并发模型 参考文档
Go语言是为并发而生的语言,Go语言是为数不多的在语言层面实现并发的语言;也正是Go语言的并发特性,吸引了全球无数的开发者。
Go实现了两种并发形式。第一种是大家普遍认知的:多线程共享内存。其实就是Java或者C++等语言中的多线程开发。另外一种是Go语言特有的,也是Go语言推荐的:CSP(communicating sequential processes)并发模型。
CSP并发模型是在1970年左右提出的概念,属于比较新的概念,不同于传统的多线程通过共享内存来通信,CSP讲究的是“以通信的方式来共享内存”。
请记住下面这句话:
Do not communicate by sharing memory; instead, share memory by communicating.
“不要以共享内存的方式来通信,相反,要通过通信来共享内存。”
Go的CSP并发模型,是通过goroutine和channel来实现的。
goroutine 是Go语言中并发的执行单位。有点抽象,其实就是和传统概念上的”线程“类似,可以理解为”协程“。
channel是Go语言中各个并发结构体(goroutine)之前的通信机制。 通俗的讲,就是各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
生成一个goroutine的方式非常的简单:Go一下,就生成了。
| 1 | go f(); |
|---|---|
通信机制channel也很方便,传数据用channel <- data,取数据用<-channel。
在通信过程中,传数据channel <- data和取数据<-channel必然会成对出现,因为这边传,那边取,两个goroutine之间才会实现通信。
而且不管传还是取,必阻塞,直到另外的goroutine传或者取为止。
有两个goroutine,其中一个发起了向channel中发起了传值操作。(goroutine为矩形,channel为箭头)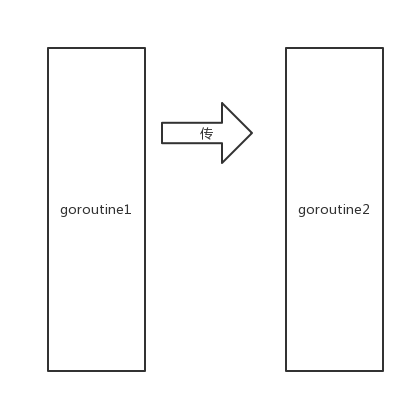
左边的goroutine开始阻塞,等待有人接收。
这时候,右边的goroutine发起了接收操作。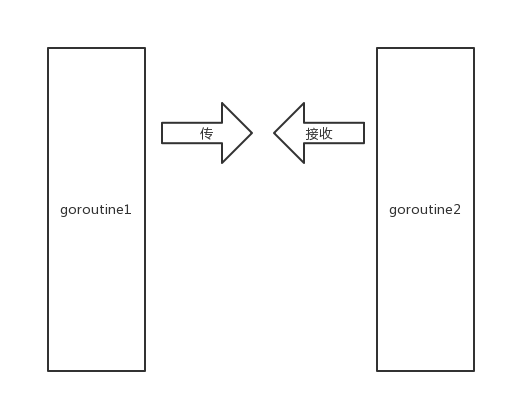
右边的goroutine也开始阻塞,等待别人传送。
这时候,两边goroutine都发现了对方,于是两个goroutine开始一传,一收。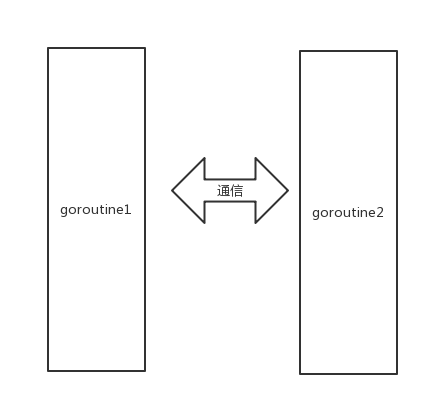
这便是Golang CSP并发模型最基本的形式。
Go线程实现模型MPG
