

![WJ]P195TY392)IWW0$G2`DS.png](/uploads/projects/u26765122@ul70is/7d986a3b844e40122517f14279ca3104.png)
流程上一上
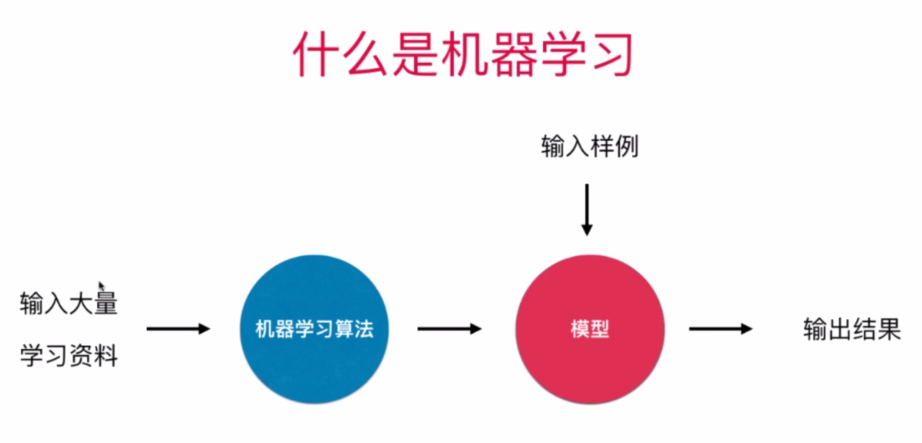
机器学习的数据来源
![@JD$C0C698%$21(1MSW]XZV.png](/uploads/projects/u26765122@ul70is/a3a4ceb085b4541e87843031ffdef436.png)
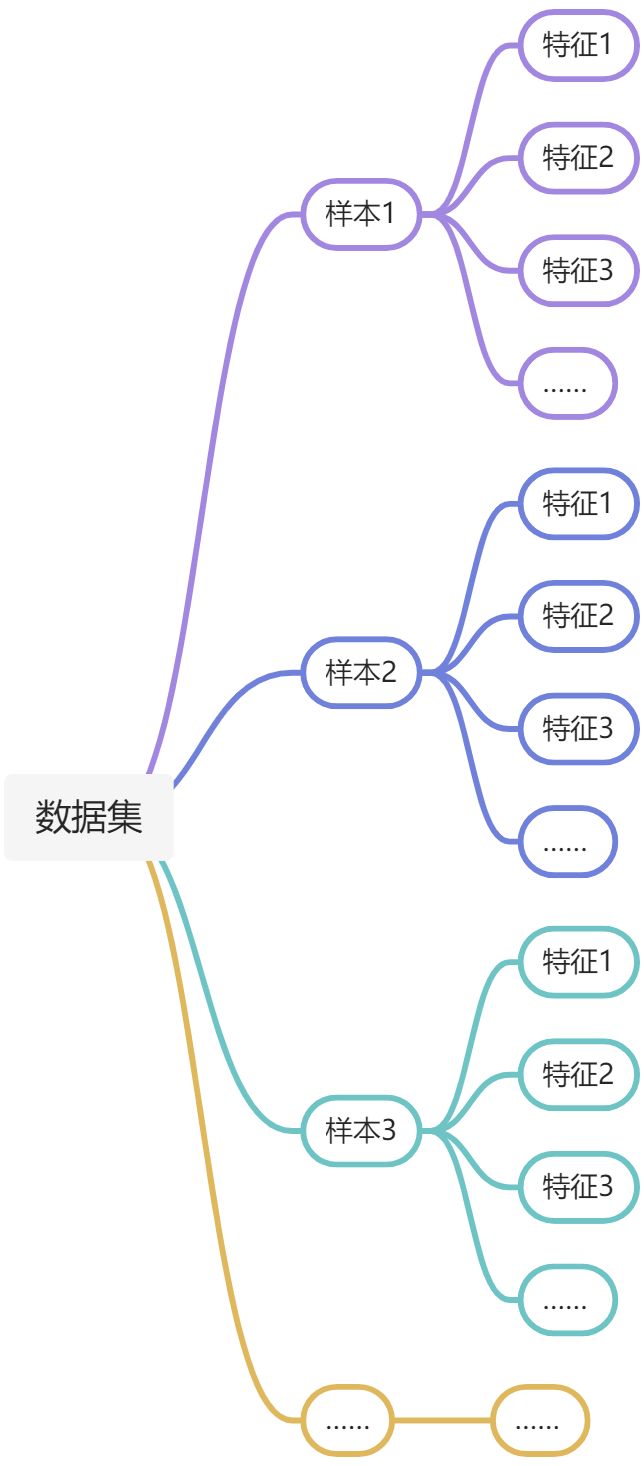
我们一般用列向量来表示一个样本及其所有特征值
把列向量转置后组合可以组合成一个矩阵
(下图表述不是很对,图中的一个样本应该是一行,其中有多个特征值)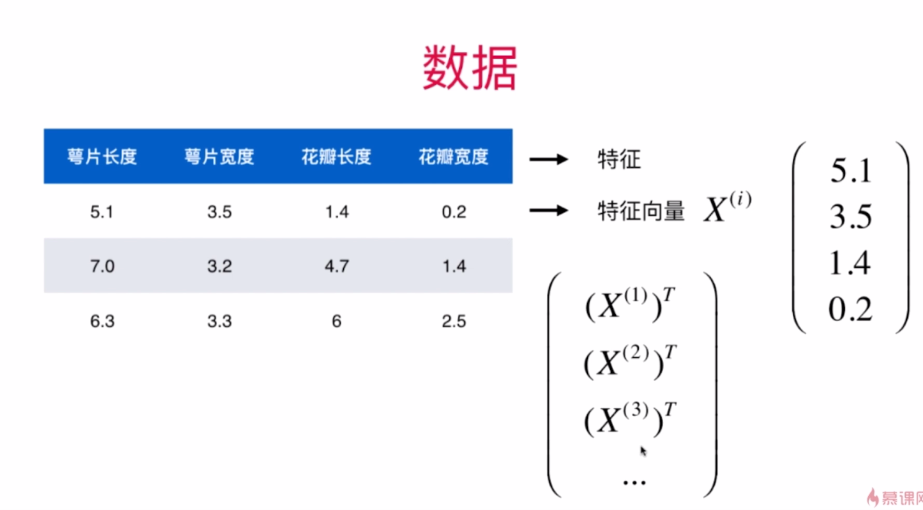
我们也可以把数据集放到坐标系中表示,每一个特征值的大小对应一个轴的坐标大小(有多少个特征值坐标系就有多少维度)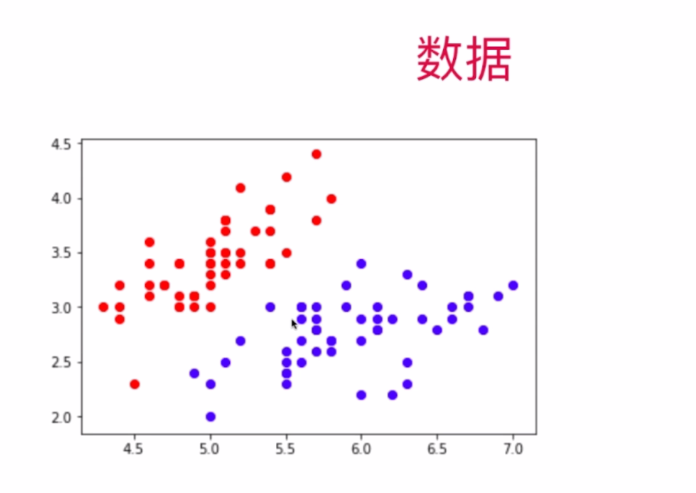
一般来说,我们会对坐标系里面的样本用拟合的曲线进行分类,而且维度很高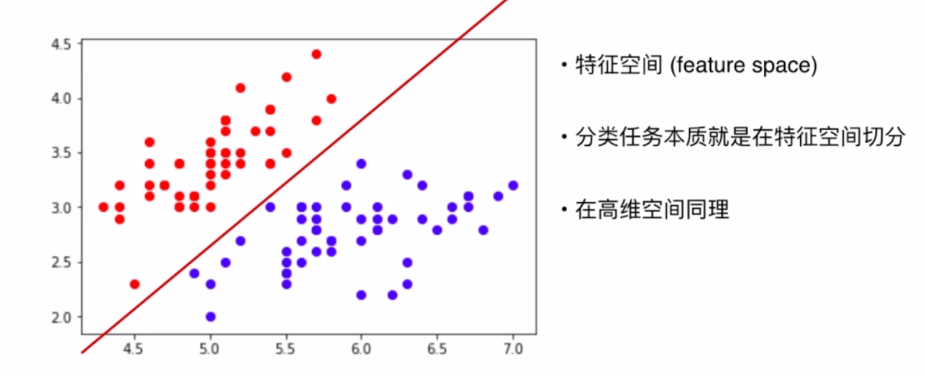
对于特征的获取
特征可以很抽象,甚至是来源于我们逻辑之外的
:::warning 在深度学习中,特征(权重)的获取是由BP算法在训练中不断矫正权重参数达成的 :::
