水平拆分
水分分库
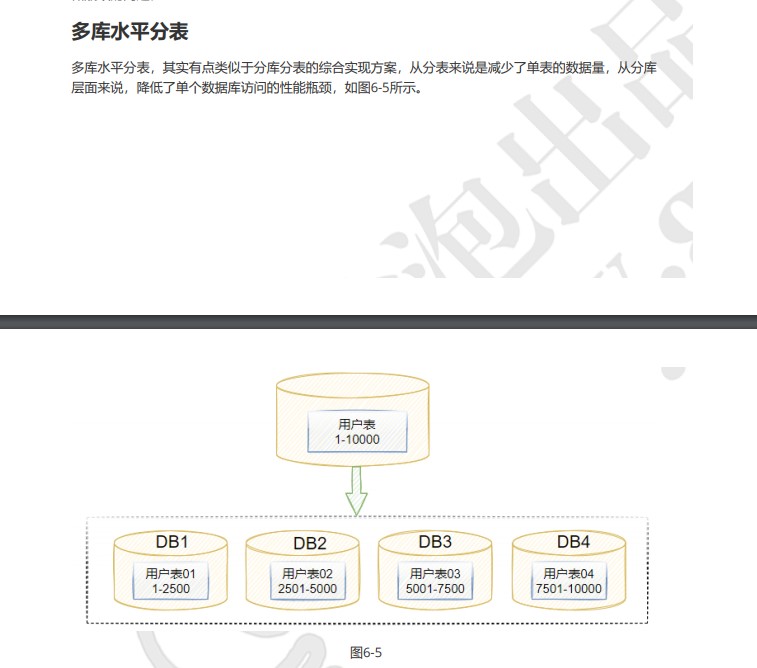
水平分表


垂直拆分
垂直分库
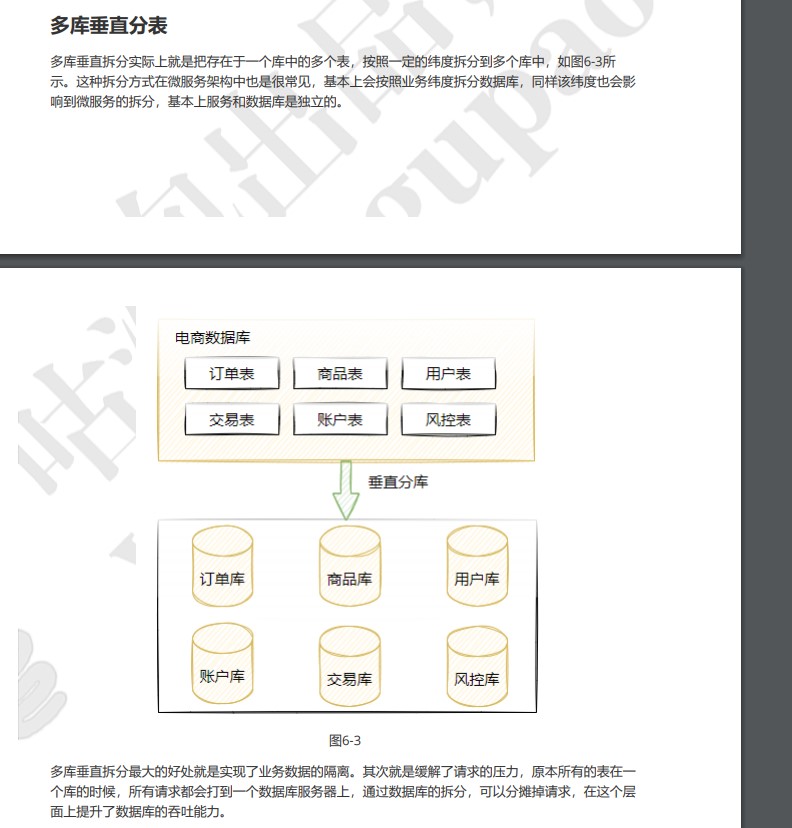
垂直分表
将将订单表中的订单详情信息单独拆开 拆分成订单表和订单详情表两个表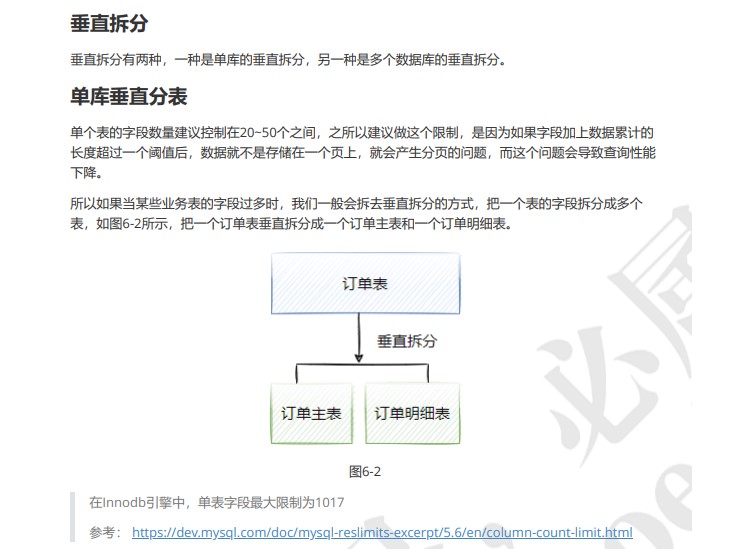
Msql 优化的手段
1.增加索引,索引是直观也是最快速优化检索效率的方式。
2.基于Sql语句的优化,比如最左匹配原则,用索引字段查询、降低sql语句的复杂度等
3.表的合理设计,比如符合三范式、或者为了一定的效率破坏三范式设计等
4.数据库参数优化,比如并发连接数、数据刷盘策略、调整缓存大小
5.数据库服务器硬件升级
6.mysql大家主从复制方案,实现读写分离
数据迁移遇到的问题
新老库双写
数据库表的双写,老的数据库表和新的数据库表同步写入数据,事务的成功以老的模型为准,查询
也走老的模型
以新的模型为准
仍然保持数据双写,但是事务的成功和查询都以新模型为准
定时任务进行数据核对,补平数据差异
结束双写
取消双写,所有数据只需要保存到新的模型中,老模型不需要再写入新的数据
如果仍然有部分老的业务依赖老的模型,所以等到所有业务都改造完成后, 再废除老的模型
大数据表优化方案
1.分库分表,大表拆小表
2.冷热数据分离