M指的是Machine,一个M直接关联了一个内核线程。P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。G指的是Goroutine,其实本质上也是一种轻量级的线程。
三者关系如下图所示: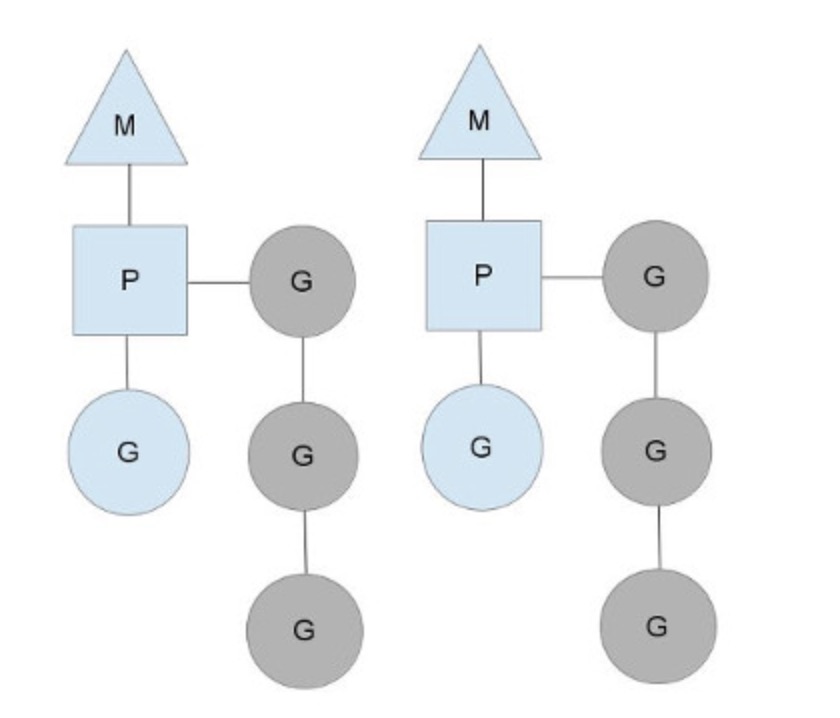
以上这个图讲的是两个线程(内核线程)的情况。一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。P(Processor)的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数runtime.GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有固定数量的线程在运行go代码。Goroutine中就是我们要执行并发的代码。图中P正在执行的Goroutine为蓝色的;处于待执行状态的Goroutine为灰色的,灰色的Goroutine形成了一个队列runqueues
三者关系的宏观的图为: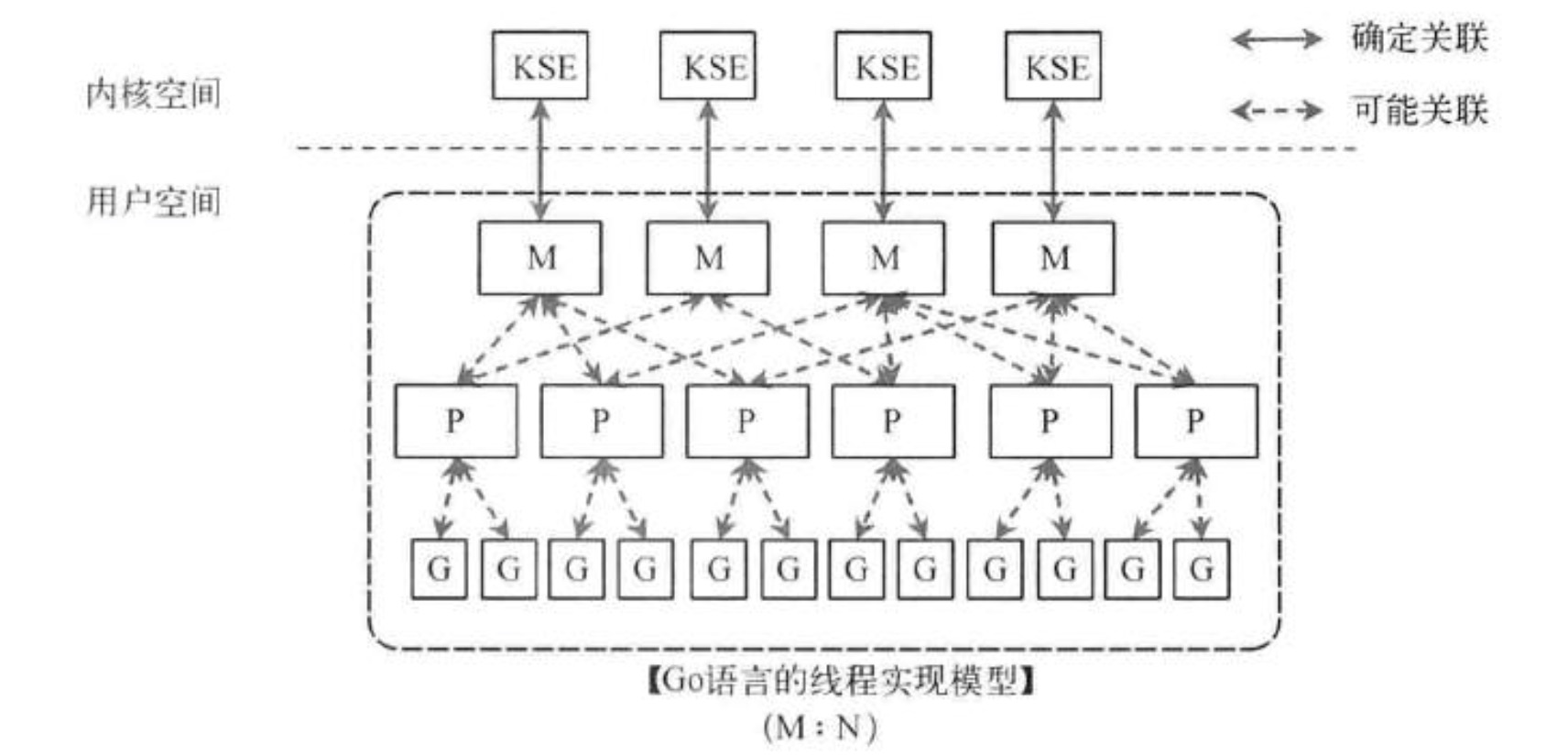
抛弃P(Processor)
你可能会想,为什么一定需要一个上下文,我们能不能直接除去上下文,让Goroutine的runqueues挂到M上呢?答案是不行,需要上下文的目的,是让我们可以直接放开其他线程,当遇到内核线程阻塞的时候。
