- https://www.yuque.com/u2282626/wzx5os/kdfneb">后接merge和concat表连接:https://www.yuque.com/u2282626/wzx5os/kdfneb
- 1.读取;
- 2.查看数据类型信息:
- 3.转化格式方法:
- 4.apply函数(map)
- 5.每列首字母大写
- 5.1将price中的万去掉转化为浮点型(90万)-90
- 5.2 寻找值是否在一个字符串里(国4)
- 5.3any()布尔判断值是否为true
- 6.值计算:(series.value_counts())
- 7.画图: import matplotlib.pyplot
- 8.基于统计学异常值检测
- 9.df.groupby分组显示
- 10.transform(函数(sum))
后接merge和concat表连接:https://www.yuque.com/u2282626/wzx5os/kdfneb
数据清洗案例:演员
1.读取;
import numpy as np
import pandas as pd
csv文件:
a=pd.read_csv(‘文件名’)
xslx文件
a=pd.read_excel(文件名)
a.head() #读取前5行
变量:skipfooter=2(去掉末尾2行
comment=’#’ ,删除有# 符号的数据
,skiprows=1,(去掉首行)
encoding=’utf8’,(解决编码)
engine=’python’,(解决报警)
thousands=’&’(将数字千分位&转化没)
sep=’,’ 默认逗号,其他时在写
合并列:
#comment='#' ,删除有# 符号的数据,thousands='&'取消数字里的符号df=pd.read_csv('data_test01.txt',skipfooter=2,skiprows=1,encoding='utf-8',engine='python',thousands='&',parse_dates={'birthday':[0,1,2]})# df['year']=df['year'].map(lambda x:x.replace('#',''))df
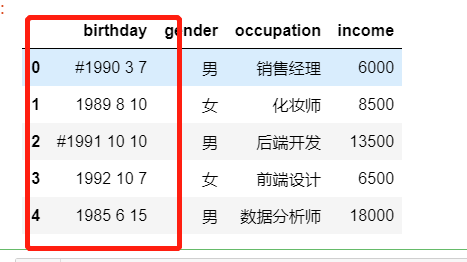
重设索引
df.set_index() 把某一列作为索引df.reset_index(drop=) 把索引重置(0-n),drop参数:是否把现在的索引当成你的列,相当于多了一个列.
2.查看数据类型信息:
1.a.isnull().any()
2.a.info():查看数据信息(对象类型,有几条数据,索引,列数,每列类型及空值)
3.a.describe(include=[‘object’]):默认查看数值型数据信息,加上include表示包含查看哪些数据类型.
销售数量 应收金额 实收金额count 6575.000000 6575.000000 6575.000000mean 2.385095 50.479095 46.321442std 2.373712 87.608147 80.987671min -10.000000 -374.000000 -374.00000025% 1.000000 14.000000 12.32000050% 2.000000 28.000000 26.60000075% 2.000000 59.599998 53.000000max 50.000000 2950.000000 2650.000000
3.转化格式方法:
转化为日期格式: to_datetime()
转化为字符串: astype(‘str’)
4.列索引的设置与重置
#重命名行名(reset_index):排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值data.reset_index(drop=True,inplace=True)data.set_index()
4.apply函数(map)
定义函数:def
lambda x:x[]
map:可以传入字典,旧列名和新列名一一对应,单列
apply: 不可以传字典, 可以传多列.
5.每列首字母大写
wine['Mjob']=wine.Mjob.str.capitalize()wine['Fjob']=wine['Fjob'].apply(lambda x:x.capitalize())wine
5.1将price中的万去掉转化为浮点型(90万)-90
1.去除不符合的值a=a[a['New_price']!='暂无']2.将字符串里的万去掉#第一种利用replace替换为空a['New_price']=a['New_price'].apply(lambda x : x.replace('万',''))#第二种:利用切片切到万前面# a['New_price']=a['New_price'].apply(lambda x : x[:-1])#第三:利用字符串转化为列表,以万为分割符# a['New_price']=a['New_price'].apply(lambda x : x.split('万')[0])3.将字符串格式转化为浮点型a['New_price'].astype(np.float64,errors='ignore')
5.2 寻找值是否在一个字符串里(国4)
bo=a.Discharge.apply(lambda x:'国4'in x)
5.3any()布尔判断值是否为true
any()
为空或者都是False
有一个true就为true
1.用anyany(s15['销售年份']!=2015)2.用count_values()计算值不同
