泛型
泛型的好处


泛型介绍

4. 可以在类声明时通过一个标识表示类中某个类的属性,或者是某个方法返回值的类型,或者是参数类型。
public static void main(String[] args) {Person<String> a = new Person<String>("ss");}class Person<E>{E s;public Person(E s){this.s = s;}public E f(){return s;}}
特别强调:E具体的数据类型在定义Person对象的时候指定,即在编译期间就确定E是什么类型。
泛型的声明与实例化


类似C++的模板。
这里对HashMap的遍历进行泛型改写:!!!!
public static void main(String[] args) {HashMap<String,Student> map = new HashMap<String,Student>(); //带泛型的声明map.put("ss",new Student("ss",20));map.put("mm",new Student("mm",19));map.put("hh",new Student("hh",30));//Set set = map.entrySet(); 不使用泛型的写法Set<Map.Entry<String, Student>> set = map.entrySet();//Set里面的结点类型就是它的泛型,为Map.Entry<String, Student>Iterator<Map.Entry<String, Student>> iterator = set.iterator();//迭代器指向的结点类型就是它的泛型,为Map.Entry<String, Student>while (iterator.hasNext()) {Map.Entry<String,Student> entry = iterator.next(); //原先是ObjectSystem.out.println(entry.getKey() + " " +entry.getValue());}for (Map.Entry<String, Student> entry : set) { //就不用Object了System.out.println(entry.getKey() + " " + entry.getValue());}}
这里有一个很好的写法:带泛型的数据类型(如HashMap)声明子类就用var,就不用泛型担心出错了。

查看源码可以发现,HashMap有
使用细节
2. 在给泛型具体类型后,可以传入该类型或者其子类类型。
public static void main(String[] args) {Dog<A> a = new Dog<>(new A()); //用 new Dog<A>(new A()).var 快捷键Dog<A> b = new Dog<>(new B()); //输入子类}class A{}class B extends A{}class Dog<E>{E e;public Dog(E e) {this.e = e;}}
3. 泛型推荐使用形式
List<Integer> list1 = new ArrayList<Integer>(); // 不推荐List<Integer> list1 = new ArrayList<>(); //推荐,因为编译器会自己进行类型推断
4. 泛型默认为Object
ArrayList a = new ArrayList();ArrayList<Object> b = new ArrayList<>(); //两者等价
如果一个类A里有另外一个类B的对象,并且A需要用B的属性进行排序,最好在B中写一个compare方法(教程上说实现Comparable接口的compareTo方法,但是自己定义也行)。
public int compare(MyDate a,MyDate b){int h = a.year*365 + a.month*30 + a.day;int t = b.year*365 + b.month*30 + b.day;return h-t;}
自定义泛型

class Tiger<T,R,M>{ //Tiger后面泛型,一般把这种类就叫做自定义泛型类R r;M m;T t; // 属性使用泛型// T,R,M是泛型的标识符,一般是单个大写字母,可以有多个public Tiger(R r, M m, T t) { //构造器使用泛型this.r = r;this.m = m;this.t = t;}public void setR(R r){ //方法使用泛型this.r = r;}public M getM(){ //返回类使用泛型return m;}}
重点解释第二点和第三点。
T[] ts = new T[5]; //报错,因为数组在new时不能确定T的类型,因此无法在内存开辟空间static R r2;//因为静态是和类相关的,在类加载时,对象还没有创建(也即r2没有创建)//所以,如果静态方法和静态属性使用了泛型,JVM就无法完成初始化
自定义泛型接口

interface Usb<U,R>{ //自定义接口泛型E e; //错误,因为接口里的属性默认为 public static final,为静态属性R get(U u);void hi(R r);default R method(U u){ //jdk8中使用默认方法System.out.println("默认方法");return null;}}
1. 在继承接口中指定泛型接口的类型
interface IA extends Usb<String,Double>{}//当我们实现IA接口时,指定了U为String,R为Double//因此实现Usb接口的方法时,使用String替换U,使用Double替换Rclass AA implements IA{@Overridepublic Double get(String s) {return null;}@Overridepublic void hi(Double aDouble) {}}
2. 实现接口时确定
class BB implements Usb<String,Double>{//实现接口时,直接指定泛型接口的类型@Overridepublic Double get(String s) {return null;}@Overridepublic void hi(Double aDouble) {}}
3. 不写默认为Object(但是会出现警告)
class CC implements Usb{//等价 class CC implements Usb<Object,Object>,最好还是写上!...}
自定义泛型方法


注:2类型的确定只针对一次调用,可以输入一个Integer,下一条语句还可以输入一个Double.
public<E> fly(E e){...}fly(10); //此时E是Integerfly("ccc") //此时E是String
class Car{ //普通类public<T,R> void fly(T t,R r){} //泛型方法}class Fish<T,R>{ //泛型类public <U,M> void eat(U u,M m,T t,R r){} //泛型方法//可以使用类声明的泛型,也可以使用自己声明的泛型public void hi(T t){} //注意这是 使用了泛型的普通方法,并不是泛型方法}
泛型的继承和通配符

