- 准备:认识Protobuf
- 准备:认识varint编码
- 1. ByteArray 类封装
- C\C++知识点复习补充:float、double类型存储结构
准备:认识Protobuf
概念:Protobuf(Google Protocol Buffers)是谷歌提供的一个具有搞笑的协议数据交换格式的工具库(类似Json数据格式),时间和空间效率上都比Json要好一些。目前还不是太流行,仅支持C++、JAVA、python语言的开发。
重点关注:ProtoBuf中数据序列与反序列的规则
protobuf把消息结果message也是通过 key-value键值对来表示。只是其中的key是采取一定的算法计算出来的即通过每个message中每个字段(field index)和字段的数据类型(type)进行运算得来:key = (index << 3) | typefield index = key >> 3type = key & 0x111
type类型的对应关系如下: | type | mean | used for | | —- | —- | —- | | 0 | varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum | | 1 | 64-bit | fixed64, sfixed64, double | | 2 | length-delimited | string, bytes, embedded messages, packed repeated fields | | 3 | start group | groups (deprecated) | | 4 | end group | groups (deprecated) | | 5 | 32-bit | fixed32, sfixed32, float |
准备:认识varint编码
概念:varint是一种使用1字节~多字节序列化一个整数的方法,会根据一个整数的数值大小对应编码变长的存储字节大小。32int型数据经varint编码后需要1~5字节;64int型数据经varint编码后需要1~10字节。通常,在实际应用场景中,小数字的使用远多于大数字,varint编码能够起到很好的压缩效果,节省空间。
· 编码原理
- 除最后一个字节外,每一个字节的最高位都有特殊的意义,即:最高有效位(most significant bit —msb),msb = 1表明后面的数据还是属于当前数据;msb = 0表明这已经是当前数据已经结束。
- 每个字节的低7位用于以7位为一组存储数字的二进制补码表示,且按照小端字节序排列。
例子1,将数字
uint32_t = 123456进行varint编码123456|0000 0000 000|0 0001 11|10 0010 0|100 0000 ------二进制补码表示 4字节表示|| 每7bit划分,添加msb重新编码,从低位到高位取,并反转排序|1|1000000 1|1000100 0|00001110xC0 0xC4 0x07 --------varint编码后的数据 3字节表示
例子2,将数字
uint32_t = 665进行varint编码665|0000 0000 0000 0000 00|00 0010 1|001 1001 ------二进制补码表示 4字节表示|| 每7bit划分,添加msb重新编码,从低位到高位取,并反转排序|1|0011001 0|00001010X99 0X05 --------varint编码后的数据 2字节表示
例子3,将数字
int32_t = -1进行varint编码(可以看到有时候对负数的压缩编码效率低下)-1|1111 |1111 111|1 1111 11|11 1111 1|111 1111 ------二进制补码表示 4字节表示|| 每7bit划分,添加msb重新编码,从低位到高位取,并反转排序|1|1111111 1|1111111 1|1111111 1|1111111 0|00011110xff 0xff 0xff 0xff 0x0f ------varint编码后的数据 5字节表示
例子4,将数字
int32_t = -123进行varint编码(可以看到有时候对负数的压缩编码效率低下)-123|1111 |1111 111|1 1111 11|11 1111 1|000 0101 ------二进制补码表示 4字节表示|| 每7bit划分,添加msb重新编码,从低位到高位取,并反转排序|1|0000101 1|1111111 1|1111111 1|1111111 0|00011110x85 0xff 0xff 0xff 0x0f ------varint编码后的数据 5字节表示
1. ByteArray 类封装
目的:网络编程中势必涉及到数据包的封装、传递等操作。将这些数据的序列化和反序列化操作抽象到一个类中来管理,有点类似”内存池”的管理,但不是真正的内存池。
注意:涉及网络编程,小心数据包传递、组装还原时候字节序问题
1.1 成员变量
class ByteArray{......private://每一个内存块有多大size_t m_baseSize;//当前操作指针的位置size_t m_position;//总共容量大小size_t m_capacity;//已经使用的空间大小size_t m_size;//数据字节序(大端/小端)int8_t m_endian;//内存结点个数size_t m_nodeSum;//内存链表头结点Node* m_root;//内存链表尾结点Node* m_cur;};
1.2 接口
1.2.1 构造函数
/*** @brief ByteArray类构造函数* @param base_size 传入的指定内存块的大小 默认为4KB*/ByteArray(size_t base_size = 4 * 1024);ByteArray::ByteArray(size_t base_size):m_baseSize(base_size),m_position(0),m_capacity(base_size),m_size(0),m_endian(KIT_BIG_ENDIAN) //网络字节序是大端,m_root(new Node(base_size)),m_cur(m_root){}
