一.行的多层索引
1.groupby 聚合俩个字段后出现多层索引:MultiIndex
data=mult.groupby(['地区','年份'])['populations'].mean()

2.构造多层索引”pd.MultiIndex.from_
1.乘积法: product
俩个子列表元素相互乘
multindex1=pd.MultiIndex.from_product([['上海','北京','深圳'],[2010,2018]])
2.数组法:arrays
数据一 一对应
multindex2=pd.MultiIndex.from_arrays([['北京','北京','上海','上海','深圳','深圳'],[2010,2018,2010,2018,2010,2018]])
3.元组法:
参数直接输入多层索引
multindex3=pd.MultiIndex.from_tuples([('上海', 2010),('上海', 2018),('北京', 2010),('北京', 2018),('深圳', 2010),('深圳', 2018)])
4,将三种方法构建多级索引用于数据返回dataframe
创建dataframe, 数据data传入列的value,index=多级索引,columns=[新命名列]
给索引重新命名:
data3.index.names=[‘city’,’year’]
data3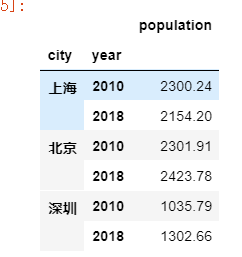
二 .列的多层索引
构造数据:columns 构建俩层列表每个子列表对应一层索引
columns = pd.MultiIndex.from_product([['张三丰', '张无忌', '张翠山'],['实际战力', '爆发战力']])data = [[np.NaN,np.NaN,96.0,100,88.5,90.0],[90.2,90.4,98.0,50,88.5,90.0],[95,95.4,96.0,-np.inf,np.NaN,np.NaN],[96,97.4,98.0,100,np.NaN,np.NaN]]# 构造战力值(Combat Effectiveness)ce = pd.DataFrame(data, columns=columns)ce
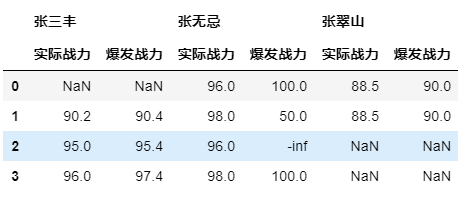
索引查看:
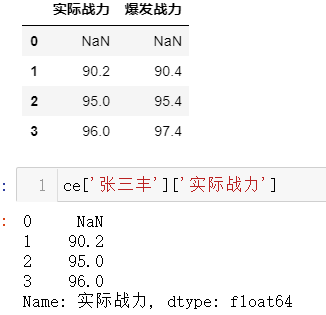
构造一个索引切片对象 IndexSlice
idx=pd.IndexSlicece.loc[:,idx[:,'实际战力']]ce.loc[:,idx['张翠山','实际战力']]

逗号左边对外层索引,右边对外层索引:
idx=pd.IndexSlice
ce.loc[:,idx[:,’实际战力’]]
三.行,列索引一起加上:
创建索引,创建dataframe,index,value都加上创建的多层索引
四. 行列转化
1.test=ce1.unstack(level=1)
2.test.stack(level=1)
五.删除列索引:
五.删除列索引数据不变
第一层,按列删除索引
test.droplevel(1,axis=1)
**
六.特征交叉:
test.columns = ['张三丰年轻女孩在身旁实际战力','张三丰实际战力自己单独一人','张三丰爆发战力年轻女孩在身旁','张三丰爆发战力自己单独一人','张无忌实际战力年轻女孩在身旁','张无忌实际战力自己单独一人','张无忌爆发战力年轻女孩在身旁','张无忌爆发战力自己单独一人','张翠山实际战力年轻女孩在身旁','张翠山实际战力自己单独一人','张翠山爆发战力年轻女孩在身旁','张翠山爆发战力自己单独一人']
将多层列索引交叉合并为一层索引.

若有收获,就点个赞吧
0 人点赞
