1. 线程类的测试
1.1 调用如下:
引入之前已经完成日志系统配合使用,打印相应的调试信息
void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::GetName()<< " this.name=" << Thread::GetThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::GetThis()->getId();sleep(100);}int main(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test begin!";vector<Thread::ptr> mv;for(int i = 0;i < 5;i++){Thread::ptr v(new Thread(&func1, "t_" + to_string(i)));mv.push_back(v);}for(int i = 0; i < 5;i++){mv[i]->join();}KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test end";return 0;}
1.2 运行结果如下
- 日志打印信息:

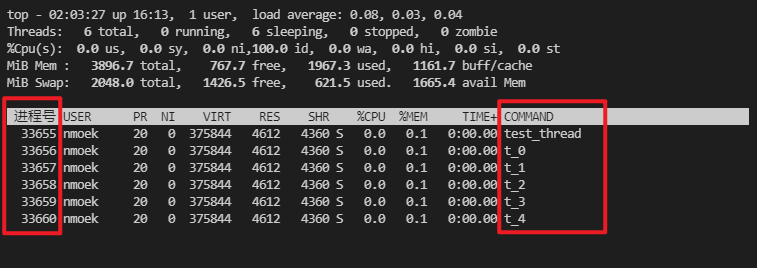
ps -aux | grep test_thread获得程序运行的进程号PID

top -H -p 27593[查到的PID]查看当前进程PID下所有线程运行情况
- 将函数
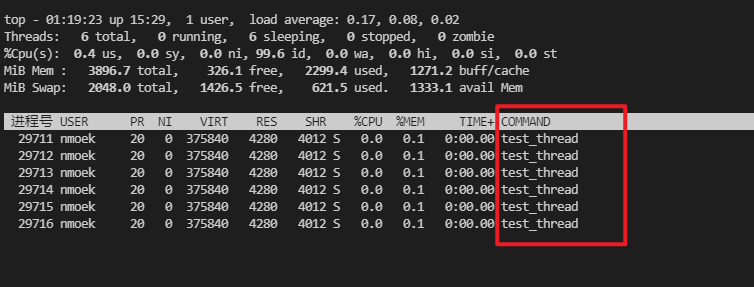
Thread::run::pthread_setname_np()注释后重复上述步骤发现线程名字恢复为默认。
2. 锁的性能测试比较
目的:封装了锁之后,好奇各类锁之间的性能差异,简单对加解锁开销时间做了比较。也为后续实际使用哪一种锁提供一点参照。
测试对象:5个线程对一个进程全局变量进行累加,每个线程累加100,000,000次。观察最终结果和耗时
2.1 不加锁
2.1.1 代码如下:
int sum = 0; //全局累加变量//以ms为单位计时#define TIME_SUB_MS(tv1, tv2) ((tv1.tv_sec - tv2.tv_sec) * 1000 + (tv1.tv_usec - tv2.tv_usec) / 1000)void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){++sum;}}int main(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test begin!";vector<Thread::ptr> mv;struct