1.2.2 析构函数
功能:负责将申请的内存结点,逐一手动释放
/*** @brief ByteArray类析构函数*/~ByteArray();ByteArray::~ByteArray(){//释放内存链表Node* temp = m_root;while(temp){m_cur = temp;temp = temp->next;delete m_cur;}}
** 私有接口 (核心)
1). addCapacity()
功能:给内存扩容,指定扩容空间大小
- 核心逻辑:
- 获取当前内存剩余的容量,和传入的要写入的数据size比较。
remain_cap >= size就不用扩容 - 计算出需要扩容的容量大小,根据该大小和单个内存结点大小,计算需额外添加结点的数量
size_t count = ceil(1.0 * size / m_baseSize);(进行上取整)
- 找到尾部结点的位置,开始从该位置采用尾插添加新的结点。并且要记录第一个新添加的结点位置
- 如果之前获取的剩余容量的大小刚好为0,要将指示当前可用结点指针
m_cur置为第一个新添加结点 ```cpp /**- @brief 给内存扩容
- @param[in] size 需要扩大的容量大小 */ void addCapacity(size_t size);
void ByteArray::addCapacity(size_t size) { if(size == 0) return;
//获取剩余的容量size_t remain_cap = getRemainCapacity();if(remain_cap >= size)return;//减去原有的容量size = size - remain_cap;//计算需额外添加结点的数量size_t count = ceil(1.0 * size / m_baseSize);//找到尾部内存块结点的位置Node *temp = m_root;while(temp->next){temp = temp->next;}//从尾部开始尾插法添加新结点Node *first = nullptr;for(size_t i = 0;i < count;++i){temp->next = new Node(m_baseSize);//将新加入的第一个结点记录一下便于连接if(first == nullptr){first = temp->next;}temp = temp->next;m_capacity += m_baseSize;}//如果原来的容量恰好用完 要把m_cur置到第一个新结点上if(remain_cap == 0)m_cur = first;
}
<a name="rBUqv"></a>#### 2). `getRemainCapacity()`功能:计算返回当前内存剩余容量大小。```cpp/*** @brief 获取能使用的剩余容量大小* @return size_t*/size_t getRemainCapacity() const {return m_capacity - m_position;}
** 辅助函数(重点)
目的:将有符号的数都转为无符号数进行varint压缩,避免出现负数压缩的情况。因为varint算法对负数压缩的效率很低下。存入时候负——>正,取出时候恢复正——->负
1). EncodeZigzag32()/DecodeZigzag32()
功能:int32_t—————>uint32_t / uint32_t—————>int32_t
/*** @brief int32_t---------->uint32_t* @param[in] v 传入的int32_t数据* @return uint32_t*/static uint32_t EncodeZigzag32(const int32_t &v){//不转换的话 负数压缩会浪费空间if(v < 0){return ((uint32_t)(-v)) * 2 - 1;}return v * 2;}/*** @brief uint32_t---------->int32_t* @param[in] v 传入的uint32_t数据* @return int32_t*/static int32_t DecodeZigzag32(const uint32_t &v){//消除乘2 异或一下最后一位来恢复负数return (v >> 1) ^ -(v & 1);}
2). EncodeZigzag64()/DecodeZigzag64()
功能:int64_t—————>uint64_t / uint64_t—————>int64_t
/*** @brief int64_t---------->uint64_t* @param[in] v 传入的int64_t数据* @return uint64_t*/static uint64_t EncodeZigzag64(const int64_t &v){//不转换的话 -1压缩一定要消耗10个字节if(v < 0){return ((uint64_t)(-v)) * 2 - 1;}return v * 2;}/*** @brief int64_t---------->uint64_t* @param[in] v 传入的int64_t数据* @return int64_t*/static int64_t DecodeZigzag64(const uint64_t &v){//消除乘2 异或一下最后一位来恢复负数return (v >> 1) ^ -(v & 1);}
1.2.3 写系列函数
1.2.3.1 write()(核心)
功能:将缓冲区的内容写入到内存块中
- 核心逻辑:
- 保险起见,先将总容量再扩展size个字节
addCapacity(size) - 获取当前内存块的相关信息:内存指针内存块哪一个字节上,内存块剩余容量等