机器学习的分类(性质列举)
从结果上机器学习算法的典型举例
进行以下分类任务和回归任务的绝大多数算法属于监督学习
分类任务
多分类任务
识别动物类型,人脸识别,文字识别,自动驾驶,风险评级,训练玩简单游戏的AI
二分类任务
注意
 非监督学习
非监督学习
训练的数据没有任何标记或者答案(待续)
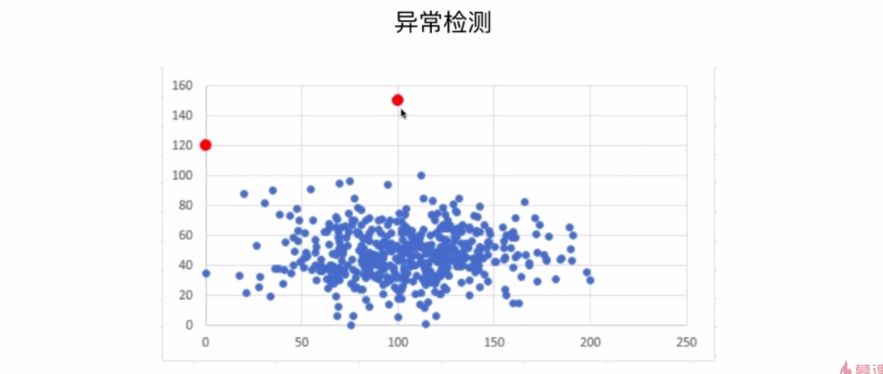
非监督学习可以剔除数据中的异常点
半监督学习
一部分数据集有对应的答案/标记,但是另一部分没有,这种数据大多数是直接来源于生活中的原始数据。![QB15C)}$39PA2E%10]O@}18.png](/uploads/projects/u26765122@ul70is/d8344fb64a160798be0b14f8db472d30.png)
从方法特性上机器学习算法的典型举例
增强学习
及时得到反馈并改变行动方式的学习
![)DSP{LCX[IEF]9WBM3TI{]Y.png](/uploads/projects/u26765122@ul70is/942eb8ebbcdc01339270619774d4e24f.png)
批量学习和在线学习
批量学习
输入大量已经收集到的数据来训练模型,模型训练成功后即可投入使用(样例不再改变模型)![NSTPNEZ{}9YC5@{YN0P`]K9.png](/uploads/projects/u26765122@ul70is/9f25fec4569240817ad50ed7fbb6d847.png)