一个很简单的例子就是系统调用sysall,一个线程肯定不能同时执行代码和系统调用被阻塞,这个时候,此线程M需要放弃当前的上下文环境P,以便可以让其他的Goroutine被调度执行。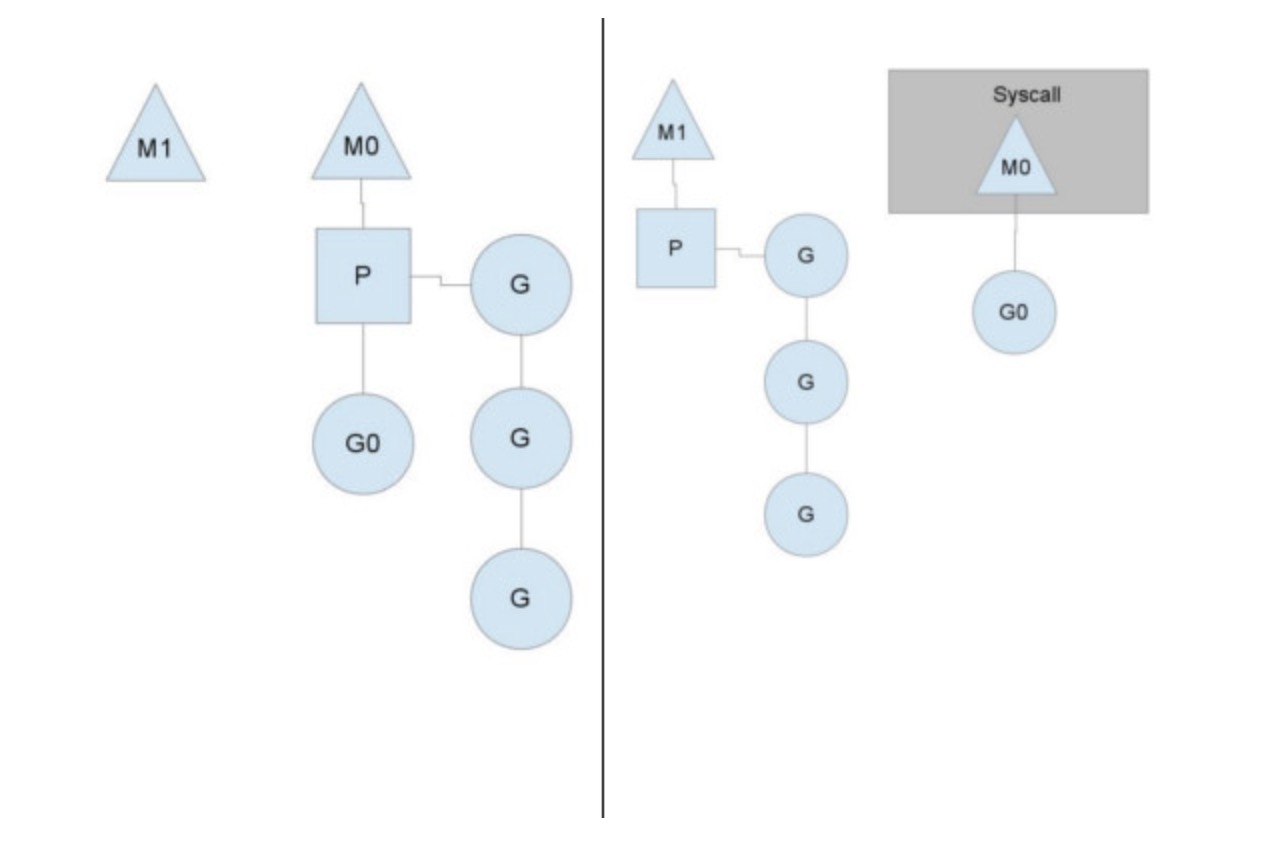
如上图左图所示,M0中的G0执行了syscall,然后就创建了一个M1(也有可能本身就存在,没创建),(转向右图)然后M0丢弃了P,等待syscall的返回值,M1接受了P,将·继续执行Goroutine队列中的其他Goroutine。
当系统调用syscall结束后,M0会“偷”一个上下文,如果不成功,M0就把它的Gouroutine G0放到一个全局的runqueue中,然后自己放到线程池或者转入休眠状态。全局runqueue是各个P在运行完自己的本地的Goroutine runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
均衡的分配工作
按照以上的说法,上下文P会定期的检查全局的goroutine 队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。
