输入层
卷积层(特征提取)
1.前置信息要点
fliter(过滤器)和卷积核(kernel)
(23条消息) 卷积核(kernel)和过滤器(filter)的区别Medlen的博客-CSDN博客卷积核和过滤器是一样的吗.pdf :::info 卷积核是一个参数矩阵,其尺寸等于单层卷积中选择的区域的大小,过滤器是把所有层的对应卷积核集合在一起,并加上一个b参数形成的整体。 ::: :::warning 注意,可以同时存在许多个过滤器对数据进行卷积以提取不同特征(或者比较同一特征提取的效果),不过在一个模型的训练中,所有过滤器(卷积核)的大小应该保持一致以方便将得到的多个特征图进行分析处理 :::
2.卷积的本质
卷积参数共享
:::info 注意,在一次卷积进行过程中(单层特征图的求取),一个卷积核中的参数是共享的,共享应用,共享训练矫正 :::
卷积流程
假设:输入一张图片数据32323, 卷积操作会先对图像进行分层(这里是分为三层),每层每和一个卷积核在二维空间进行遍历内积计算(遍历间隔取决于选定的步长大小),就分别获得每层对应的一个特征值矩阵。然后再将对应的三层特征值矩阵合在一起,并加上b参数,从而得到图片(该样本)的一个特征值矩阵
:::info
经过卷积,得到的每一个特征值矩阵相较于原数据矩阵大小上取决于步长大小,边缘填充和卷积核尺寸,计算公式:H2=(H1-FH+2P)/S+1
H1表示输入原数据矩阵的长度,H2表示输出特征图的长度,F表示卷积核长的大小,S表示滑动窗口的步长,P表示边界填充的圈数。
(宽可类比)
层数上等于过滤器的数量
:::
3.卷积层涉及的参数
滑动窗口步长
即遍历间隔的大小
步长越小越精密,拟合效果越好,但是这会增大计算量,一般来说设置为1,而且在特定的任务中(比如文本识别)需要的步长更大
卷积核尺寸(大小)