timeval tv_begin;struct timeval tv_cur;gettimeofday(&tv_begin, nullptr);for(int i = 0;i < 5;i++){Thread::ptr v(new Thread(&func1, "t_" + to_string(i)));mv.push_back(v);}for(int i = 0; i < 5;i++){mv[i]->join();}KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test end";memcpy(&tv_cur, &tv_begin, sizeof(struct timeval));gettimeofday(&tv_begin, nullptr);unsigned long int t = TIME_SUB_MS(tv_begin, tv_cur);KIT_LOG_INFO(KIT_LOG_ROOT()) << "sum=" << sum;KIT_LOG_INFO(KIT_LOG_ROOT()) << "time=" << t;return 0;}
2.2 运行结果如下:
运行时间在1ms以下非常的快。这里没有出现累加结果不对,其实不太合理,有可能是数据量太少的原因,或者线程数太少的原因。
2.2 加普通锁
2.2.1 代码如下:
Mutex m_mutex;void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){Mutex::Lock lock(m_mutex);++sum;}}
2.2.2 运行结果如下:
运行时间time=17762(单位:ms)
2.3 加写锁
2.3.1 代码如下:
RWMutex s_mutex;void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){RWMutex::WriteLock lock(s_mutex);++sum;}}
2.3.2 运行结果如下:
运行时间time=50122(单位:ms),和普通锁的开销相比,相差很大。写锁很耗资源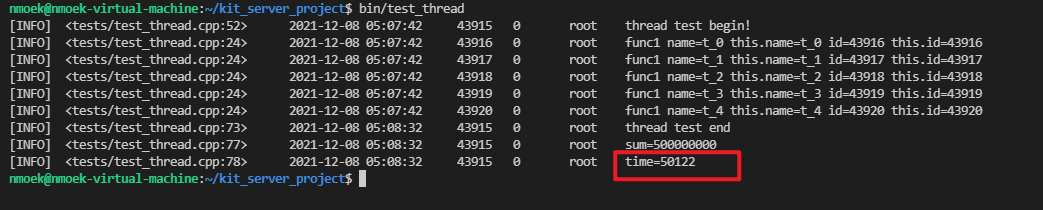
2.4 加读锁
2.4.1 代码如下:
RWMutex s_mutex;void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){RWMutex::ReadLock lock(s_mutex);++sum;}}
2.4.2 运行结果如下:
运行时间time=43761(单位:ms),累加数sum=429797772 != 500000000
