


TPS单机6000 连接池上万
优化过程

查询语句执行流程

1.客户端发送请求到mysql服务端 会先查询缓存如果缓存查询到了就返回给客户端否则继续
2.解析器
语法解析
词法解析
将比如select from user 打碎 打算成4个单词 分别是 select , ,from ,user
3.预处理器
4.查询优化器
物理优化
CBO

RBO
逻辑优化
5.执行计划
6.执行引擎
7.存储引擎(数据存放的位置)
InnoDB
1.支持事务(ACID)
2.默认解决了幻读
3.具有崩溃提交回滚的功能
4.数据存放索引中 速度大大的
5.支持外键 完整的约束
6.支持行锁和表锁
7.并发性能更好
8.适用于事务场景 并经常更新
9.有预读机制
线性预读:为了便于管理 InnoDb将相邻的64个Page称为一个区 如果访问了56个page 会将下一个区域读进BufferPoll中
随机预读:如果一个区已经缓存了数据页 就会将这个区剩余的所有缓存到BufferPoll中
MyIsAm(无事务)
1.不做事务请求 如果只需要做查询请求 或者统计类选择这个引擎比较合适
2.较高的插入速度和查询速度
3.表锁 大大的降低了性能
Memory
CSV
Archive

机器的并发配置
8核16G可以抗一秒一两千
16核32G可以抗一秒两三千
压测指标
TPS
QPS
每秒查询数
IO压测指标
IOPS
吞吐量
latency
磁盘里写入一条数据的延迟
高并发情况下的优化
设置buffer 内存
innodb_buffer_poll_sieze = 8589934592
innodb_buffer_poll_instances=4
chunk 机制

动态调整 buffpoll大小(默认128MB)
https://www.cnblogs.com/wxlevel/p/12995324.html
比如bufferpoll总大小是8G 现在要动态扩容到16G 那么只需要申请128MB大小的 多个check就可了
bufferpoll 大小设置
总内存的百分之50-60
bufferpoll总大小= (chunk * bufferpoll)的两倍
缓冲池 BufferPoll

