1.投影(指定结果键值)
find()方法的第二个参数,即为投影,说白了就是指定返回的键值,因为在有些场景下,我们是不希望返回文档的全部键值的。此时就需要声明投影参数
投影参数有以下几个需要注意的点:
- 投影格式为{key1:1, key2:1, …}。其中1代表显示该键值,0代表不显示该键值。
- 在指定了具体键值为1后,除了_id键值和声明为1的键值,其他键值都不显示
- 如果仅需要设置第二个参数,而不需要设置第一个参数的话,则需要在第一个参数的位置添加一个空的花括号{}作为占位符,例如:db.${collectionName}.find({}, {_id:1})。
在执行 find() 方法时 _id 字段是始终显示的,如果您不希望显示此字段,就需要将其设置为 0。
2.查询条数限制(分页)
命令格式
mongo中提供了两种命令进行分页查询,通常情况下我们会将两种命令结合使用进行分页查询
limit(number):该方法接收一个数字作为参数,用来设置要显示的记录数。默认为空,代表查询全部数据。具体命令格式:db.${collectionName}.find().limit(number)
skip(number):该方法接收一个数字作为参数,用来设置要跳过的文档数。默认为0,代表不跳过任何数据。具体命令格式:db.${collectionName}.find().skip(number)
示例
测试数据存入
db.test.insert([{“name”:”ftc”,”age”:18},{“name”:”skx”,”age”:18},{“name”:”wqw”,”age”:22},{“name”:”gn”,”age”:22},{“name”:”mm”,”age”:3}])
[{"name":"ftc","age":18},{"name":"skx","age":18},{"name":"wqw","age":22},{"name":"gn","age":22},{"name":"mm","age":3}]
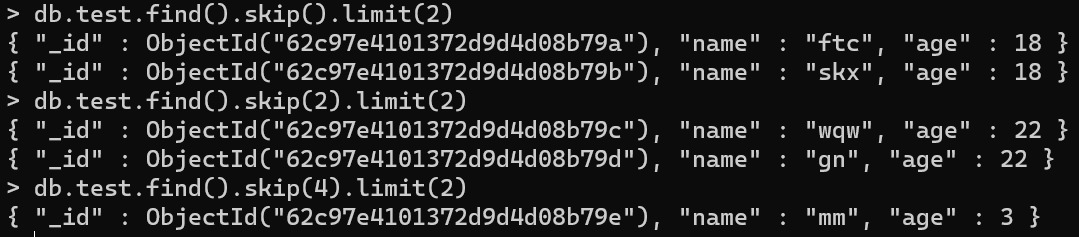
- 查询前2个数据:db.test.find().limit(2)

- 查询后3个数据:db.test.find().skip(2)

- 分页查询数据,每页2个,查询第1,2,3页内容
(PS:分页公式=db.test.find().skip((pageNum-1)*pageSize).limit(pageSize))
- db.test.find().skip().limit(2)
- db.test.find().skip(2).limit(2)
- db.test,find().skip(4).limit(2)
3.排序
命令格式
mongo中使用sort命令来进行数据的排序
db.$collectionName.find().sort({key1:1/0},{key2:1/0},…)。其中1代表升序排列,0代表降序排列
示例
- 按照年龄升序
db.test.find().sort({age:1})
- 按照年龄降序
db.test.find().sort({age:-1})
- 安装年龄升序、名称降序
db.test.find().sort({age:1,name:-1})
4.聚合查询
MongoDB 中的聚合操作用来处理数据并返回计算结果,聚合操作可以将多个文档中的值组合在一起,并可对数据执行各种操作,以返回单个结果,有点类似于 SQL 语句中的 count(*)、group by 等。
命令格式
db.${collectionName}.aggregate(aggregate_operation)
管道符
MongoDB 中聚合操作同样支持管道,即 MongoDB 会在一个管道处理完毕后将结果传递给下一个管道处理,而且管道操作是可以重复的。
- $group:对集合中的文档进行分组,可用于统计结果
- $match:用于过滤数据,只输出符合条件的文档,可以减少作为下一阶段输入的文档数量
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
- $project:用于从集合中选择要输出的字段,与投影功能一致
- $sort:将输入文档进行排序后输出
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档
- $limit:用来限制 MongoDB 聚合管道返回的文档数量
- $geoNear:输出接近某一地理位置的有序文档
其他的参考:链接
$Group聚合参数
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和 | db.test.aggregate([{$group : {_id : “$author”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算平均值 | db.test.aggregate([{$group : {_id : “$author”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 获取集合中所有文档对应值得最小值 | db.test.aggregate([{$group : {_id : “$author”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 获取集合中所有文档对应值得最大值 | db.test.aggregate([{$group : {_id : “$author”, num_tutorial : {$max : “$likes”}}}]) |
| $push | 在结果文档中插入值到一个数组中 | db.test.aggregate([{$group : {_id : “$author”, url : {$push: “$url”}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本 | db.test.aggregate([{$group : {_id : “$author”, url : {$addToSet : “$url”}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据 | db.test.aggregate([{$group : {_id : “$author”, first_url : {$first : “$url”}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.test.aggregate([{$group : {_id : “$author”, last_url : {$last : “$url”}}}]) |
示例
- 计算年龄总和:db.test.aggregate({$group:{_id:”Total”,ageAll:{$sum:”$age”}}})

