1.MapReduce
作用
在用 MongoDB 查询时,若返回的数据量很大,或者做一些比较复杂的统计和聚合操作做花费的时间很长时,可以使用 MongoDB 中的 mapReduce 进行实现。
mapReduce 是个灵活且强大的数据聚合工具,它的好处是可以把一个聚合任务分解为多个小的任务,分配到多个服务器上并行处理。
MapReduce是一个编程模型,封装了并行计算、容错、数据分布、负载均衡等细节问题。
通俗理解,aggragation和mapreduce都可以实现聚合,但是mapreduce支持分片模式存储的分布式数据聚合,可以处理更大的数据量
命令格式
在 mapReduce 命令中要实现两个函数,分别是 map 函数和 reduce 函数,其中 map 函数调用 emit(key, value),遍历集合中的所有记录,并将 key 与 value 传递给 reduce 函数进行处理,
db.collection_name.mapReduce(function() {emit(key, value);}, // map 函数function(key, values) {return reduceFunction}, // reduce 函数{out: collection,query: document,sort: document,limit: number})
参数说明如下:
- map 函数:一个 javascript 函数,它用一个键映射一个值并发出一个键值对;
常用格式:emit(p1, p2)
- p1:需要分组的字段,this.字段名。
- p2:需要进行统计的字段,this.字段名。可以设置为常数1
- reduce 函数:一个 javascript 函数,用于减少或分组具有相同键的所有文档;
其中重点关注相同键这个词,map处理的键值对交给reduce处理时,是按照键值分组的
统计常用的方法:
//对数值类型进行求和。(PS:Arrays.sum方法在js中时无效的,只在mongo shell js中有效)var reduce = function(key, values){ return Array.sum(values); }//对字符串类型进行拼凑var reduce = function(key, values){ return values.join(', '); }