List<Object> a = new LinkedList<String>(); //错误,String不能赋给Object
对不限于直接父类的解释:比如AA继承BB,Object就不是AA的直接父类(类似于爷爷类),但是也可以传入。
class BB{}class AA extends BB{} //Object就不是AA的直接父类public void print(List<?> c){} //随意public void print1(List<? extends AA> c){} //AA及AA的子类们public void print2(List<? super AA> c){} //AA及AA的父类们 可以传入Object
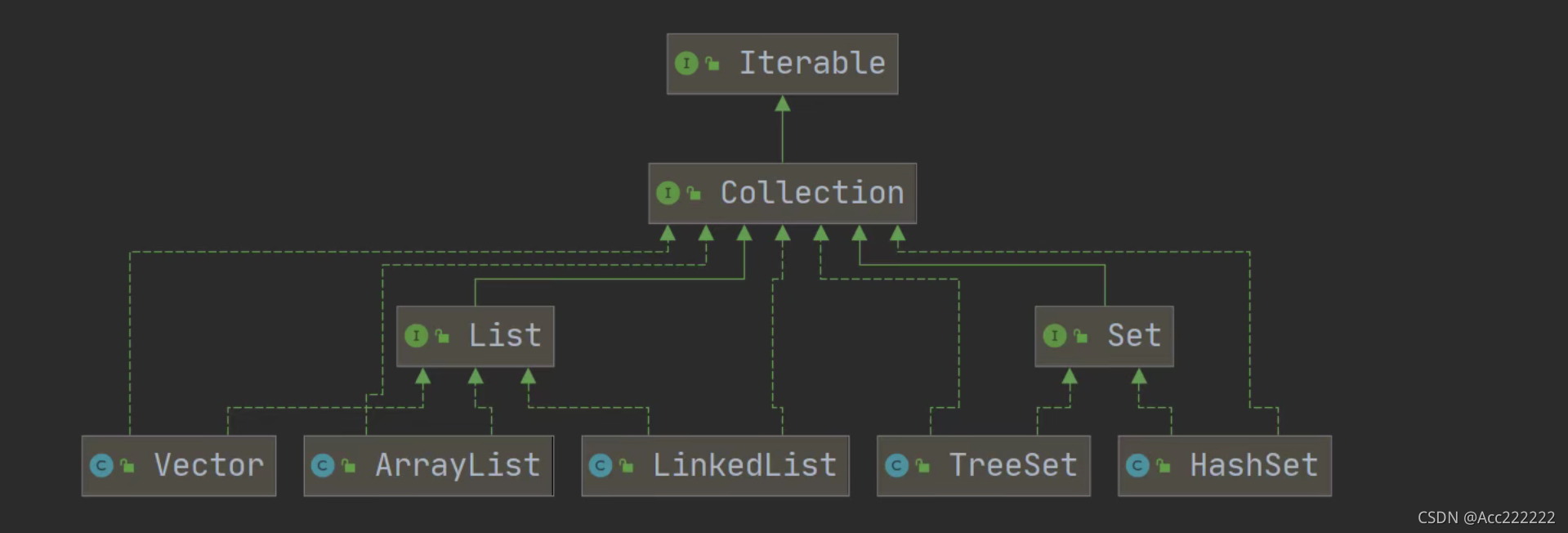
Collection
Collection接口有两个重要的子接口 List和Set,实现子类都是单列集合。
集合体系图

Collection常用方法
Collection常用方法对于Collection以及下属子类都可以用,这里用ArrayList演示。
1. add: 添加单个元素
ArrayList a = new ArrayList();a.add(10); //注意放入的是Integer类,其余同理a.add(true);System.out.println(a); // [10, true]
2. remove:删除指定元素
3. contains:查找元素是否存在
4. size:获取元素个数
5. isEmpty:判断是否为空
6. clear:清空
a.remove(true);System.out.println(a); // [10]System.out.println(a.contains(10)); //trueSystem.out.println(a.size()); // 1System.out.println(a.isEmpty()); //falsea.clear();
7. allAll:添加多个元素(Collection集合)
8. containsAll:查找多个元素是否都存在
9. removeAll:删除多个元素
ArrayList a = new ArrayList();ArrayList b = new ArrayList();b.add(20);b.add(30);a.addAll(b); //只能添加集合类System.out.println(a.contains(b));a.removeAll(b);
遍历方式
1. 使用Iterator迭代器
Iterator iterator = a.iterator(); //得到一个集合的迭代器iterator.hasNext(); //判断是否还有下一个元素iterator.next() // 1.将迭代器往下移动 2.将下移后迭代器指向位置上的元素返回(刚开始在第一个元素的上面一格)


迭代器while循环的构造快捷键—— itit
public static void main(String[] args) {ArrayList a = new ArrayList();for(int i = 0;i<10;i++){a.add(i+10);}Iterator iterator = a.iterator(); //迭代器构造方法while (iterator.hasNext()) { //快捷键:ititObject obj = iterator.next();System.out.println(obj);} //当while循环结束时,iterator指向最后一个元素iterator = a.iterator(); //重置迭代器}
2. 增强for循环(foreach)
增强for循环的底层仍然是迭代器,因此可以理解成简化版本的迭代器遍历。快捷键:I 或者 集合名.for(推荐)。
public static void main(String[] args) {ArrayList a = new ArrayList();for(int i = 0;i<10;i++){a.add(i+10);}for (Object obj : a) {System.out.println(obj);}}

List集合
常用方法


注意这是List集合独有的方法,并且一旦涉及到范围(比如subList方法),总是左闭右开的。List不能单独声明(因为是一个接口),需要用到List的实现子类。
List a = new ArrayList();List b = new LinkedList();List c = new Vector();
ArrayList
注意事项
- ArrayList 可以加入多个null。
2. ArrayList 是由数组来实现数据存储的。
3. ArrayList 基本等同于Vector,但ArrayList是线程不安全的(没有synchronized),在多线程情况下,不建议使用ArrayList。ArrayList底层结构
- ArrayList 中维护了一个Object类型的数组elementData。
trannsient Object[] elementData; // transient 表示瞬间,短暂的,表示该属性不会被序列化
2. 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第一次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
3. 如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍。ArrayList底层源码