6.值计算:(series.value_counts())
结果为series
统计一列中不同值的个数
df[‘’]
7.画图: import matplotlib.pyplot
(pandas里的包)
pandas里底层的绘图也是matplotlib包里的绘图包后
series.plot
mat-矩阵,plot-绘图 lib-库
params: 形参
attribute:属性
argument:实参
统计值出现 次数:value_counts()
#导入画图包mat-matlab软件的一部分库import matplotlib.pyplot as plt# 换字体plt.rcParams['font.sans-serif']=['SimHei'] #plt是matplotlip包的缩写,他修改了参数# kind是图表类型a.season.value_counts().plot(kind='bar')#python的画图函数(plot)#对季度的值的个数进行统计绘图a.season.value_counts().plot(kind='pie')plt.show()# 图显示
解决负号不出现的方法:
1 import matplotlib.pyplot as plt2plt.rcParams['axes.unicode_minus']=False
8.基于统计学异常值检测
1.三西格玛原则判断异常值:正态分布
μ为分布的平均值,而σ为标准差:
在统计上,68–95–99.7原则是在正态分布中,距平均值小于一个标准差、二个标准差、三个标准差以内的百分比,更精确的数字是68.27%、95.45%及99.73%。
9.df.groupby分组显示
场景: 分组,聚合,排序, 空值聚合填充
比数据库的分组排序简单.先分组,在用一个排序函数就可以.x——相当于分组,一个组一个组分开.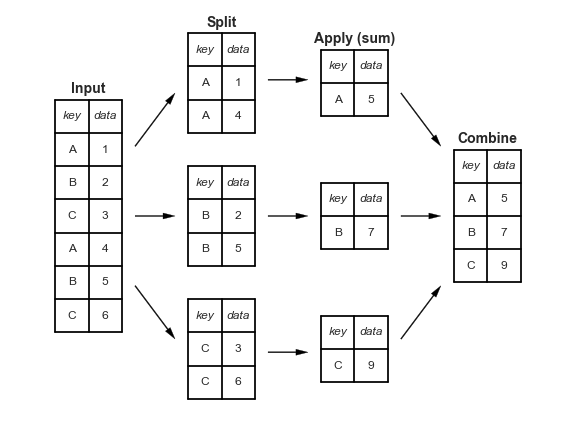
9.1.解决 表多出的聚合列 或者索引
group_keys=”” : 将聚合的组字段是否做为分组的字段.会出来索引套索引的相同的列
在索引的基础上让他不重复出现
as_index=False :将聚合的字段是否作为索引.,变为dataframeq
去掉索引
# 求和后(df)在索引也可以可以接['','']df.groupby(by=lable|list of lable,as_index=,group_keys="").sum()#求排序后的top3个df.groupby(by=列名|['列名','列名'],as_index=,group_keys="")['',''].sum().apply(lambdax:x.sort_values(by='',ascending=False)[:3]#x代表分组后的每一个组数据块进行排序
9.2.生成series,如果要变成dataframe
生成series,如果要变成dataframe1.group()[[列名]]2.group().reset_index3.group(as_index=False)temp =s1.groupby(['销售年份','销售代表ID'])['销售额'].sum().reset_index()temp
9.3.sum()
9.4.案例模板求topn :
多层索引
多变少,分组聚合,在分组排序求前几( apply)/nlargest()
分组求和在分组排序[nlargest(5)] 代替apply排序找
sort_valeus:全局排序,俩层(字段)索引排序在组内排序,必须在聚合一下.
:单层索引一个字段
按照年分组排序,
1.nlargest(),省略了group后的apply(lambda x:x.sort_values(by=””,asscending=))排序
#计算每年销量的top3s1.groupby(['销售年份','销售代表ID'],as_index=False]).sum()['销售额'].groupby('销售年份',group_keys=False).nlargest(5)
- 2. 按年份和区域对销售额分组求和取销售额前3 个:俩个groupby
# 分组求和在分组排序sale_merge_district = s3.groupby(['销售年份','区域'])[['销售额']].sum().groupby('销售年份',group_keys=False).apply(lambda x:x.sort_values(by='销售额',ascending=False)[:3])sale_merge_district
10.transform(函数(sum))
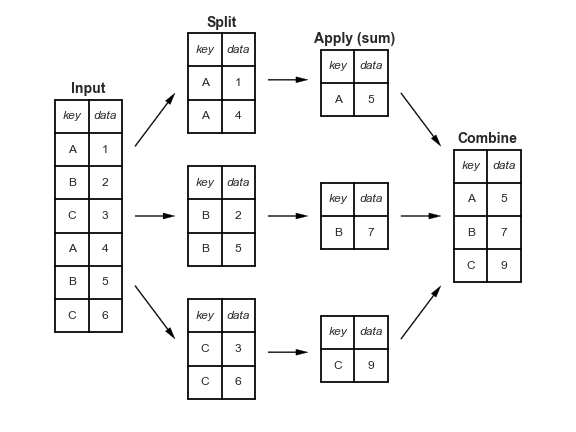
1.解决求和后不同列计算时个数不同不能直接运算,
利用apply 需要聚合后多加一个列# transform () 对每一个数据都进行转化,传入需要的结果df1.groupby('order')[['ext price']].transform('sum')df1['percent_of_total']=df1['ext price']/df1.groupby('order')['ext price'].transform('sum')df1
total=df2.groupby('order')['ext price_y'].sum().rename('order_total')df3=pd.merge(df1,total,how='left',on='order')df3['parenr_of_total']=df3['ext price']/df3['order_total']

若有收获,就点个赞吧
0 人点赞