优点:成型快,效率高
缺点:难以与时俱进,时效性和可塑性不高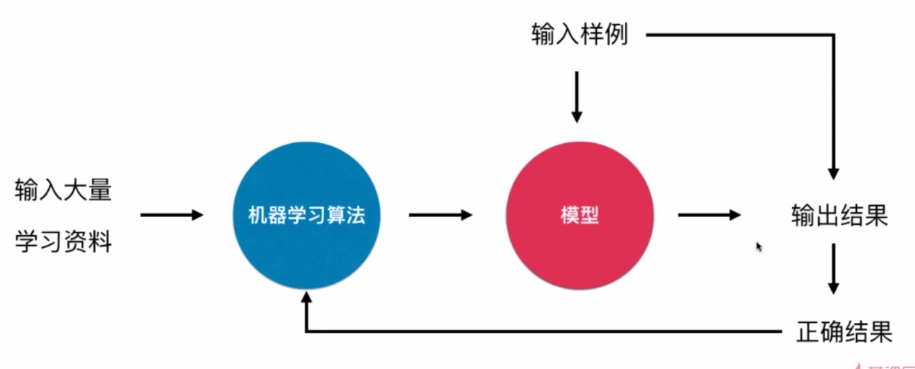
![]DNCFU(S8KOM_V8LCPJ30H4.png](/uploads/projects/u26765122@ul70is/7ac2134cc9c11215436677d3a28f1315.png)
可用非监督学习进行异常数据排除
参数学习和非参数学习
参数学习
数据集经过算法的学习,获得了拟合于数据集的算法中的参数,那么这个数据集就可以不再利用,转而利用更简洁的参数

非参数学习
 注意:这里指的是该算法用于所有的问题,而在特定的问题中,不同的算法表现不一样,所有算法没有绝对的优劣之分
注意:这里指的是该算法用于所有的问题,而在特定的问题中,不同的算法表现不一样,所有算法没有绝对的优劣之分![F_O~[_QDU%T6]EREUG_EOMJ.png](/uploads/projects/u26765122@ul70is/2165eb6dd177f920fc3f72f61a45166c.png)
对于机器学习的预测结果的看待:根据已经确定等事实所得出的数据对未来进行预测,本就是具有不确定性的,机器学习更像是远超所有人类记忆力和判断力的产物,对世界进行逆向工程或者是黑盒预测。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}