饥人谷java体系课
Collection的体系
List
ArrayList
本质上是一个数组
:::info
jdk 7情况下
ArrayList list=new ArrayList();//底层创建了长度为10的Object[]数组elementData
list.add(123);//=elementData[0]=new Integer(123);
……
list.add(11);//如果此次的添加导致底层elementDAta数组容量不够时,则扩容。默认情况下,扩容为原来的1.5倍,同时需要将原有的数组中的数据复制到新的数组中
jdk 8中ArrayList的变化
ArrayList list=new ArrayList();//底层Object[] elementData初始化为{}。并没有创建长度为10的数组。
list.add(123);//第一次调用add()时,底层才创建了长度为10的数组,并将数据123添加到elementData[0]
:::
构造器
//直接newpublic ArrayList()//可以传入已经存在的Collectin集合public ArrayList(Collection<? extends E> c)//可以设置集合的初始容量public ArrayList(int initialCapacity)
方法
:::info
• R:
size() 元素个数
isEmpty() 是不是为空
contains() 是不是包含指定元素
for() 循环遍历
stream()
• C/U:
add() 添加一个元素
addAll() 将一个集合中的元素全部加入
retainAll(Collection c) 与当前c相比,存在的都保留
• D:
clear() 删除所有元素
remove() 删除指定元素
removeAll() 从当前集合中移除传入集合中所有的元素
:::
扩容实现:add时判断容量,然后根据容量大小创建一个容量大小为之前1.5倍的集合,将原有的数据全部放入新的集合
Set
无序的、不可重复的
判断重复:equals()方法
Java世界⾥第⼆重要的约定:hashCode
- 同⼀个对象必须始终返回相同的hashCode
- 两个对象的equals返回true,必须返回相同的hashCode
-
HashSet
LinkedHashSet
作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据的前一个数据和后一个数据
采用双向链表
保证和插入的顺序一样
优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSetMap
接口:
C/U:
put() 添加数据
putAll() 把另外一个map中的数据放入R:
get() 得到对应key的value
size() 里面元素个数
containsKey() 判断是否包含指定key
containsValue() 判断是否包含指定value
keySet() 返回map的所有key
values() 返回map的所有value
entrySet() 返回map的键值对D:
HashMap
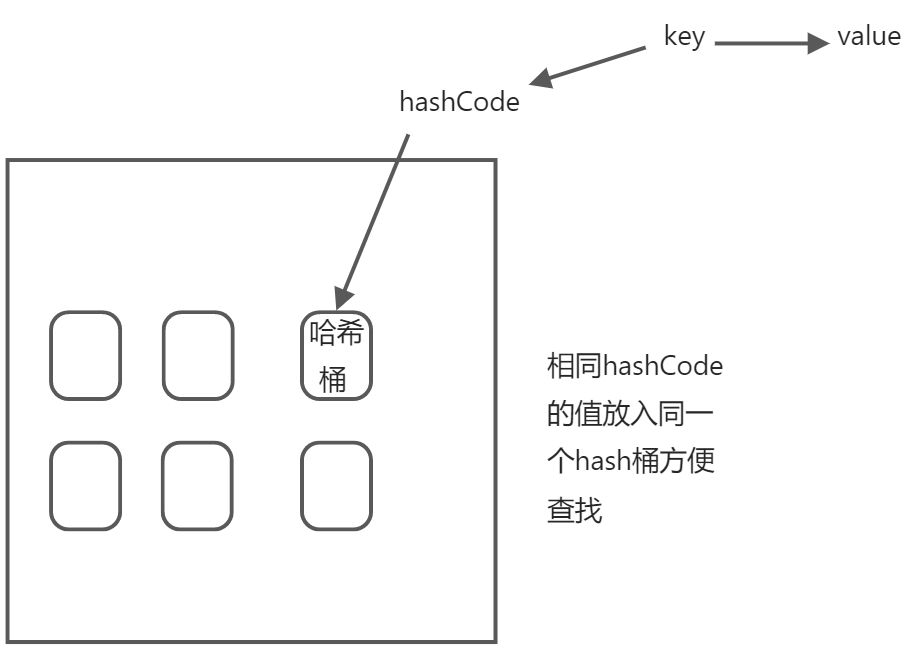 :::info
HashMap map=new HashMap();
:::info
HashMap map=new HashMap();
在实例化以后底层创建了一个长度为16的数组Entry[] table。
……可能已经执行过多次put…….