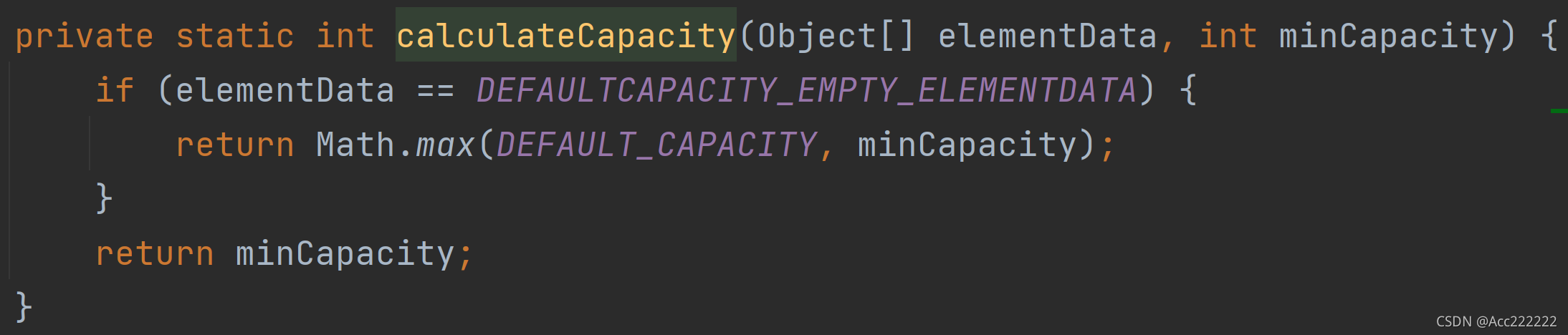
如果数组为初始分配数组,那么就返回最小需求容量和10之间的最大值(注意有初始化参数的并不是DEFAULTCAPACITY…这个数组)。否则返回最小需求容量。
1. modCount 记录集合被修改的次数 2. 如果elementData的大小不够(目前的长度小于最小需求容量),就调用grow方法去扩容。
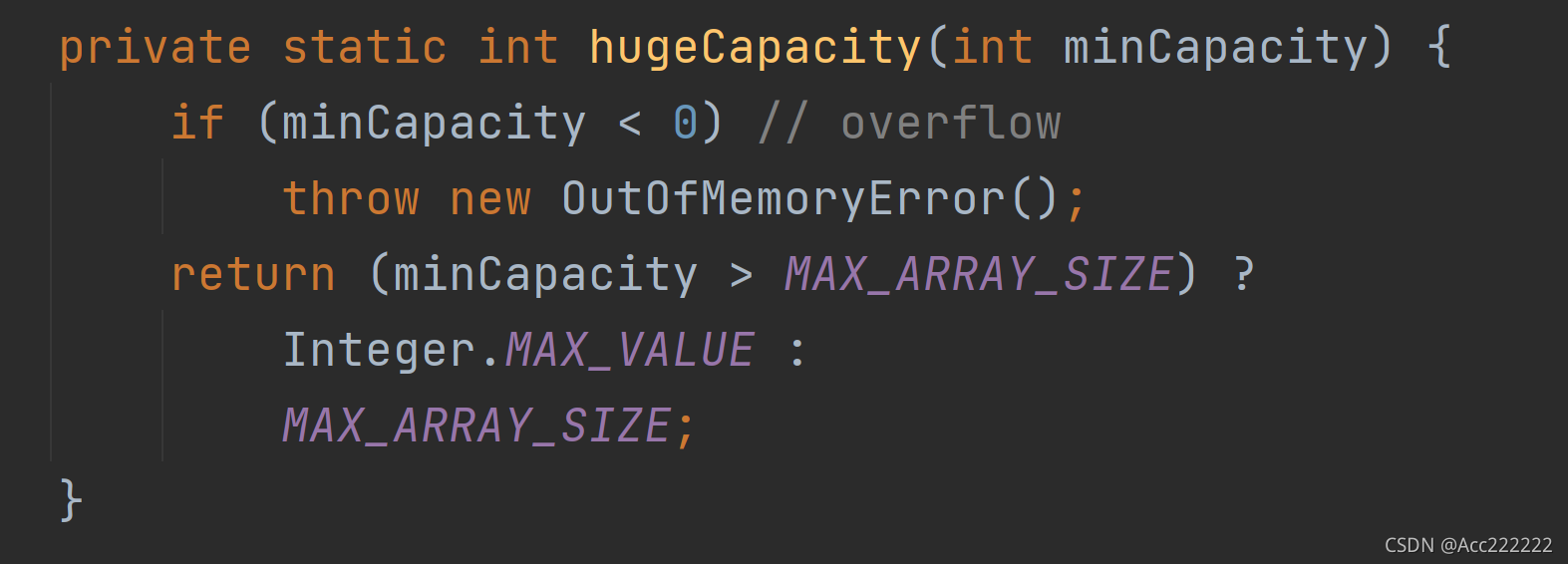
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length; //原先数组的长度// >>1表示/2,把原数组长度*1.5,赋给newCapacityint newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity; //针对第一次,newCapacity为0(0 + 0*0.5),此时minCapacity为10if (newCapacity - MAX_ARRAY_SIZE > 0)//如果超过了系统最大容量,用hugeCapacity判断newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); //用Arrays类的copyOf方法(空余位置为null)}
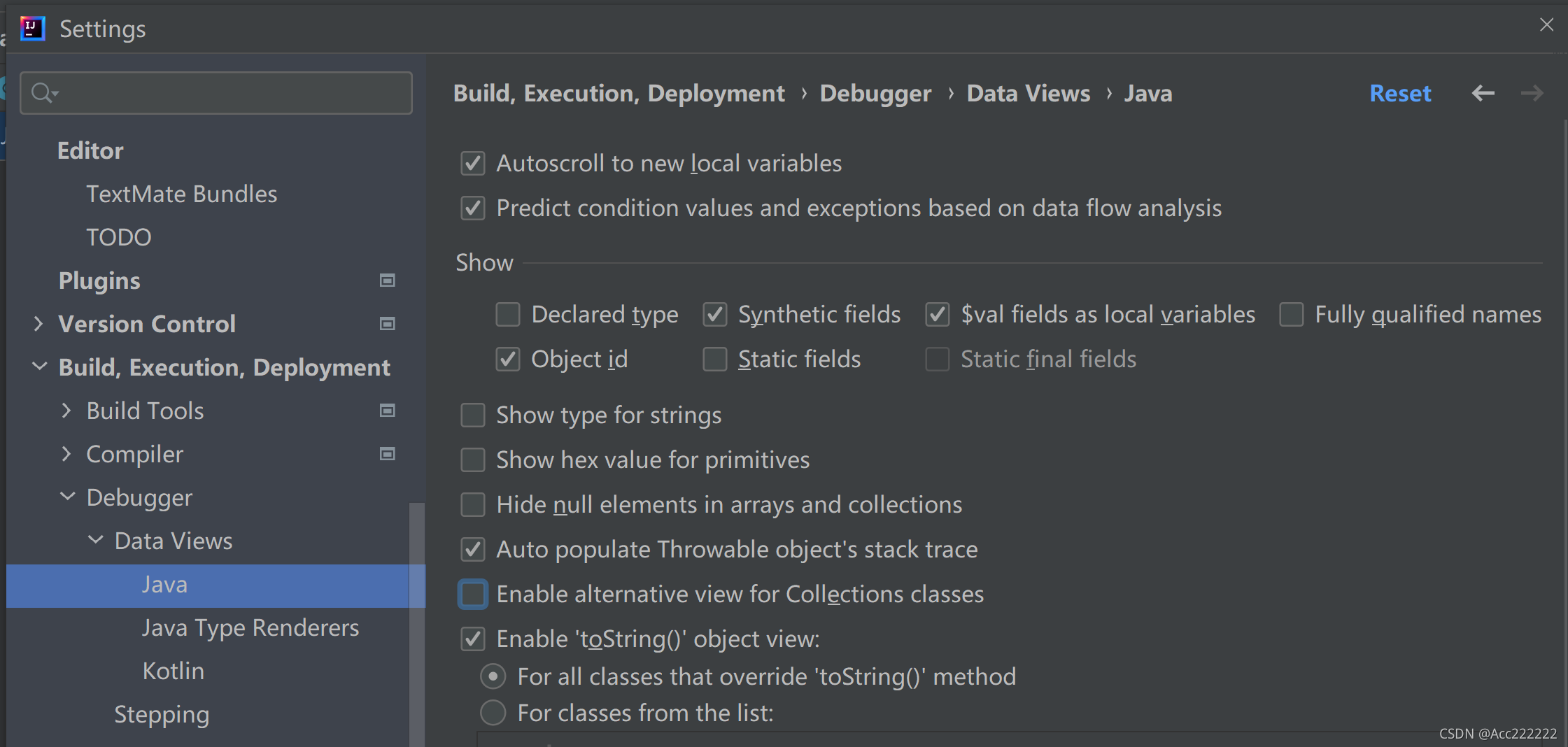
扩容后Debug时看不到数组的null?把 Hide null elements in arrays and collections 和 Enable alternative view for Collections classes去掉。Vector
基本介绍

