| 创建时间: | 2019/10/8 20:48 |
|---|---|
| 作者: | sunpengwei1992@aliyun.com |
思考一下,归并排序适合哪些场景?哪里有用到归并排序
归并排序是一种分治思想的应用,所以也适合处理大数量的排序,因此也是一种外排序算法,磁盘排序算法,应用场景也较多,比如mysql的排序,sharding-jdbc的排序,
- 下面文字是shardding-jdbc官网的一段描述,官网地址如下,友情提示:官网左边导航栏最下方支持中英文语言切换哦
归并排序,由于在SQL中存在ORDER BY语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。 这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/merge/
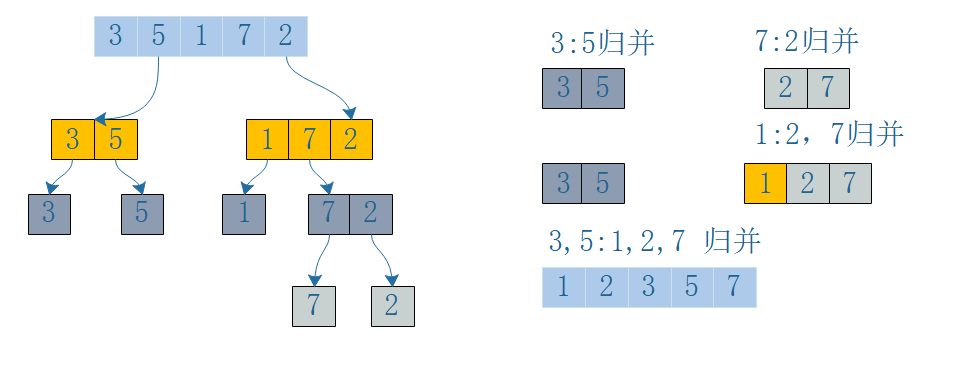
该算法是将已有的子序列不断进行合并从而最终达到全局有序,一般我们的实现都是二路归并,就是两个有序的子序列进行合并,但也可以进行多路归并(将大于两个的子序列进行合并)我们通过一个简单的归并排序(递归)来分析时间,空间复杂度
我们分析上面的代码,看看归并排序的复杂度怎么样呢,首先递归的终止条件必须确定,就是数组大小小于等于1时,递归终止,我们不断通过对待排序的数据array进行折中,从而达到最终二路归并时left,right的数组大小都是1,我们看下图,方便大家理解递归和归并,由图得知,我们每次对数组拆分都是一分为二的才做,比如数组长度为4,拆分到最后为1时就是4/2/2的操作,所以递归拆分的时间复杂度是logN(以2为底),在归并时是对两个有序的序列开始做合并,递归了n次,所以要合并n次,但每次合并时遍历子序列,假设子序列长度为n,所以整体时间复杂度为nlogN,每次合并时申请新的空间存储合并后的有序数组返回,所以空间复杂度为O(n),func MergeSort(array []int)[]int{if len(array) <= 1{return}middle := len(array) / 2//不断缩小待排序的数组的范围大小left := MergeSort(array[:middle])right := MergeSort(array[middle:])//开始二路归并return merge(left,right)}func merge(left,right []int) (result []int){l,r := 0,0for l < len(left) && r < len(right){if left[l] < right[r]{result = append(result,left[l])l++continue}if left[l] > right[r]{result = append(result,right[r])r++continue}result = append(result,left[l])result = append(result,right[r])l++r++}for l < len(left){result = append(result,left[l])l++}for r < len(right){result = append(result,right[r])r++}return result}
利用数求递归的复杂度,这是一种简单思想,现在,我们需要知道这棵树的高度 h,用高度 h 乘以每一层的时间消耗 n,就可以得到总的时间复杂度n * h,而满二叉树的高度是log2(n),所以时间复杂度一目了然。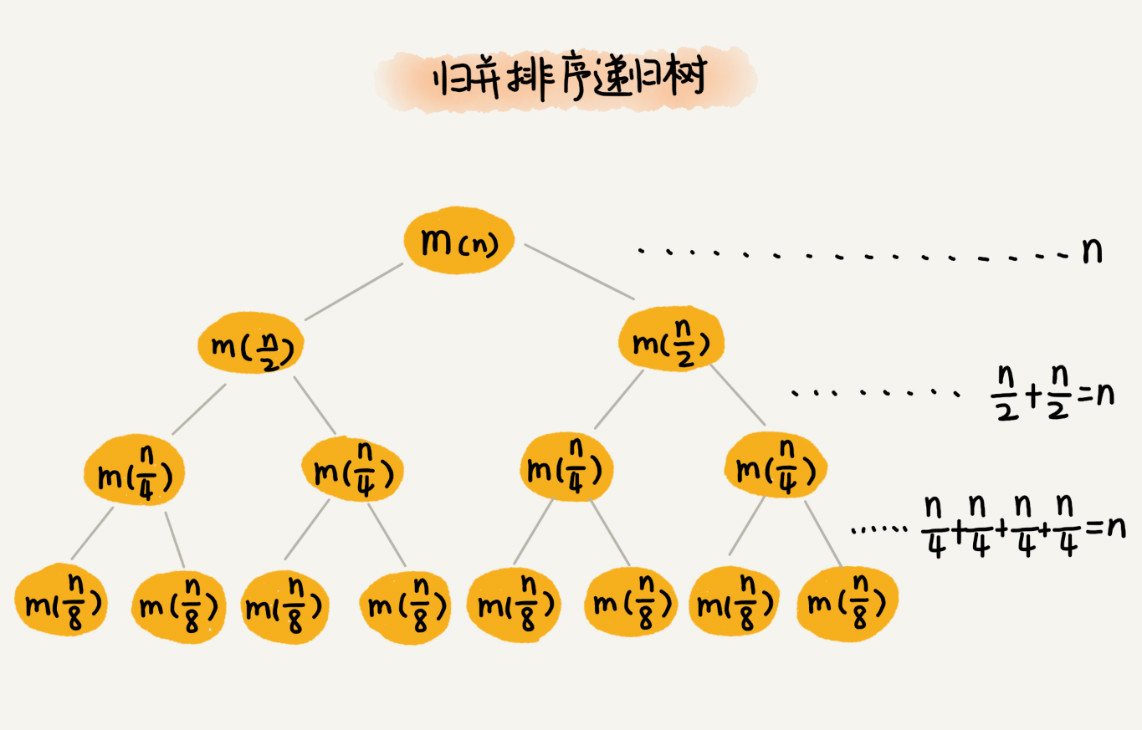
复杂度总结
时间复杂度:nlog2(n)
空间复杂度:O(n)除了递归实现,你能想到非递归怎么实现吗?