假设统计当前班级成员,包括姓名,年龄,性别三个字段
参数如下
[{"name":"ftc","age":18,"sex":"boy"},{"name":"gn","age":18,"sex":"girl"},{"name":"wqw","age":20,"sex":"girl"},{"name":"skx","age":17,"sex":"girl"},{"name":"wkf","age":15,"sex":"girl"},{"name":"wys","age":24,"sex":"girl"},{"name":"nn","age":26,"sex":"girl"}]
统计年龄大于17岁的学生,男女生分别的个数是多少
var map = function() { emit(this.sex,1); }var reduce = function(key, values) { return Array.sum(values)}var options = { query:{age:{$gt:17}}, out:"result"}db.test.mapReduce(map,reduce,options)db.result.find()
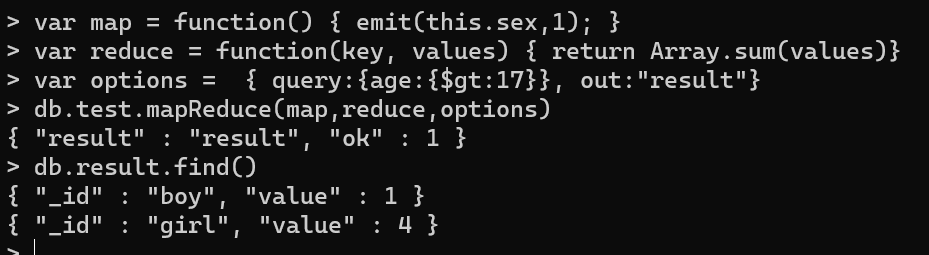
统计年龄大于17岁的学生,男女生分别的详细列表
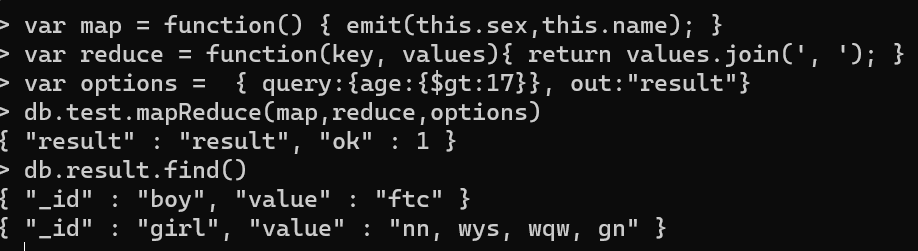
var map = function() { emit(this.sex,this.name); }var reduce = function(key, values){ return values.join(', '); }var options = { query:{age:{$gt:17}}, out:"result"}db.test.mapReduce(map,reduce,options)db.result.find()
2.正则表达式
作用
mongo中同样提供了正则表达式查询模式,可以在不建立文本索引的情况下,进行文本字段的匹配查询。MongoDB 使用 PCRE(Perl 兼容的正则表达式)作为正则表达式语言