开销比普通锁高,比写锁小,但是最终结果不对,发生了线程竞态,即:两个线程同时读取到相同的数据,但是+1操作是一样的。A线程读取到x,执行完毕后为x+1;此时恰好B线程也读取到的是x,执行完毕后将A线程的执行结果x+1又覆盖了一遍还是x+1,相当于漏加了一次。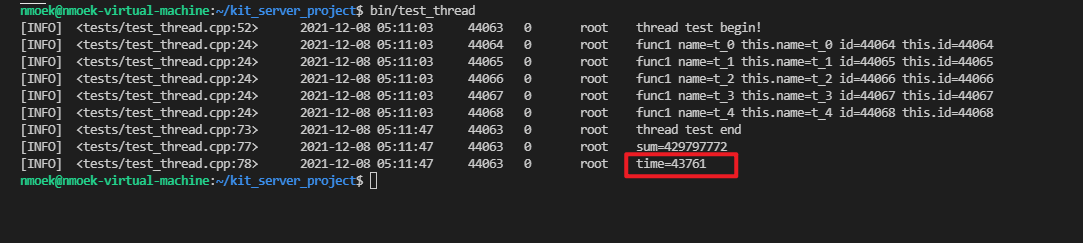
2.5加自旋锁
2.4.1 代码如下:
SpinMutex p_mutex;void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){SpinMutex::Lock lock(p_mutex);sum++;}}
2.4.2 运行结果如下:
运行时间time=47339(单位:ms),和写锁性能相当,和普通锁差异较大。
2.6 加CAS锁
2.4.1 代码如下:
CASMutex c_mutex;void func1(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "func1 " << "name=" << Thread::_getName()<< " this.name=" << Thread::_getThis()->getName()<< " id=" << GetThreadId()<< " this.id=" << Thread::_getThis()->getPid();for(int i = 0; i < 100000000;++i){CASMutex::Lock lock(c_mutex);sum++;}}
2.4.2 运行结果如下:
运行时间time=51280(单位:ms),和写锁、自旋锁性能相当,和普通锁差异较大。
3. 验证日志系统的线程安全性
小技巧1:构建”空锁”
**NullMutex**,契合区域锁的接口,避免多次注释//空通用锁class NullMutex{public:typedef ScopedLockImpl<NullMutex> Lock;NullMutex() {}~NullMutex() {}void lock() {}void unlock() {}};
小技巧2:类中对锁的真正类型起一个别名,方便调试修改锁类型
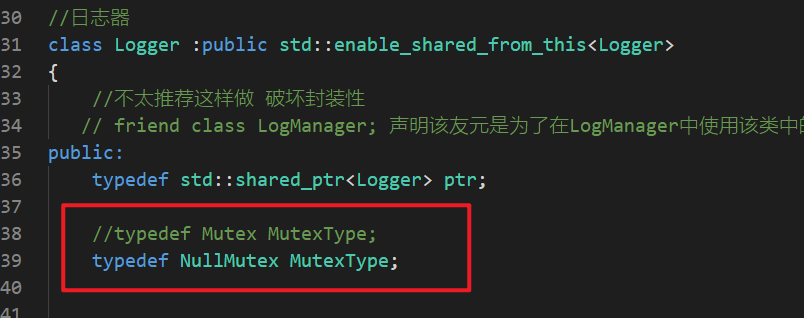
3.1 BUG:加锁后运行测试程序直接死锁
3.1.1 笨办法:将之前加锁的地方全部注释,一个一个打开运行程序
- 定位到大致死锁位置:
Logger::addAppender()函数:
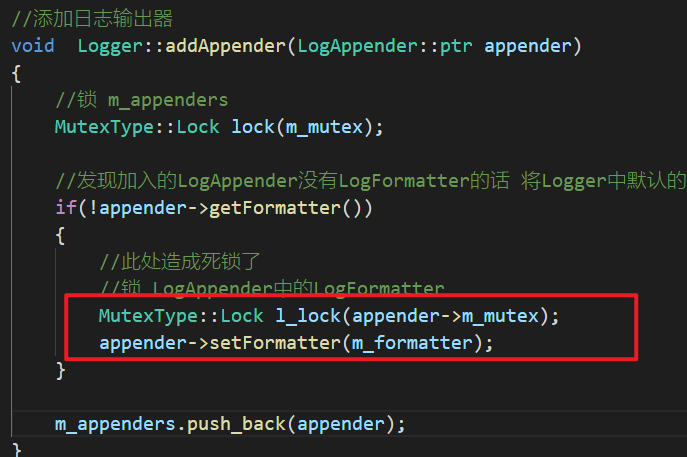
LogAppender::setFormater函数:
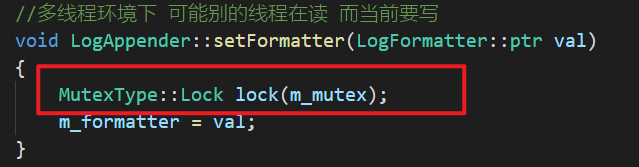
3.1.2 进一步使用GDB调试确认