while(size >0) 只要待写入数据量不为0就要一直写入
{
- 开始将数据从缓冲区写入内存块:
- 当前内存块剩余容量
ncap>= 缓冲区数据量size:
- 当前内存块剩余容量
当前结点能够放下缓冲区的全部数据。
- 当前内存块剩余容量
ncap< 缓冲区数据量size:
当前结点只能够放下缓冲区的一部分数据,另外一部分数据需要放入下一个内存块中,发生”数据断层”。
}
- 最后,内存指针的位置
m_position> 已经使用的内存空间m_size,需要更新一下已使用内存。 ```cpp /**- @brief 将数据写入内存
- @param[in] buf 写入缓冲区指针
- @param[in] size 要写入的字节大小 / void write(const void buf, size_t size);
void ByteArray::write(const void * buf, size_t size) { if(size == 0) return;
//扩展容量sizeaddCapacity(size);//内存指针现在在内存块结点哪一个字节位置上size_t npos = m_position % m_baseSize;//当前结点的剩余容量size_t ncap = m_cur->size - npos;//已经写入内存的数据量size_t bpos = 0;while(size > 0){//内存结点当前剩余容量能放下size的数据if(ncap >= size){memcpy(m_cur->ptr + npos, (const char*)buf + bpos, size);//如果当前结点恰好被写完 也要把内存指针移到下一个内存块上if(m_cur->size == (npos + size))m_cur = m_cur->next;m_position += size;bpos += size;size = 0;}else //否则就是不够放 先把当前剩余空间写完 在下一个新结点继续写入{memcpy(m_cur->ptr + npos, (const char *)buf + bpos, ncap);m_position += ncap;bpos += ncap;size -= ncap;//去遍历下一个内存块m_cur = m_cur->next;ncap = m_cur->size;npos = 0;}}//如果内存指针超过了当前表示的已经使用的空间大小 更新一下if(m_position > m_size)m_size = m_position;
}
<a name="JTVyQ"></a>#### 1.2.3.2 写入固定长度数据除了1字节长度的数据,其他 >1字节的数据需要检查存储的数据字节序是否和用户物理机的字节序相同,不同需要进行字节序调整交换。```cpp/*固定长度存储*/void writeFint8(int8_t value);void writeFuint8(uint8_t value);void writeFint16(int16_t value);void writeFuint16(uint16_t value);void writeFint32(int32_t value);void writeFuint32(uint32_t value);void writeFint64(int64_t value);void writeFuint64(uint64_t value);void writeFloat(float value);void writeDouble(double value);
void ByteArray::writeFint8(int8_t value){write(&value, sizeof(value));}void ByteArray::writeFuint8(uint8_t value){write(&value, sizeof(value));}void ByteArray::writeFint16(int16_t value){//如果当前字节序和本机字节序不符 需要swapif(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFuint16(uint16_t value){if(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFint32(int32_t value){if(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFuint32(uint32_t value){if(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFint64(int64_t value){if(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFuint64(uint64_t value){if(m_endian != KIT_BYTE_ORDER)value = byteswap(value);write(&value, sizeof(value));}void ByteArray::writeFloat(float value){uint32_t v;memcpy(&v, &value, sizeof(value));writeFuint32(v);}void ByteArray::writeDouble(double value){uint64_t v;memcpy(&v, &value, sizeof(value));writeFuint64(v);}
1.2.3.3 写入varint压缩编码数据 (难点)
/*带varint压缩存储*/void writeInt32(int32_t value);void writeUint32(uint32_t value);void writeInt64(int64_t value);void writeUint64(uint64_t value);