PCRE具体参考链接命令格式
db.${collectionName}.find(${fieldName:{$regex:”具体参数”,$options:”具体可选项”}})
$regex:使用正则表达式进行匹配查询
$options:正则表达式可选项,比较常用的是”$i”,代表不区分大小写
验证
存入测试数据(与mapReduce中参数一致)
- 查询名称中带有w的学生:db.test.find({name:{$regex:”w”}})
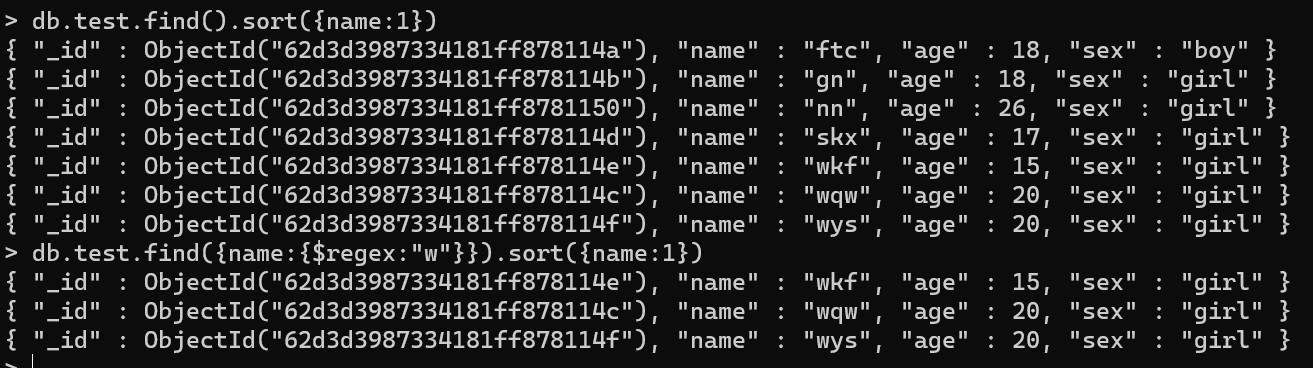
此时每个文档新增一个tags字段
[{"name":"ftc","age":18,"sex":"boy","tags":["帅哥","器大","活好"]},{"name":"gn","age":18,"sex":"girl","tags":["美女","长腿"]},{"name":"wqw","age":20,"sex":"girl","tags":["熟女","性感"]},{"name":"skx","age":17,"sex":"girl","tags":["美女","嗓音独特"]},{"name":"wkf","age":15,"sex":"girl","tags":["美女","气质出众"]},{"name":"wys","age":24,"sex":"girl","tags":["少女","好看"]},{"name":"nn","age":26,"sex":"girl","tags":["美女","性感"]}]
查询标签为美女的学生:db.test.find({tags:{$regex:”美女”}})
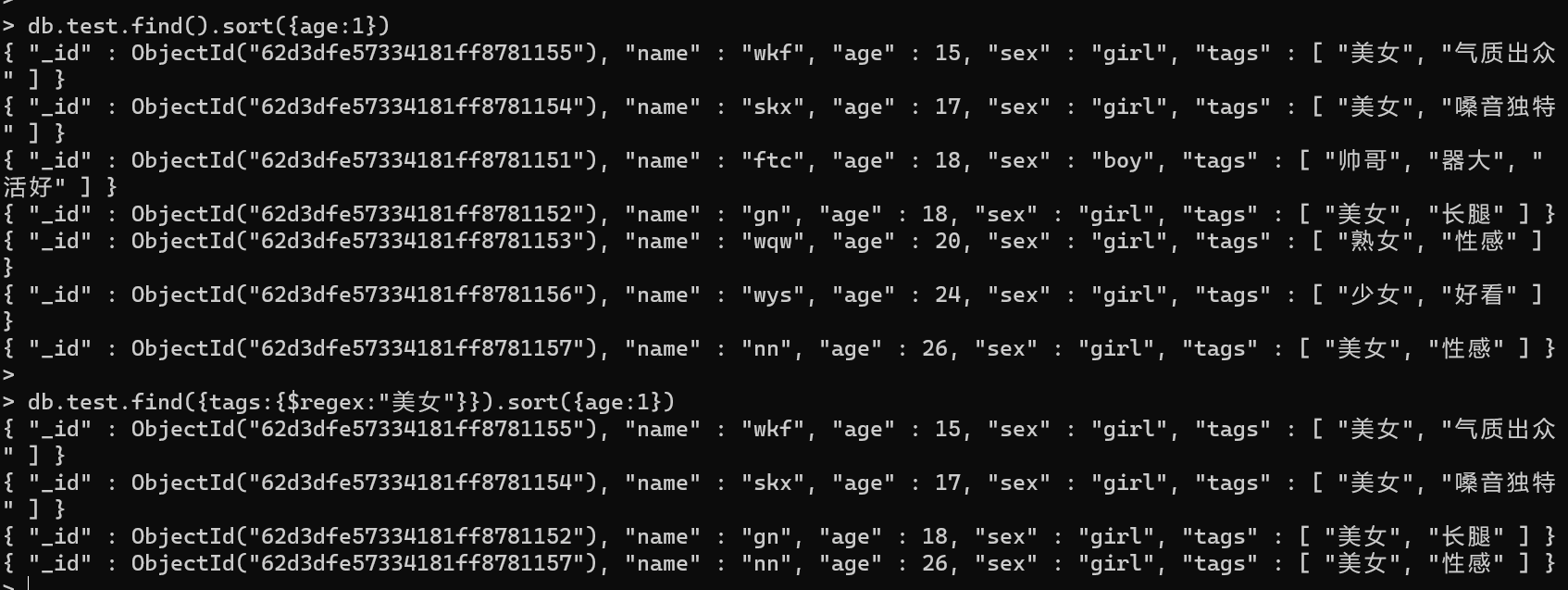
- 此时修改skx名称为SKX:db.test.update({name:”skx”},{$set:{name:”SKX”}})
- 查询名称中带有s的学生:db.test.find({name:{$regex:”s”,$options:”$i”}})

3.GridFS
作用
MongoDb GridFS 是MongoDB的文件存储方案,主要用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频等),对大文件有着更好的性能。