ps -aux |grep test_thread拿到测试程序对应的PID 3884

- 确认一下多个线程是否已经启动。没有启动,不是多线程之间的死锁,而是主线程自己死锁。
只有主线程存在,基本可以确定是加锁位置不恰当导致的死锁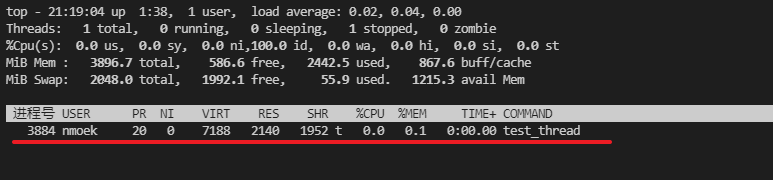
- 使用GDB 拉取进程 3884 进入调试。
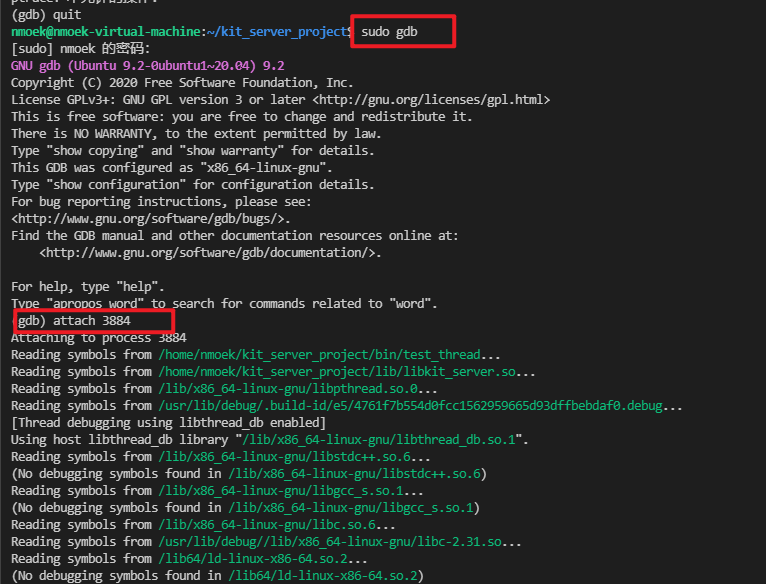
- 出现如下提示,该测试程序的主线程正在处于锁请求等待

bt(backtrace)使用该命令查看当前线程,堆栈调用信息
从#0-15依次显示的是从栈顶到栈底的栈帧信息,栈顶#0帧是最终线程停在函数调用上。另外可以看到,#5帧Logger::addAppder()先发生调用,#4帧LogAppender::setFormatter()后发生调用,符合程序设计。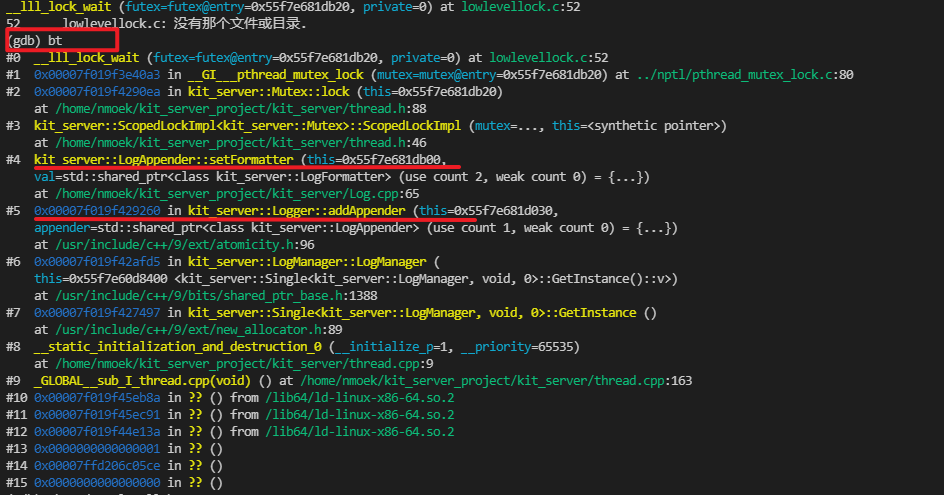
3.1.3 最终可以认为死锁发生在:
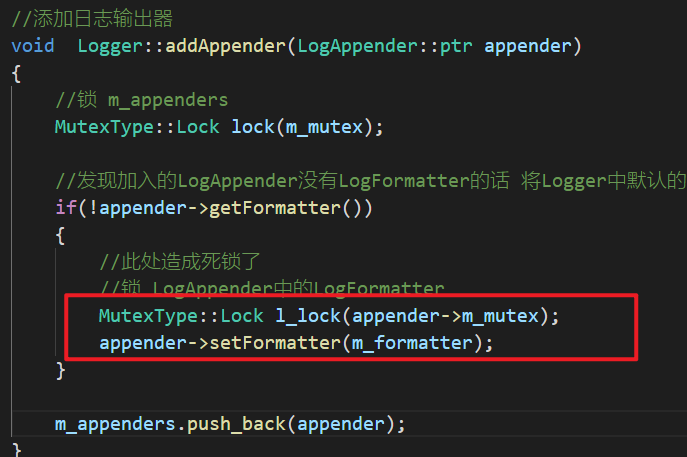
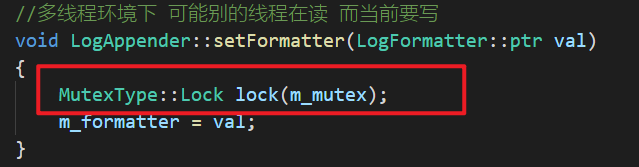
3.1.4 解决办法:将这一层中的锁去掉
3.2 测试文件输出日志情况
测试文件.cpp如下: ```cpp void func2() { while(1) KIT_LOG_INFO(KIT_LOG_ROOT()) << “xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”;
}
void func3() { while(1) KIT_LOG_INFO(KIT_LOG_ROOT()) << “=====================================================”;
}
int main()
{
KIT_LOG_INFO(KIT_LOG_ROOT()) << “thread test begin!”;
//加载配置文件 让日志只往文件中输出YAML::Node root = YAML::LoadFile("/home/nmoek/kit_server_project/tests/logs2.yaml");Config::LoadFromYaml(root);vector<Thread::ptr> mv;for(int i = 0;i < 2;i++){Thread::ptr v(new Thread(&func2, "t_" + to_string(i * 2)));Thread::ptr v2(new Thread(&func3, "t_" + to_string(i * 2 + 1)));mv.push_back(v);mv.push_back(v2);}for(size_t i = 0; i < mv.size();i++){mv[i]->join();}KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test end";return 0;
