airbnb作业.ipynb
airbnb作业1.ipynb
数据清洗:
1.数据空值缺失值处理
查看数据缺失值.是否删除或者填充缺失值
1.1删除:dropna()
1.2填充: 利用其它类似数据信息的均值(相同时间段的)填充
分组
2.删除多余信息列:
drop()
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors=’raise’
# 删除训练集的 date_first_booking,country_destination列train.drop(columns=['date_first_booking','country_destination'],axis=1,inplace=True)# # 删除测试集的 date_first_bookingtest.drop(columns=['date_first_booking'],axis=1,inplace=True)# # 整合训练集和测试集ignore_index:忽略源数据索引,使用新索引data=pd.concat([train,test],axis=0,ignore_index=True)data.head()
转化数据格式:
from datetime import datetimefrom dateutil import parser#数据为数字类型.转化为字符串在转化..........data['first_active'] = pd.to_datetime(data['first_active'],format='%Y%m%d%H%M%S')#利用parser.parse将字符串解析.............data['first_active']=data.first_active.astype(str).apply(lambda x:parser.parse(x))## 利用datetime.strptime(字符串,格式)将字符串转化....data['first_active']=data.first_active.astype(str).apply(lambda x:datetime.strptime(x,'%Y%m%d%H%M%S'))
isoweekday
构建季节函数:
1.提取月列
# 定义一个季节生成函数def gen_season(param): # generateif param in {3,4,5}:return 'spring'elif param in {6,7,8}:return 'summer'elif param in {9,10,11}:return 'autumn'else:return 'winter'# 此函数只适应于北半球温带及寒带,不适合赤道地区和南半球,需要谨慎对待data['season'] = data['month'].apply(gen_season)# import matplotlib.pyplot as pltdata.season.value_counts().plot(kind='pie')
2.提取工作日:
# 构造激活日期的年,月,日特征data['year'] = data.timestamp_first_active.dt.yeardata['month'] = data.timestamp_first_active.dt.monthdata['day'] = data.timestamp_first_active.dt.day# 构造工作日特征data['weekday'] = data.timestamp_first_active.apply(lambda x:x.isoweekday())data.head()datetime.isoweekday(data)工作日提取直接
客户量的累加
# 创建客户量的累积数量,计算当天的客户量加上前面所有的客户量acc_cum = train.groupby('date_account_created')['id'].apply(lambda x:len(x)).reset_index()acc_cum['id']=acc_cum['id'].cumsum()acc_cum
独热编码:One-Hot
年龄,时间,季节
将连续性数据变为离散型后,疏散 数据(类别型数据),数字特征化后,分类器默认是连续可以计算距离的,. 但是 这样数字化后不是有序的是随机分配的.
所以用独热编码将一个特征(季节)的几个值(季度)经过独热编码后变成一个二元特征(1 0)数据会稀疏,
离散特征的编码:
1.离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。
独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
假设某列(或称之为特征)有4种取值方式 初中,高中,本科,硕士,这些是离散无序的需要特征数字化
独热编码之后某一行的学历特征就变成了了4列,比如初中变成了0001,高中变成了0010,本科变成了0100,硕士变成了1000
方法:get_dummies该方法可以讲类别变量转换成新增的虚拟变量/指示变量。
def get(data,name):#name为字符串temp = pd.get_dummies(data[name], prefix=name)data = pd.concat((data,temp),axis=1)return data
pd.get_dummies(data.season, prefix='season') # 独热编码有什么作用?
重尾分布和对数交换
对数变换的特点
- 用数学语言来说,对数变换可以将[1,10]映射到[0,1],将[10,100]映射到[1,2].