- 计算不同年龄段人数:db.test.aggregate({$group:{_id:”$age”,count:{$sum:1}}})

- 计算年龄平均值:db.test.aggregate({$group:{_id:”avgAge”,age:{$avg:”$age”}}})

- 计算年龄最大值: db.test.aggregate({$group:{_id:”maxAge”,maxAge:{$max:”$age”}}})

- 计算年龄大于17的总人数:db.test.aggregate([{$match:{age:{$gt:17}}},{$group:{_id:”total”,”count”:{$sum:1}}}])
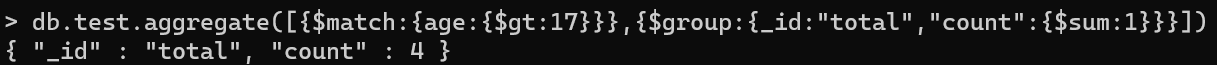
5.多表联查
假设目前存在学生以及成绩的概念,一个学生关联多门成绩,数据结构如下
{"name":"语文","score":63}
{"name":"ftc","age":12}
嵌入式数据模型
数据模型
嵌入式数据模型如下
[{"name":"ftc","age":12,"grades":[{"name":"语文","score":63},{"name":"数学","score":109},{"name":"英语","score":90},{"name":"物理","score":80},{"name":"化学","score":98}]}]
查询成绩语句
db.test.find({name:”ftc”},{“grades”:1})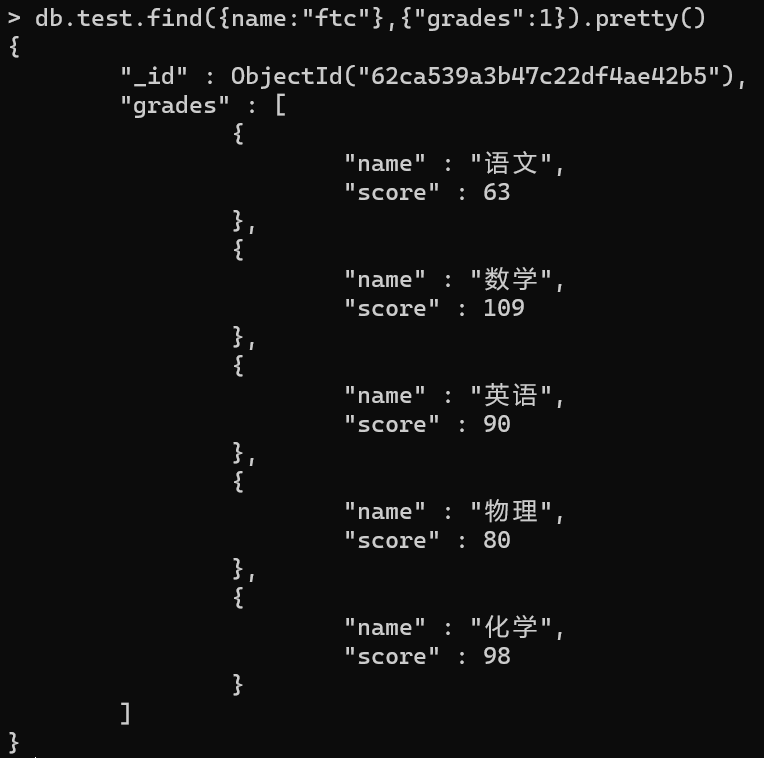
如图,嵌入式数据模型
优点:查询简单,只需要查询一个文档,之后获取文档特定的字段即可。
缺点:当数据量逐步增大时,如果单个文档过大,势必会对读写性能产生影响。
规范化数据模型(引用式)
数据模型
{"_id":ObjectId("62ca60683b47c22df4ae42c1"),"name":"ftc","age":12}