}
- `logs2.yaml`文件如下:```yamllogs:- name: rootlevel: debugformatter: "[%p]%T%d%T%m%n"appender:- type: FileLogAppenderfile: mutex.txt
3.2.1 不加锁往文件输出
目的:观察是否有”串行”情况,如果发生说明不加锁的输出是线程不安全的。
3.2.1.1 笨办法:直接观察输出结果看是否有不和谐的输出行
优点:直观、快捷 缺点:人眼识别有限,且不够科学自动化。
3.2.1.2 使用shell编程协助输出,打印内容固定每一行的长度也固定,出现不同长度的行则异常
head mutex.txt显示文件中开头的一部分
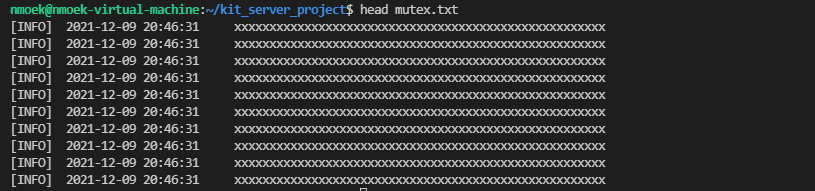
head mutex.txt | awk '{print length($0)}'计算开头这几行的长度,正常长度为80个字节- awk命令是文本解析,可以执行shell代码并且输出结果
cat mutex.txt | awk '{print length($0)}' | grep -v 80 > 1.txt使用grep -v反向分组命令,将不等于80个字节长度的行的实际长度输出到1.txt文件中。很遗憾:在80字节这个长度下没能观察到应该出现的”串行”情况。
3.2.1.3 考虑将线程的输出内容加长
head mutex.txt | awk '{print length($0)}'加长到 174字节
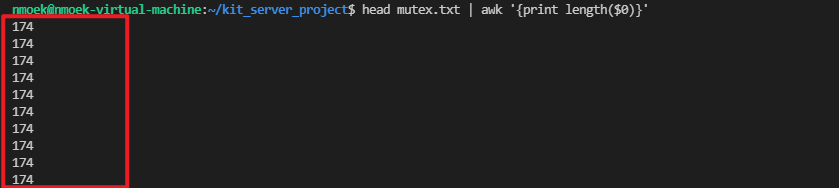
- 再一次
cat mutex.txt | awk '{print length($0)}' | grep -v 80 > 1.txt。
如愿观察到多线程下不加锁的输出”串行情况”。以下几个输出均不符合正常长度174。
3.2.2 加普通锁Mutex之后,3.2.1中的情况不再出现
重复测试几次后,没有出现多线程串行输出的情况。
4. 优化日志系统线程安全下的性能
目的:在 3. 中我们解决了日志打印的线程安全问题,但是加锁必然会带来性能的损失,这一小节就尝试考虑性能优化
锁优化的思路和方法,有以下几种:
- 减少锁持有时间
临界区尽量精简、操作简单
- 减小锁粒度
拆分临界对象,只对必要的对象上锁
- 锁分离
读写分离,分为读写锁,读读共享,读写互斥,写写互斥。
- 锁粗化
减少对锁不停地请求、同步和释放步骤。请求频率高虽然能保证并发性,但不能保证性能