1). writeUint32()/writeInt32()
功能:写入经过varint压缩编码的uint32_t型数据/int32_t型数据,处理时候避免负数压缩
void ByteArray::writeUint32(uint32_t value){//uint32_t 压缩后1~5字节的大小uint8_t temp[5];uint8_t i = 0;//varint编码 msp等于1 就认为数据还没读完while(value >= 0x80){//取低7位 + msp==1 组成新的编码数据temp[i++] = (value & 0x7F) | 0x80;value >>= 7;}temp[i++] = value;write(temp, i);}void ByteArray::writeInt32(int32_t value){writeUint32(EncodeZigzag32(value));}
2). writeUint64()/writeInt64()
功能:写入经过varint压缩编码的uint64_t型数据/int64_t型数据,处理时候避免负数压缩
void ByteArray::writeUint64(uint64_t value){//uint64_t 压缩后1~10字节的大小uint8_t temp[10];uint8_t i = 0;//varint编码 msp等于1 就认为数据还没读完while(value >= 0x80){//取低7位 + msp==1 组成新的编码数据temp[i++] = (value & 0x7F) | 0x80;value >>= 7;}temp[i++] = value;write(temp, i);}void ByteArray::writeInt64(int64_t value){writeUint64(EncodeZigzag64(value));}
1.2.3.4 写入string字符串类型
/*** @brief 写入 长度:int16_t + 字符串数据* @param value 传入的字符串*/void writeStringF16(const std::string& value);/*** @brief 写入 长度:int32_t + 字符串数据* @param value 传入的字符串*/void writeStringF32(const std::string& value);/*** @brief 写入 长度:int64_t + 字符串数据* @param value 传入的字符串*/void writeStringF64(const std::string& value);/*** @brief 写入 长度:varint(变长) + 字符串数据* @param value 传入的字符串*/void writeStringVint(const std::string& value);/*** @brief 写入 不带长度字符串数据* @param value 传入的字符串*/void writeStringWithoutLen(const std::string& value);
void ByteArray::writeStringF16(const std::string& value){//先写入一个长度 在写入具体数据writeFuint16(value.size());write(value.c_str(), value.size());}void ByteArray::writeStringF32(const std::string& value){//先写入一个长度 在写入具体数据writeFuint32(value.size());write(value.c_str(), value.size());}void ByteArray::writeStringF64(const std::string& value){//先写入一个长度 在写入具体数据writeFuint64(value.size());write(value.c_str(), value.size());}void ByteArray::writeStringVint(const std::string& value){//写入压缩长度uint64_t型writeUint64(value.size());write(value.c_str(), value.size());}void ByteArray::writeStringWithoutLen(const std::string& value){write(value.c_str(), value.size());}
1.2.3.5 将内存内容写入到文件
功能:将当前内存结点保存的内容全部写入到文件中,且不改变当前的内存指针位置。
/*** @brief 将数据从内存写入到文件中* @param[in] name 写入的文件路径* @return true 写入成功* @return false 写入失败*/bool writeToFile(const std::string& name) const;bool ByteArray::writeToFile(const std::string& name) const{std::ofstream ofs;//先清除内容再打开 以二进制方式写入ofs.open(name, std::ios::trunc | std::ios::binary);if(!ofs){KIT_LOG_ERROR(g_logger) << "ByteArray::writeToFile open error, errno=" << errno << ", is:"<< strerror(errno);return false;}//获取剩余可读取的数据量int64_t remain_size = getReadSize();//拿到当前内存指针位置 作为一个副本int64_t pos = m_position;Node * cur = m_cur;while(remain_size > 0){//计算得到当前内存指针所处内存块的偏移量位置int diff = pos % m_baseSize;//计算能写入的长度 = min(剩余可读数据量, 单个结点容量) - 内存指针偏移量int64_t len = (remain_size > (int64_t)m_baseSize ? m_baseSize : remain_size) - diff;ofs.write(cur->ptr + diff, len);cur = cur->next;pos += len;remain_size -= len;}return true;}