所谓的冷热数据,其实就是根据访问频次来划分的,访问频次较多的数据是热数
据,访问频次少的数据是冷数据。冷热数据分离就是把这两类数据分离到不同的表中,从而减少热
数据表的大小。
3.历史数据归档
简单来说就是把时间比较久远的数据分离出来存档,保证实时库的数据的有效生命周期。
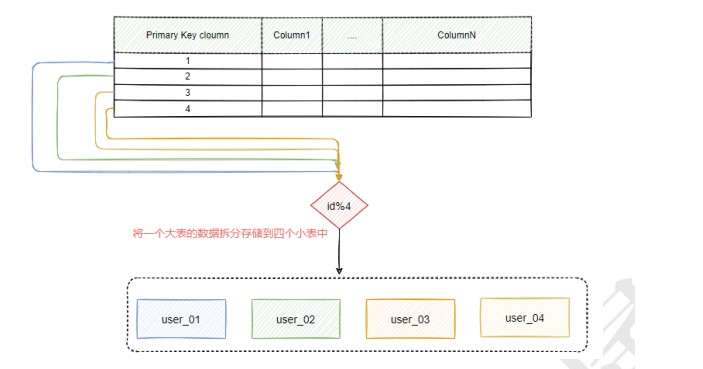
水平分表的策略
哈希取模分片
哈希分片,其实就是通过表中的某一个字段进行hash算法得到一个哈希值,然后通过取模运算确定数据
应该放在哪个分片中,如图6-6所示。这种方式非常适合随机读写的场景中,它能够很好的将一个大表
的数据随机分散到多个小表
缺点
hash取模运算有个比较严重的问题,假设根据当前数据表的量以及增长情况,我们把一个大表拆分成了
4个小表,看起来满足目前的需求,但是经过一段时间的运行后,发现四个表不够,需要再增加4个表来
存储,这种情况下,就需要对原来的数据进行整体迁移,这个过程非常麻烦。
一般为了减少这种方式带来的数据迁移的影响,我们会采用一致性hash算法
一致性hash算法
一致性哈希将整个哈希值空间组织成一个虚拟的圆环
就是我们通过0-232
-1的数字组成一个虚拟的圆环,圆环的正上方的点代表0,0点右侧的第一个点代表
1,以此类推,2、3、4、5、6……直到2
32
1,也就是说0点左侧的第一个点代表2