ArrayList和Vector比较

LinkedList
说明


注:LinkedList维护的双向链表没有头结点,第一个就是首元结点。remove方法默认删除第一个结点。里面的元素是LinkedList类里定义的Node。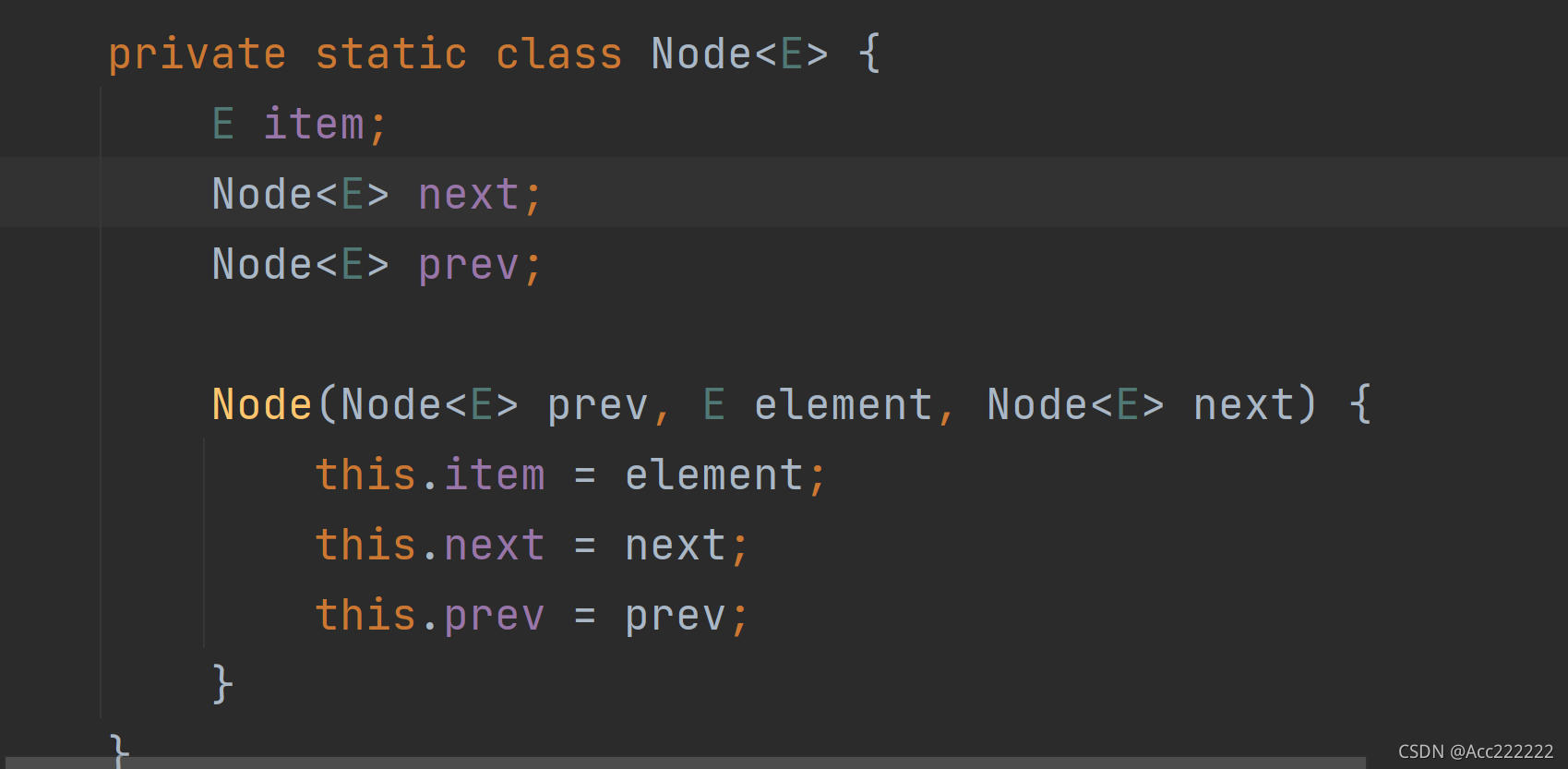
遍历方法有:迭代器,增强for与普通for循环。public static void main(String[] args) {LinkedList a = new LinkedList();Iterator iterator= a.iterator();while (iterator.hasNext()) { //迭代器Object next = iterator.next();...;}for (Object o : a) { //增强for...;}for(int i = 0;i<a.size();i++){ //普通for循环...;}}
初始化源码
void linkLast(E e) {final Node<E> l = last; //保存尾指针final Node<E> newNode = new Node<>(l, e, null); //三个参数分别对应prior,data,nextlast = newNode; //更新尾指针if (l == null)first = newNode; //如果原先尾指针为null,说明newNode为第一个结点,修改firstelsel.next = newNode; //否则把新结点接在最后一个结点后面size++;modCount++;}
ArrayList和LinkedList比较

