| 创建时间: | 2019/10/16 21:09 |
|---|---|
| 作者: | sunpengwei1992@aliyun.com |
我们经常接触的冒泡排序,快速排序,归并排序等,这些排序时间复杂度大多是n^2或者N(logN),他们都是基于比较的排序(就是排序过程中数据两两做比较),那你有知道和了解几种线性排序的算法吗?他们的时间复杂度都是O(n),下面的几个问题你会了吗?
问题
- 1000万订单数据金额如何O(n)复杂度排序?
- 100万考生成绩如何O(n)复杂度秒级排序?
- 100个手机号如何从小到达O(n)复杂度排序?
常见的线性排序
桶排序
桶排序,顾名思义就是把要排序的元素放入各个桶中,然后每个桶中的元素再进行排序,这样最后所有桶中的元素按桶的顺序排列,则所有元素有序,我们假设n个元素,m个桶,那么每个桶中放入(n/m=k)个元素,每个桶中元素的排序可以用之前我们分享过的快速排序,则桶排序的时间复杂度是m k(logk),我们把k用n/m进行等价替换,所以时间复杂度就编程了 n log(n/m),当m非常接近n时,那么桶排序的时间复杂度就是O(n)了。
1000万订单数据金额排序答疑:
我们来看上面1000万订单数据金额排序的问题,假设我们只有10M内存,我们首先遍历一遍文件,得出金额的最大值,假设最大值50000,也就是说1000万订单数据金额最小值是0,最大值是50000,那么我们对0到50000的金额大小划分1000个桶,把0到50的金额第一个桶,50到100的金额放入第二个桶,以此类推,然后对每个桶的数据进行排序,之后写入磁盘文件,命名为bucket_0_50.txt,以此类推,直到所有桶的数据都排序完毕,排序过程中,当某一个桶的数据过大,10M内存放不下时,可以用同样的思想进行拆分为多个桶,用下面的图描述一个这个过程。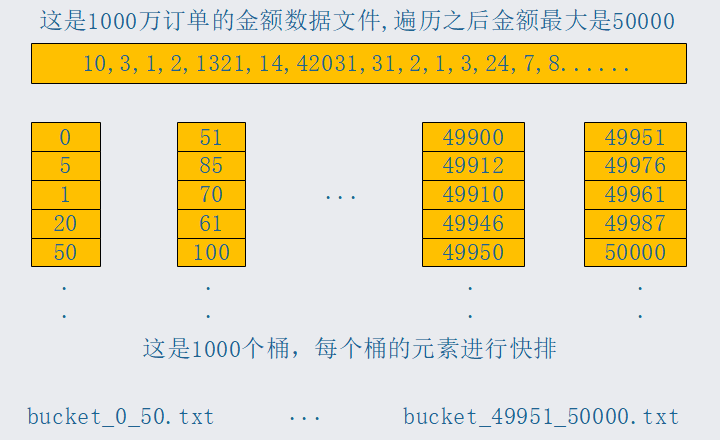
桶排序的示例代码://对数组array进行桶排序func BucketSort(array []int){max := 0 //选出最大值for i:=0; i<len(array);i++{if array[i] > max {max = array[i]}}k := 10 //每个桶放入的元素的范围m := max / k + 1 //计算桶的个数//创建buckets数组buckets := make([][]int,m)for j:=0;i<len(array);j++{//获取所在桶的下标bucket_index := array[j] / 10if(buckets[bucket_index] == nil){temp := make([]int,10)temp = append(temp,array[j])buckets[bucket_index] = temp}else{buckets[bucket_index] = append(buckets[bucket_index],array[j])}}//对每个桶的数组进行快速排序for _,v :=range buckets{QuickSort(v)}}
计数排序
计数排序跟上面的桶排序非常的类似,我们提到上面每个桶放入的元素是(k=n/m),假设这个k=1,那么相当于每个桶的元素就只有一个,试想一下,我们是不是只要遍历原始数据,就相当于排序完成。
分析下100万考生成绩O(n)复杂度秒级排序
100万考生,看着数据量很大,但我们透过现像看本质,这些数据的最大值是多少呢?750,是的,高考成绩最大值750,最小值0,也就是说我我们只需要751个桶,我们声明一个长度为751的数组,代表751个桶,数组的下标就是考生的成绩,然后我们100万数据遍历,数组的值是这个成绩出现的次数,当100万数据遍历完成后,我们遍历我们创建的这个桶,根据数组中的值确定打印数组下标的次数,结果就是这100考生成绩的排序。我们看代码实现。
我们看下边的图,就能理解上面代码的逻辑了//max 是数组的最大值func CountSort(array []int, max int){bucket := make([]int,max+1)for i:=0;i<len(array);i++{//统计每个元素出现的次数bucket[array[i]]++}result := make([]int)//将bucket中的下标根据值写入result中for i:=0;i<len(bucket);i++{for j:=0;j<bucket[i];j++{result = append(result,i)}}}
