1.事务机制
开启事务 : multi
添加命令
执行事务: exec
取消事务:discard (添加命令后不想执行)
事务处理机制
Redis对于命令执行错误处理,有两种解决方式:
语法错误(编译):执行命令的语法不正确
执行直接报错,正确的命令也不会执行
执行错误(运行):命令在运行过程中出现错误
错误的命令不执行,争取的命令能够正常执行
2.持久化机制
Redis将数据保存在内存中。一旦服务器宕机重启,内存中的数据就会丢失。当出现这种情况后,为了能够让Redis进行数据恢复,因此Redis提供了持久化机制,将内存中的数据保存到磁盘中,避免数据意外丢失。
Redis提供了两种持久化机制:RDB、AOF。 根据不同的场景,可以选择只使用其中一种或一起使用。
RDB快照:RDB(Redis DataBase)是Redis默认存储方式。其基于快照思想,当符合一定条件(手动或自动触发)时,Redis会将这一刻的内存数据进行快照并保存在磁盘上,产生一个经过压缩的二进制文件,文件后缀名.rdb。
触发条件:在redis.conf文件中配置了一些默认触发机制
save "" # 不使用RDB存储 不能主从# 记忆save 3600 1 #表示1小时内至少1个键被更改则进行快照。save 300 100 #表示5分钟(300秒)内至少100个键被更改则进行快照。save 60 10000 #表示1分钟内至少10000个键被更改则进行快照。
在redis客户端执行save或bgsave命令,手动触发RDB快照。
#进入客户端
bin/redis-cli
#执行save命令(同步执行)
save #同步处理,阻塞Redis服务进程,服务器不会处理任何命令,直到RDB文件保存完毕。
#执行bgsave命令(异步子线程执行)
bgsave #会fork一个和主线程一致的子线程负责操作RDB文件,不会阻塞Redis服务进程,操作RDB文件的同时仍然可以处理命令。
# Redis默认使用的是 bgsave 来保存快照数据。
执行过程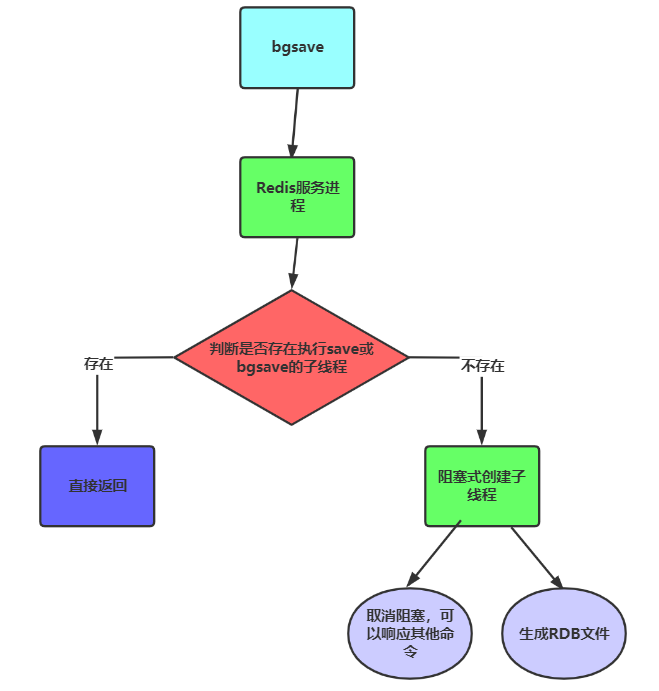
1)Redis服务进程判断,当前是否有子线程在执行save或bgsave。
2)如果有,则直接返回,不做任何处理。
3)如果没有,则以阻塞式创建子线程,在创建子线程期间,Redis不处理任何命令。
4)创建完子线程后,取消阻塞,Redis服务继续响应其他命令。
5)同时基于子线程操作RDB文件,将此刻数据保存到磁盘。
优缺点:
优点:
- 基于二进制文件完成数据备份,占用空间少,便于文件传输。
- 能够自定义规则,根据Redis繁忙状态进行数据备份。
缺点:
- 无法保证数据完整性,会丢失最后一次快照后的所有数据。
- bgsave执行每次执行都会阻塞Redis服务进程创建子线程,频繁执行影响系统吞吐率。
AOF:RDB方式会出现数据丢失的问题,对于这个问题,可以通过Redis中另外一种持久化方式解决:AOF。AOF(append only file)是Redis提供了另外一种持久化机制。与RDB记录数据不同,当开启AOF持久化后,Redis会将客户端发送的所有更改数据的命令,记录到磁盘中的AOF文件。 这样的话,当Redis重启后,通过读取AOF文件,按顺序获取到记录的数据修改命令,即可完成数据恢复。

使用:AOF方式需要手动开启,修改redis.conf
# 是否开启AOF,默认为no
appendonly yes
#设置AOF文件名称
appendfilename appendonly.aof
对于AOF的触发方式有三种:always、everysec、no。 默认使用everysec。可以通过redis.conf中appendfsync属性进行配置。
执行原理:AOF功能实现的整个执行过程可以分为三个部分:命令追加、文件写入、文件同步。

1)客户端向Redis发送写命令。
2)Redis将接收到的写命令保存到缓冲文件aof_buf的末尾。 这个过程是命令追加。