Set集合
基本介绍
 注:取出的顺序是固定的,不会变。遍历方法:迭代器,增强for,不能用for循环因为没有索引,也没有get方法。
注:取出的顺序是固定的,不会变。遍历方法:迭代器,增强for,不能用for循环因为没有索引,也没有get方法。
LinkedHashSet可以使添加和取出的顺序一致(通过双向链表实现)。HashSet
底层是HashMap 使用 Hash + equals 方法


public HashSet() {map = new HashMap<>(); //创建一个HashMap}
HashSet的add方法
1. 先获取元素的哈希值(hashCode方法) 2. 对哈希值进行运算,得出一个索引值即为要存放在哈希表中的位置号。 3. 如果该位置上没有其他元素,则直接存放。4. 如果该位置上已经有其他元素,则需要进行equals判断,如果相等则不再添加。如果不相等,则以链表形式添加。
其中PRESENT是一个Object对象,只起到占位的作用。
key是输入的关键字,value就是PRESENT。hash方法计算出key的哈希值,注意并不是简单调用了hashCode方法,而是与 h>>>16进行了异或,计算的伪哈希值,最终在putVal方法中用 按位与 计算出索引。 重点是理解 putVal这个方法,源码自己去看,这里只写说明。resize方法用于修改Node数组大小。afterNodeInsertion(evict) 无实际用处,是留给子类实现的方法。
重点是理解 putVal这个方法,源码自己去看,这里只写说明。resize方法用于修改Node数组大小。afterNodeInsertion(evict) 无实际用处,是留给子类实现的方法。
要注意的一个地方:table扩容的两个时机—— 1. 大于临界值 2. 链表加入结点并且大于8个final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//table是HashMap的属性,是放Node的数组。刚开始table为null,resize对tab初始化,扩容到16个空间if ((p = tab[i = (n - 1) & hash]) == null) //计算出真正的索引,把对应位置赋给p//如果p为空,说明没有元素,创建一个结点,把内容放进去。tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//准备添加的key的hash值与当前索引位置对应链表的首元结点hash值相同。//并且满足下面两个条件之一:1. p指向的Node结点的key和准备加入的key是同一个对象// 2. p指向的Node结点的key用equals方法和准备加入的key比较后相同 此时不能加入,e指向p,不做任何处理else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 如果p是红黑树,那么调用putTreeVal方法加入else {// 最后一种情况,说明虽然位置被占,但是与首元结点不相同,找首元结点对应的链表for (int binCount = 0; ; ++binCount) { //开始遍历链表if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 依次和该链表的每一个元素比较后,都不相同(到了最后一个结点),则加入到该链表的最后if (binCount >= TREEIFY_THRESHOLD - 1) // 注意在把元素添加到链表后,立即判断该链表是否已经达到8个结点(也就是>=7)treeifyBin(tab, hash);// 如果已经达到,就调用 treeifyBin()。在这个方法里,要先进行判断 if(tab == null || (n=tab.length)<MIN_TREEIFY_CAPACITY) 也就是看table是否为空或者是否小于64,如果成立,先table扩容。如果不成立才转成红黑树。break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;// 和该链表的每一个元素比较过程中,如果有相同情况,就直接break(判断条件与上方一致)p = e;}}if (e != null) { // 说明有重复元素(主要针对HashMap,用于覆盖)V oldValue = e.value; //记录value,HashSet都是PRESENT,但HashMap是自己定义的if (!onlyIfAbsent || oldValue == null)e.value = value; //HashMap要覆盖,HashSet就不用了,因为PRESENT是nullafterNodeAccess(e);return oldValue; //add失败(不是null)}}++modCount; //记录修改次数if (++size > threshold) //threshold在resize方法中,是表的临界值(初始12)resize(); //如果size大于临界值,扩容afterNodeInsertion(evict);//留给子类实现的方法,对HashMap来说是个空方法return null;//返回空 成功}
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize(); // treeifyBin的部分代码// 这告诉我们,如果链表上已经超过8个结点,但是table还没达到64,那么会先扩容
重写判断是否加入的方法
下面这个是需求:
需要重写Employee类的equals方法和hashCode方法(直接输入equals)
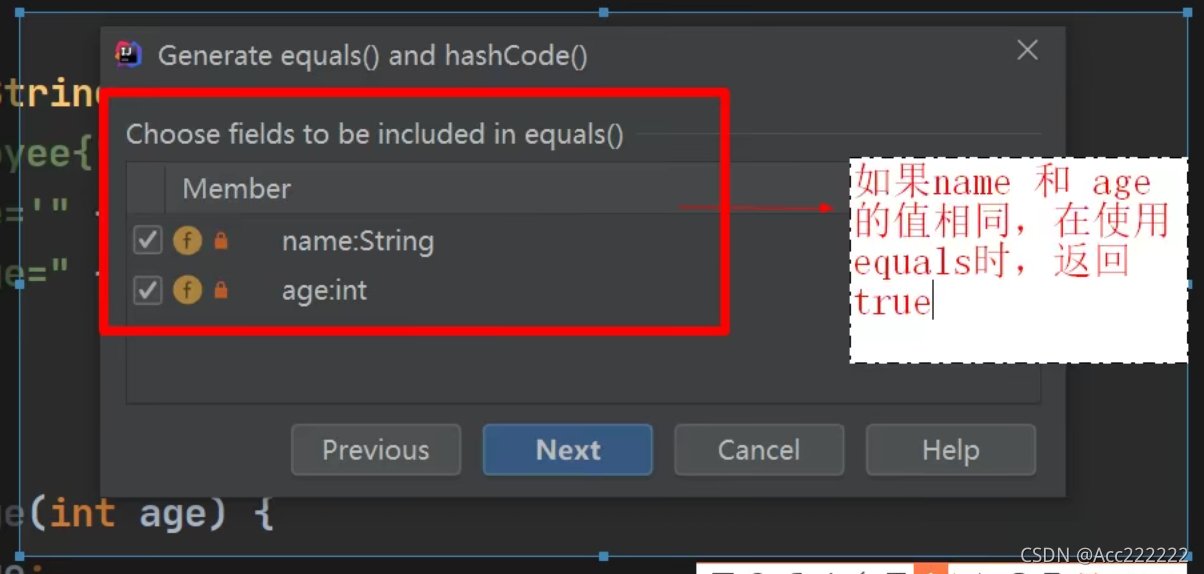