该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!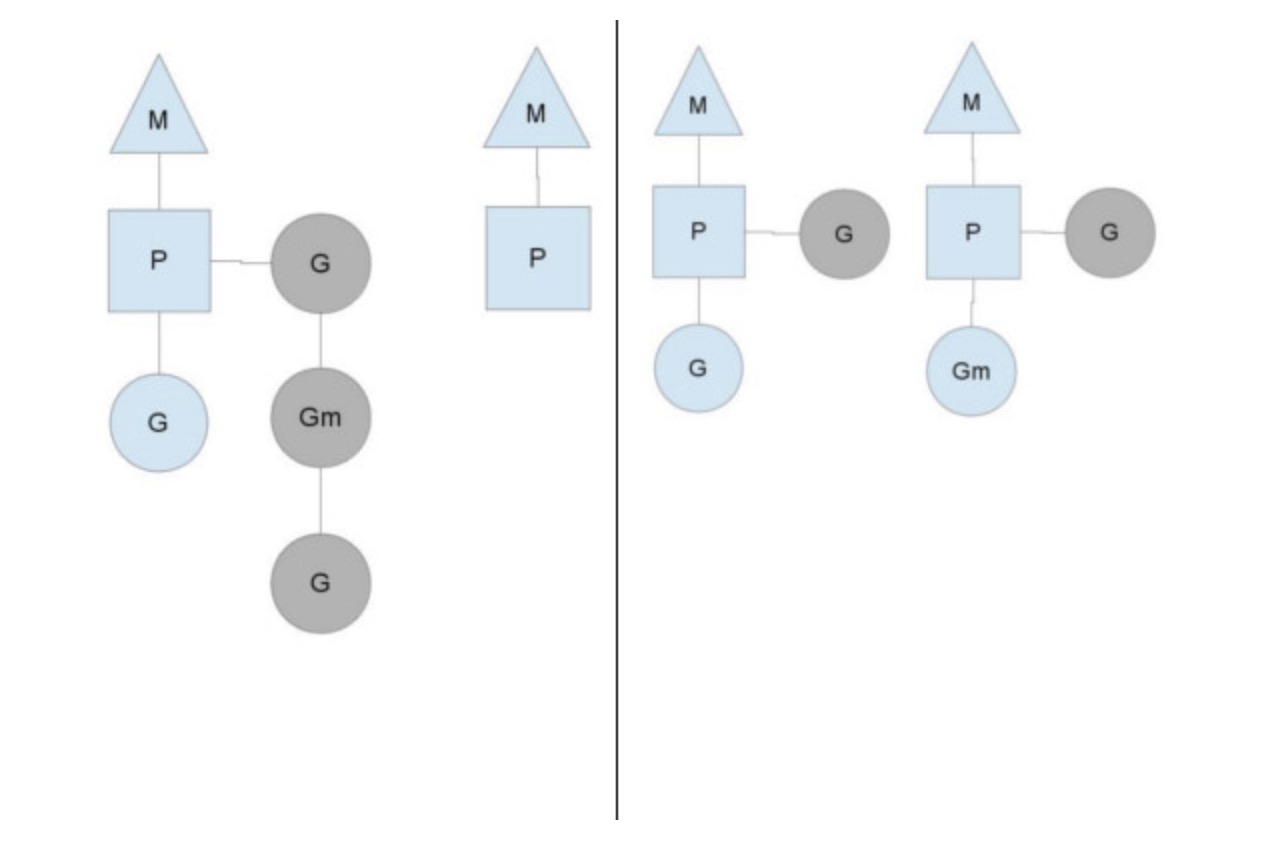
内存分配 参考文档
golang的内存采用了TCMalloc 这种分配机制
- 性能提升主要从两点来看,第一点线程内部小对象的使用不存在锁竞争,减少了竞争带来的性能开销; 第二点内存大对象的分配直接在堆上,并且采用了自旋锁,某个线程等待另一个线程释放锁的时候,不会像传统互斥锁一样由运行态转到休眠态,等待线程一会处于忙等待,减少了线程状态的切换。
- 在内存利用率方面,区分了线程、central、heap三级,线程之间有一个共享内存池(central 区)。当线程内部内存不足时,会向central申请,当不再使用时,归还到central区。每个线程都可以向central区申请和归还,充分利用了内存。central区内存不足时,跟heap申请,空闲时归还给heap。
1.1 内存块
go中的有两种内存块:span和object。span面向内部管理(可以是一种按照大小将内存页进行组织的形式),object面向内存分配。- span:由多个地址连续的页组成的大块内存
- object: 将span按照特定大小切分成多个小块,每个小块可存储一个对象。