1.2.4 读系列函数
1.2.4.1 read()(核心)
功能:将内存块的内容读取到缓冲区中。和write()一模一样的流程,读什么位置依赖于内存指针的位置,始终从内存指针m_position一直读到最后
/*** @brief 将数据从内存读出* @param[out] buf 读取缓冲区指针* @param[in] size 预计要读取的字节大小*/void read(char *buf, size_t size);void ByteArray::read(char *buf, size_t size){//读取的长度超出可读范围要抛异常if(size > getReadSize())throw std::out_of_range("memory pool not enough!!");//内存指针现在在内存块结点哪一个字节位置上size_t npos = m_position % m_baseSize;//当前结点剩余容量size_t ncap = m_cur->size - npos;//当前已经读取的数据量size_t bpos = 0;while(size > 0){if(ncap >= size){memcpy(buf + bpos, m_cur->ptr + npos, size);//如果当前结点被读完if(m_cur->size == npos + size)m_cur = m_cur->next;m_position += size;bpos += size;size = 0;}else{memcpy(buf + bpos, m_cur->ptr + npos, ncap);m_position += ncap;bpos += ncap;size -= ncap;m_cur = m_cur->next;npos = 0;}}}
1.2.4.2 (重载)read()(核心)
功能:将内存块的内容读取到缓冲区中,但不影响当前内存指针指向的位置,使用一个外部传入的内存指针position,而不使用当前真正的内存指针m_position。即:用户只关心存储的内容,而不关心是否移除内存中的内容,或许还要紧接着写入内容。
/*** @brief 将数据从内存读出 但不影响操作指针位置* @param[out] buf 读取缓冲区指针* @param[in] size 预计要读取的字节大小* @param[in] position 当前内存操作指针的位置*/void read(char *buf, size_t size, size_t position) const;
1.2.4.3 读取固定长度数据
除了1字节长度的数据,其他 >1字节的数据需要检查存储的数据字节序是否和用户物理机的字节序相同,不同需要进行字节序调整交换。(采用宏替换简化代码)
/*固定长度读取*/int8_t readFint8();uint8_t readFuint8();int16_t readFint16();uint16_t readFuint16();int32_t readFint32();uint32_t readFuint32();int64_t readFint64();uint64_t readFuint64();float readFloat();double readDouble();
int8_t ByteArray::readFint8(){int8_t v;read((char*)&v, sizeof(v));return v;}uint8_t ByteArray::readFuint8(){uint8_t v;read((char*)&v, sizeof(v));return v;}#define READ_XX(type)\type v;\read((char*)&v, sizeof(v));\if(m_endian != KIT_BYTE_ORDER)\v = byteswap(v);\return v;int16_t ByteArray::readFint16(){READ_XX(int16_t);}uint16_t ByteArray::readFuint16(){READ_XX(uint16_t);}int32_t ByteArray:: readFint32(){READ_XX(int32_t);}uint32_t ByteArray::readFuint32(){READ_XX(uint32_t);}int64_t ByteArray::readFint64(){READ_XX(int64_t);}uint64_t ByteArray::readFuint64(){READ_XX(uint64_t);}float ByteArray::readFloat(){uint32_t v = readUint32();float value;memcpy(&value, &v, sizeof(v));return value;}double ByteArray::readDouble(){uint64_t v = readUint64();double value;memcpy(&value, &v, sizeof(v));return value;}
1.2.4.4 写入varint压缩编码数据 (难点)
/*读取varint压缩后的数据*/int32_t readInt32();uint32_t readUint32();int64_t readInt64();uint64_t readUint64();