注意这样生成的方法就是重写后的方法,不用更改。 ```java @Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age); //name,age等属性都被塞进一个object数组里
}
**如果类里面有别的类属性(比如A里面有B类的对象),那么B里面也要重写equals和hashCode方法 **<a name="fj0x1"></a>### LinkedHashSet<a name="pjLFJ"></a>#### 说明<a name="y91zw"></a>#### 底层机制示意图<br />(结点应该放在绿色框里,这里画的不清楚)<br />**1. LinkedHashSet 加入顺序和取出元素的顺序一致。**<br />**2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)**<br />3. LinkedHashSet 底层结构—— 数组table + 双向链表<br />4. 添加第一次时,**直接将数组table扩容到16**,数组table是 HashMap$Node[]类型,但存放的结点类型是 LinkedHashMap$Entry(多态),**是Node的子类(可以从左下角的structure查看)**```javastatic class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}
TreeSet(TreeMap)
基本介绍
- 如果只有key,没有伴随数据value,可以使用TreeSet结构
- 如果既有key,又有伴随数据value,可以使用TreeMap结构(他们两个底层结构相同)
- 有序表和哈希表的区别是:有序表把key按照顺序组织起来(内部是有序的),而哈希表完全不组织。
- 红黑树、AVL树、size-balance-tree和跳表等都属于有序表结构,只是底层具体实现不同。
- 放入有序表的东西,如果是基础类型,内部按值传递,内存占用就是数据类型的大小。
如果不是基础类型,必须提供比较器,内部按引用传递,内存占用是这个东西内存地址的大小(一个指针,8字节)
操作API
构造方法
正常的TreeSet声明应该是这样的:
TreeSet a = new TreeSet();
但是TreeSet有一个构造器,可以传入一个比较器Comparator(匿名内部类)
public static void main(String[] args) {TreeSet a = new TreeSet(new Comparator() { //匿名内部类@Overridepublic int compare(Object o1, Object o2) {return ((String)o1).compareTo((String)o2); //按照字符串大小比较}});a.add("jack");a.add("a");a.add("sss");a.add("mmm");System.out.println(a);// [a, jack, mmm, sss]}
要注意一个问题:假设要求按照字符串的length来从小到大排序
public static void main(String[] args) {TreeSet a = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {return ((String)o1).length() - ((String)o2).length(); //从小到大}});a.add("jack");a.add("a");a.add("sss");a.add("mmm");System.out.println(a); // [a, sss, jack]}
可以发现 “mmm” 并没有加入进去,那么我们就需要追一下源码了。
Entry<K,V> t = root;if (t == null) {compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;} // 初始化,生成一个新结点int cmp;Entry<K,V> parent;Comparator<? super K> cpr = comparator; //重点在这里,把比较器赋过去if (cpr != null) {do { //对整个链表(key)进行循环,给当前key找适当位置parent = t;cmp = cpr.compare(key, t.key); //比较原结点与要加入的结点的key//这里会动态绑定到匿名内部类对象if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right; //按照比较结果移动指针else //遍历过程中发现准备添加的key和当前已有的key相等return t.setValue(value); //由于Set的value为PRESENT,因此相当于没加} while (t != null); //循环结束后,t就指向结点应该加入的位置//parent为上一次,因此结束后还需要再移动一次}... //没有比较器的情况Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)parent.left = e;elseparent.right = e; //按照比较结果把结点e放在正确位置(parent是原来的t)fixAfterInsertion(e);size++; //结点个数加一modCount++; //修改次数加一return null;}
“sss” 是先加入的,长度为3。因为自定义的比较器是比较长度的,而 “mmm” 的长度也为3,因此结果为0,直接不加入了(参考do里面的else情况)。
由于TreeSet的底层是TreeMap,因此比较器初始化方法在TreeMap里。 ```java public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}

