ZooKeeper 部署(二)— ZooKeeper集群搭建
一、Zookeeper原理简介
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。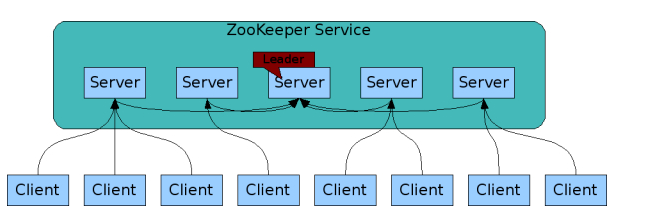
1、Zookeeper设计目的
- 最终一致性:client不论连接到那个Server,展示给它的都是同一个视图。
- 可靠性:具有简单、健壮、良好的性能、如果消息m被到一台服务器接收,那么消息m将被所有服务器接收。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
2、Zookeeper工作原理
在zookeeper的集群中,各个节点共有下面3种角色和4种状态:
角色:leader,follower,observer
zookeeper 集群通常是用来对用户的分布式应用程序提供协调服务的,为了保证数据的一致性,对 zookeeper 集群进行了这样三种角色划分:leader、follower、observer分别对应着总统、议员和观察者。
总 统 (leader):负责进行投票的发起和决议,更新系统状态。
议 员 (follower):用于接收客户端请求并向客户端返回结果以及在选举过程中参与投票。
观察者 (observer):也可以接收客户端连接,将写请求转发给leader节点,但是不参与投票过程,只同步leader的状态。通常对查询操作做负载。
状态:leading,following,observing,looking
:::info
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议(ZooKeeper Atomic Broadcast protocol)。Zab协议有两种模式,它们分别是恢复模式(Recovery选主)和广播模式(Broadcast同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有4种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
OBSERVING:observer的行为在大多数情况下与follower完全一致,但是他们不参加选举和投票,而仅仅接受(observing)选举和投票的结果。
:::
二、环境
1、系统配置
| IP地址 | hostname | 系统 |
|---|---|---|
| 192.168.8.161 | zk161 | cetnos7.9 |
| 192.168.8.161 | zk162 | cetnos7.9 |
| 192.168.8.161 | zk163 | cetnos7.9 |
systemctl stop firewalld # 关闭防火墙,临时关闭systemctl disable firewalld # 禁止开机启动systemctl status firewalld # 查看防火墙状态systemctl start firewalld # 启动防火墙
2、软件下载
从清华镜像下载zookeeper(新版本后,bin是zookeeper文件,下面那个是源码,一定不要下载错了)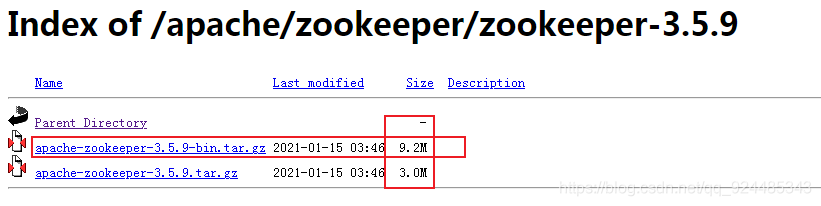
# wget https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.8/zookeeper-3.7.0.tar.gz -P /usr/local/src/
3、java安装
Zookeeper运行需要java环境,需要安装jdk,注:每台服务器上面都需要安装zookeeper、jdk,建议本地下载好需要的安装包然后上传到服务器上面,服务器上面下载速度太慢。
JDK安装
JDK 部署
三、zookeeper安装
1、配置集群
将zookeeper上传至三台机器
1、上传文件
tar zxvf zookeeper-3.4.8.tar.gz -C /opt
cd /opt && mv zookeeper-3.4.8 zookeeper
cd zookeeper
cp conf/zoo_sample.cfg conf/zoo.cfg
2、把zookeeper加入到环境变量
echo -e "# append zk_env\nexport PATH=$PATH:/opt/zookeeper/bin" >> /etc/profile
3、Zookeeper配置文件修改
#修改过后的配置文件zoo.cfg,如下:
egrep -v "^#|^$" zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataLogDir=/opt/zookeeper/logs
dataDir=/opt/zookeeper/data
clientPort=2181
autopurge.snapRetainCount=500
autopurge.purgeInterval=24
server.1 = 192.168.8.161:2888:3888
server.2 = 192.168.8.162:2888:3888
server.3 = 192.168.8.163:2888:3888
4、创建相关目录,三台节点都需要
mkdir -p /opt/zookeeper/{logs,data}
#其余zookeeper节点安装完成之后,同步配置文件zoo.cfg。
配置文件修改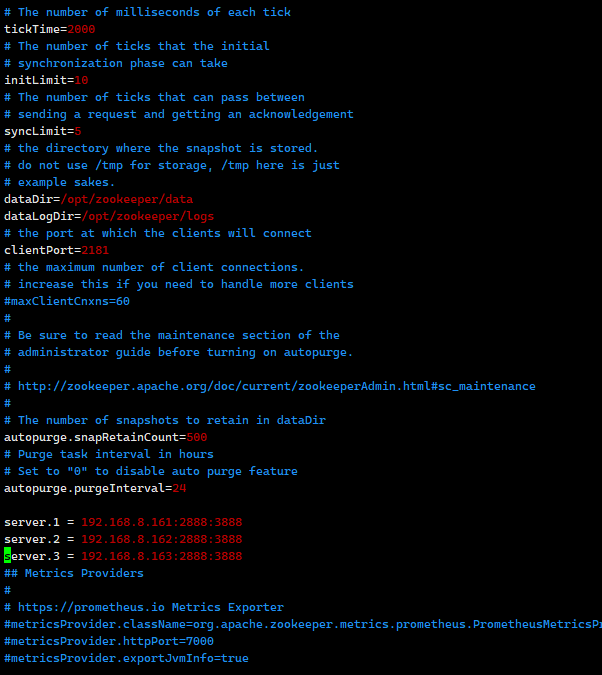 :::info
配置参数说明
:::info
配置参数说明
tickTime 这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳。
initLimit这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 102000=20秒。
syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是52000=10秒。
dataDir顾名思义就是zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里;
clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