- 锁消除
编译级别的优化,有时为了通用性在标准库下的一些代码默认带锁,满足一定条件后会去掉不必要的锁
4.1 日志写入文件性能比较
- 调用如下:
每一个线程中写入20,000,000次内容,总共2*2=4个线程,写入内容有8千万条日志。
比较加锁和不加锁的性能损耗。
#define TIME_SUB_MS(tv1, tv2) ((tv1.tv_sec - tv2.tv_sec) * 1000 + (tv1.tv_usec - tv2.tv_usec) / 1000)void func2(){int i = 0;while(i++ < 20000000)KIT_LOG_INFO(KIT_LOG_ROOT()) << "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";}void func3(){int i = 0;while(i++ < 20000000)KIT_LOG_INFO(KIT_LOG_ROOT()) << "===================================================================================================================================================";}int main(){KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test begin!";YAML::Node root = YAML::LoadFile("/home/nmoek/kit_server_project/tests/logs2.yaml");Config::LoadFromYaml(root);vector<Thread::ptr> mv;struct timeval tv_begin;struct timeval tv_cur;gettimeofday(&tv_begin, nullptr);for(int i = 0;i < 2;i++){Thread::ptr v(new Thread(&func2, "t_" + to_string(i * 2)));Thread::ptr v2(new Thread(&func3, "t_" + to_string(i * 2 + 1)));mv.push_back(v);mv.push_back(v2);}for(size_t i = 0; i < mv.size();i++){mv[i]->join();}KIT_LOG_INFO(KIT_LOG_ROOT()) << "thread test end";memcpy(&tv_cur, &tv_begin, sizeof(struct