1). readUint32()/readInt32()
功能:读取经过varint压缩编码的uint32_t型数据/int32_t型数据,处理时候恢复出负数
int32_t ByteArray::readInt32(){return DecodeZigzag32(readUint32());}uint32_t ByteArray::readUint32(){//最终得到一个uint32_t型数据uint32_t result = 0;//读取次数 = 32 / 7 + 1 组for(int i = 0;i < 32;i += 7){//一次读取8位uint8_t b = readFuint8();//msp==0 说明这是该数据的最后一个字节if(b < 0x80){//把取出来的位恢复到原来对应的位上result |= ((uint32_t)b) << i;break;}else //msp==1 说明后面还有字节没有取 要去掉头部的msp位result |= ((uint32_t)(b & 0x7F)) << i;}return result;}
2). readUint64()/readInt64()
功能:读取经过varint压缩编码的uint64_t型数据/int64_t型数据,处理时候恢复出负数
int64_t ByteArray::readInt64(){return DecodeZigzag64(readUint64());}uint64_t ByteArray::readUint64(){//最终得到一个uint32_t型数据uint64_t result = 0;//读取次数 = 64 / 7 + 1 组for(int i = 0;i < 64;i += 7){uint8_t b = readFuint8();//msp==0 说明这是该数据的最后一个字节if(b < 0x80){//最后一个字节直接或运算 不用去msp位result |= ((uint64_t)b) << i;break;}else //msp==1 说明后面还有字节没有取 要去掉头部的msp位result |= ((uint64_t)(b & 0x7F)) << i;}return result;}
1.2.4.5 读取string字符串类型
/*** @brief 读取 长度:int16_t + 字符串数据* @return std::string*/std::string readStringF16();/*** @brief 读取 长度:int32_t + 字符串数据* @return std::string*/std::string readStringF32();/*** @brief 读取 长度:int64_t + 字符串数据* @return std::string*/std::string readStringF64();/*** @brief 读取 长度:varint(变长) + 字符串数据* @return std::string*/std::string readStringVint();
std::string ByteArray::readStringF16(){uint16_t len = readFuint16();std::string buf;buf.resize(len);read(&buf[0], len);return buf;}std::string ByteArray::readStringF32(){uint32_t len = readFuint32();std::string buf;buf.resize(len);read(&buf[0], len);return buf;}std::string ByteArray::readStringF64(){uint64_t len = readFuint64();std::string buf;buf.resize(len);read(&buf[0], len);return buf;}std::string ByteArray::readStringVint(){uint64_t len = readUint64();std::string buf;buf.resize(len);read(&buf[0], len);return buf;}
1.2.4.6 将文件内容读取到内存中
/*** @brief 将数据从文件中读取到内存中* @param[in] name 读取的文件路径* @return true 读取成功* @return false 读取失败*/bool readFromFile(const std::string& name);bool ByteArray::readFromFile(const std::string& name){std::ifstream ifs;//以二进制打开ifs.open(name, std::ios::binary);if(!ifs){KIT_LOG_ERROR(g_logger) << "ByteArray::readFromFile open error, errno=" << errno << ", is:"<< strerror(errno);return false;}//用智能指针定义一个char数组 指定析构函数释放该空间std::shared_ptr<char> buf(new char[m_baseSize], [](char *ptr){delete[] ptr;});while(!ifs.eof()) //没有到文件末尾就一直读入{//从文件读取到buf 每次读取一个结点大小的数据量ifs.read(buf.get(), m_baseSize);//从buf写回到内存池 gcount()是真正的从文件读取到的长度write(buf.get(), ifs.gcount());}return true;}
1.2.5 setPosition()/getPosition()