非递归实现二路归并排序
一般非递归代替递归,递归其实利用了操作系统的栈空间存储临时数据,所以两种方案,一是利用栈数据结构,二是利用变量(这种相对局限一点)
func MergerSortNotRecursion(array []int) []int {length := len(array)if length <= 1 {return array}i := 1 // 子序列大小result := make([]int, 0)for i < length {j := 0//按顺序两两归并,j用来定位起始点//随着系序列大小翻倍,每次两两归并的数组大小也在翻倍for j < length {if j+2*i > length {result = merge(array[j:j+i], array[j+i:length])index := jfor _, v := range result {array[index] = vindex++}} else {result = merge(array[j:j+i], array[j+i:j+2*i])index := jfor _, v := range result {array[index] = vindex++}}j = j + 2*i}i = i << 1 // 子序列大小翻倍}return array}
分析一下上面的代码的时间复杂度还是nlog2(n)吗? 答案是是的,自己分析一下哦
磁盘文件归并排序(也就是经常说的1亿数据,10M内存,请排序)
核心思路(多路排序)
- 每次读取一定量的数据(10M内存能放下),排序后单独写入小文件,直到大文件全部排完序写入很多(不再是两个,所以多路排序)个小文件,这时所有小文件中的数据是有序的
- 所有小文件中的数据每次读取一个做归并排序写入最终的结果文件中,直到所有小文件都处理完成
不多说,贴代码,看代码说事
//读取大文件排序写入临时文件func RedFileSortWriteTempFile(fileName string) {file, _ := os.Open(fileName)bufio := bufio.NewReader(file)//按行读取bs, _, _ := bufio.ReadLine()array := make([]int, 0, 0)suffix := 1for len(bs) > 0 {//NUMBER_TO_SORT,最多读取这么多个数据if len(array) == NUMBER_TO_SORT {//排序array = QuickSort2(array)// 写入文件WriteTempFile(array, suffix)//重新创建数组array = make([]int, 0)suffix++}number, _ := strconv.Atoi(string(bs))array = append(array, number)bs, _, _ = bufio.ReadLine()}//对最后不足最多个数的数组排序,写入文件array = QuickSort2(array)WriteTempFile(array, suffix)//对各个小文件开始归并排序MergerSortFile("E://temp/")defer file.Close()}
//多个已经排好序的小文件合并排序,入参是小文件的父级目录func MergerSortFile(childFilePath string) {//最终生成的排序文件sortFile, _ := os.Create("E://finally_number_sort.txt")sortFileBufio := bufio.NewWriter(sortFile)//读取排好序的小文件数组fileInfos, _ := ioutil.ReadDir(childFilePath)if len(fileInfos) == 0 {return}//用来存放每个小文件的最小值minArray := make([]int, len(fileInfos))fileArray := make([]*os.File, len(fileInfos))//每个小文件的bufio指针fileBufio := make([]*bufio.Reader, len(fileInfos))//用来标识小文件是否读到末尾isEnd := make([]bool, len(fileInfos))for index, fileInfo := range fileInfos {file, _ := os.Open("E://temp/" + fileInfo.Name())fileArray[index] = filefileBufio[index] = bufio.NewReader(file)}startSort(fileArray,minArray,isEnd,sortFileBufio,sortFile)}
//开始排序func startSort(fileArray []*os.File,minArray []int,isEnd []bool,sortFileBufio *bufio.Writer,sortFile *os.File,fileBufio []*bufio.Reader){for {flag := truefor i := 0; i < len(fileArray); i++ {if !isEnd[i] && minArray[i] == 0 {bs, _, _ := fileBufio[i].ReadLine()if len(bs) == 0 {isEnd[i] = true}value, _ := strconv.Atoi(string(bs))minArray[i] = value}}//找出多个小文件的最小值的最小值minValue := GetMin(minArray)//写入最终文件中if minValue != 0 {sortFileBufio.WriteString(strconv.Itoa(minValue) + "\r\n")sortFileBufio.Flush()}//判断所有文件是否读取完毕for _, temp := range isEnd {if !temp {flag = false; break;}}//如果完毕,终止循环if flag {break}}//关闭流defer func() {sortFile.Close()for _, f := range fileArray {f.Close()}}()}
//获取最小值func GetMin(array []int) int {index := 0min := array[0]for k, value := range array {if min > value && value != 0 {min = valueindex = k}}array[index] = 0return min}
欢迎大家关注微信公众号:“golang那点事”,更多精彩期待你的到来

若有收获,就点个赞吧
0 人点赞