3)redis将缓冲区文件内容写入到AOF文件,这个过程是文件写入。
4)redis根据策略将AOF文件保存到磁盘,这个过程是文件同步。
5)何时将AOF文件同步到磁盘的策略依据就是redis.conf文件中appendfsync属性值:always、everysec、no
- always:每次执行写入命令都会将aof_buf缓冲区文件全部内容写入到AOF文件中,并将AOF文件同步到磁盘。该方式效率最低,安全性最高。
- everysec:每次执行写入命令都会将aof_buf缓冲区文件全部内容写入到AOF文件中。 并且每隔一秒会由子线程将AOF文件同步到磁盘。该方式兼备了效率与安全,即使出现宕机重启,也只会丢失不超过两秒的数据。
- no:每次执行写入命令都会将aof_buf缓冲区文件全部内容写入到AOF文件中,但并不对AOF文件进行同步磁盘。 同步操作交由操作系统完成(每30秒一次),该方式最快,但最不安全。 | 模式 | aof_buf写入到AOF是否阻塞 | AOF文件写入磁盘是否阻塞 | 宕机重启时丢失的数据量 | 效率 | 安全 | | —- | —- | —- | —- | —- | —- | | always | 阻塞 | 阻塞 | 最多只丢失一个命令的数据 | 低 | 高 | | everysec | 阻塞 | 不阻塞 | 不超过两秒的数据 | 中 | 中 | | no | 阻塞 | 阻塞 | 操作系统最后一次对AOF写入磁盘的数据 | 高 | 低 |
AOF重写优化
AOF会将对Redis操作的所有写命令都记录下来,随着服务器的运行,AOF文件内保存的内容会越来越多。这样就会造成两个比较严重的问题:占用大量存储空间、数据还原花费的时间多。
为了解决AOF文件巨大的问题,Redis提供了AOF文件重写功能。 当AOF文件体积超过阈值时,则会触发AOF文件重写,Redis会开启子线程创建一个新的AOF文件替代现有AOF文件。 新的AOF文件不会包含任何浪费空间的冗余命令,只存在恢复当前Redis状态的最小命令集合。
触发配置: 对于重写阈值的配置,可以通过修改redis.conf进行配置。
#当前aof文件大小超过上一次aof文件大小的百分之多少时进行重写。如果之前没有重写过,以
启动时aof文件大小为准
auto-aof-rewrite-percentage 100
#限制允许重写最小aof文件大小,也就是文件大小小于64mb的时候,不需要进行优化
auto-aof-rewrite-min-size 64mb
#除了让Redis自动执行重写外,也可以手动让其进行执行:`bgrewriteaof`
RDB和AOF对比:
- RDB默认开启,AOF需手动开启。
- RDB性能优于AOF。
- AOF安全性优于RDB。
- AOF优先级高于RDB。
- RDB存储某个时刻的数据快照,AOF存储写命令。
- RDB在配置触发状态会丢失最后一次快照以后更改的所有数据,AOF默认使用everysec,每秒保存一次,最多丢失两秒以内的数据。
生产环境下持久化实践:
- 如当前只追求高性能,不关注数据安全性,则关闭RDB和AOF,如redis宕机重启,直接从数据源恢复数据。
- 如需较高性能且关注数据安全性,则开启RDB,并定制触发规则。
- 如更关注数据安全性,则开启AOF。
- 黑马头条 选择 即开启AOF 也开启RDB
3. 高可用-主从复制
通过持久化机制的学习,RDB和AOF都不能百分百的避免数据丢失,关键是现在只有一台服务器,持久化数据都是保存在这台服务器的磁盘上,假设这台服务器的磁盘损坏,数据仍然会全部丢失。
将持久化数据同时保存在多台服务器上,这样即使一台服务器出现问题,仍然可以从其他服务器同步数据。当一台服务器中数据更新后,可以自动的将更新的数据同步到其他服务器上, 这就是所谓的复制。
复制的搭建和使用:
持久化优化:
现在如果master和所有的slave都开启持久化的话,性能相对来说比较低。该如何优化提升性能呢?
