基本介绍
正则表达式就是用某种模式去匹配字符串的一个公式,许多语言都支持正则表达式。
public static void main(String[] args) {String content = "1895 iajdijada dsjnda sjidjw 1111";//1. \\d 表示一个任意的数字,因此需要找到四个数字的组合String regStr = "\\d\\d\\d\\d";//2. 创建模式对象(即正则表达式对象)Pattern pattern = Pattern.compile(regStr);//3. 创建匹配器,按照正则表达式的规则去匹配 content字符串Matcher matcher = pattern.matcher(content);//开始匹配while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}

底层逻辑解析
matcher.find()
- 根据指定的规则,定位满足规则的子字符串(比如1895)
- 找到后,将子字符串开始的索引和结束的索引+1 记录到 matcher对象的属性int[] groups。即groups[0] = 0,把该子字符串的结束的索引+1的值记录到 groups[1] = 4
同时记录属性 oldLast 的值为子字符串的结束的索引+1的值即4,下次执行find时,就从4开始匹配
group方法
public String group(int group) {if (first < 0)throw new IllegalStateException("No match found");if (group < 0 || group > groupCount())throw new IndexOutOfBoundsException("No group " + group);if ((groups[group*2] == -1) || (groups[group*2+1] == -1))return null;return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();}
根据源码可以看出,最后matcher.group(0) 的返回值是从 content 开始截取字符串[0,4),即从索引为0开始,一直截取到索引为3的地方,结果为1895。
再次调用find方法时,继续从索引为4开始寻找,如果找到的话,会把groups[0]和groups[1]覆盖掉 (29 和 33)。因此自始至终都是输出 matcher.group(0)。考虑分组
String regStr = "(\\d\\d)(\\d\\d)"
正则表达式有() 表示分组,第一个()表示第一组,第2个()表示第2组…
当找到满足条件的字串时(比如1895),还是将索引记录到 int[] groups,其中 groups[0] = 0,groups[1] = 4,这是不变的。
但是因为有了分组,因此我们需要把每一组对应的开始和结束+1都记录在groups中。第一组:groups[2] = 0,groups[3] = 2,表示从[0,2)的字串。 第二组:groups[4] = 2,groups[5] = 4。
下面的步骤就一样了。查看分组内容依然使用 group方法。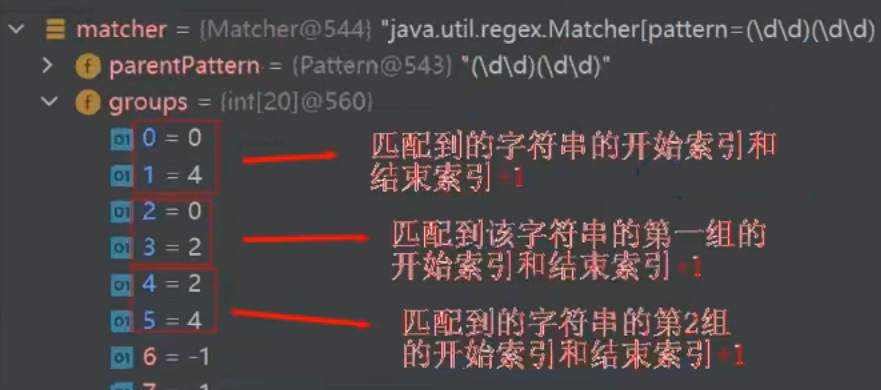
public static void main(String[] args) {String content = "1895 iajdijada dsjnda sjidjw 1111";//1. \\d 表示一个任意的数字String regStr = "(\\d\\d)(\\d\\d)";//2. 创建模式对象(即正则表达式对象)Pattern pattern = Pattern.compile(regStr);//3. 创建匹配器,按照正则表达式的规则去匹配 content字符串Matcher matcher = pattern.matcher(content);//开始匹配while(matcher.find()){System.out.println("找到:" + matcher.group(0));//查看分组内容依然使用 group方法System.out.println("第一组:" + matcher.group(1));System.out.println("第二组:" + matcher.group(2));}}
正则表达式语法
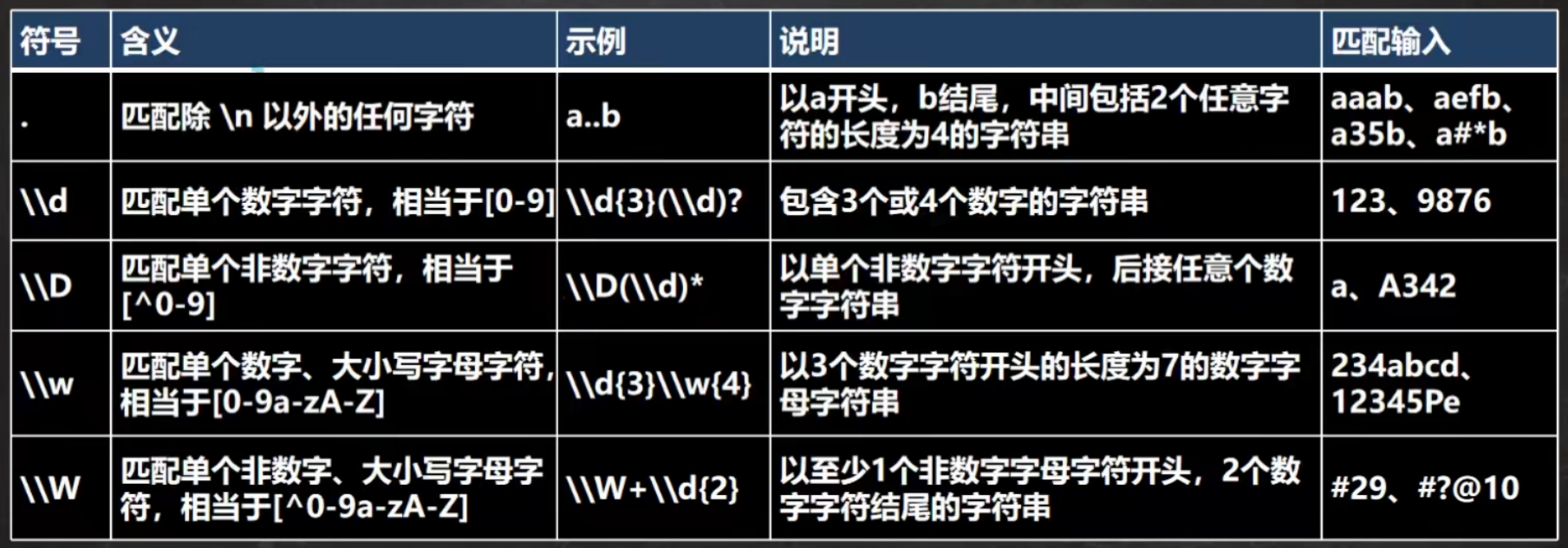
字符匹配符
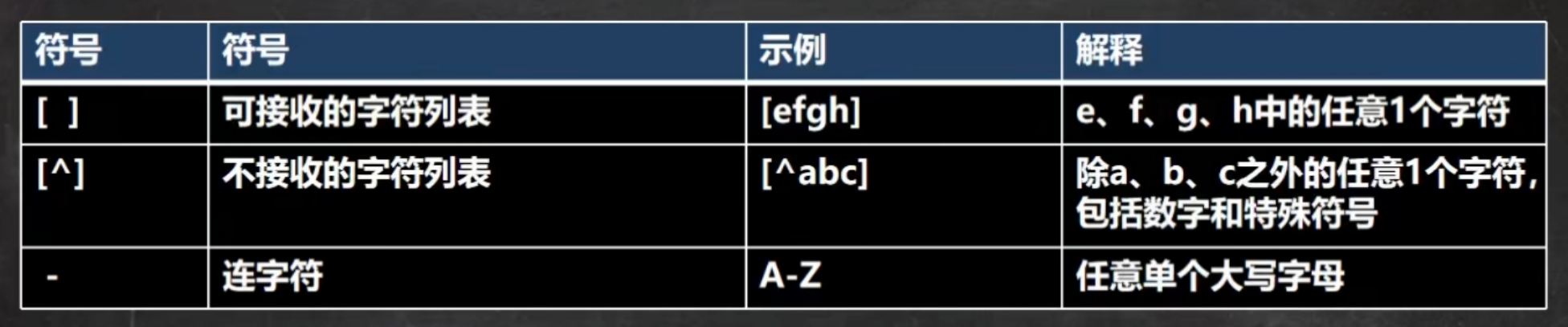
注:[0-9]表示可以匹配0-9之间的任意字符,[a-z]表示可以匹配任意小写字母。[^0-9]表示可以匹配不是0-9的任意一个字符。public static void main(String[] args) {String content = "1895 iajdijada dsjnda sjidjw 1111";//String regStr = "[0-9]";String regStr = "[abcd]";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到:" + matcher.group(0));}}