{"_id" : ObjectId("62ca61c93b47c22df4ae42c3"),"sid" : ObjectId("62ca60683b47c22df4ae42c1"),"name" : "语文","score" : 63}{"_id" : ObjectId("62ca621b3b47c22df4ae42c4"),"sid" : ObjectId("62ca60683b47c22df4ae42c1"),"name" : "数学","score" : 109}{"_id" : ObjectId("62ca62333b47c22df4ae42c5"),"sid" : ObjectId("62ca60683b47c22df4ae42c1"),"name" : "英语","score" : 90}{"_id" : ObjectId("62ca624f3b47c22df4ae42c6"),"sid" : ObjectId("62ca60683b47c22df4ae42c1"),"name" : "物理","score" : 80}{"_id" : ObjectId("62ca62573b47c22df4ae42c7"),"sid" : ObjectId("62ca60683b47c22df4ae42c1"),"name" : "化学","score" : 98}
lookUp与unwind
mongo中使用lookUp管道符进行多表联查
命令格式示例:$lookup:{from:”orders”,localField:”_id”,foreignField:”uid”,as:”orders”}
参数介绍:
- form:需要关联的外表名,$lookup的多变查询使用的是左外连接
- localField:本表的外表关联字段
- foreignField:外表的关联字段;
- as:参考查询结果,使用$lookup进行查询后会将所有符合条件的文档封装为一个list,as参数定义这个list的名字
mongo中使用unwind管道符进行多表联查后结果的拆分,将一条记录拆分为多条记录
命令格式示例:$unwind:”$被拆分键值名称”
查询成绩语句
综上所述,规范化模型多表联查语句如下:
db.student.aggregate([{$lookup:{from:”grade”,localField:”_id”,foreignField:”sid”,as:”student_grades”}},{$unwind:”$student_grades”}]).pretty()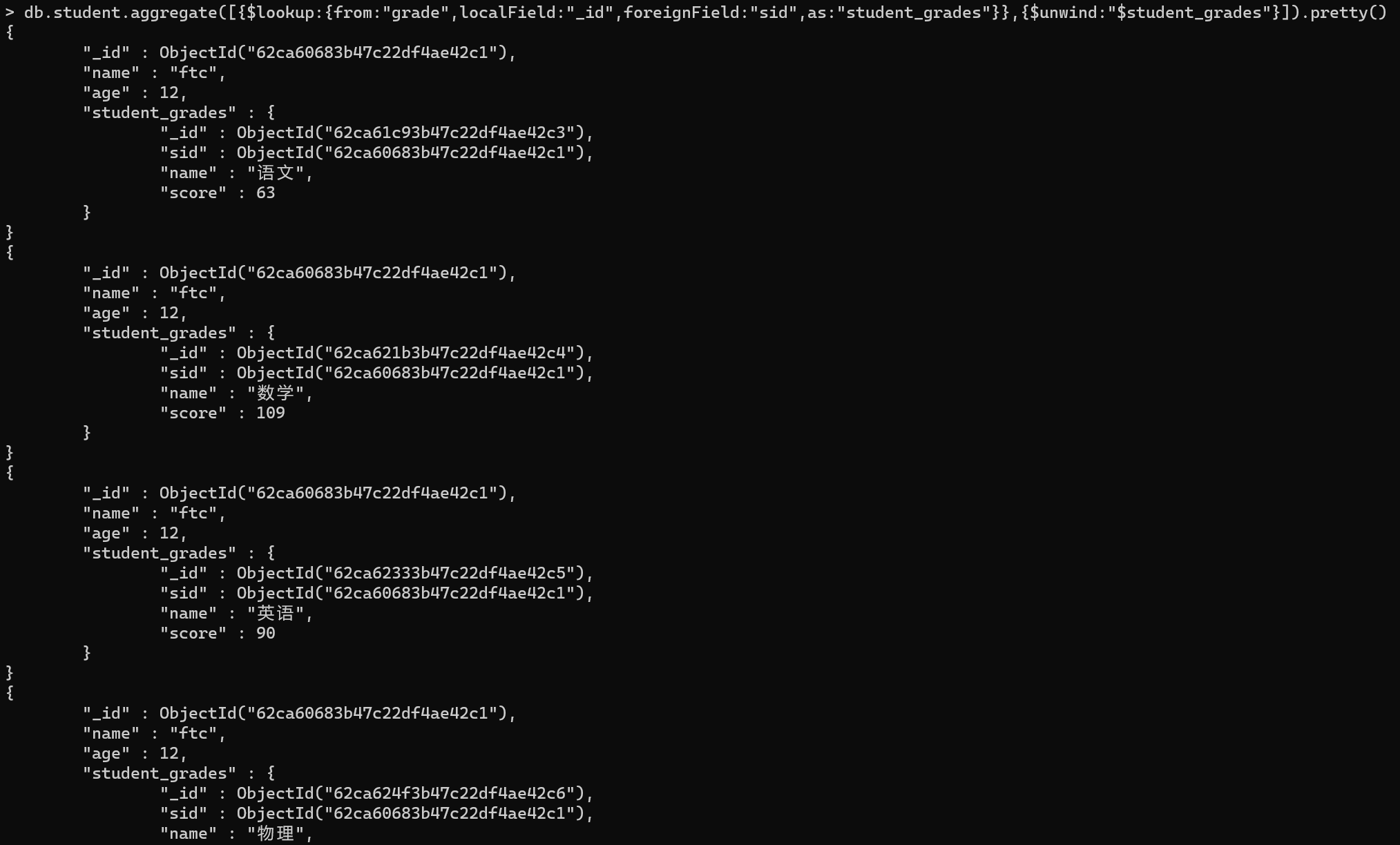

若有收获,就点个赞吧
0 人点赞
