索引类别
唯一索引
聚簇索引(主键索引)
普通索引(二级索引)
哈希索引
查询速度特快 因为hash索引不用来排序
只支持等值查询 = 或者in
重复值特别多会到导致hash冲突 用拉链法解决
全文索引
针对比较大的索引 比如存放消息 只有文本类型的才能建立全文索引
覆盖索引
只要select 列能从索引中取得 就避免了回表
比如二级索引 name 根据name 查 会回表 然后 name列在查询的列上会成为覆盖索引
回表
当mysql查询时,使用非聚簇索引(也叫二级索引,辅助索引) 查到相应的叶子节点获取主键值,然后通过 主键索引(聚簇索引) 再查到相应的数据行信息,找到主键后通过聚簇索引 找到相应数据行的过程叫做回表。
非主键索引 比如通过name = 1 找到id 然后在通过id主键找到对应的数据这样多扫描一颗B+树
联合索引
联合索引最左匹配
1.比如name上建立索引 age上没所有 如果where age = and name = 索引会失效
2.使用联合索引 必须把索引放在最左边 符合最左前缀原则
3.遇到范围查询直接失效
4.根据 名称和 age 建立索引 ,只要跟在 顺序调换了没有问题 如果只根据名称也没问题 但是如果只根据age 缺少名称就有问题了
5.分组和排序 最好也根据 联合索引的最左前缀
联合索引查询规则


主键索引和非主键索引查询的区别
主键索引
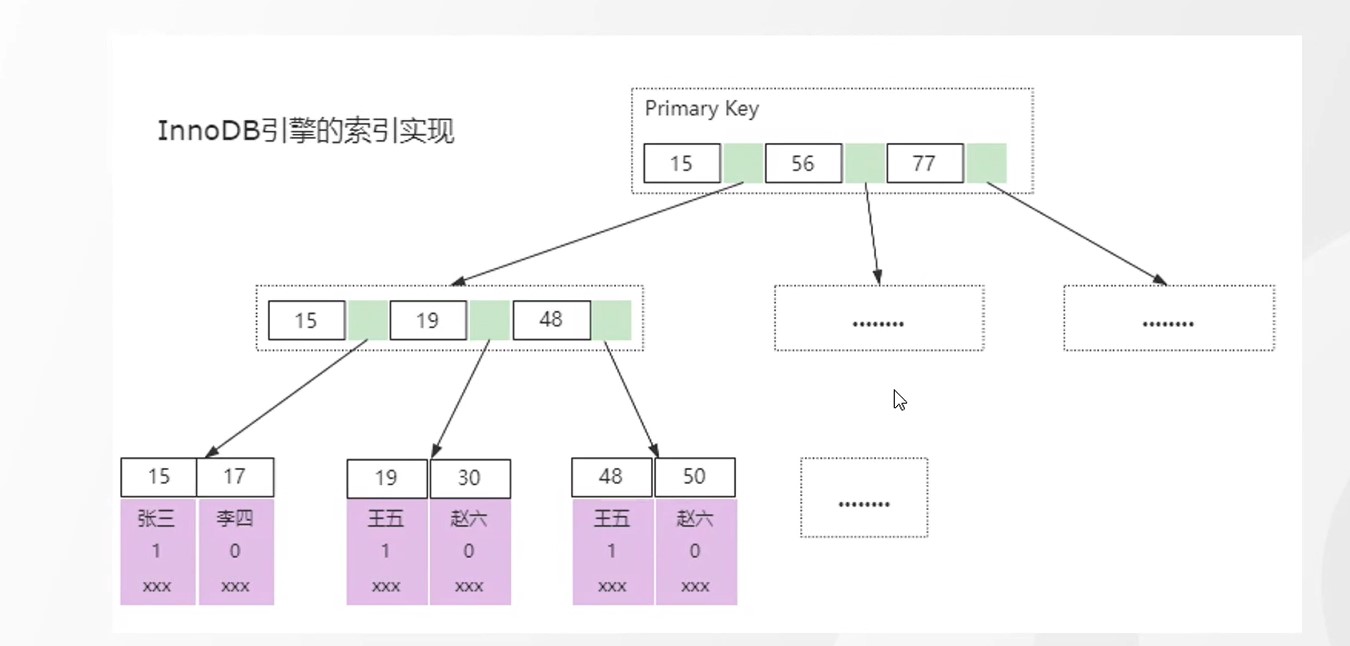
非主键索引
先根据比如name 找到主键id 然后在通过id 全表扫描一颗B+树找到对应的数据
区别
二级索引扫描会回表 当指定了列的时候会走覆盖索引
主键索引比非主键索引少扫描一整颗树
索引使用的原则
列的离散度
比如性别只有男和女 这样的话离散度就低 电话有很多个离散度就高
在离散度高的字段上建立索引
尽量考虑到 where order by gorup by 都可以用上
索引创建条件
1.在join ,where条件 group by创建索引
2.索引的个数不要太多