- 用通俗的语言来说,对数变换可以对大数值的范围进行压缩,对小数值的范围进行扩展
- 用高逼格的语言来说,对数变换可以压缩分布高端的长尾,可以扩展分布低端的头部
例:
查看用户分布行为
import matplotlib.pyplot as pltimport numpy as np# 导入scipy包from scipy import stats# 查看用户行为的分布sessions.action.value_counts().plot(kind='hist',bins=50)
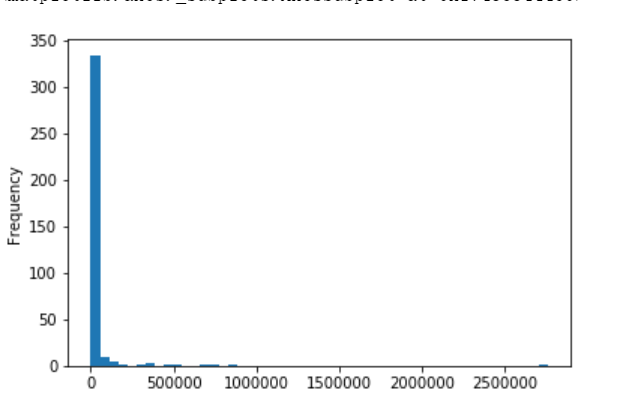
- 行为次数的分布是个长尾分布,长尾分布的特点是均值和方差可能无限大
- 这种情况下常有的分析假设(误差服从独立同分布的正态分布)经常就不会满足
必须让数据尽量满足假设,让方差恒定,即让波动相对稳定
而这种目的可以通过对数转换做到
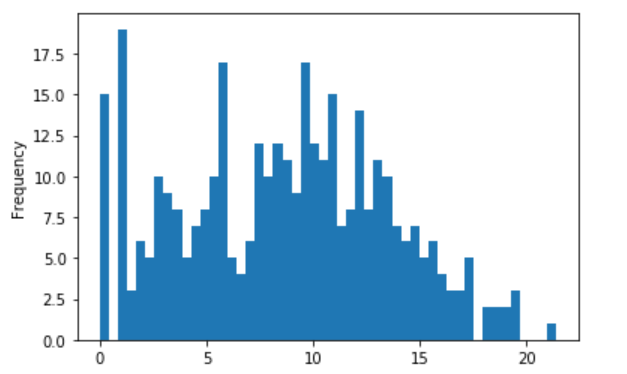
对数交换:np.log2
np.log2(sessions.action.value_counts()).plot(kind='hist',bins=50)
# Box-Cox变换可以明显地改善数据的正态性、对称性pd.DataFrame(stats.boxcox(sessions.action.value_counts())[0]).plot(kind='hist',bins=50)
处理各种特征:
通过分析用户的不同行为 种类
第一步:计算各用户每个action的次数
pt_action_count = sessions.pivot_table(values='device_type',columns='action',index='id',aggfunc='count')
透视表的列信息和上面验证的行为种类个数相同
第二步计算各用户所有action的均值和方差
pt_action_count['act_mean'] = pt_action_count.mean(axis=1)pt_action_count['act_std'] = pt_action_count.std(axis=1)pt_action_count.head()
pt_actiontype_ms = pt_actiontype_count.stack().groupby(id).agg([np.mean,np.std])pt_actiontype_ms.head()
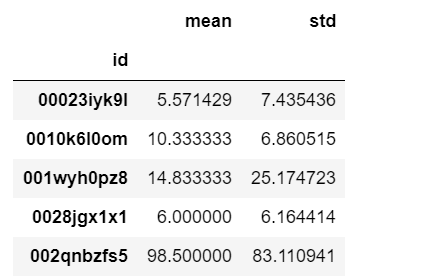
连接俩个表:
pt_actiontype_count = pd.concat([pt_actiontype_count,pt_actiontype_ms],axis=1)pt_actiontype_count.head()
缺失值的处理
1,s删除
2,聚合关系型填充:
比如用户血糖的高低与用户的体重,和
# 第九步,按每个用户的均值填充secs_elapsed的空值sessions['secs_elapsed'] = sessions.groupby('id')['secs_elapsed'].transform(lambda x:x.fillna(x.mean()))sessions.head()
lookup——对应为空的数据填充

若有收获,就点个赞吧
0 人点赞
