1.搜索技术理论基础
1.1.Lucene原理图:

1.2.数据查询方法
1.2.1顺序扫描法
算法描述:
所谓顺序扫描,例如要找内容包含一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头
看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,知道扫描完所有的文件。
优点:
缺点:
使用场景:
数据库中的like关键字模糊查询
文本编辑器的Ctrl + F 查询功能
1.2.2倒排索引(Lucene)

优点:
查询准确率高
查询速度快,并且不会因为查询内容量的增加,而使查询速度逐渐变慢
缺点:
使用场景:
1.3.全文检索技术应用场景
应用场景:
1、站内搜索(baidu贴吧、轮胎、京东、淘宝)
2、垂直领域的搜索(818工作网)
3、专业搜索引擎公司(google、baidu)
2.Lucene介绍


3.Lucene全文检索的流程
3.1.索引和搜索流程图
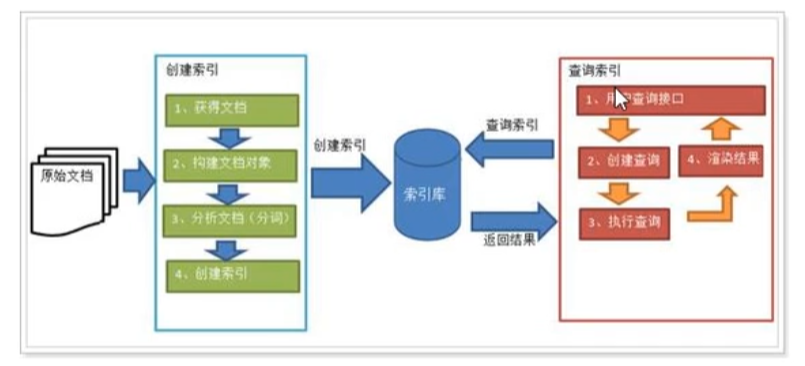
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容
获得文档
创建文档
分析文档
索引文档
2、红色代表搜索过程,从索引库中搜索内容,搜索过程包括:
创建查询
执行搜索,从索引库搜索
渲染搜索结果
3.2.索引流程
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
3.2.1原始内容
原始内容就是指要索引和搜索的内容。
原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
3.2.3获得文档(采集数据)
采集数据分类:
1、对于互联网上网页,可以使用工具将网页抓取到本地生成html文件
2、对于数据库中的数据,直连数据库读取表中的数据。
3、文件系统中的某个文件,I/O流读取文件内容。
3.2.3创建文档