注:Java正则表达式默认是区分字母大小写的,如果需要实现不区分大小写,那么需要用到(?i)

- (?i)abc 表示abc都不区分大小写
- a(?i)bc 表示bc不区分大小写
- a((?i)b)c 表示只有b不区分大小写
也可以使用 Pattern.compile(regEx,Pattern.CASE_INSENSITIVE) 表示该正则表达式不区分大小写。
public static void main(String[] args) {String content = "abcabcabc";// String regStr = "abc";String regStr = "(?i)ABC";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}


选择匹配符
在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个,这时需要用到选择匹配符号。
public static void main(String[] args) {String content = "aqqbsssc";String regStr = "a|b|c";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}

限定符
用于指定其前面的字符和组合项连续出现多少次。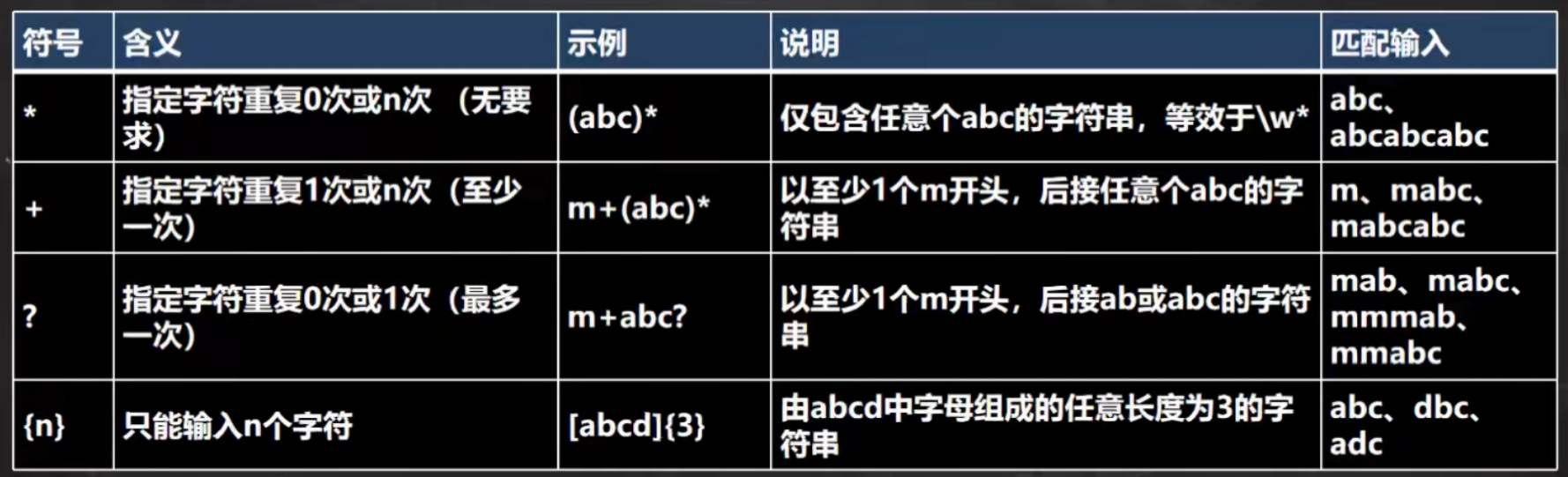

所有的符号都是匹配前一个字符,有括号就匹配括号里的,没有就是前一个字符。
public static void main(String[] args) {String content = "123456789";//String regStr = "\\d{2}";//String regStr = "\\d{2,}"; //匹配两位以上的数字String regStr = "\\d{2,5}"; //匹配2,3,4,5位数字Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}