map.put(key1,value1);
首先调用key1所在类的HashCode()计算key1的哈希值,此哈希值经过某种算法计算以后,得到Entry数组中的存放位置。
如果此位置上数据为空,此时的key1-value1添加成功———情况1
如果此位置上数据不为空(以为存在一个或多个数据(以链表的形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
如果key1的哈希值与已经存在数据的哈希值都不相同,此时key1-value1添加成功———情况2
如果key1的哈希值与已经存在数据的某一个的哈希值相同,继续比较;调用key1类所在的equals()方法,比较:
如果equals()返回false:此时key1-value1添加成功——-情况3
如果equals()返回true:使用value1替换相同的key的value值。补充:关于情况2和情况3,此时key1-value1和原来的数据以链表的形式存储
正在不断的添加过程中会涉及到扩容问题,默认的扩容方式:当超出临界值(且要存放的位置非空),扩容为原来容量的2倍,并将原有的数据复制过来。 :::
HashMap扩容过程
- capacity 即容量,默认16。
- loadFactor 加载因子,默认是0.75
- threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍。
HashMap的容量是有上限的,必须小于1<<30,即1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为Integer.MAX_VALUE(  ,即永远不会超出阈值了)。
,即永远不会超出阈值了)。
JDK8的扩容机制
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让
 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!) - 如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
HashMap线程不安全性
它不是线程安全的
会出现HashMap死循环:在多线程环境下扩容的时候有可能出现死循环链表
在hashmap调用put添加元素时,它会调用addEntry()这个方法,如果多个线程对同一数组位置同时调用这个方法,会同时得到头节点,都写入新的节点,那么写入操作就会被覆盖
删除键值对时,多个线程也都会取得现在这个状态下的头节点,然后各自计算操作,然后写回,但是其他线程可能已经写回会覆盖其他线程的修改
在扩容方面,addEntry中加入新的键值对后键值对总数超过阈值的限定之后会调用一个resize方法,这个操作会形成一个新的容量的数组,然后对原数组的的所有键值对计算写入新的数组,之后指向新生成的数组。当多个线程同时出现总数量超过阈值的情况,最后也只有一个线程生成的新数组被赋给变量,其他线程均会丢失。而当某些线程已经完成赋值而其他线程刚开始扩容的时候,就会用已经被赋值的table作为原始数组,也会有问题ConcurrentHashMap
并发HashMap适合多线程使用HashMap在Java 7+后的改变:链表->红⿊树
Hash桶中个数是有限的但对象是无限的,当有特殊原因有大量数据有相同的hashcode,这个时候这个hash桶的性能会恶化,因此在jdk7之后把链表变成了红黑树java8与java7对比
:::info 1.new HashMap():底层没有创建一个长度为16的数组
2.jdk8 底层的数组是Node[],并非Entry[]
3.首次调用put()方法时,底层创建长度为16的数组
4.jdk7 的底层结构只有数组+链表。jdk8中底层结构:数组+链表+红黑树
当数组的某一个索引位置上的元素以链表的形式存在的数据个数>8且当前数组长度超过64时,此时此索引位置上的数组采用红黑树存储。
DEFAUL TINITIAL_CAPACITY : HashMap的默认容量,16
DEFAULT_LOAD_FACTOR: HashMap的默认加载因子:0.75
threshold:扩容的临界值,=容量填充因升 160.75=12
TREEIFY THRESHOLD: Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量。:64
:::
TreeSet和TreeMap
TreeSet
保证数据是有序的
根据Comparator进行排序,默认从大到小
内部结构是红黑树(一种二叉树)
二叉树
根节点的左孩子比它小,右孩子比它大
TreeSet可以减少查找时间,把算法复杂度从线性时间下降到对数时间
Collections工具方法
emptySet(): 等返回⼀个⽅便的空集合
synchronizedCollection: 将⼀个集合变成线程安全的
unmodifiableCollection: 将⼀个集合变成不可变的(也可以使⽤Guava的Immutable)
其他实现
Queue/Deque
Queue 队列 先进先出
存储带优先级元素的集合
peek() 从队列的头去看一个元素是什么但不把它移除
Deque 双端队列
线性集合支持在两端插入删除元素
addFirst()/addLast() 在最前面/最后面插入元素
getFirst()/getLast() 取最前面/最后面的元素
Vector/Stack
Vector被抛弃的集合,是Arraylist的前身
Satck 栈 可以使用双端队列deque代替
LinkedList
ConcurrentHashMap
PriorityQueue
Guava
遇到一些Collections不能满足的一些要求,可以先去搜索Guava看看有没有合适的
Lists/Sets/Maps 跟这些类有关的工具类
ImmutableMap/ImmutableSet 创建不可变的集合
Multiset/Multimap
Multiset 可以存放元素还可以告诉你这个元素存放了几次
Multimap 一个key可以对应多个value
BiMap

若有收获,就点个赞吧
0 人点赞
