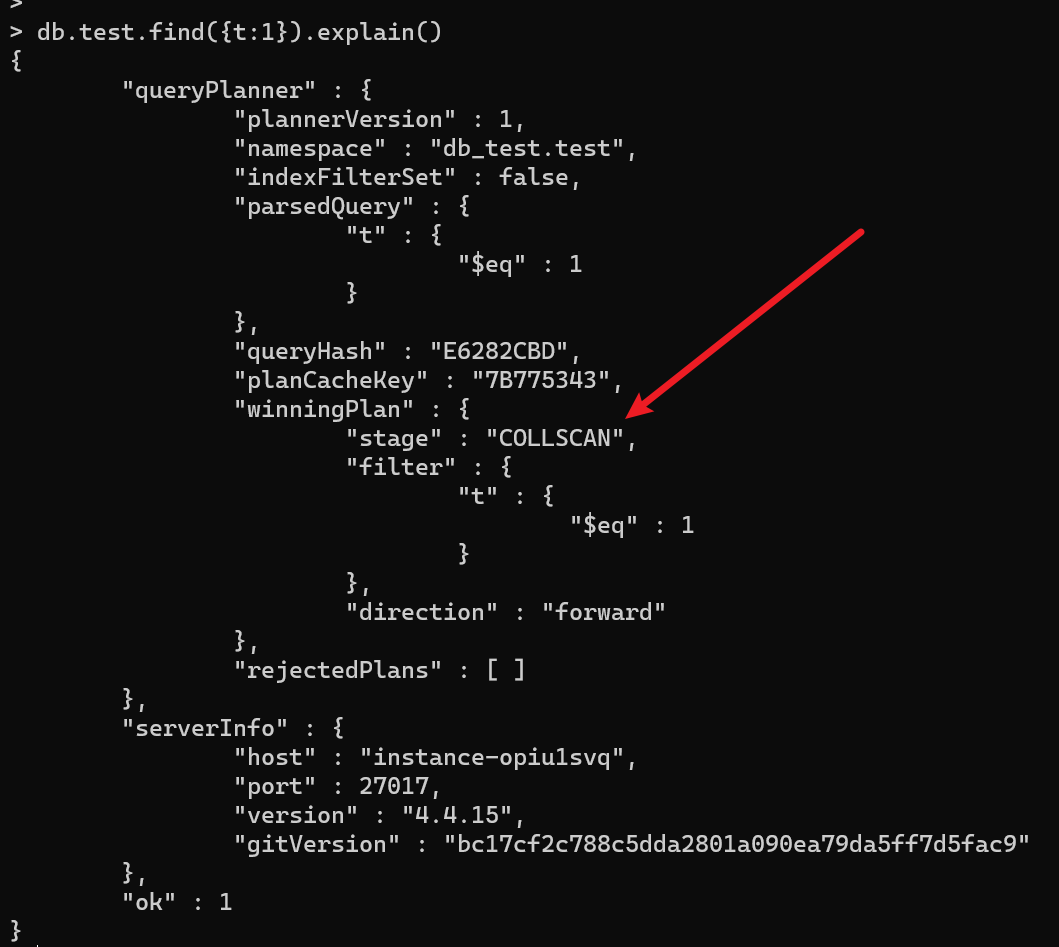
TTL索引
针对日期字段,或者包含了日期元素的数组字段,可以使用设定了生存时间的索引,来自动删除字段值超过生存时间的文档。
具体语句:db.${collectionName}.createIndex({${fieldName}:1/-1},{expireAfterSeconds:秒数})
验证如图:在createDate字段上建立了ttl索引,过期时间为10s。10s后数据被删除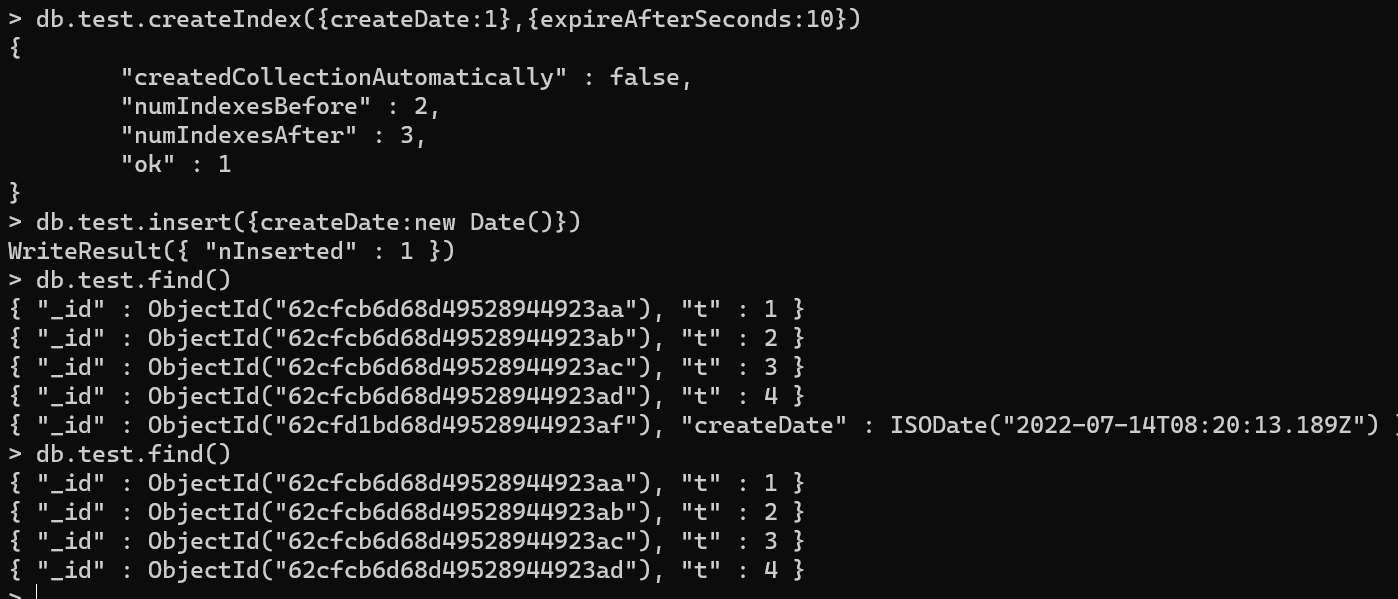
5.索引在磁盘上的存储形式
如图,在wiredTiger引擎,索引在磁盘上的存储形式为.wt文件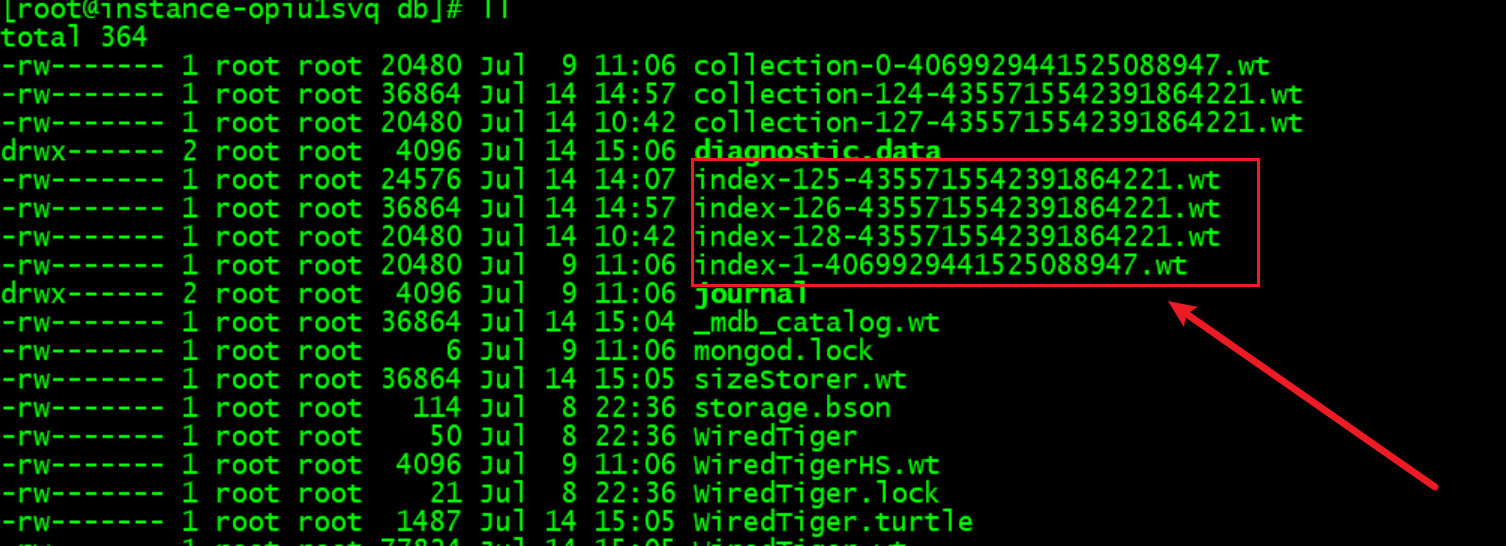
6.覆盖索引
与mysql一样。mongo中同样存在覆盖索引的概念。
如果查询的投影,直接命中了索引列,那么就无须再去文档中查询对应的字段,这一过程成为覆盖索引。覆盖索引的查询效率明显优于回表查询的
同时如果索引字段是一个数组或对象(子文档),那么也不会触发覆盖索引操作
可以通过explain(“executionStat”)返回结果中的必须扫描文档数,来查看是否覆盖索引,覆盖索引时必须扫描文档数=0