3.2.4分析文档

3.2.5索引文档
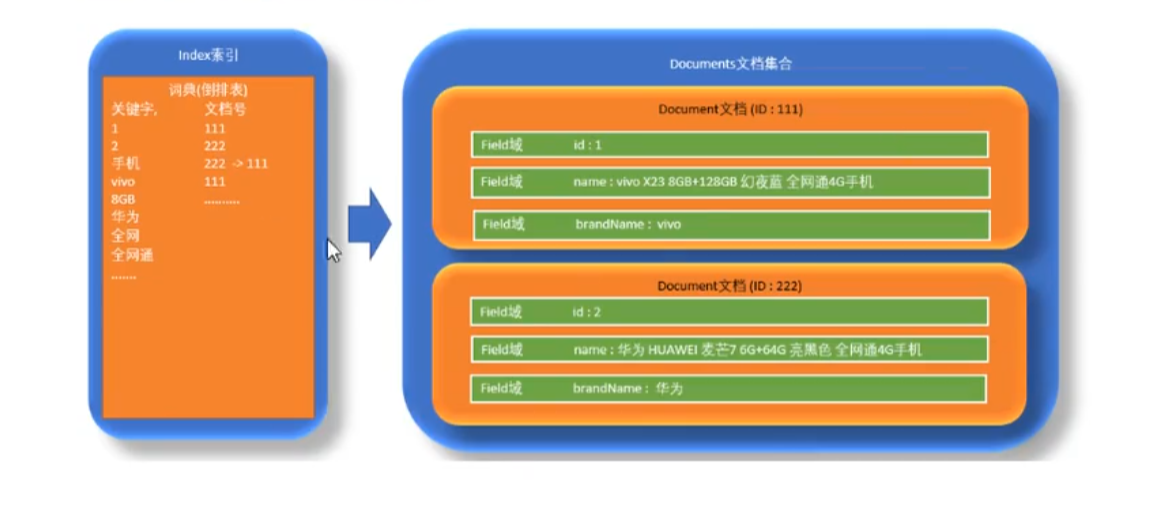
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
创建索引是对语汇单元索引,通过词语找到文档,这种索引的结构叫倒排索引结构。
3.2.6Lucene底层存储结构
3.2.搜索流程
3.3.1用户
就是使用搜索的角色,用户可以是自然人,也可以是远程调用的程序。
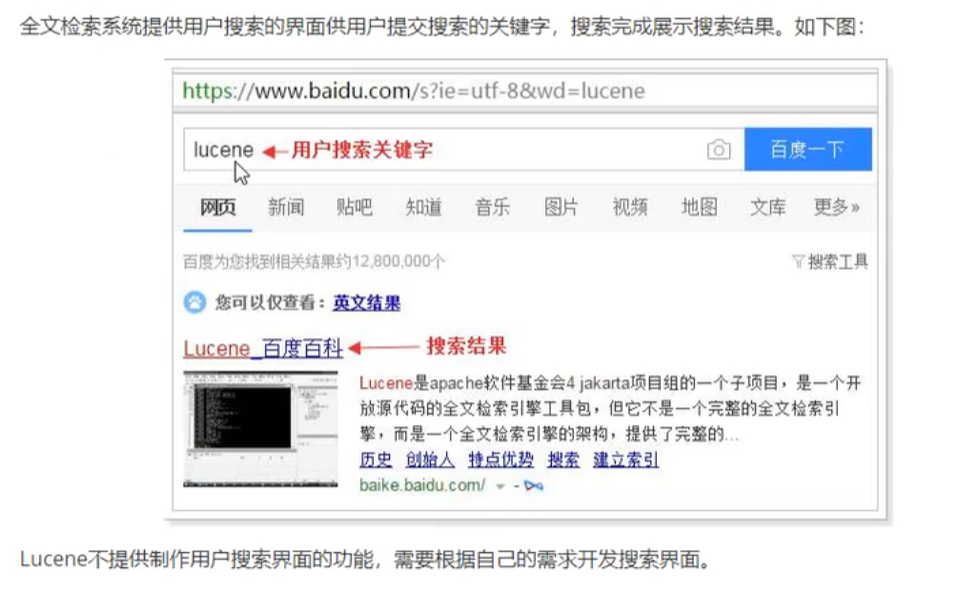
3.3.2用户搜索界面
3.3.3创建查询

3.3.4.执行搜索


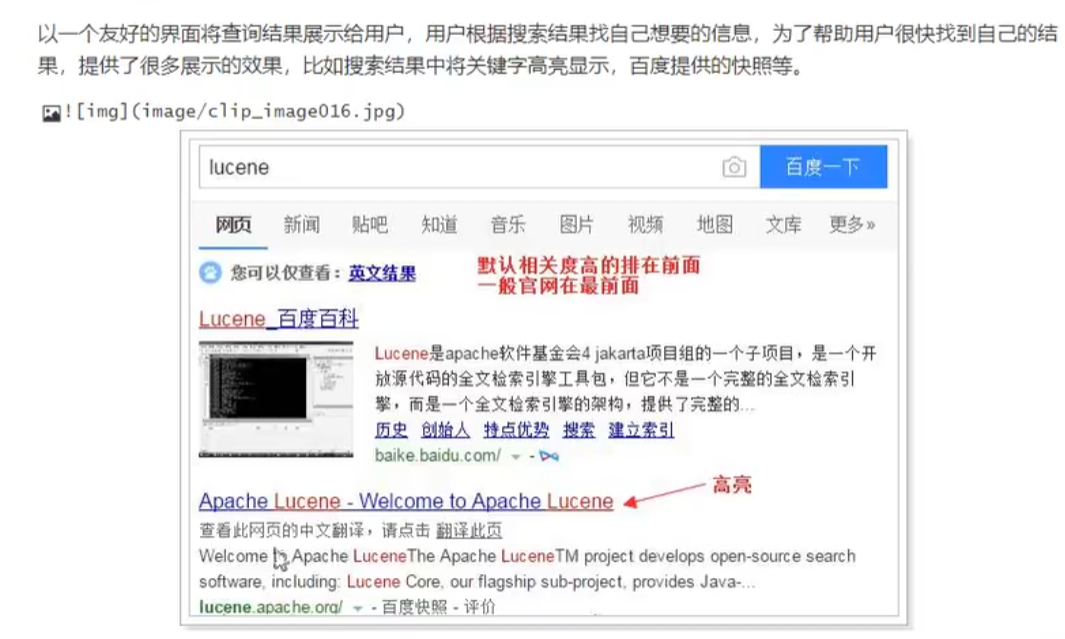
3.3.5渲染结果
4.Lucene入门
4.1.Lucene主备
4.2.开发环境