public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
**TreeSet和TreeMap的底层都是TreeMap,因此TreeMap的源码不再做解析。**<br /><a name="xazgH"></a>#### 关于TreeSet加入自定义类** 如果TreeSet没有重写Comparator,并且加入的类也没有实现Comparable接口,那么就会报错,因为add源码里需要赋予一个比较器。**```javaTreeSet a = new TreeSet();a.add(1); //这样是没有问题的,因为1相当于Integer,而Integer实现了Comparable接口
public static void main(String[] args){TreeSet a = new TreeSet();a.add(new Car("AAA",2331313)); //报错 ClassCastException}class Car{String name;double price;public Car(String name, double price) {this.name = name;this.price = price;}}
TreeSet a = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {return 0;}}); //这样写,给TreeSet加入比较器,再加入Car类就没问题了class Car implements Comparable{ //这样写也没问题,Car类实现了Comparable接口String name;double price;public Car(String name, double price) {this.name = name;this.price = price;}@Override //重写compareTo方法public int compareTo(Object o) {return 0;}}
Map
集合体系图
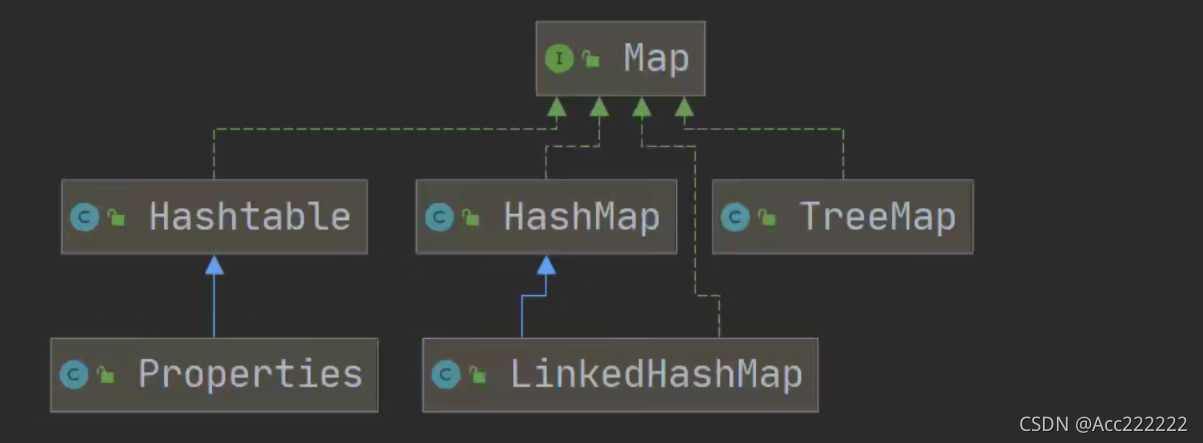
接口特点

注:1. Set本来也是 Key - Value 结构,但是它的Value一直都是PRESENT,因此可以看作Key。
2. 因为key不允许重复,所以如果重复添加会导致覆盖。
3. 用 put 方法添加键值对,用 get 方法指定key返回value。
4. Hash表的操作可以视为常数阶。
5. Hash表的Key如果是基础类型(Integer等,包括String),那么Hash表会拷贝一份。如果是对象类型,那么一直都是8字节,保存的是地址。
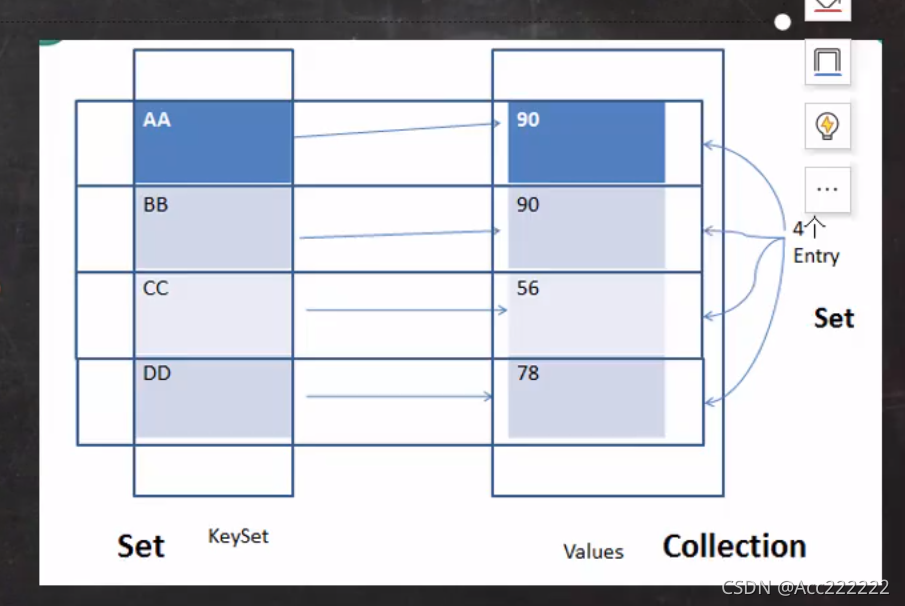
内部创建EntrySet
k-v 最后是 HashMap$Node node = newNode(hash,key,value,null)。注意 k-v 为了方便程序员的遍历,还会在内部创建 EntrySet 集合,KeySet集合以及Values集合。其中KeySet里面存放key,Values(当然只是引用(地址)!不是真正的结点,真正的结点在Node中)。而EntrySet则是包括KeySet与Values,里面内容的运行类型为Node。
entrySet中,存放的元素的类型为Map.Entry
为什么能够转型:因为 Node类实现了Entry接口。当把 Node对象存放到 entrySet 就方便我们的遍历,因为 Map.Entry 提供了重要的方法 getKey 以及 getValue。
如果只想使用key,那么就用KeySet。如果只想用value,那么用values。如果两者都想用,那么就用EntrySet。
public static void main(String[] args) {Map a = new HashMap();a.put("张三",18); //put方法加入键值对a.put("李四",20);a.put("王五",21);Set b = a.entrySet(); // 用entrySet遍历,entrySet父类是Set,因此用Set接收for (Object obj : b) {Map.Entry t = (Map.Entry)obj; //向下转型,编译类型为 Map.EntrySystem.out.println(t.getKey()+" " + t.getValue());}Set c = a.keySet(); //只能操作keyCollection d = a.values(); //只能操作value}
基本方法