作用
减少了直接和磁盘进行交互 在中间加了一层缓存 先将数据放到缓存中 查询的时候如果缓存能拿到就不用去和磁盘交互
为了提高读写的效率
分类
1.ChangeBuffer(写缓冲)
读多写少可以用写缓冲
change buffer就是在非唯一普通索引页不在buffer pool中时,对页进行了写操作的情况下,先将记录变更缓冲,等未来数据被读取时,再将 change buffer 中的操作merge到原数据页的技术。在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
原理
当需要更新一个数据页时,如果数据页在内存中(BufferPoll)就直接更新。如果数据页不在内存(BufferPoll)中。在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
虽然名字叫作 change buffer,实际上它是可以持久化的数据。也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上
merge
将 change Buffer 中的操作合并到原数据页 得到最新的结果的过程称为merge
触发 merge的条件
- 访问这个数据页;
- 后台master线程会定期 merge;
- 数据库缓冲池不够用时;
- 数据库正常关闭时;
- redo log写满时;
为什么ChangeBuffer只能针对非聚集唯一索引
因为如果是主键索引或者唯一索引需要判断数据是否唯一 这时候就需要去索引页中加载数据判断而不仅仅只操作缓存2.Adaptive Hash index(hash索引)
只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列的值计算一个哈希码,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针3.log Buffer(操作系统缓冲区 存储redolog)
组成
一个真实的bufferPoll 是由多个bufferPoll组成 每个bufferPoll是由多个chunk组成
我们给buffer pool设置了8GB的总内存,然后设置了它应该有4个Buffer Pool,也就是说,每个Buffer Pool的大小就是2GB。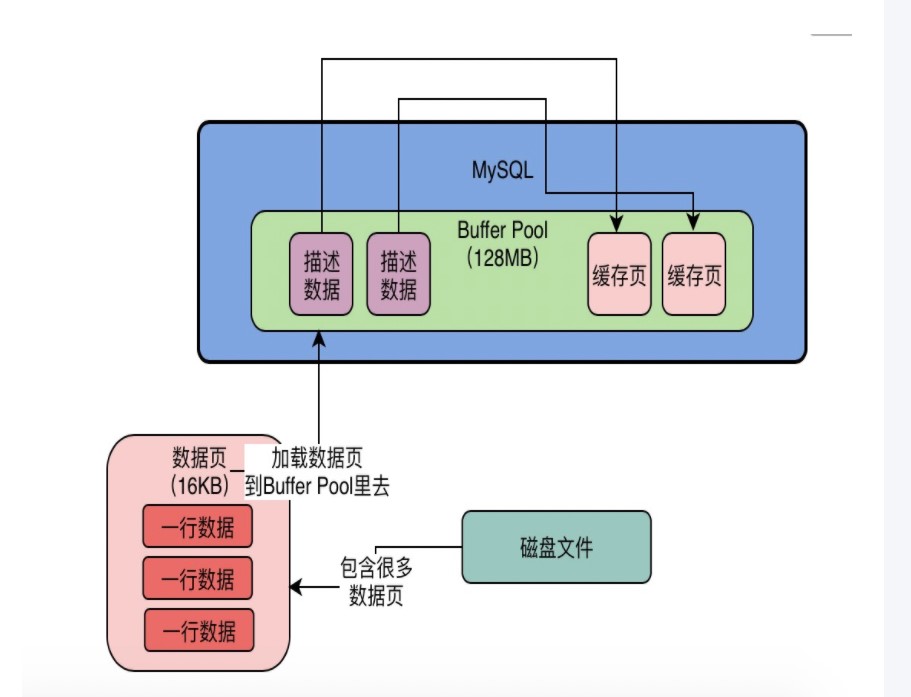
chunk机制(调整BufferPoll大小)
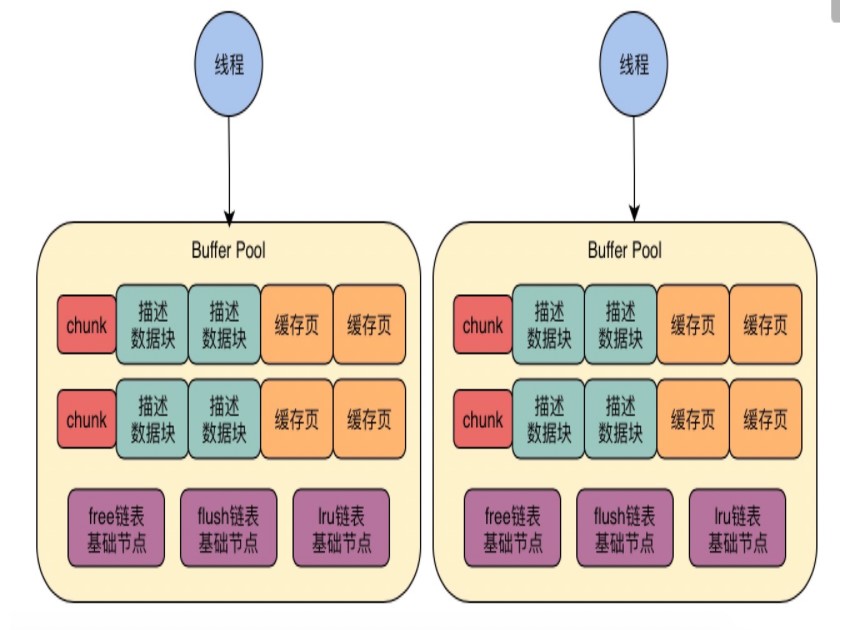
存储的数据
数据页
淘汰算法
当BufferPoll满了之后用Lru 算法管理缓冲池 经过淘汰的都是热区的数据
LRU

用Map和链表实现 value存的是链表的地址
预读数据不受热点数据的影响
热区(靠近head 存放热点数据)
冷区(靠近tail 存放不常被访问的数据) 默认37%
分割线(midpoint)
淘汰策略