注:匹配中默认为贪婪匹配原则,即尽可能匹配较大的字符串。比如 \d{2,5},会先去寻找5位满足条件的字符串,然后是四位…最后才是两位。
public static void main(String[] args) {String content = "11111111";String regStr = "1{3,4}";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}
默认先匹配四位,即1111。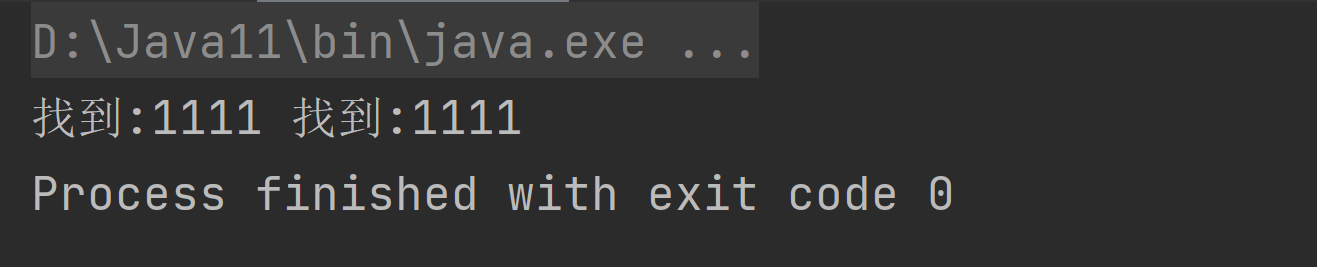
public static void main(String[] args) {String content = "aaa11111111";//String regStr = "a1+"; 匹配 1~∞个1//String regStr = "a1*"; 匹配 0~∞个1String regStr = "a1?"; //匹配0~1 个1Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}



定位符
定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置。
注:1. 除了起始字符匹配的是后面,其他匹配的还是前面。2. 起始和结束指的是整个字符串,而不是截取出的字串。
public static void main(String[] args) {String content = "123aa99cccc";//+修饰[0-9],即必须以至少一个数字开头,后接任意个小写字母String regStr = "^[0-9]+[a-z]*";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.print("找到:" + matcher.group(0) + " ");}}