功能:设置/获取当前操作内存指针的位置
/*** @brief 获取当前操作内存指针的位置* @return size_t 返回位置坐标数值*/size_t getPosition() const {return m_position;}/*** @brief 设置当前操作内存指针的位置* @param[in] val 传入准备设置的指针位置数值*/void setPosition(size_t val);//设定内存位置void ByteArray::setPosition(size_t val){//设置内存指针位置超出了当前总容量大小 抛出异常if(val > m_capacity)throw std::out_of_range("set position out of range");m_position = val;//检查内存指针位置 > 使用内存空间大小要进行更新m_size = m_position > m_size ? m_position : m_size;m_cur = m_root;/*移动当前可用结点指针m_cur*///只要设定值val比单个结点容量大小大 认为没达到预期设定位置while(val >= m_cur->size){val -= m_cur->size;m_cur = m_cur->next;}}
1.2.6 clear()
功能:清除当前内存结点中所有内容
/*** @brief 清除当前内存结点中所有内容*/void clear();void ByteArray::clear(){m_position = m_size = 0;//只留下一个结点 其他结点全部清理m_capacity = m_baseSize;Node* temp = m_root->next;while(temp){m_cur = temp;temp = temp->next;delete m_cur;}m_cur = m_root;m_root->next = nullptr;}
1.2.7 getBaseSize()
功能:获取单个结点容量
/*** @brief 获取内存单个结点存储容量大小* @return size_t*/size_t getBaseSize() const {return m_baseSize;};
1.2.8 getReadSize()
功能:获取剩余可读数据容量
/*** @brief 获取当前内存中剩余可读数据的容量* @return size_t*/size_t getReadSize() const {return m_size - m_position;}
1.2.9 getSize()
功能:获取当前整个内存已经使用的空间大小
/*** @brief 获取当前整个内存已经使用的空间大小* @return size_t*/size_t getSize() const {return m_size;}
1.2.10 toString()/toHexString()
功能:将内存块的内容输出为可显示文本/十六进制文本
/*** @brief 将内存块的内容输出为可显示文本* @return std::string*/std::string toString() const;/*** @brief 将内存块的内容输出为十六进制文本* @return std::string*/std::string toHexString() const;std::string ByteArray::toString() const{std::string s;s.resize(getReadSize());if(!s.size())return s;//不影响内存指针位置 仅仅是显示read(&s[0], s.size(), m_position);return s;}std::string ByteArray::toHexString() const{std::string s = toString();std::stringstream ss;for(size_t i = 0;i < s.size();++i){//一行显示32个字符if(i > 0 && i % 32 == 0)ss << std::endl;//一次显示一个字节 2个字符,不足的要用0补齐ss << std::setw(2) << std::setfill('0') << std::hex<< (int)(uint8_t)s[i] << " ";}return ss.str();}
1.2.11 getReadBuf()
功能:把内存中所有可读部分拿到用户缓冲区中去,从当前内存指针位置开始。从ByteArray中读取数据
/*** @brief 把内存中所有可读部分拿到用户缓冲区中去,从当前位置开始* @param[out] buffers 存储内存内容的缓冲区* @param[in] len 准备读取的长度* @return uint64_t 返回实际读取字节数*/uint64_t getReadBuf(std::vector<struct iovec>& buffers, uint64_t len) const;uint64_t ByteArray::getReadBuf(std::vector<struct iovec>& buffers, uint64_t len) const{len = len > getReadSize() ? getReadSize() : len;if(len == 0)return 0;uint64_t size = len;size_t npos = m_position % m_baseSize;size_t ncap = m_cur->size - npos;Node* cur = m_cur;while(len > 0){struct iovec iov;//当前结点剩余容量大小 > 读取的长度if(ncap > len){iov.iov_base = cur->ptr + npos;iov.iov_len = len;len = 0;}else // 当前结点剩余容量大小 <= 读取的长度{iov.iov_base = cur->ptr + npos;iov.iov_len = ncap;len -= ncap;cur = cur->next;ncap = cur->size;npos = 0;}buffers.push_back(iov);}return size;}