7.索引的注意事项
额外开销
每个索引都会占用一些空间,并且在每次执行插入、更新和删除等操作时也需要对索引进行操作,导致额外的开销。因此,如果很少将某个集合用于读取操作,最好不要在集合中使用索引。
RAM 使用
由于索引存储在 RAM(内存)中,因此应确保索引的总大小不超过 RAM 的限制。如果总大小大于 RAM 的大小,那么 MongoDB 将删除一些索引,这就会导致性能下降。
查询限制
在以下的查询中,不能使用索引:
- 正则表达式或否定运算符,例如 $nin、$not 等;
- 算术运算符,例如 $mod 等;
$where 子句。
因此,建议经常使用 explain() 来检查查询时索引的使用情况。索引键限制
从 2.6 版本开始,如果现有索引字段的值超过索引键的限制,那么 MongoDB 将不会创建索引。
插入超过索引键限制的文档
如果文档索引字段的值超过了索引键的限制,那么 MongoDB 不会将任何文档插入到集合中。mongorestore 和 mongoimport 实用程序也是如此。
索引建限制
在定义索引时有以下几点需要注意:
集合的索引不能超过 64 个;
- 索引名称的长度不能超过 128 个字符;
- 复合索引最多可以拥有 31 个字段。

若有收获,就点个赞吧
0 人点赞