在存储文件时 GridFS 可以将一个文件分为多个数据块,并将每个数据块存储在一个单独的文档中,每个文档最大为 255KB。
通俗来讲就是用来存储大型文件(大于16M的文件)的,可以在分布式项目中用来存储大型文件
原理
默认情况下,GridFS 使用 fs.files 和 fs.chunks 两个集合来存储文件的元数据和块。
- fs.files:每个大文件会生成一个文档,用来存储文档的明细信息,具体字段如下

- fs.chunks:每个大文件会生成一个或多个文档。每个区块都由其唯一的 ObjectId(_id)字段标识。fs.files 用作父文档,fs.chunks 文档中的 files_id 字段将块链接到fs.file的_id字段。具体字段如下

- 存储架构图
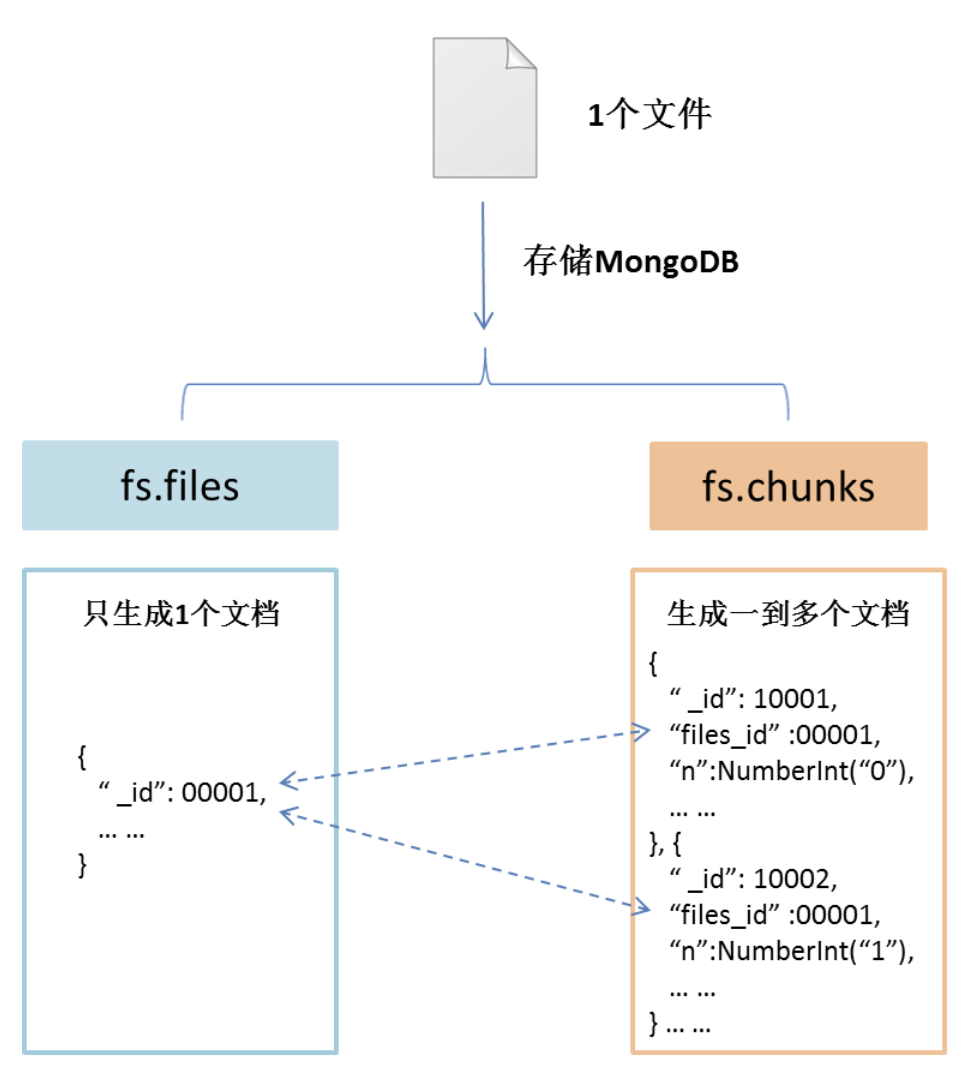
读取时,先查询fs.files集合中对应的唯一文档,然后查询fs.chunks集合中关联的数据块文档,通过n字段按顺序分段读取整个文档的内容
使用
存储文件 PUT
示例命令:mongofiles -h 120.48.107.224 -u test -p test —db files -l C:\Users\86176\Desktop\1.jpg put 1.jpg
如图,保存完成
查询对应信息,如图,因为fs.chunk.data数据过多不好展示,因此不展示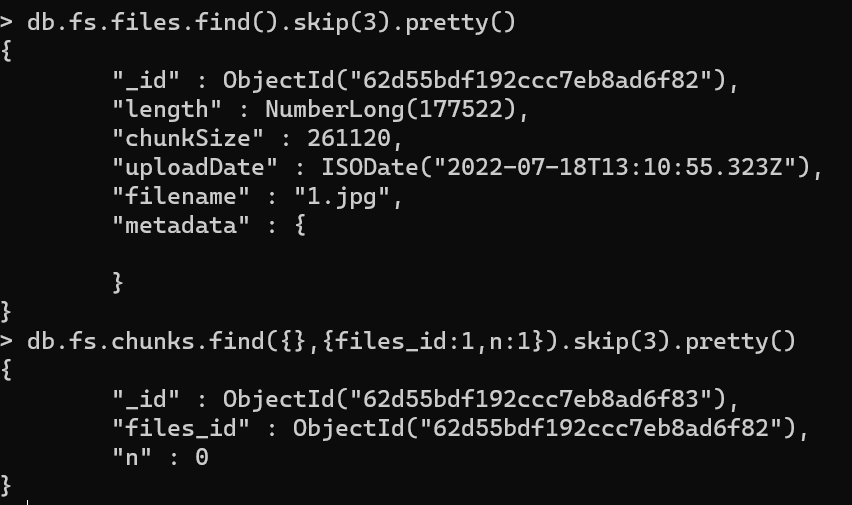
获取文件 GET
shell命令行默认目录下,此时并没有1.jpg
示例命令:mongofiles -h 120.48.107.224 -u test -p test —db files get 1.jpg
执行完下载后,获取到了1.jpg文件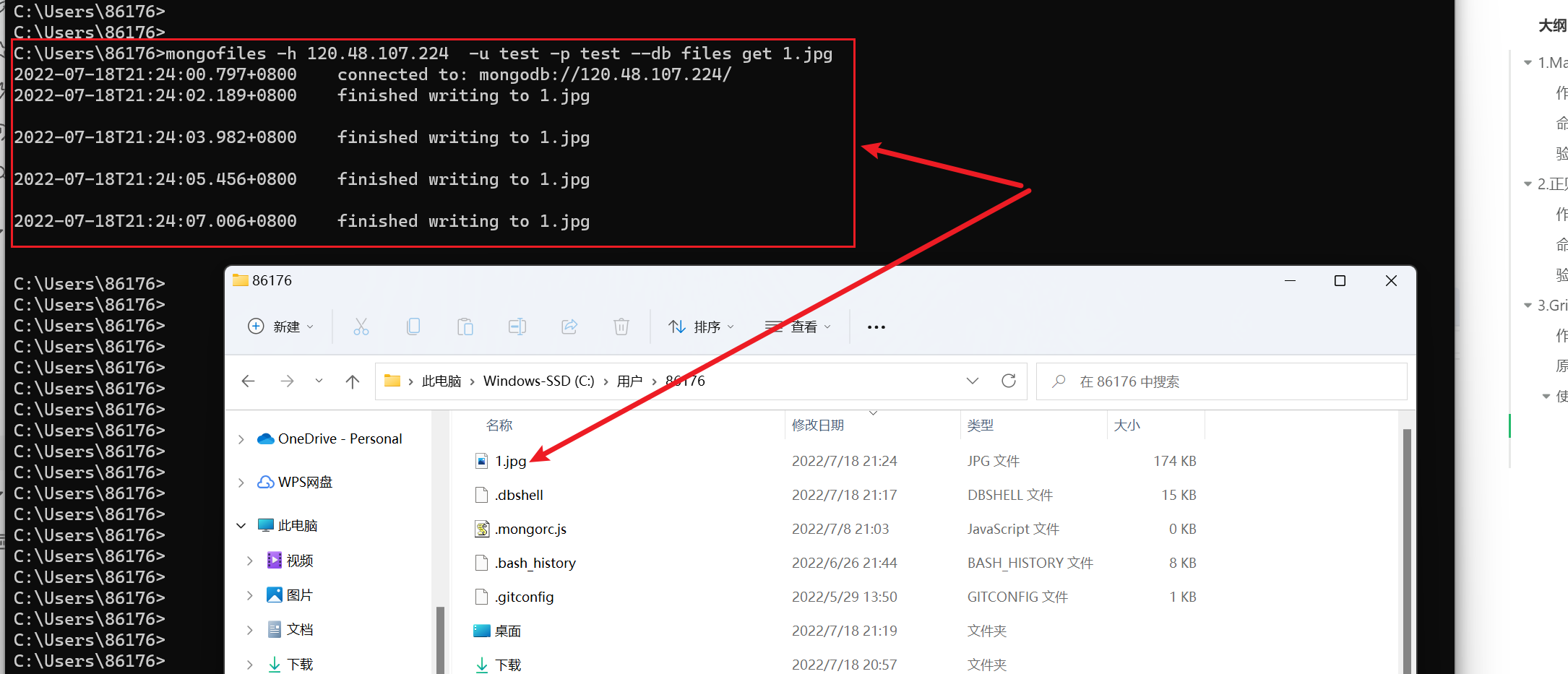
列出所有文件 LIST
示例命令:mongofiles -h 120.48.107.224 -u test -p test —db files list
如图,显示出文件夹以及每个文件的大小
删除文件 DELETE