3.过长的字段建立前缀索引
4.区分度低的不要建立索引 因为会造成重排序
5.频繁更新的不要建立索引 因为会造成页分裂
6.无序的不建议建立索引
7.组合索引把散列高的放where 前面
8.创建复合索引不修改单页索引
9.利用一两个复杂的多字段联合索引 抗下百分之80的查询 利用辅助字段创建联合索引 抗住剩下百分之20的非典型查询
存储结构
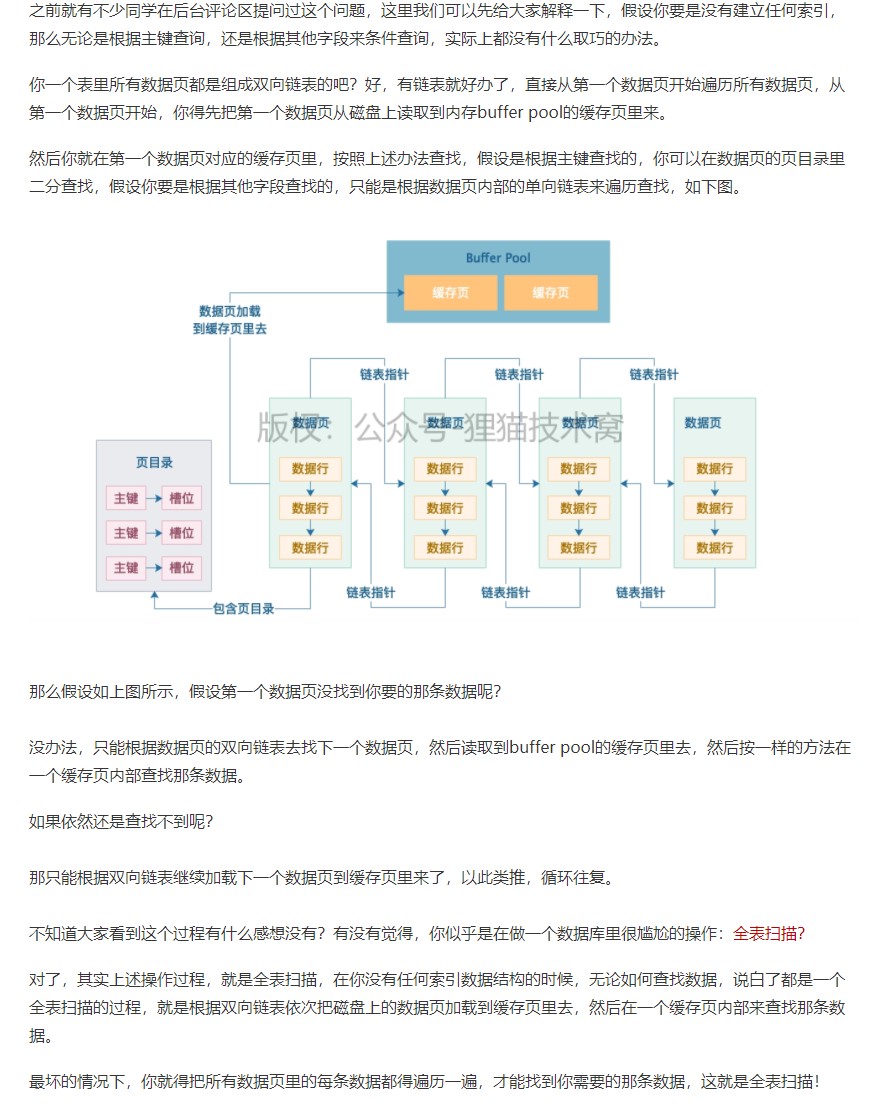
insert时索引列变化流程
1.初始化的数据页就是一个根页 每个数据页内就有一个基于主键的 页目录 直接基于主键去搜索找到唯一的一条数据
2.当数据越来越多时 如果数据页满了就会生成一个新的数据页 然后把你根页面里的数据都拷贝 过去在搞一个新的数据页 根据主键大小排序 后一个数据页的主键大小永远大于前一个数据页的主键大小
3.此时根页就变成了索引页存放了其他的页号和指向其他页的指针 指向了其他的数据页
4.当根页存放的只想数据索引页越来越多就会分类成多个根页 形成树形结构指向
查看语句执行成本
show table status like 表名
mysql 使用错误的执行计划的解决方法
select * from user force index(索引名) where xxx
索引结构类型
1.二分查找
2.二分查找树
3.平衡二叉树
4.B Tree
B+Tree
关键数数量和路数相等
数据只存储在最下面的叶子节点
比如搜索Id =28 数据在树枝节点就命中了但是也需要往下去探索到叶子节点才能拿到数据
查找过程
比如找id =28的数据 先根据id 找到树枝节点 然后根据树枝节点的左右开合找叶子节点
如果是范围查询的话比如找到22了就直接从22往后探索直到找到数据
优势
每个节点存储的关键字更多,路数更多
扫库扫表的能力更强 如果全表扫描只需要扫描叶子节点不用整颗树都扫描
排序能力更强
效率更稳定
如果一个表没有主键索引 会自动创建一个rowid 的隐形索引
索引下推
只适应二级索引 减少了访问表的行数