分配对象时,大的对象直接从堆上分配,小的对象从 Span 中分配。

span跟page的关系: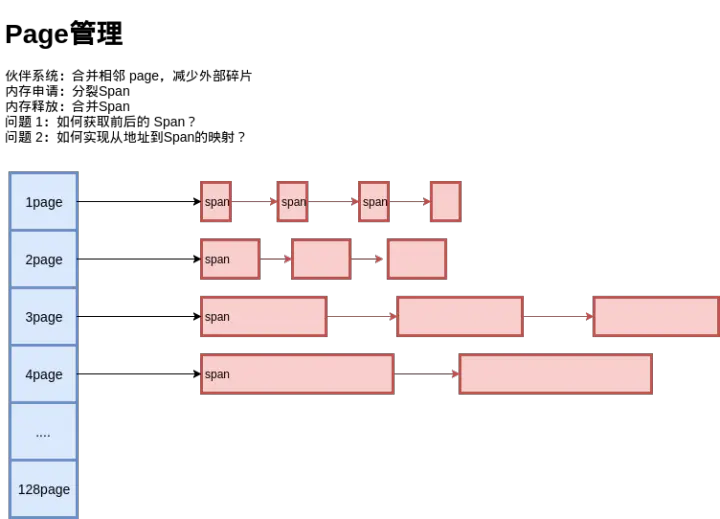
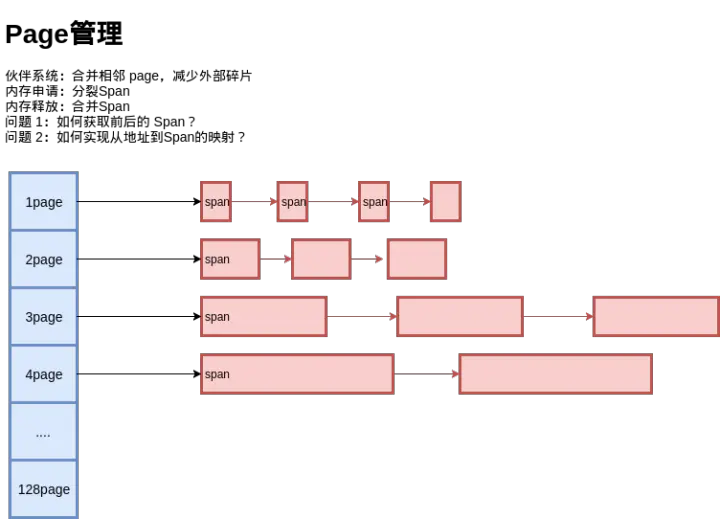
看一下span的定义哈:既包含起始页跟页数,又有object链表
type mspan struct {next *mspan //双向链表prev *mspanstart pageID //起始页号npages uintptr //页数freelist gclinkptr //待分配的object 链表。}
1.2 管理组件
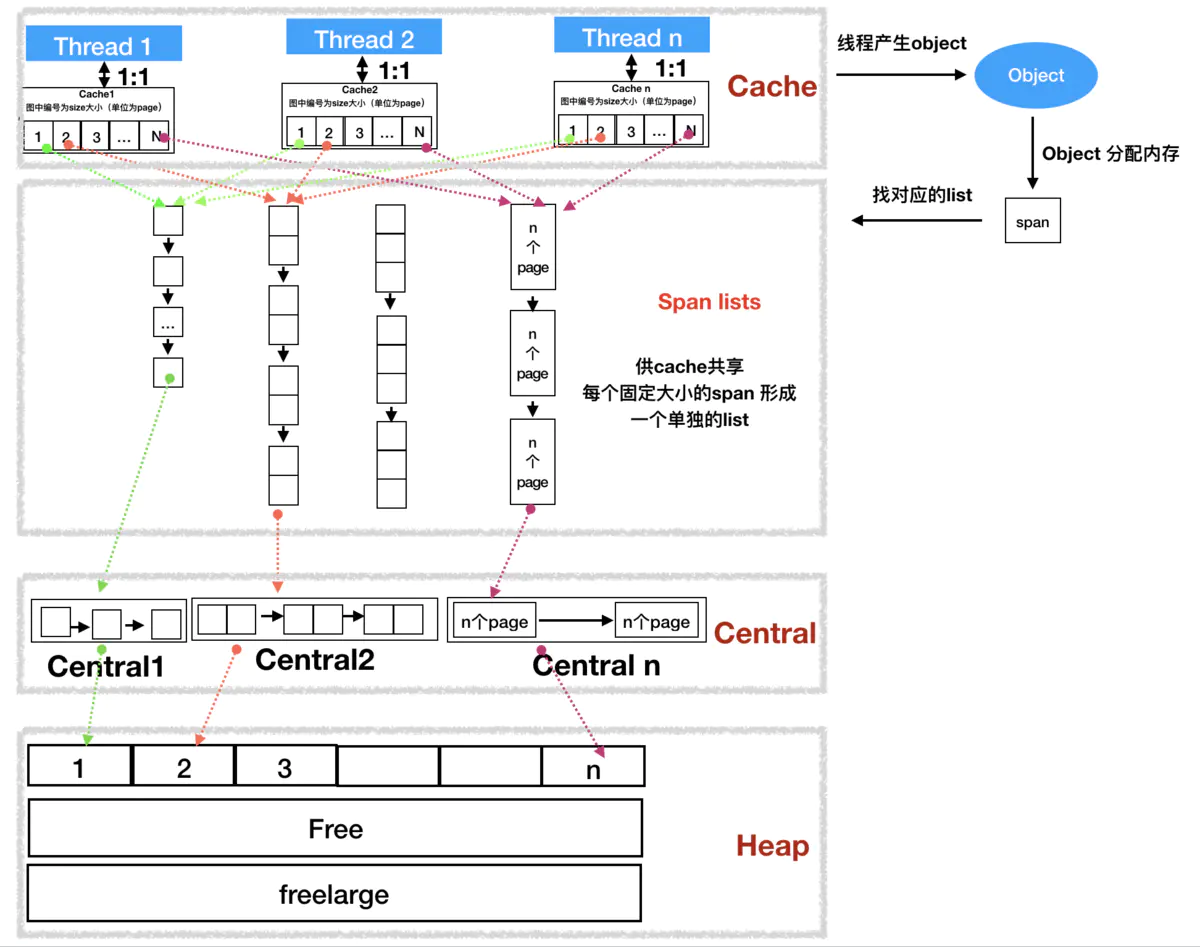
tcmalloc 分配器有三种管理组件:
- cache: 每个运行期工作线程都会有一个cache
- central:为所有cache提供切分好的后备span资源
- heap:管理闲置span,需要时向操作系统申请新内存
heap中包含一系列不同sizeclass的central,每个central中包含了对应大小的span列表,cache中 以sizeclass为索引管理多个用于分配的span。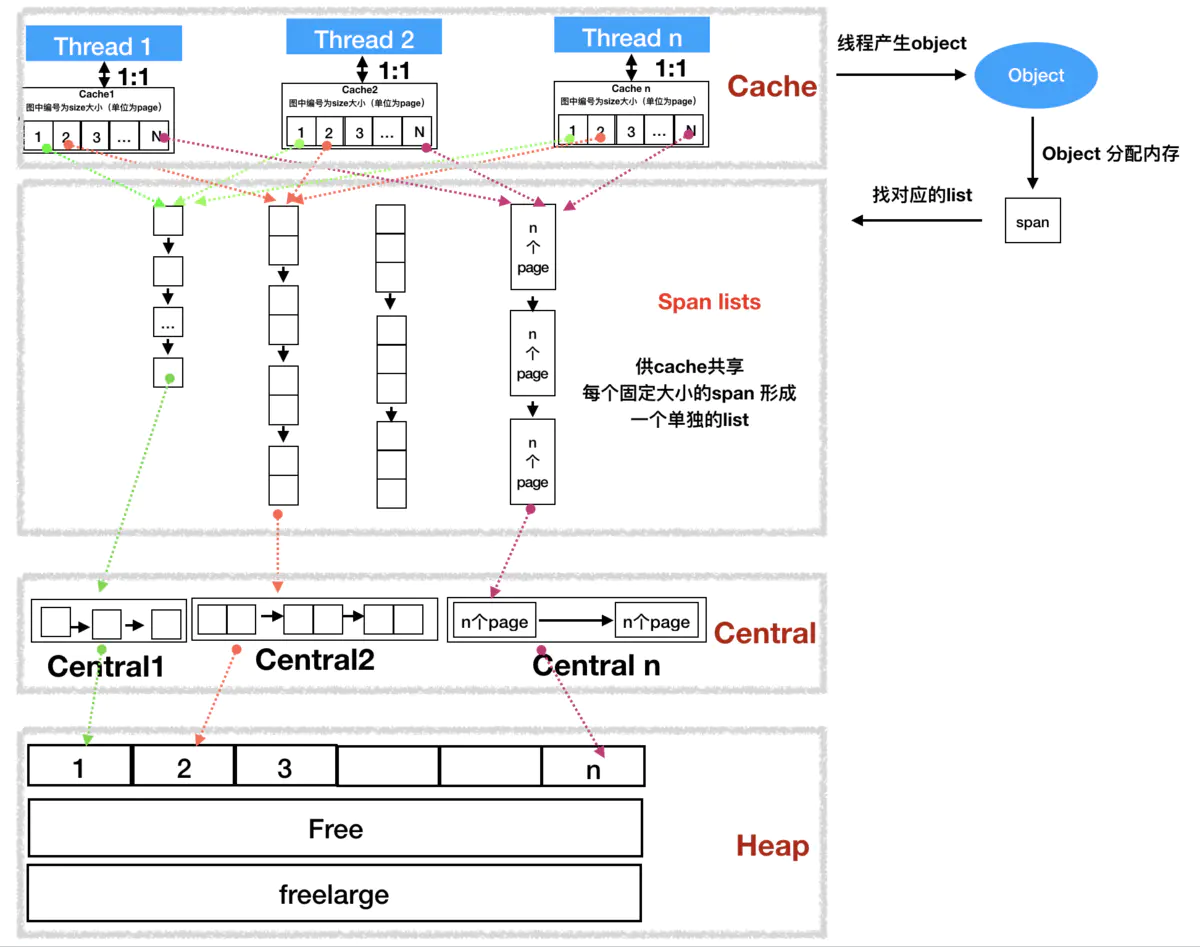
2 go初始化时,在内存这部分做了什么?