示例命令:mongofiles -h 120.48.107.224 -u test -p test —db files delete 1.jpg
如图删除成功
此时在进行查找,同名文件已全部删除
注意
如果系统中大文件数量处于不断增加状态,还是建议使用专用的文件存储设备
-
4.数据备份
mongo中通过mongodump工具进行数据的备份,mongodump工具的下以及部署请参考链接
命令格式
mongodump -h dbhost -u username -p password -d dbname -c collectionName -o dbdirectory
-h:非必传,缺省代表链接本机
- -u:非必传,用户名
- -p:非必传,密码
- -d:必传,备份数据库
- -c:非必传,指定备份集合。缺省代表备份整个数据库
- -o:必传,备份文件存储位置,对应目录需提前创建!!!!
命令示例:mongodump -h 120.48.107.224 -u test -p test -d files-c fs.chunks -o D:\Code\Base\MongoDB\dump
验证
- 上传一张图片到files数据库:mongofiles -h 120.48.107.224 -u test -p test —db files -l C:\Users\86176\Desktop\1.jpg put 1.jpg

- 对files数据库进行备份:mongodump -h 120.48.107.224 -u test -p test -d files -o D:\Code\Base\MongoDB\dump

5.数据恢复
在进行了数据备份后,同样需要对数据进行恢复操作,mongo提供了mongorestore命令进行数据的恢复
命令格式
mongorestore -h dbhost -u username -p password -d dbname -c collectionName —dir dbdirectory
- -h:非必传,缺省代表链接本机
- -u:非必传,用户名
- -p:非必传,密码
- -d:必传,备份数据库
- -c:非必传,指定备份集合。缺省代表恢复整个数据库
- —dir:备份数据文件夹位置,需要具体到备份的数据库路径下!!!!