1.2.12 (重载)getReadBuf()
功能:把内存中所有可读部分拿到用户缓冲区中去,从指定内存指针位置开始。从ByteArray中读取数据
/*** @brief 把内存中所有可读部分拿到用户缓冲区中去,从指定位置开始* @param[out] buffers 存储内存内容的缓冲区* @param[in] len 准备读取的长度* @param[in] position 指定读取开始位置* @return uint64_t 返回实际读取字节数*/uint64_t getReadBuf(std::vector<struct iovec>& buffers, uint64_t len, uint64_t position) const;uint64_t ByteArray::getReadBuf(std::vector<struct iovec>& buffers, uint64_t len, uint64_t position) const{len = len > getReadSize() ? getReadSize() : len;if(len == 0)return 0;uint64_t size = len;size_t npos = position % m_baseSize;//找到指定位置所在的内存节点size_t count = position / m_baseSize;Node* cur = m_root;while(count > 0){cur = cur->next;--count;}size_t ncap = cur->size - npos;while(len > 0){struct iovec iov;if(ncap > len){iov.iov_base = cur->ptr + npos;iov.iov_len = len;len = 0;}else{iov.iov_base = cur->ptr + npos;iov.iov_len = ncap;len -= ncap;cur = cur->next;ncap = cur->size;npos = 0;}buffers.push_back(iov);}return size;}
1.2.13 getWriteBuf()
功能:把内存中所有可写部分拿到用户缓冲区中去,从指定内存指针位置开始。向ByteArray中写入数据
/**
* @brief 把内存中所有可写部分拿到用户缓冲区中去,从指定位置开始
* @param[out] buffers 存储内存内容的缓冲区
* @param[in] len 准备读取的长度
* @return uint64_t 返回实际读取字节数
*/
uint64_t getWriteBuf(std::vector<struct iovec>& buffers, uint64_t len);
uint64_t ByteArray::getWriteBuf(std::vector<struct iovec>& buffers, uint64_t len)
{
if(len == 0)
return 0;
//写入前先扩展容量
addCapacity(len);
size_t size = len;
size_t npos = m_position % m_baseSize;
size_t ncap = m_cur->size - npos;
struct iovec iov;
Node *cur = m_cur;
while(len > 0)
{
if(ncap >= len)
{
iov.iov_base = cur->ptr + npos;
iov.iov_len = len;
len = 0;
}
else
{
iov.iov_base = cur->ptr + npos;
iov.iov_len = ncap;
len -= ncap;
cur = cur->next;
npos = 0;
ncap = cur->size;
}
buffers.push_back(iov);
}
return size;
}
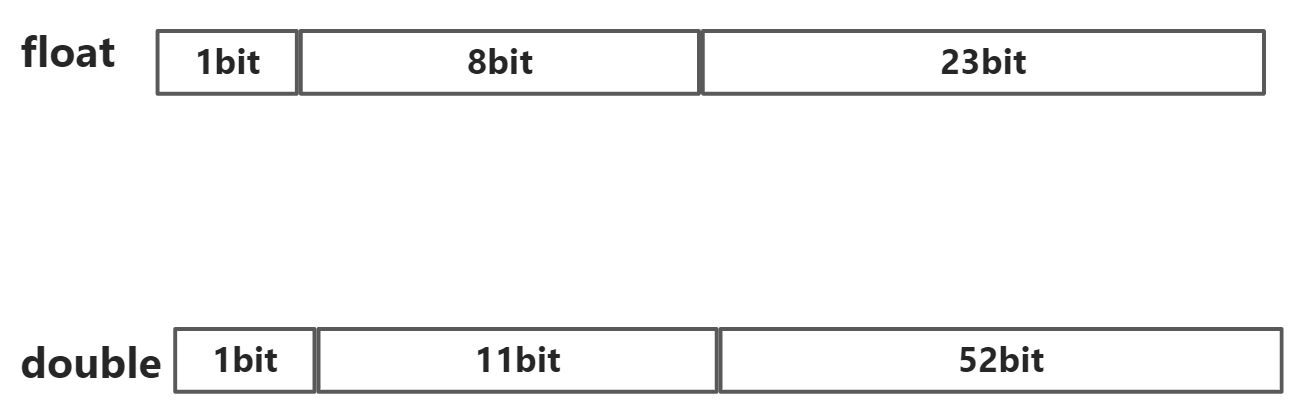
C\C++知识点复习补充:float、double类型存储结构
概念:C\C++中对float数据使用32位存储,double数据使用64位存储。
组成部分 = 符号位 + 指数位 + 尾数位
- 符号位:0为正数,1为负数
- 指数位:存储科学计数法中的指数部分,采用移位存储
- 尾数位:存储尾数
float = 1 bit + 8 bit + 23 bitdouble = 1 bit + 11 bit + 52 bit
例子
- float = 9.125 ,科学记数法表示为 9.125 * 10^0
那么001001称为尾数部分,3称为指数位。由于1.任何时候都不会改变因此不用存储,这使得float的23bit的尾数可以表示24bit的精度,double中52bit的尾数可以表达53bit的精度。9.125 = 9 + 0.125 = 1001 | 0.001 1001.001 使用科学记数法表示:1.001001 * 2^3
注意:存储指数位时采用移位存储,即:基数开始不为0,而是127。指数位最终存储结果:1000 0010
- 最终存储结果:

对于float、double精度位数不同来源于尾数位
十进制中最高位 9 = 1001,也就是1位十进制需要4位二进制表示
float精度 = 24 / 4 = 6位
double精度 = 53 / 4= 13位
由于保存精度有限,因此使用float、double保存金额等数据是不安全的,造成精度丢失。小数转化为二进制的时候可能出现无限循环的可能,最终表示的尾数位只能截断。

若有收获,就点个赞吧
0 人点赞