在初始化阶段,预留了一大段虚拟地址空间,分了三部分:
首先是用户内存分配区域,其大小决定了可分配用户内存的上限 其次有一个位图bitmap,其为每个对象提供4bit标记位,用于保留指针、GC标记等信息 最后还有一个页所属span指针数组
go 内存初始化做的工作主要有初始化上面的结构,然后为他们保留地址空间,然后初始化heap的一些其他属性。在初始化heap的时候,创建了多个不同大小的central。
3 TCMalloc 分配过程
3.1 TCMalloc分配
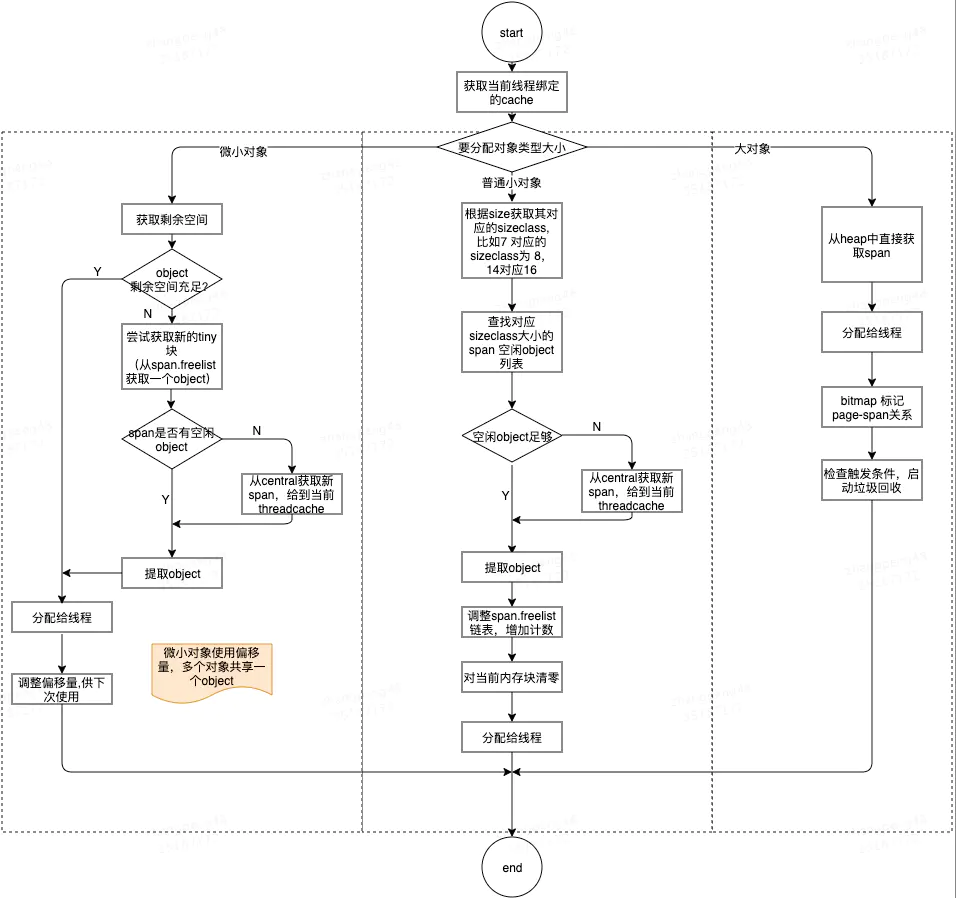
分析了整体的线程内存分配流程,那么当资源不足时如何扩张呢?
资源不足分两种,第一种是central不足,另一种是heap不足。下面我们从分配的角度,看一下这两种的流程是什么样子的?
3.2 central的分配
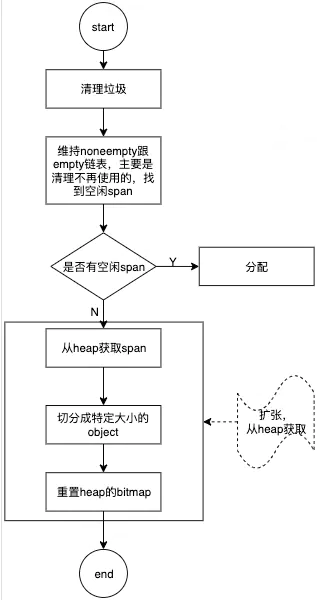
其中维持noneempty跟empty链表过程中涉及到了sweepgen,这个用于central 中span的清理。
从central 里获取span时,优先取用已有资源。哪怕是要执行清理操作,只有当现有资源不满足时才会去heap中获取span。
3.3 heap的分配
heap自己维护了两个链表,busy跟busylarge,顾名思义,就是按照大小区分的。
在分配时,当是小对象时,放在busy链表供central使用,大对象放在busylarge,放在busylarge链表。
- 为了避免浪费,当返回更大的span时,会将多余部分切出来重新放回heap链表。
- 同时,还会尝试合并相邻限制的span空间,减少碎片。
3.4 向操作系统申请分配
使用了mmap,从指定位置申请内存。需要同步扩张heap的 bitmap和spans区域,以及调整arena_used这个位置指示器。
3.5 总结一下分配过程
- 1 计算待分配对象对应的size class
- 2 从cache.alloc 找到对应规格相同的span
- 3 从span.freelist链表提取可用的object,如果span.freelist没有span可用,执行4
- 4 从central 获取新的span, 如果有,分配给cache使用;如果central也没有可用span,执行5
- 5 从heap获取span。如果heap有,则将span切分成对应大小的object,并将整个span给到central;如果heap也不足,则执行6
- 6 向操作系统申请。
4 TCMalloc 回收过程
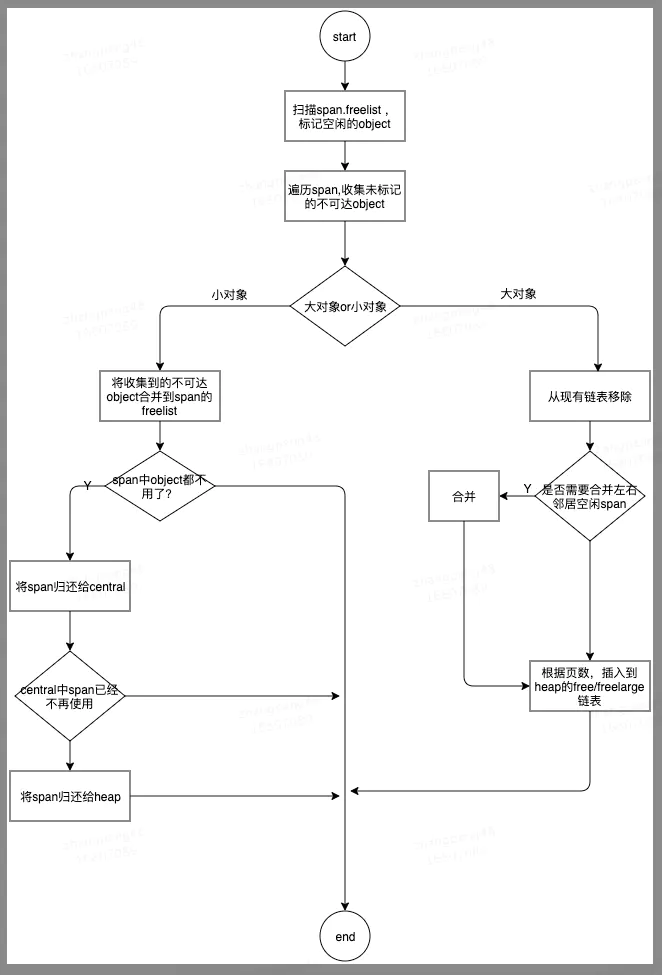
5 TCMalloc 释放
main启动时会启动一个监控任务sysmon,每隔一段时间就会检查heap中的闲置内存块,如果闲置时间超过阈值,则释放其关联的物理内存。
作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