timeval));gettimeofday(&tv_begin, nullptr);unsigned long int t = TIME_SUB_MS(tv_begin, tv_cur);//KIT_LOG_INFO(KIT_LOG_ROOT()) << "time=" << t;std::cout << "time=" << t << std::endl;return 0;}
**logs2.yaml**配置文件如下:logs:- name: rootlevel: debugformatter: "[%p]%T%d%T%m%n"appender:- type: FileLogAppenderfile: mutex.txt
4.1.1 不加锁情况下(使用NullMutex日志打印情况)
- 耗时
time=311494单位:ms。约为5.1min左右

- 写入数
wc -l mutex.txt统计文件中共有多少行数据,每一条日志占一行。除去串行的行,有效行数 = 84238863 - 43 ≈ 8.42千万行,还多出了4百万行数据,进一步说明不加锁的输出是有问题的。

4.1.2 加普通锁情况下(使用Mutex日志打印情况)
- 耗时
time=325362单位:ms。约为5.4min左右。
和不加锁的情况相比,慢了0.4min ≈ 24s左右
- 写入数
wc -l mutex.txt统计文件中共有多少行数据,每一条日志占一行。除去串行的行,有效行数 = 80000001 - 1 = 8千万行。

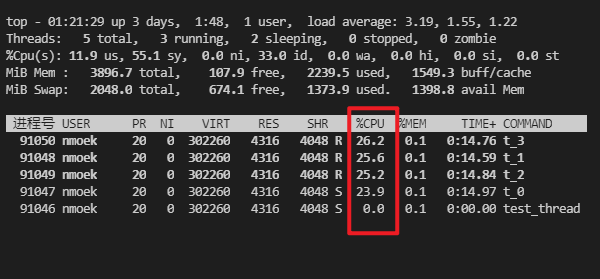
- 每秒文件写入量 在20MB/s左右
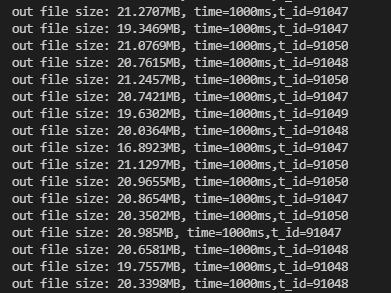
CPU占用率 平均在25%左右
4.1.3 加写锁情况下(使用RWMutex日志打印情况)
- 耗时
time=319164单位:ms。约为5.4min左右。
和不加锁的情况相比,慢了7.6s左右
和加普通锁情况相比,快了6.1s左右
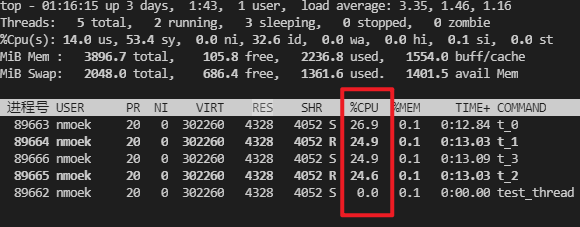
- 每秒文件写入量 在20MB/s左右
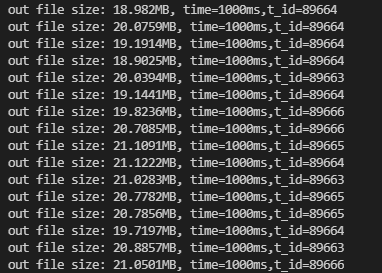
- CPU占用率 平均在25%左右
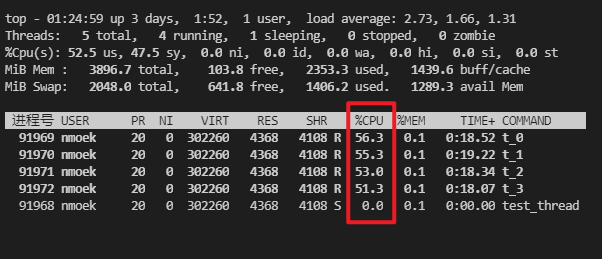
4.1.4 加自旋锁情况下(使用SpinMutex日志打印情况)
- 耗时
time=729497单位:ms。约为12.1min左右。

- 每秒文件写入量 在10MB/s左右
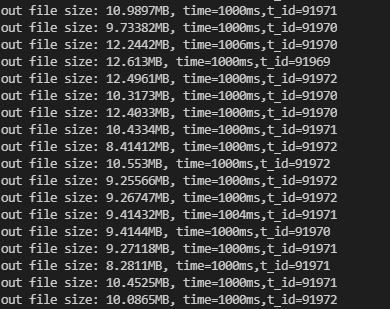
- CPU占用率 平均在55%左右。从理论上