public static void main(String[] args) {Map a = new HashMap();a.put("张三",18);a.put("李四",9);a.put("王五",31);a.put("尚",20);System.out.println(a);//{李四=9, 张三=18, 王五=31, 尚=20}a.remove("李四"); //根据某个Key删除结点System.out.println(a);//{张三=18, 王五=31, 尚=20}System.out.println(a.get("张三"));//18 根据Key返回valueSystem.out.println(a.size());//3System.out.println(a.isEmpty());//falseSystem.out.println(a.containsKey("王五"));//true 查找是否有这个Keya.clear(); //清除System.out.println(a.isEmpty());//true}
注:如果要修改元素的内容,也可以用put,因为可以覆盖。 P550
HashMap
遍历方法
用keySet
public static void main(String[] args) {Map map = new HashMap(); //这里可以用泛型改写map.put("张三",18);map.put("李四",9);map.put("王五",31);map.put("尚",20);Set set = map.keySet(); //获取所有的key//第一种方法 增强for循环for (Object key : set) {System.out.println(key + "->" + map.get(key));//用get方法获取value}//第二种方法 迭代器Iterator iterator = set.iterator(); //获取set对象的迭代器while (iterator.hasNext()) {Object key = iterator.next();System.out.println(key + "->" + map.get(key));}}
用values
Collection values = map.values(); //获取valuesfor (Object key : values) { //增强forSystem.out.println(key); //注意 Map中没有从value获取key的方法}Iterator iterator = values.iterator(); //迭代器while (iterator.hasNext()) {Object key = iterator.next();System.out.println(key);}
用EntrySet
Set set = map.entrySet(); // entrySet是Set的子类,是Map的内部类//1. 增强forfor (Object entry : set) {// entry是Object类,需要向下转型(如果使用了泛型就不需要了)Map.Entry t = (Map.Entry)entry;System.out.println(t.getKey() + "->" + t.getValue());}//2. 迭代器Iterator iterator = set.iterator();while (iterator.hasNext()) {Map.Entry h = (Map.Entry)iterator.next(); //一步到位写法System.out.println(h.getKey() + "->" + h.getValue());}
P534 value为对象需要调用方法的情况
for (Object o : s) {Map.Entry t = (Map.Entry)o;if(((Employee)t.getValue()).getSal()>18000) //注意方法前要加括号,作为一个整体if((Employee)t.getValue().getSal()>18000) //这样就是错的...}for (Object o : s) { //可读性更强Map.Entry t = (Map.Entry)o;Employee ee = (Employee) t;if(ee.getSal()>18000)}

HashMap底层


为什么HashMap每次都要扩容2倍
除留余数法:
第一是因为哈希函数的问题
通过除留余数法方式获取桶号,因为Hash表的大小始终为2的n次幂(参照JavaGuide),因此可以将取模转为位运算操作,提高效率,容量n为2的幂次方,n-1的二进制会全为1,位运算时可以充分散列,避免不必要的哈希冲突,这也就是为什么要按照2倍方式扩容的一个原因
第二是因为是否移位的问题
是否移位,由扩容后表示的最高位是否1为所决定,并且移动的方向只有一个,即向高位移动。因此,可以根据对最高位进行检测的结果来决定是否移位,从而可以优化性能,不用每一个元素都进行移位,因为为0说明刚好在移位完之后的位置,为1说明不是需要移动oldCop,这也是其为什么要按照2倍方式扩容的第二个原因。
HashMap底层源码
因为HashSet底层就是HashMap,因此底层几乎完全相同。
1. 执行构造器 new HashMap(),初始化加载因子 loadfactor = 0.75,HashMap$Node[] table = null。
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}transient Node<K,V>[] table;
2. 执行put,调用hash方法,计算key的hash值(注意要进入一个方法最好使用 force step into)。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
3. 执行putVal 方法,具体注释已经在 HashSet中给出。
HashTable
基本介绍

扩容
底层有数组 Hashtable$Entry[],初始化大小为 11。临界值 threshold 为8 = 11 * 0.75。调用put方法里的 addEntry(hash, key, value, index); 当满足 if (count >= threshold) 扩容(rehash)
int newCapacity = (oldCapacity << 1) + 1; //新容量计算方法threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); // 临界值计算方法
HashTable和HashMap对比

Properties

Java 读写Properties配置文件 - 旭东的博客 - 博客园 感兴趣可以看这篇文章。
注意事项
1. Properties 继承 Hashtable,是无序的。
2. 可以通过 k-v 存放数据,当然key和value不能为null。
3. 常用方法:增 put(key,value),删 remove(key),改 put(相同的key,value),查 get(key)。
开发中如何选择集合实现类


若有收获,就点个赞吧
0 人点赞