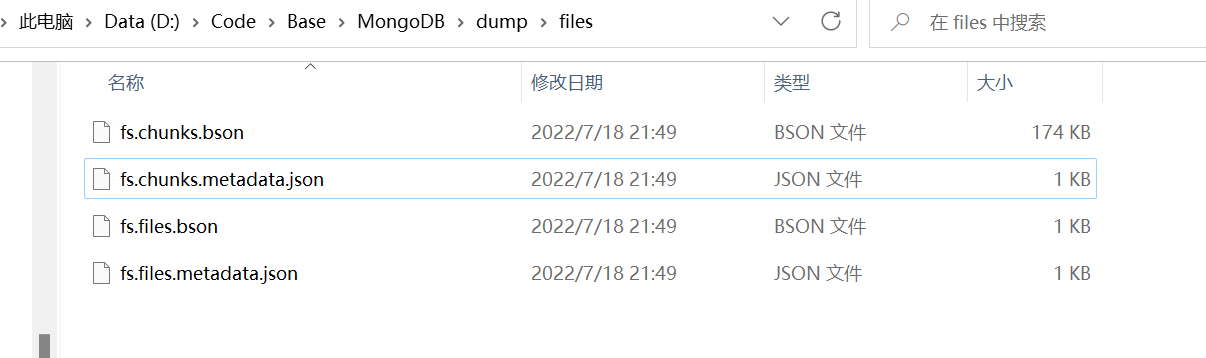
命令示例:mongorestore -h 120.48.107.224 -u test -p test -d files —dir D:\Code\Base\MongoDB\dump\files
验证
- 删除1.jpg文件:mongofiles -h 120.48.107.224 -u test -p test —db files delete 1.jpg

- 执行命令:mongorestore -h 120.48.107.224 -u test -p test -d files —dir D:\Code\Base\MongoDB\dump\files
如图,数据恢复成功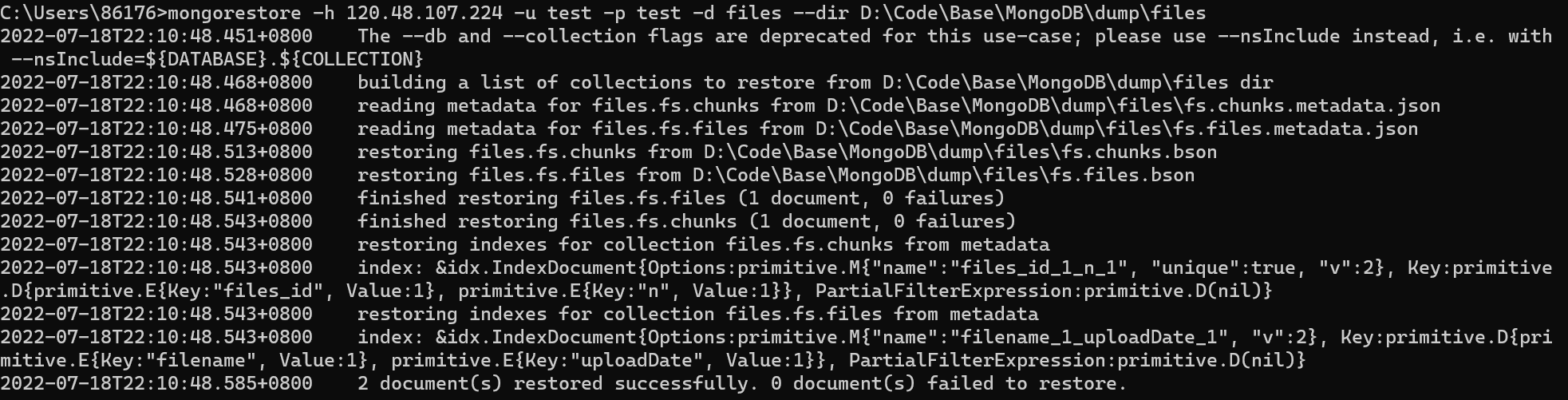
- 数据查看数据是否已恢复

6.统计与监控
在部署完Mongo服务器之后,为了保障 MongoDB 的正常运行。MongoDB 中提供了 mongostat 和 mongotop 两个命令来监控 MongoDB 的运行情况
mongostat
mongostat够检查所有正在运行的 mongod 实例的状态,并返回数据库操作的计数器。这些计数器包括插入、查询、更新、删除和游标。当您的内存不足、写入量不足或者出现一些性能问题时,该命令还会显示发生错误的时间,并显示锁定百分比。
命令格式
mongostat -h 120.48.107.224 -u root -p 123456—authenticationDatabase admin
验证
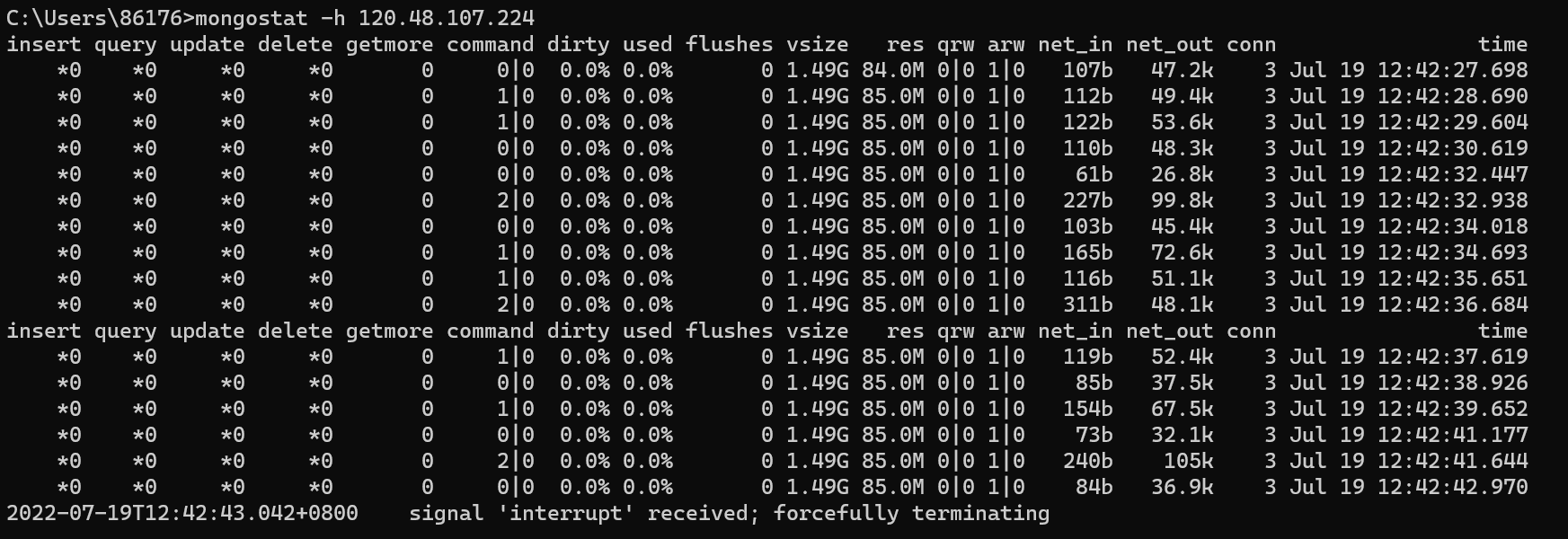
参数介绍如下:
- insert/s : 官方解释是每秒插入数据库的对象数量,如果是slave,则数值前有*,则表示复制集操作
- query/s : 每秒的查询操作次数
- update/s : 每秒的更新操作次数
- delete/s : 每秒的删除操作次数
- getmore/s: 每秒查询cursor(游标)时的getmore操作数
- command: 每秒执行的命令数,在主从系统中会显示两个值(例如 3|0),分表代表 本地|复制 命令
注: 一秒内执行的命令数比如批量插入,只认为是一条命令(所以意义应该不大)
- dirty: 仅仅针对WiredTiger引擎,官网解释是脏数据字节的缓存百分比
- used:仅仅针对WiredTiger引擎,官网解释是正在使用中的缓存百分比
- flushes:
- For WiredTiger引擎:指checkpoint的触发次数在一个轮询间隔期间
注:一般都是0,间断性会是1, 通过计算两个1之间的间隔时间,可以大致了解多长时间flush一次。flush开销是很大的,如果频繁的flush,可能就要找找原因了
- vsize: 虚拟内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据)
- res: 物理内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据)
注:这个和你用top看到的一样, vsize一般不会有大的变动, res会慢慢的上升,如果res经常突然下降,去查查是否有别的程序狂吃内存。
- qr: 客户端等待从MongoDB实例读数据的队列长度
- qw:客户端等待从MongoDB实例写入数据的队列长度
- ar: 执行读操作的活跃客户端数量
- aw: 执行写操作的活客户端数量