为什么没有 “99cccc”:因为要求的是整个字符串必须以至少一个数字开头,字串以数字开头是不可以的。
分组
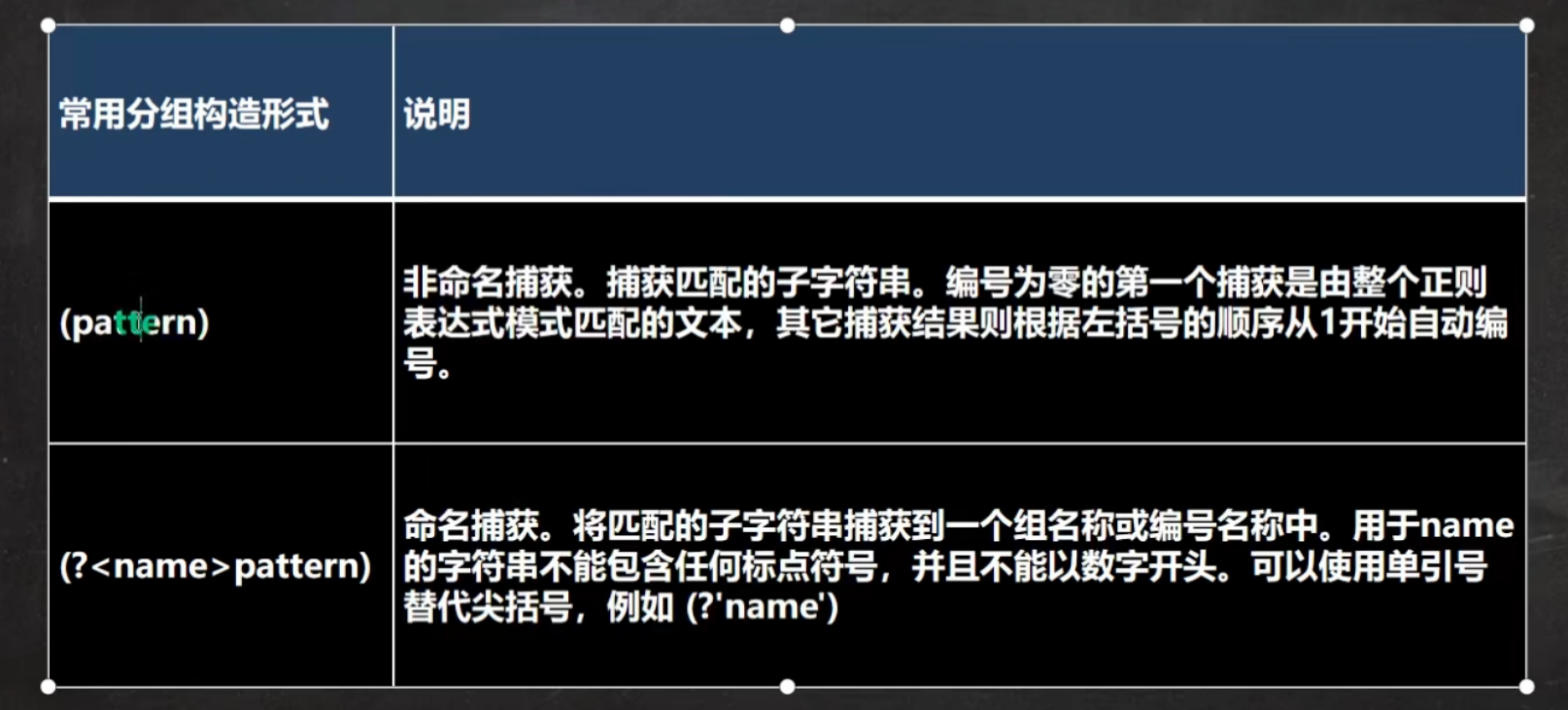
非命名捕获其实就是正常的分组,使用 matcher.group(n) 来输出对应分组的内容。
public static void main(String[] args) {String content = "1895 iajdijada dsjnda sjidjw 1111";//1. \\d 表示一个任意的数字String regStr = "(\\d\\d)(\\d\\d)";//2. 创建模式对象(即正则表达式对象)Pattern pattern = Pattern.compile(regStr);//3. 创建匹配器,按照正则表达式的规则去匹配 content字符串Matcher matcher = pattern.matcher(content);//开始匹配while(matcher.find()){System.out.println("找到:" + matcher.group(0));//查看分组内容依然使用 group方法System.out.println("第一组:" + matcher.group(1));System.out.println("第二组:" + matcher.group(2));}}
命名分组:可以给分组取名,然后根据 matcher.group(name) 输出分组对应的内容。