即卷积中选择的区域的大小
卷积核尺寸越小越精密,拟合效果越好,但是这会增大计算量,一般来说设置为3*3,
边缘填充(0-padding)
将原数据矩阵/上一层特征值矩阵扩充(边界加一层空数据0),以促使原数据矩阵里面的每个数据点都能被卷积相同的次数并最终映射到特征值矩阵,一定程度上弥补了边界信息缺失的问题。
文本数据的边缘填充
卷积核个数
4.多次卷积的思想
池化层(压缩特征)
池化方法
MAX POOLING
max pooling会把特征图的长宽进行取区域最大值以缩减,但不改变层数
(23条消息) Maxpooling的作用_费马定理的博客-CSDN博客_maxpooling的作用.pdf
average pooling(基本不用)
卷积神经网络整体架构
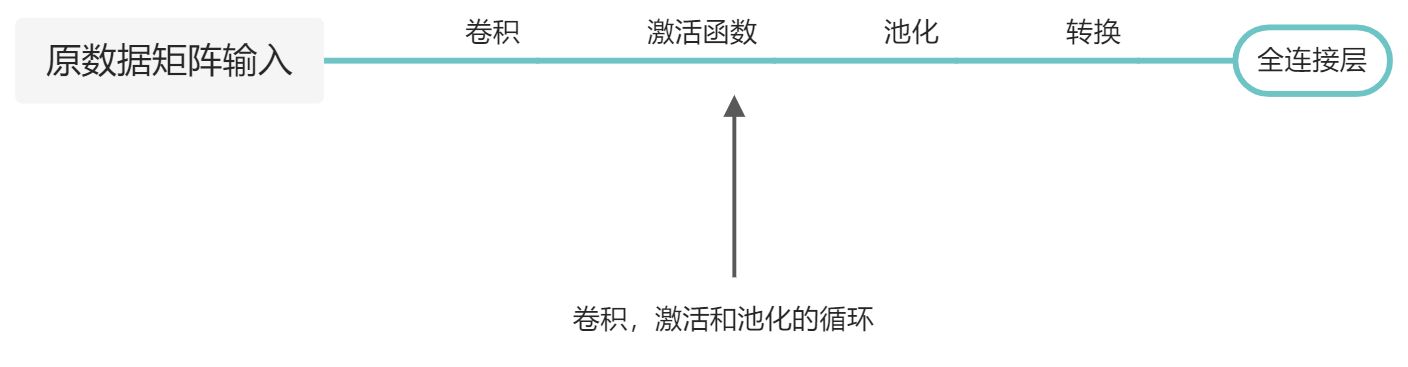
全连接层(连接输入层和隐层)
:::info 经过多次卷积,激活,池化后的数据进行转换,最后拼接成能得出最终结论的全连接层 :::
经典网络介绍
vgg网络(传统神经网络巅峰)
(23条消息) 快速理解VGG网络_YLTENG的博客-CSDN博客_vgg.pdf
Resnet残差网络(提升特征提取有效性)
:::info 随着神经网络的层数的增加,很有可能其中某一层的卷积效果不好,Resnet残差网络可以将不好的卷积层剔除掉,将上一层得出的特征图直接进行下一层的卷积(当然也要先激活一下) ::: (23条消息) resnet详解_「已注销」的博客-CSDN博客_resnet.pdf
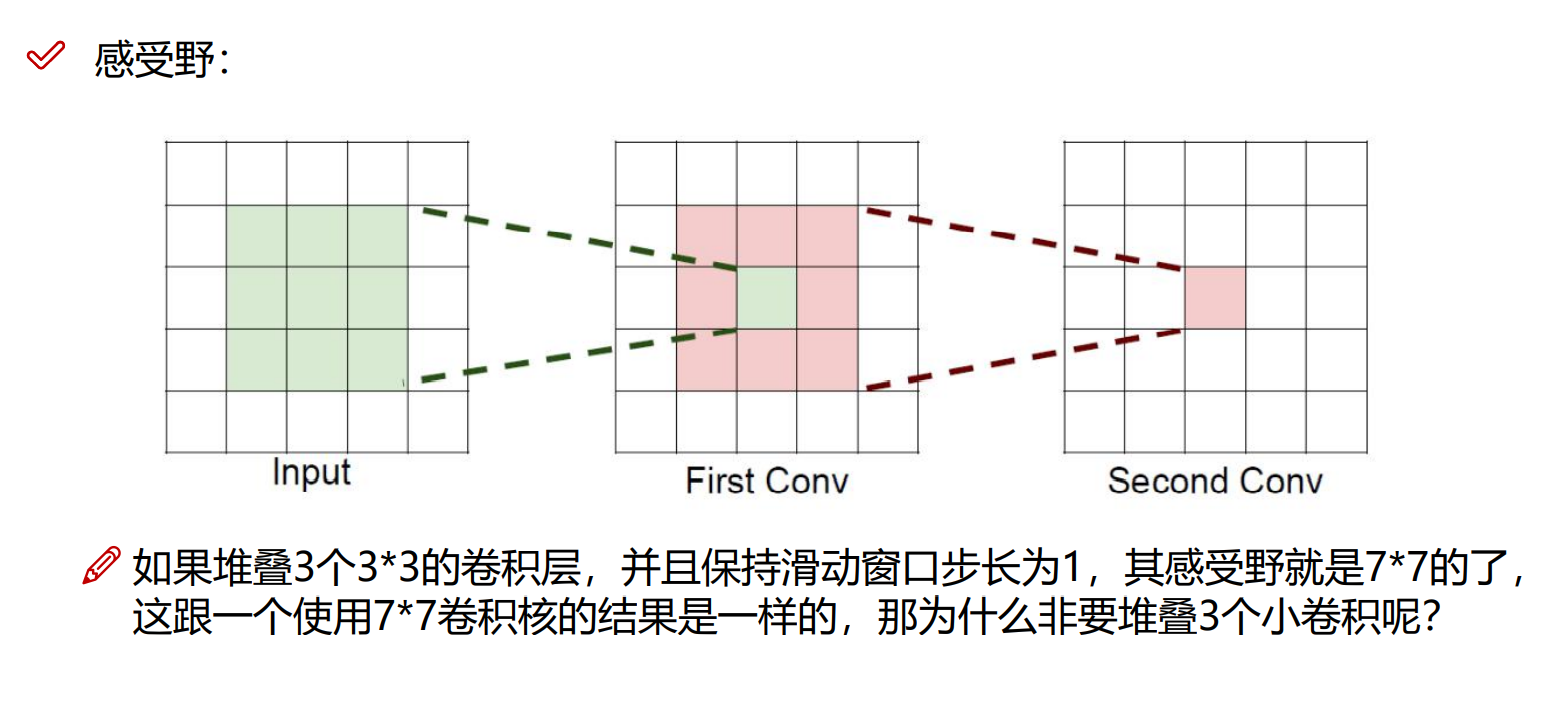
感受野的作用
当前层的一个值的感受野是指原始数据中所有参与计算出该值的相关值的集合(矩阵)

卷积神经网络的应用

若有收获,就点个赞吧
0 人点赞