我们可以在从节点上开启持久化、在主节点关闭持久化。 但是这样的话,数据不会丢失吗?
在主从复制的结构下,无非要么主节点宕机,要么从节点宕机。
- 当从节点宕机重启后,主节点会自动的将数据同步到从节点上。所以不会出现数据丢失。
- 当主节点宕机后,可以将从节点提升为主节点(slaveof no one),继续对外提供服务。 并且当原先的主节点重启后,使用slaveof命令将其设置为新主节点的从节点,即可完成数据同步。
主从复制总结:
具体步骤:
1、Slave服务启动,主动连接Master,并发送SYNC命令,请求初始化同步;
2、Master收到SYNC后,执行BGSAVE命令生成RDB文件,并缓存该时间段内的写命令;
3、Master完成RDB文件后,将其发送给所有Slave服务器;
4、Slave服务器接收到RDB文件后,删除内存中旧的缓存数据,并装载RDB文件;
5、Master在发送完RDB后,即刻向所有Slave服务器发送缓存中的写命令;
主从复制的作用:
- 读写分离:主写从读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
- 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
哨兵模式
在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机
制,它有效地解决了主从复制模式下故障转移的这三个问题。
哨兵(sentinel) 是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的master并将所有slave连接到新的master。
单节点哨兵:
注意:
- 哨兵也是一台redis服务器,只是不提供数据服务
- 通常哨兵配置数量为单数
- 如果配置启用单节点哨兵,如果有哨兵实例在运行时发生了故障,主从库无法正常切换啦,所以我们需要搭建 哨兵集群
哨兵节点集群模式: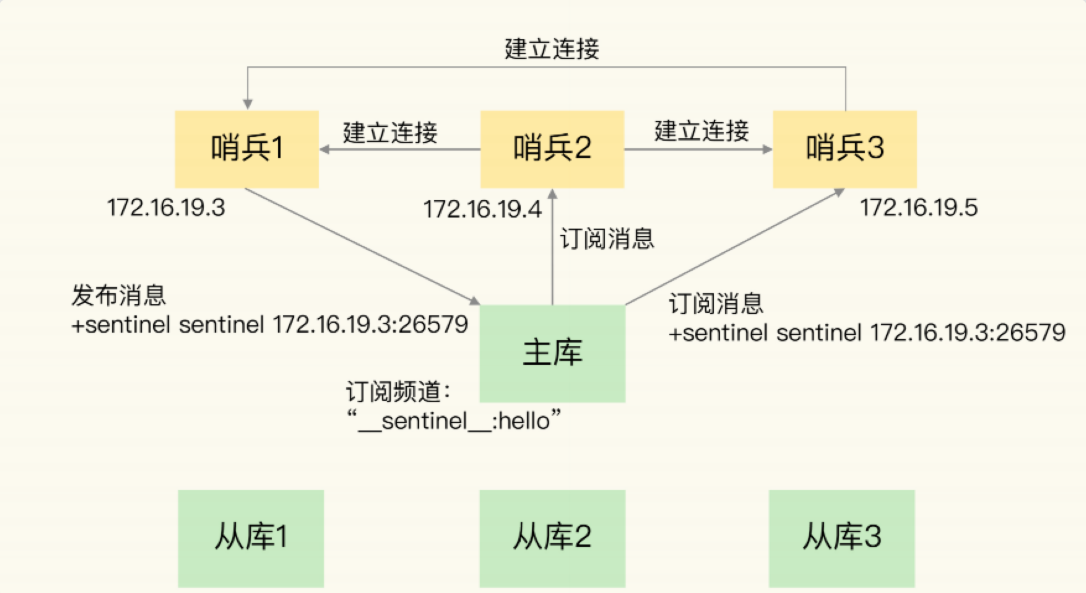
- Redis提供了哨兵的命令,是一个独立的进程
- 原理 哨兵通过发送命令给多个节点,等待Redis服务器响应,从而监控运行的多个Redis实例的运行情况
- 当哨兵监测到master宕机,会自动将slave切换成master,通过通知其他的从服务器,修改配置文件切换主机
Sentinel三大工作任务
- 监控(Monitoring)
- Sentinel 会不断地检查你的主服务器和从服务器是否运作正常
- 提醒(Notification)
- 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知
- 自动故障迁移(Automatic failover)
- 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器
- 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器
工作原理

哨兵集群中的多个实例共同判断,可以降低对主库下线的误判率
- 哨兵集群组成: 基于 pub/sub 机制
- 哨兵间发现:
- 主库频道“sentinel:hello”,不同哨兵通过它相互发现,实现互相通信
- 哨兵发现从库
- 向主库发送 INFO 命令
- 哨兵间发现:
- 基于 pub/sub 机制的客户端事件通知
- 事件:主库下线事件
- +sdown : 实例进入“主观下线”状态
- -sdown : 实例退出“主观下线”状态
- +odown : 实例进入“客观下线”状态
- -odown : 实例退出“客观下线”状态
- 事件:从库重新配置事件
- +slave-reconf-sent : 哨兵发送 SLAVEOF 命令重新配置从库
- +slave-reconf-inprog : 从库配置了新主库,但尚未进行同步
- +slave-reconf-done : 从库配置了新主库,且完成同步
- 事件:新主库切换
- +switch-master : 主库地址发生变化
- 事件:主库下线事件
- 由哪个哨兵执行主从切换?例如,现在有 5 个哨兵,quorum 配置的是 3,那么,一个哨兵需要 3 张赞成票,就可以标记主库为“客观下线”了。这 3 张赞成票包括哨兵自己的一张赞成票和另外两个哨兵的赞成票。
- 一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为“客观下线”
- 所需的赞成票数 <= quorum 配置项
- “Leader 选举”
- 两个条件:
- 拿到半数以上的赞成票
- 拿到的票数>= quorum
- 如果未选出,则集群会等待一段时间(哨兵故障转移超时时间的 2 倍),再重新选举
- 两个条件:
- 一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为“客观下线”
- 经验:要保证所有哨兵实例的配置是一致的
- 尤其是主观下线的判断值 down-after-milliseconds
总结
目前解决了什么问题:
- 主从集群间可以实现自动切换,可用性更高
- 数据更大限度的防止丢失
- 解决哨兵的集群高可用问题,减少误判率
目前还存在什么问题:
- 主节点的写能力和存储能力受限
4.高可扩—Redis Cluster分片集群
Redis原理:
- 数据切片和实例的对应分布关系
- Redis Cluster 方案:无中心化
- 采用哈希槽(Hash Slot)来处理数据和实例之间的映射关系
- 一个切片集群共有 16384 个哈希槽,只给Master分配
- 具体的映射过程
- 根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;
- 再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽
- 哈希槽映射到具体的 Redis 实例上
- 用 cluster create 命令创建集群,Redis 会自动把这些槽平均分布在集群实例上
- 也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数注意:需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作
- Redis Cluster 方案:无中心化
- 客户端如何定位数据
- Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散
- 客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端
- 客户端会把哈希槽信息缓存在本地。当请求键值对时,会先计算键所对应的哈希槽
- 但集群中,实例和哈希槽的对应关系并不是一成不变的
- 实例新增或删除
- 负载均衡
- 实例之间可以通过相互传递消息,获得最新的哈希槽分配信息,但客户端是无法主动感知这些变化
- 重定向机制
- 如果实例上没有该键值对映射的哈希槽,就会返回 MOVED 命令
- 客户端会更新本地缓存
- 在迁移部分完成情况下,返回ASK
- 表明 Slot 数据还在迁移中
- ASK 命令把客户端所请求数据的最新实例地址返回给客户端
- 并不会更新客户端缓存的哈希槽分配信息
- 如果实例上没有该键值对映射的哈希槽,就会返回 MOVED 命令
分片解决了什么问题:
- 海量数据存储
- 高可用
- 高可扩
高可用架构总结
- 主从模式:读写分离,负载均衡,一个Master可以有多个Slaves
- 哨兵sentinel:监控,自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器
- 分片集群: 为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,提高并发量。
5.key过期删除策略
如果一个key过期了,不是直接删除。
Redis中对于过期键的过期删除策略:
- 定时删除
会在设置键的过期时间的同时,创建一个定时器, 当键到了过期时间,定时器会立即对键进行删除。 这个策略能够保证过期键的尽快删除,快速释放内存空间。

Redis的操作频率是非常高的。绝大多数的键都是携带过期时间的,这样就会造成出现大量定时器执行,严重降低系统性能。
总的来说:该策略对内存空间足够友好, 但对CPU非常不友好,会拉低系统性能,因此不建议使用。
- 惰性删除
为了解决定时删除会占用大量CPU资源的问题, 因此产生了惰性删除。
它不持续关注key的过期时间, 而是在获取key时,才会检查key是否过期,如果过期则删除该key。简单来说就是:平时我不关注你,我用到你了,我才关注你在不在。
虽然它解决了定时删除会占用大量CPU资源的问题, 但是它又会造成内存空间的浪费。假设Redis中现在存在大量过期key,而这些过期key如果都不被使用,它们就会保留在redis中,造成内存空间一直被占用。
总的来说:惰性删除对CPU足够友好,但是对内存空间非常不友好,会造成大量内存空间的浪费。
- 定期删除
定期删除,顾名思义,就是每隔一段时间进行一次删除。 那么大家想一下,应该隔多久删一次? 一次又删除多少过期key呢?