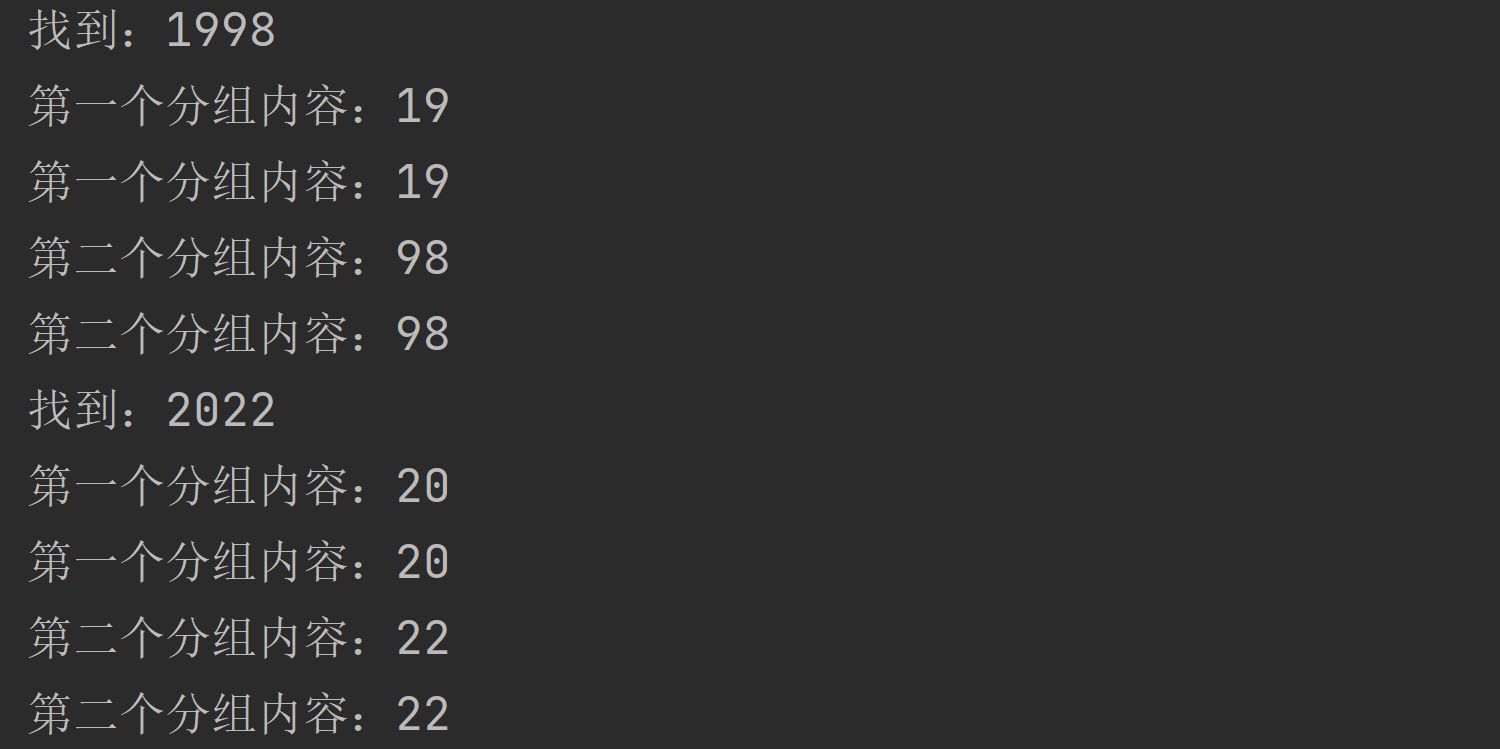
public static void main(String[] args) {String content = "1998absdua2022";//+修饰[0-9],即必须以至少一个数字开头,后接任意个小写字母String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到:" + matcher.group(0));System.out.println("第一个分组内容:" + matcher.group(1));System.out.println("第一个分组内容:" + matcher.group("g1"));System.out.println("第二个分组内容:" + matcher.group(2));System.out.println("第二个分组内容:" + matcher.group("g2"));}}
还有一些其他特殊的分组:
public static void main(String[] args) {String content = "helloMerlin校长 Merlin老师 helloMerlin同学";//等同于 "Merlin校长|Merlin老师|Merlin同学"String regStr = "Merlin(?:校长|老师|同学)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}