4.3.创建java工程
5.Field域类型
5.1. Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field
的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
是否分词(tokenized)
是:作分词处理,即将Field值进行分词,分词的目的是为了索引。
比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要
分词后将语汇单元建立索引
否:不作分词处理
比如:商品id、订单号、身份证号等
是否索引(indexed)
是:进行索引。将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索。
比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作
为查询条件。
否:不索引。
比如:图片路径、文件路径等,不用作为查询条件的不用索引。
是否存储(stored)
是:将Field值存储在文档域中,存储在文档域中的Field才可以从Document中获取。
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否:不存储Field值
比如:商品描述,内容较大不用存储。如果要向用户展示商品描述可以从系统的关系数据库中获取。
5.2. Field常用类型
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择:
5.2. Field常用类型
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择: 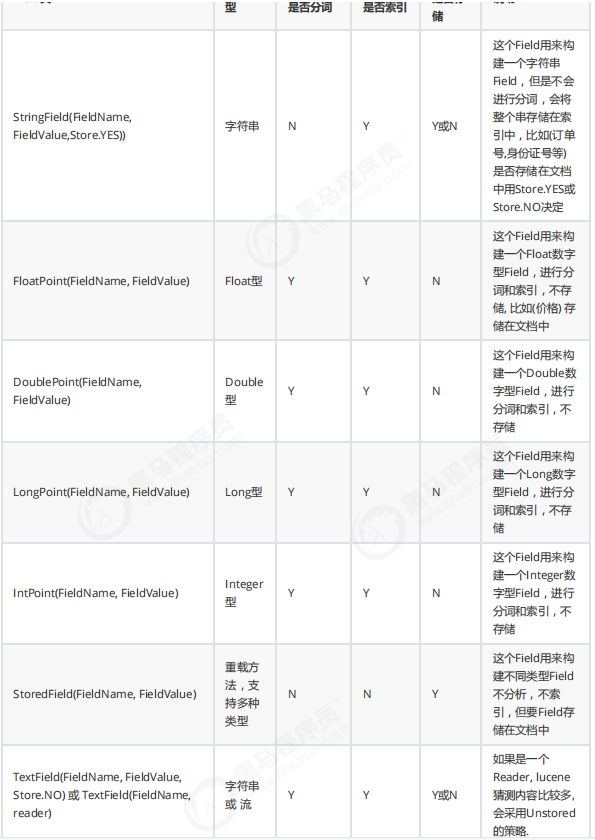

5.3. Field修改
5.3.1. 修改分析
图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值。
图书名称:
是否分词:要分词,因为要根据图书名称的关键词搜索。
是否索引:要索引。
是否存储:要存储。
图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,因 为lucene对数字型的
内容要特殊分词处理,需要分词和索引。
是否索引:要索引
是否存储:要存储
图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。
不存储是不在lucene的索引域中记录,节省lucene的索引文件空间。
如果要在详情页面显示描述,解决方案:
从lucene中取出图书的id,根据图书的id查询关系数据库(MySQL)中book表得到描述信息
5.3.2. 代码修改
6. 索引维护
6.1. 需求
管理人员通过电商系统更改图书信息,这时更新的是关系数据库,如果使用lucene搜索图书信息,需要
在数据库表book信息变化时及时更新lucene索引库。
6.2. 添加索引
调用 indexWriter.addDocument(doc)添加索引。
参考入门程序的创建索引。
6.3. 修改索引
更新索引是先删除再添加,建议对更新需求采用此方法并且要保证对已存在的索引执行更新,可以先查
询出来,确定更新记录存在执行更新操作。
如果更新索引的目标文档对象不存在,则执行添加
代码

若有收获,就点个赞吧
0 人点赞