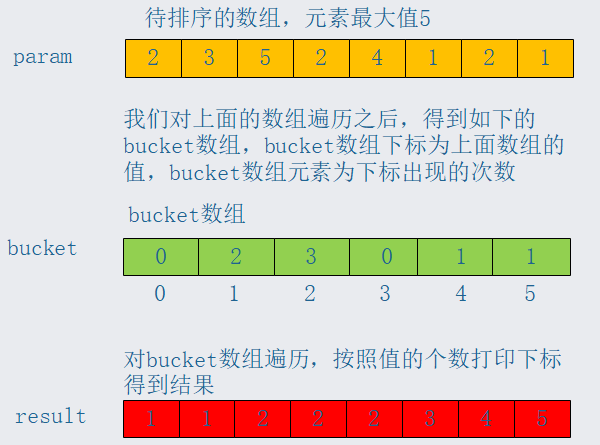
那么为什么要叫做计数排序呢?如果我想知道上图中result结果中值为2元素的在下标什么位置?该怎么获取呢?你有好的想法吗
首先我们对上图中的bucket的数组顺序求和,得到如下
我们从后往前依次遍历数组param中的元素,当遍历到1时,我我们从求和后的bucket数组中获取下标为1的元素2,也就说到现在为止,包含自己在内的小于等于1的元素只有2个,也就是说1是数组result中的第二个元素,这时小于等于1的元素就只剩1个了,当我们遍历完数组param,得到的结果就是排列有序的了。基数排序
基数排序属于分配时排序,又称桶子法,也用到了桶的概念,将待排序的元素局部进行排序分配至桶中,依次循环,直到排序完成。
上面的问题中有100个11位手机号进行从小到达排序
为了方便,我这里举例使用3个手机号,手机号码如下,我们从后往前依次遍历手机号的每一位,手机号由从数字组成,最小0,最大9,我们一个桶,桶的大小是10。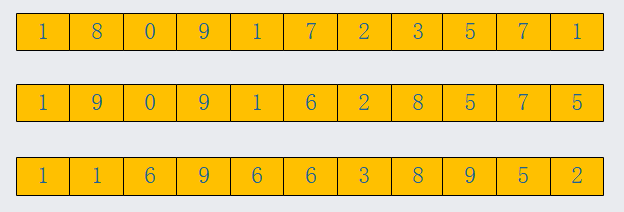
第一次遍历,三个手机号末尾是1,5,2;放入我们的桶中,那么手机号的顺序就变化为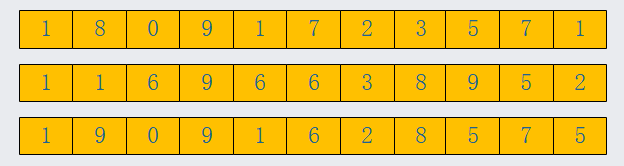
第二次遍历,三个手机号的倒数第二位是7,5,7;放入我们的桶中,手机号顺序变化为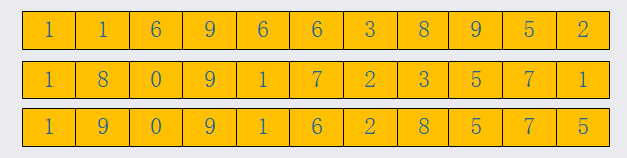
以此类推,如下图比较方方式,每一次比较都会对手机号的排序做一个调整,最终手机号
所有位数都比较完成,排序也就完成,但这里有个需要注意的点,看上面我们第二次遍历时,有两个手机号末尾都是7,这是我们需要用到稳定排序,目的为了防止第一次排好序的最后以为发生了错乱,就是保证7后面的最后一位1,5也是有序的。
我们用到代码来实现基数排序的算法func RadixSort(phones []string) {//手机号最小0,最大9,创建一个大小为10的bucket// 为什么是二维呢,因为手机号某一位可能有多个一样的bucket := make([][]string, 10)//对手机号遍历11次,因为手机号长度为11位for index := 10; index >= 0; index-- {for _, v := range phones {if bucket[v[index]-48] == nil { //把手机号根据末尾顺序放入bucket中temp := make([]string, 0)temp = append(temp, v)bucket[v[index]-48] = temp} else {bucket[v[index]-48] = append(bucket[v[index]-48], v)}}i := 0 //phones下标for k, v := range bucket {if v != nil {//根据bucket中的下标phones重新排序for _, p := range v {phones[i] = p;i++}bucket[k] = nil //重置bucket}}}}
应用场景
我们由三个问题引出了三种线性排序,这三种线性排序都有自己的特定应用场景,并不是说任何时候都能使用这三种线性排序,我们一块总结一下这三种排序的应用场景。
桶排序:是一种外部排序,适用于数据量比较均匀,数据范围不是很大的排序数据。
计数排序:适用于待排序的数据最大值不是很大情况的下,比如最大值是100000,就不可以了,这样浪费空间太严重,然后排序数据都是正整数,如果不是,就要想办法转换成正整数。
基数排序:适用于那种有高低位的数据,且数据的长度都一样,如果不一样,看看是否能够补全长度,再者,数据每一位的大小都不宜太大,因为数据也是放入桶中的,太大回过多浪费空间。三种排序你都明白了吗?欢迎留言区讨论
欢迎大家关注微信公众号:“golang那点事”,更多精彩期待你的到来

若有收获,就点个赞吧
0 人点赞