pthread_spinlock_t锁的临界操作区中不能出现陷入内核态的操作,否则引起CPU巨额性能损失。
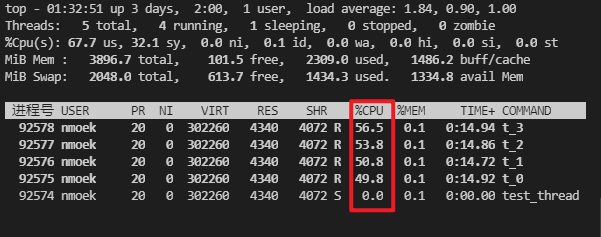
4.1.5 加原子锁情况下(使用CASMutex日志打印情况)
- 耗时
time=756024单位:ms。约为12.6min左右。
是当前加锁情况中最慢的。
- 每秒文件写入量 在10MB/s左右
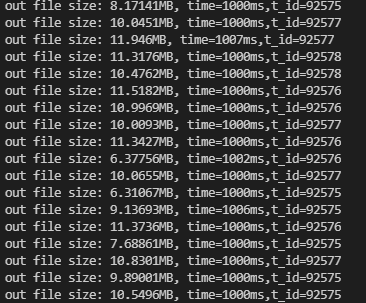
- CPU占用率 平均在55%左右。和自旋锁的实现是一样的
4.2 BUG:无意发现,日志写入文件时,强删文件没有引起报错
**ps -aux | grep test_thread**拿到测试程序的PID

- 查看进程对应的文件描述符fd管理:
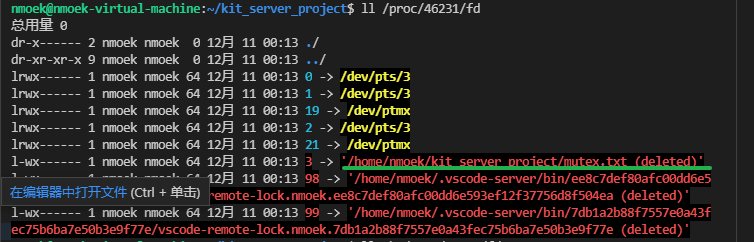
4.2.1 了解输出流ofstream的操作符是否有检查机制

关于ofstream的文档没有相关说明。猜想文件被强删后,返回的ofstream&是否有可能为nullptr
- 做如下尝试:
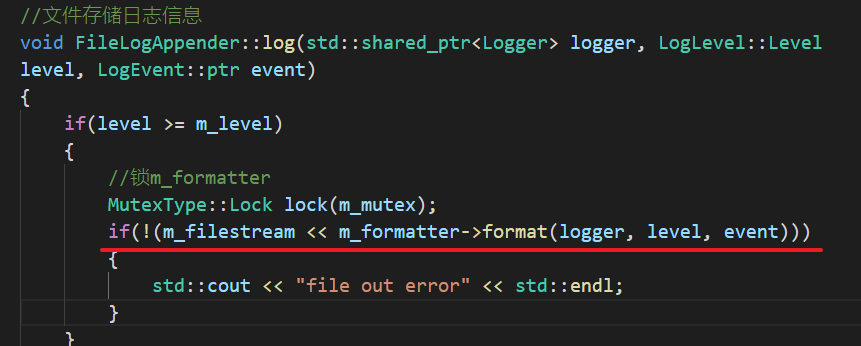
很遗憾并没有出现所期待的输出,强删后依旧没有反应。
4.2.2 考虑定时检查文件打开状态
每秒都重新打开一次文件,以确保文件没有发生删除,就算删除会重新创建同名的新文件继续写入,但是之前的写入内容就会全部丢失。还有一个好处,规避了因为外部强制删除当前操作的文件描述符而实际上文件的操作句柄仍被占用,导致物理磁盘空间得不到释放。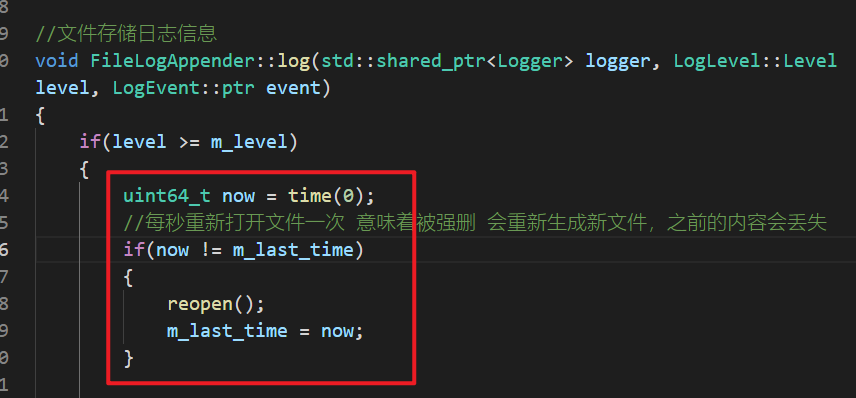
疑惑点:出现一些锁的性能和预期了解的不同,是什么原因引起的?
1. 怀疑是日志输出太大,导致磁盘用量不够。8千万条日志一次输出占约15G。
- 某次日志输出的文件大小容量:(14G)
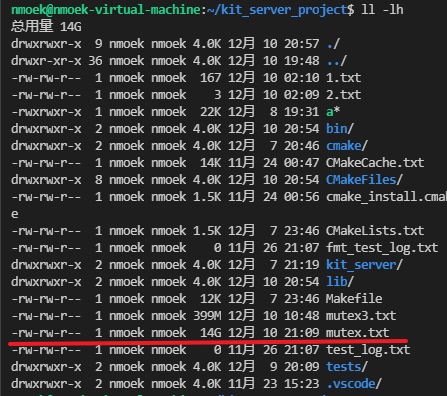
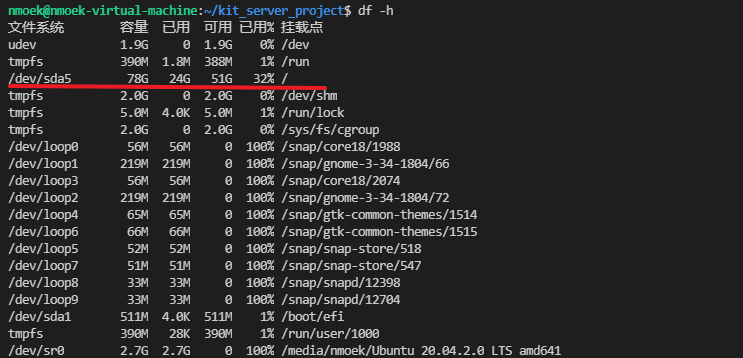
**df -h**查询当前磁盘容器使用情况,容量非常充足。排除该可能
2. 原本试图使用自旋锁SpinMutex,代替普通锁Mutex做一点优化
这个思路存在原理上的错误。
出处:《UNIX 环境高级编程 第三版》P335
原因:”不要调用在持有自旋锁情况下可能会进入休眠状态的函数”。通过一些询问和查询,持有spinlock不仅仅不能调造成休眠的函数,凡是有可能陷入内核态的包括read、write、memcpy等系统调用的函数也都不能使用。这样做占用CPU高额的资源,其他线程要获取到自旋锁会等待更加长的时间。
“事实上,有些互斥量的实现在试图获取互斥量的时候会自旋一小段时间,只有在自旋时间到达某一个阈值才会休眠”。

若有收获,就点个赞吧
0 人点赞