:::
2、创建ServerID标识
:::info
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
#在192.168.8.161服务器上面创建myid文件,并设置值为1,同时与zoo.cfg文件里面的server.1保持一致,如下
:::
# 对应下面的顺序:
server.1 = 192.168.8.161:2888:3888
server.2 = 192.168.8.162:2888:3888
server.3 = 192.168.8.163:2888:3888
# 依次各个机器输入
echo "1" > /opt/zookeeper/data/myid
echo "2" > /opt/zookeeper/data/myid
echo "3" > /opt/zookeeper/data/myid
3、启动集群
./bin/zkServer.sh start #启动
# 已经添加至全局变量,可以直接使用脚本
[root@zk161 zookeeper]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 7898.
1. 第一次启动
:::warning
[root@zk161 zookeeper]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper … STARTED
[root@zk161 zookeeper]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Error contacting service. It is probably not running.
查看集群状态发现报错
1.排查端口,发现没有端口占用
2.排查配置文件发现
最后发现:
这是因为集群状态没有同步,等一会,再次重启后,机器上线
:::
4、查看集群状态
./bin/zkServer.sh status #查看服务器状态
[root@zk161 zookeeper]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zk162 zookeeper]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zk163 zookeeper]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
5、测试集群
[root@zk161 zookeeper]# zkCli.sh -server 192.168.8.163:2181
Connecting to 192.168.8.163:2181
2022-05-19 16:01:07,394 [myid:] - INFO [main:Environment@98] - Client environment:zookeeper.version=3.7.1-a2fb57c55f8e59cdd76c34b357ad5181df1258d5, built on 2022-05-07 06:45 UTC
2022-05-19 16:01:07,398 [myid:] - INFO [main:Environment@98] - Client environment:host.name=zk161
2022-05-19 16:01:07,398 [myid:] - INFO [main:Environment@98] - Client environment:java.version=1.8.0_231
2022-05-19 16:01:07,399 [myid:] - INFO [main:Environment@98] - Client environment:java.vendor=Oracle Corporation
2022-05-19 16:01:07,399 [myid:] - INFO [main:Environment@98] - Client environment:java.home=/usr/local/jdk/jre
2022-05-19 16:01:07,399 [myid:] - INFO [main:Environment@98] - Client environment:java.class.path=/opt/zookeeper/bin/.
..........
..........
192.168.8.163/192.168.8.163:2181, session id = 0x3000ad550be0001, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 192.168.8.163:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: 192.168.8.163:2181(CONNECTED) 1]
四、模拟集群异常
1 号 follower
2 号 follower
3 号 leader
(1)首先我们先测试如果是从服务器挂掉,会怎么样,把1号服务器停掉,观察2号和3号,发现状态并没有变化
由此得出结论,3个节点的集群,从服务器挂掉,集群正常
(2)我们再把2号服务器(从服务器)也停掉,查看3号(主服务器)的状态,发现已经停止运行了。
由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
(3)我们再次把1号服务器启动起来,发现3号服务器又开始正常工作了。而且依然是领导者。
(4)我们把2号服务器也启动起来,把3号服务器停掉,停掉后观察1号和2号的状态。
发现1号服务器成为新的Leader
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader
(5)把3号服务器重新启动起来启动后,3号服务器会再次成为新的领导吗?
我们会发现,3号服务器启动后依然是跟随者(从服务器),1号服务器依然是领导者(主服务器),没有撼动1号服务器的领导地位。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
在生产环境中,zk部署越多,其可靠性越高。由于zk集群是以宕机个数过半才会让整个集群宕机,因此,奇数个zk更佳。

若有收获,就点个赞吧
0 人点赞