32
-1。我们把这个由2的
32次方个点组成的圆环称为hash环。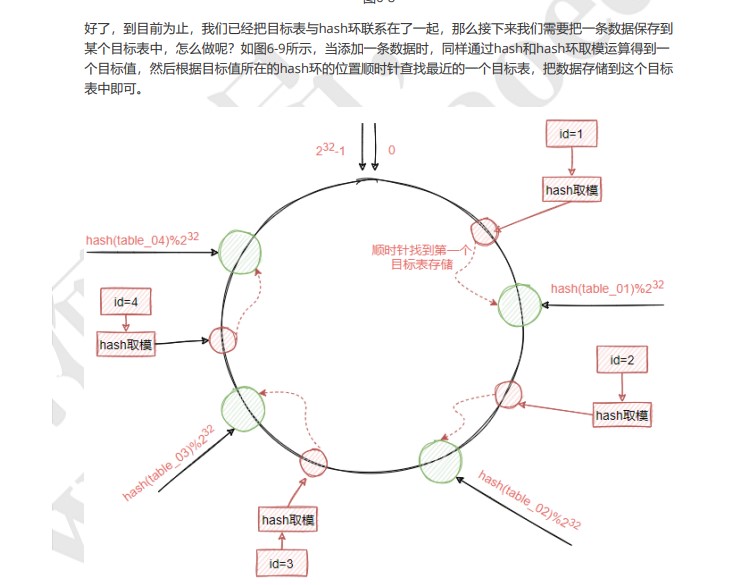
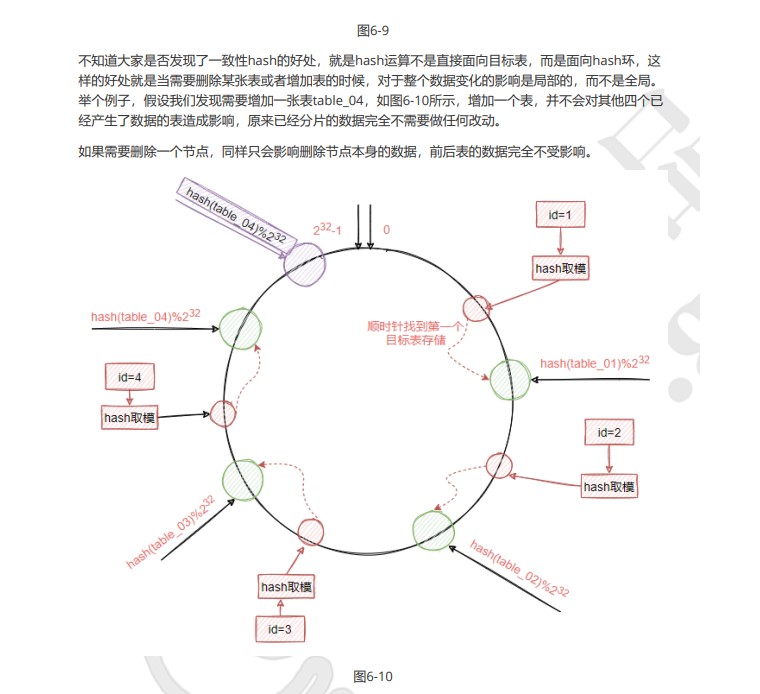
哈希环移
问题
理论情况下我们目标表是能够均衡的分布在整个hash环中,但实际情况有可能是
图6-11所示的样子。也就是产生了hash环偏斜的现象,这种现象导致的问题就是大量的数据都会保存到
同一个表中,倒是数据分配极度不均匀。
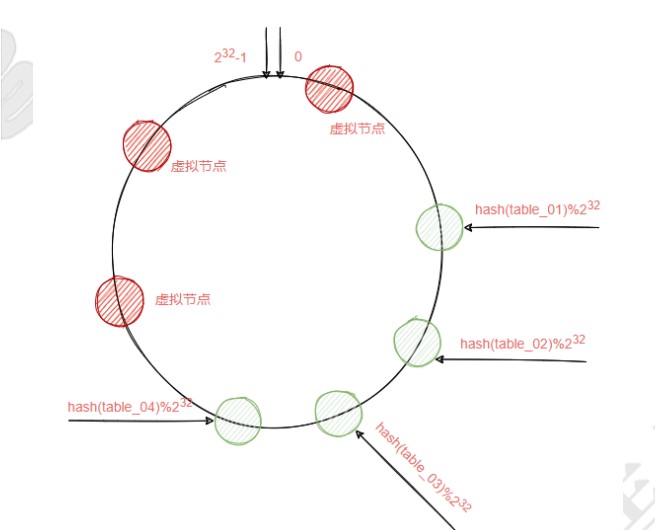
解决方法
必须要保证目标节点要均匀的分布在整个hash环中,但是真实的节点就只有4个,
如何均匀分布呢?最简单的方法就是,把这四个节点分别复制一份出来分散到这个hash环中,这个复制
出来的节点叫虚拟节点,根据实际需要可以虚拟出多个节点出来,
按照范围分片
其实就是基于数据表的业务特性,按照某种范围拆分,
1.时间范围,
比如我们按照数据创建时间,按照每一个月保存一个表。基于时间划分还可以用来做冷
热数据分离,越早的数据访问频次越少
2.区域范围,
区域一般指的是地理位置,比如一个表里面存储了来自全国各地的数据,如果数据量较
大的情况下,可以按照地域来划分多个表。
3.数据范围,
比如根据某个字段的数据区间来进行划分。

若有收获,就点个赞吧
0 人点赞