注:如果这两个数值很大,那么就是DB被堵住了,DB的处理速度不及请求速度。看看是否有开销很大的慢查询。如果查询一切正常,确实是负载很大,就需要加机器了
- netIn:MongoDB实例的网络进流量
- netOut:MongoDB实例的网络出流量
注:此两项字段表名网络带宽压力,一般情况下,不会成为瓶颈
-
mongotop
命令可以跟踪并报告 MongoDB 实例的读写活动。默认情况下,mongotop 能够提供每个集合的水平统计数据,并每秒钟返回一次,您也可以根据需要对其进行修改。
命令格式
mongotop -h 120.48.107.224 ${秒数,非必填。缺省状态下每秒刷新一次}
验证
7.Mongo中的定长集合
概念
mongo中大部分的集合都是动态集合,随着文档数递增而动态扩容
而定长集合与动态集合不同,它的大小固定,当集合中文档的大小达到固定容量后,会淘汰掉最老的文档进而存储最新的文档,可以把定长集合理解为一个队列。示例如下图: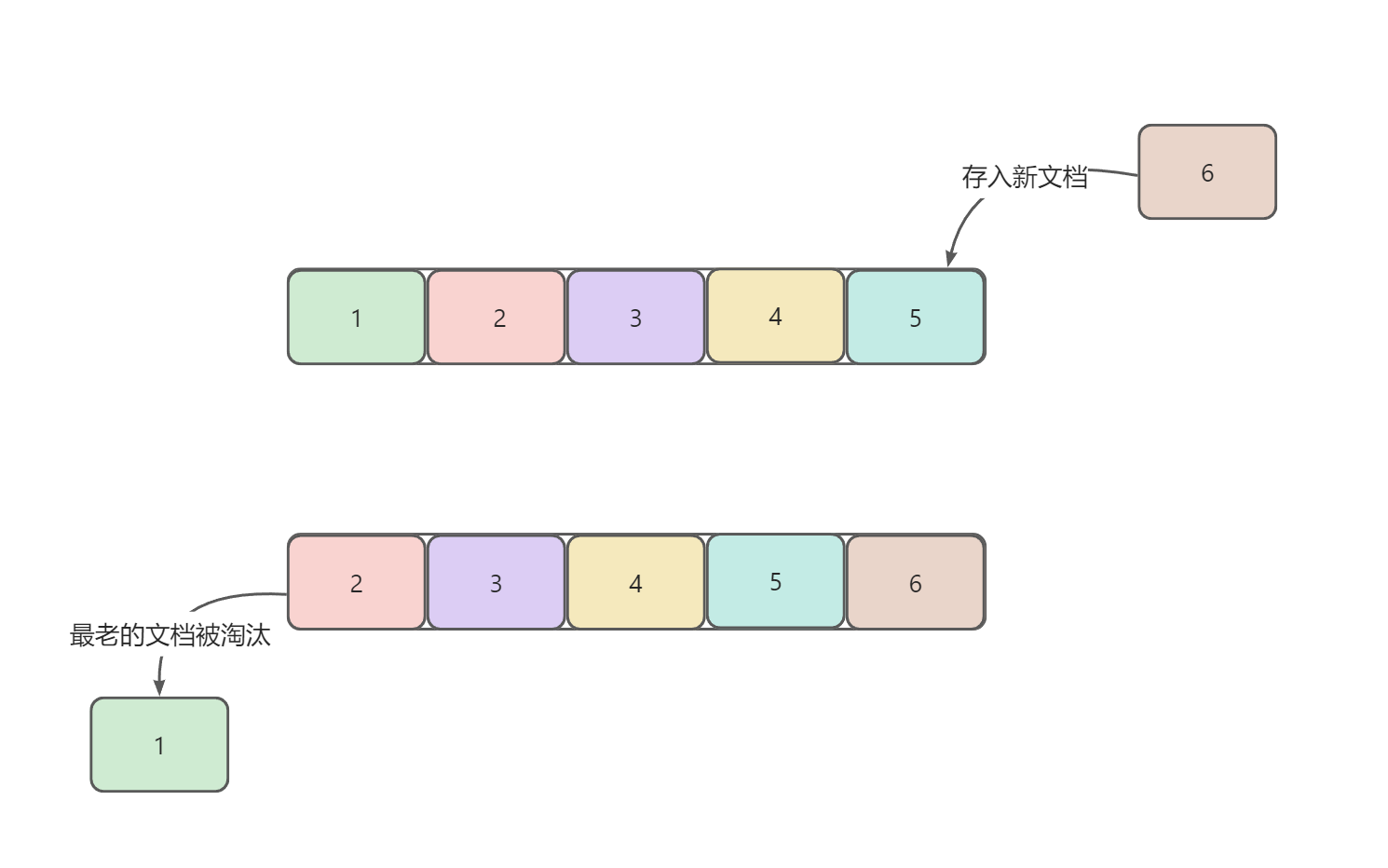
特点
支持insert操作,集合定长,当文档数达到固定大小后,会淘汰掉最老的文档
- 支持update操作,但是如果更新后整体文档大小超过固定大小,那么更新会失败
- 不支持remove操作
- 不会创建任何默认索引,_id字段也不会存在默认索引
- 文档的写入形式为顺序写,因此效率极高
-
命令格式
创建一个定长集合:db.createCollection(“cappedCollcetion”,{capped:true,size:10000,max:1000})
- capped:集合是否为定长集合
- size:定长集合的容量,单位字节数
- max:定长集合中最大文档数量

若有收获,就点个赞吧
0 人点赞