垃圾回收
常见的垃圾回收方法:
- 引用计数:对每个对象维护一个引用计数,当引用该对象的对象被销毁时,引用计数减1,当引用计数器为0是回收该对象。
优点:对象可以很快的被回收,不会出现内存耗尽或达到某个阀值时才回收。
缺点:不能很好的处理循环引用,而且实时维护引用计数,有也一定的代价。
代表语言:Python、PHP - 标记-清除:从根变量开始遍历所有引用的对象,引用的对象标记为”被引用”,没有被标记的进行回收。
优点:解决了引用计数的缺点。
缺点:需要STW,即要暂时停掉程序运行。
代表语言:Golang(其采用三色标记法) - 分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,而短的放入新生代,不同代有不同的回收算法和回收频率。
优点:回收性能好
缺点:实现复杂
代表语言: JAVAroot
首先标记root根对象,根对象的子对象也是存活的。
根对象包括:全局变量,各个stack上的变量等。三色标记
白, 灰, 黑. 白色节点表示未被mark和scan的对象, 灰色节点表示已经被mark, 但是还没有scan的对象, 而黑色表示已经mark和scan完的对象。
灰色:对象已被标记,但这个对象包含的子对象未标记
黑色:对象已被标记,且这个对象包含的子对象也已标记
白色:对象未被标记GC步骤
- 初始状态下所有对象都是白色的。
- 首先标记root对象为灰色,放入待处理队列。
- 取出待处理队列的灰色对象,将其引用标记为灰色,放入待处理队列,并将本身标记为黑色.
循环第三步,直到待处理队列为空(在标记过程中的新的引用对象,通过写屏障直接标记为灰色),此时剩下的只有白色和黑色,白色对象则表示不可达,将其清理.
触发GC的机制
在申请内存的时候,检查当前当前已分配的内存是否大于上次GC后的内存的2倍(可配置GOGC参数,即百分比,默认是100,所以为两倍),若是则触发.(如第一次是内存占用10m触发GC,第二次会是20m,第三次40m….[或许有误])
- 监控线程发现上次GC的时间已经超过两分钟了,触发
- 手动:runtime.gc()/ free()
静态链接
golang 的编译(不涉及 cgo 编译的前提下)默认使用了静态编译,不依赖任何动态链接库。
可以任意部署到各种运行环境,不用担心依赖库的版本问题。只是体积大一点而已,存储时占用了一点磁盘,运行时,多占用了一点内存。早期动态链接库的产生,是因为早期的系统的内存资源十分宝贵,由于内存紧张的问题在早期的系统中显得更加突出,因此人们首先想到的是要解决内存使用效率不高这一问题,于是便提出了动态装入的思想。也就产生了动态链接库。在现在的计算机里,操作系统的硬盘内存更大了,尤其是服务器,32G、64G 的内存都是最基本的。可以不用为了节省几百 KB 或者1M,几 M 的内存而大大费周折了。而 golang 就采用这种做法,可以避免各种 so 动态链接库依赖的问题,这点是非常值得称赞的。
标准库
工具链

若有收获,就点个赞吧
0 人点赞