ICP默认开启针对二级索引 只能能把条件下推给存储引擎就会自动下推
在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
索引失效
索引列使用函数 where id=1+44 因为会做隐式转换 无法进行索引扫描
like 前面带% 可以使用全文索引 因为%* 前百分号在最左前缀原则表示未知
Not Like
页分裂
原因
过程
将前后两个数据页的数据根据主键索引大小替换
多表查询的执行流程
select * from t1 ,t2 where t1.t1=xxx and t1.t2=t2.t2
现根据t1的where 条件去检索 假如检索出的两条记录 再去匹配t2的记录
执行计划结构

id
查询的序列编号 由大到小排列 id 越大越先执行 子查询最里层的子最先执行 然后依次执行 外层
关联查询时id 相同 则按照顺序从上到下执行
select_type
PRIMARY
SUBQUERY
UNION
UNION RESULT
SIMPLE
DERIVER
type
System
特殊的 const类型 针对于 MyISAM存储引擎的单表单记录查询
const
eq_ref
ref
普通索引或者二级索引 联合索引符合最左前缀,唯一索引 弄了个 isnotnull
renge
ref_on_all
where name = x or name is null
index
遍历二级索引拿到数据
all
possible_keys
确认type 的访问方式 有哪些索引可供选择
key
实际用到的索引
key_len
用到索引长度
ref
跟索引匹配的信息
rows
要扫描多少行才能返回
filtered
返回结果行数占需要结果行数的百分比 只对 index和all有效
Extra
附加信息
慢查询日志
默认关闭 可以在应用层做
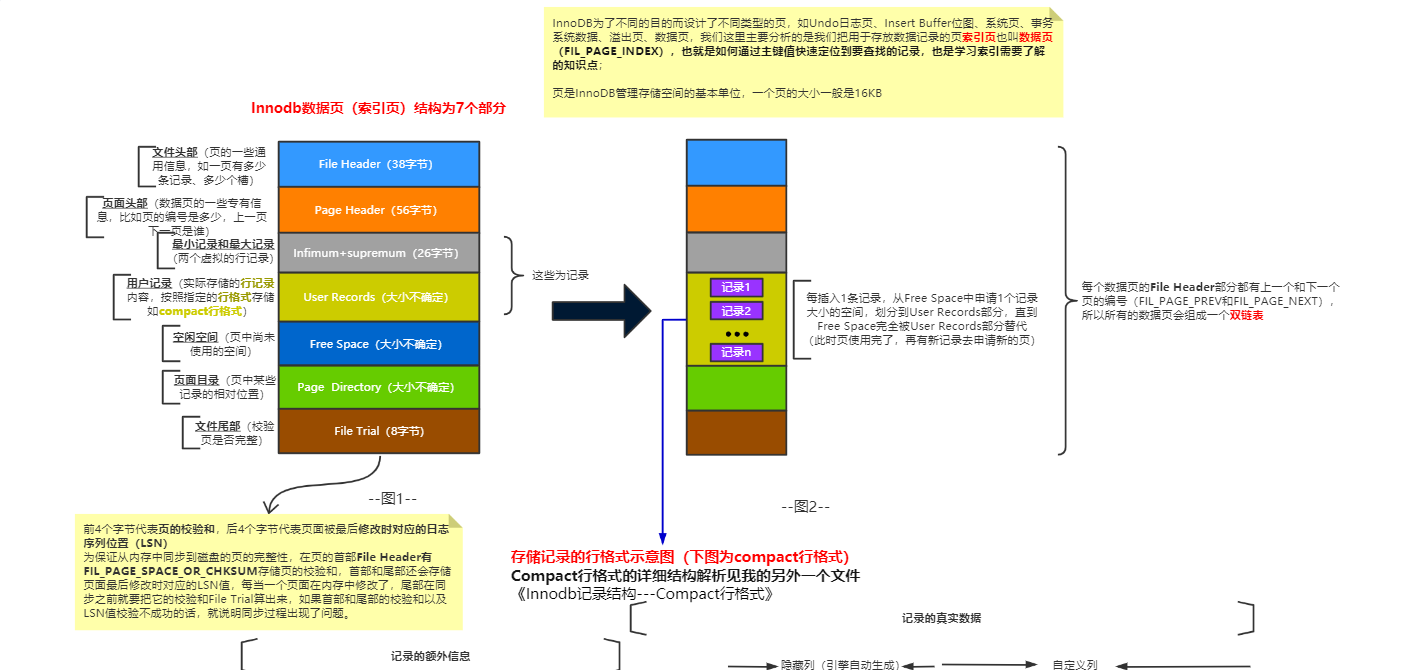
索引页结构






若有收获,就点个赞吧
0 人点赞