- 如果删除操作执行次数过多、执行时间过长,就会导致和定时删除同样的问题:占用大量CPU资源去进行删除操作。
- 如果删除操作执行次数过少、执行时间过短,就会导致和惰性删除同样的问题:内存资源被持续占用,得不到释放。
- 所以定期删除最关键的就在于执行时长和频率的设置。

- 默认每秒运行10次会对具有过期时间的key进行一次扫描,但是并不会扫描全部的key,因为这样会大大延长扫描时间。
- 每次默认只会随机扫描20个key,同时删除这20个key中已经过期的key。
- 如果这20个key中过期key的比例达超过25%,则继续扫描。
6.内存淘汰策略
当客户端执行命令,添加数据时,Redis会检查内存空间大小,如超过最大内存,则触发内存淘汰策略。
在Redis中默认提供了三类八种淘汰策略。
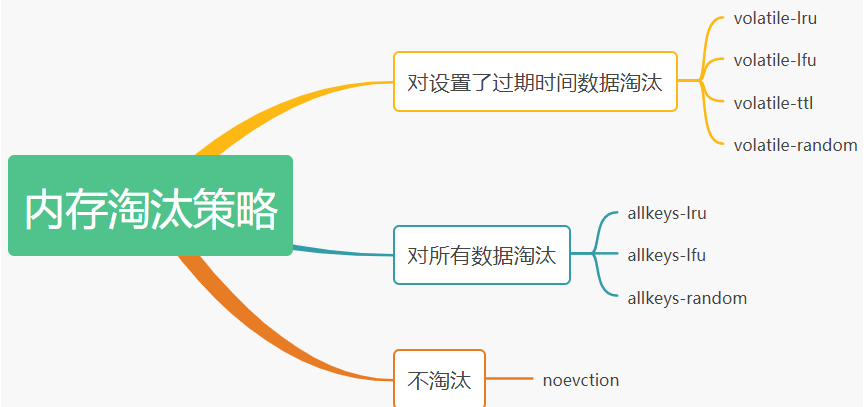
对于这些策略各自的含义,我们还需要一点前置知识的铺垫,这里我们可以看到两个名称:lru、lfu,他俩是什么意思呢?
他们的学名叫做:数据驱逐策略。 其实所谓的驱逐就是将数据从内存中删除掉。
- lru:Least Recently Used,它是以时间为基准,删除最近最久未被使用的key。
- lfu:Least Frequently Used,它是以频次为基准,删除最近最少未被使用的key。
那理解了lru和lfu之后,我们再回来看这三类八种内存淘汰策略各自的机制。
不同策略的使用场景
1、Redis只做缓存,不做DB持久化,使用allkeys。如状态性信息,经常被访问,但数据库不会修改。
2、同时用于缓存和DB持久化,使用volatile。如商品详情页。
3、存在冷热数据区分,则选择LRU或LFU。如热点新闻,热搜话题等。
4、每个key被访问概率基本相同,选择使用random。如企业内部系统,访问量不大,删除谁对数据库也造成太大压力。
5、根据超时时间长久淘汰数据,选择选用ttl。如微信过期好友请求。

若有收获,就点个赞吧
0 人点赞