public static void main(String[] args) {String content = "helloMerlin校长 Merlin老师 helloMerlin同学";//String regStr = "Merlin(?=校长|老师)";String regStr = "Merlin(?!校长|老师)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}
(?=pattern):找到Merlin关键字,但是只能匹配后面带有 “校长” 和 “老师” 的Merlin。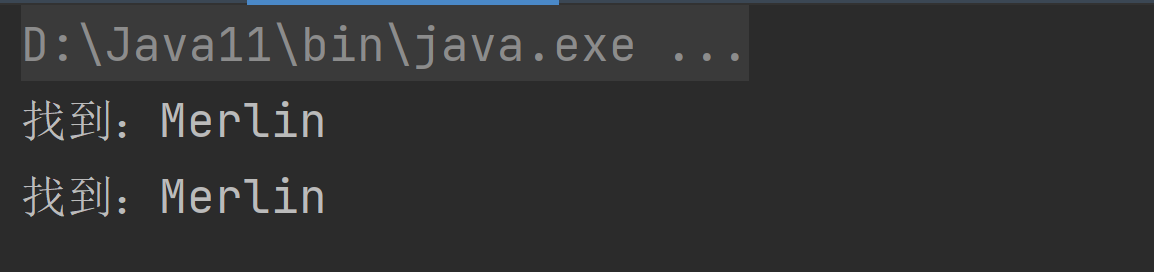
(?!pattern):和上面正好反过来,它是不能匹配后面带有 “校长” 和 “老师” 的Merlin。
反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用:\分组号,外部反向引用:$分组号。
比如:要匹配两个连续的相同的数字:(\d)\1。要匹配五个连续的相同数字:(\d)\1{4}
要匹配个位与千位相同,十位与百位相同的数(如5225,1551等):(\d)(\d)\2\1 ( \2表示第二个分组,即百位。\1表示第一个分组,即千位)
public static void main(String[] args) {//满足前面是一个五位数,然后是一个-号,然后是一个九位数,三三相同(如12345-333999111)String content = "12345-333999111";String regStr = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);String newContent = matcher.replaceAll("你好");System.out.println(newContent);while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}
非贪婪匹配
如果要实现非贪婪匹配,可以在对应表达式最后加上一个 ‘?’ 。
public static void main(String[] args) {String content = "111111";String regStr = "\\d+?"; //非贪婪匹配,这次只匹配1个 (1~∞)//如果+换成*,那么一个也不匹配Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}

Pattern类
pattern对象是一个正则表达式对象。Pattern类没有公共构造方法。要创建一个 Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第一个参数,比如: Pattern r = Pattern.compile(pattern);
Pattern类的matches方法常用于判断 正则表达式是否与整个字符串匹配成功。
Matcher类
Matcher 对象是对输入字符串进行解释和匹配的引擎,与Pattern类一样,Matcher 也没有公共构造方法。需要调用 Pattern 对象的 matcher 方法来获得一个Matcher对象。

public static void main(String[] args) {String content = "hello edu jack tom hello smith hello hssss";String regStr = "hello";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while(matcher.find()){System.out.println("找到:" + matcher.group(0));System.out.println(matcher.start());System.out.println(matcher.end());System.out.println(content.substring(matcher.start(),matcher.end()));}}
start和end实际上就是找到的对应子串 的开始索引和结束索引+1,因此可以使用substring方法截取。
public static void main(String[] args) {String content = "hello edu jack tom hello smith hello hssss";String regStr = "hello";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);//把hello替换为你好,原content不变,返回新的字符串String newContent = matcher.replaceAll("你好");System.out.println(newContent);// while(matcher.find()){// System.out.println("找到:" + matcher.group(0));// System.out.println(matcher.start());// System.out.println(matcher.end());// System.out.println(content.substring(matcher.start(),matcher.end()));// }}

String类中使用正则表达式
replaceAll
//使用正则表达式方式,将 JDK1.3 和 JDK1.4 替换成JDK//因为 . 在正则表达式中是有意义的,因此需要使用\\进行转义content = content.replaceAll("JDK1\\.3|JDK1\\.4","JDK");
验证字符串格式
验证一个手机号,要求必须是以138,139开头的。
content = "13899999999";if(content.matches("1(38|39)\\d{8}")){System.out.println("验证成功");}else{System.out.println("验证失败");}
split
要求按照 # 或者 - 或者 ~ 或者 任意数字 来对字符串进行分割。
public static void main(String[] args) {// \\d+ 表示任意数字String content = "hello#abc-jack12smith~郑州";String[] split = content.split("#|-|~|\\d+");for (String s : split) {System.out.println(s);}}


若有收获,就点个赞吧
0 人点赞