新数据进入BufferPoll的时候会先进入冷区 如果域读的数据长时间没用就会在冷区被淘汰
如果一秒之后再次访问会放到热区
如果热区的数据长时间没被访问会被放到被冷区进行淘汰
如果实在是没有内存页的时候会把最不常用的页数据刷新到磁盘
后台线程定时会把冷区尾部的数据刷到磁盘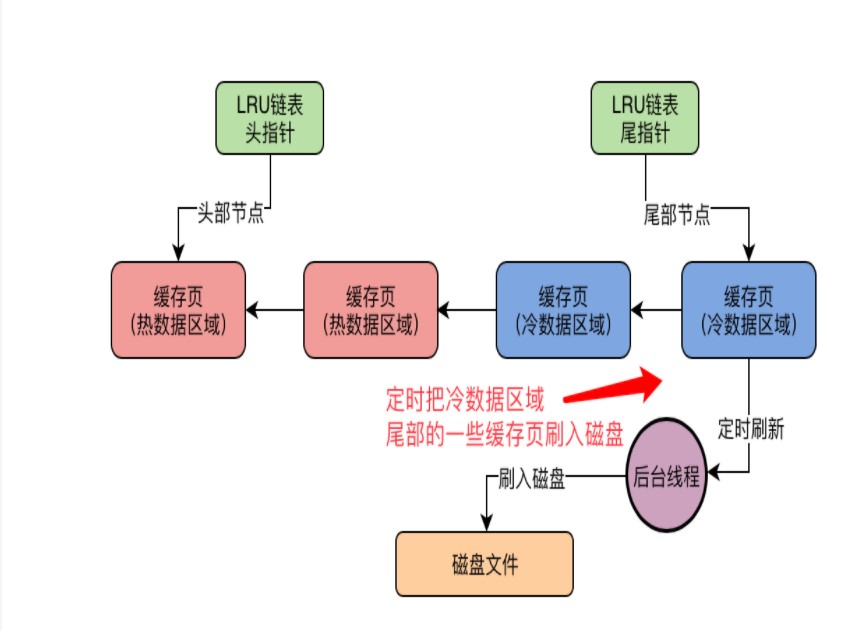
加载流程
内存申请完毕之后 系统会按照默认的缓存页的大小16KB 在BufferPoll中划分出一个个的缓存页和对应它们的描述数据,刚加载的时候事空的只有当真正执行增删改查操作的时候才会去填充数据
查看数据页是否被缓存
表空间+数据页号作为key 去 哈希表中查 如果没查到则 加载数据读取到缓存页
每次读取数据页到缓存页的时候 都会在hash 表中写入key -value 对 key 是 表空间+数据页号 value 是缓存页的地址
冷热区数据变换流程
1.数据页第一次被加载到缓存的时候 缓存页会被放到冷数据区域的链表头部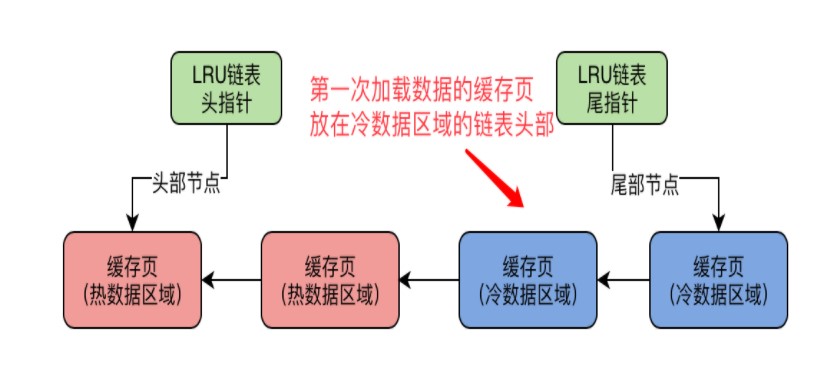
2.一个数据页被加载到缓存页之后 在1S之后你访问这个缓存页 他才会被挪到热数据区域的链表头部 为了防止数据访问频繁 每次都要移动所以 只有在热区 3/4被访问到才会移动到链表头部 如果数据刚被加载到缓存页 在1S内就访问缓存页 此时是不会把缓存页放入热数据区域的头部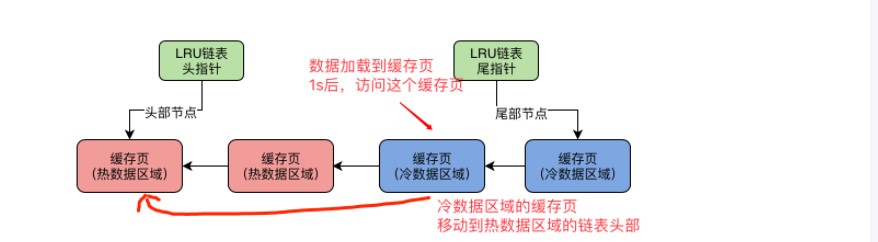
3.预读机制和全表扫描的数据页会被加载到冷区中
判断数据页有没有被缓存
数据库有一个哈希表的结构 key 是表空间号+页号 value是缓存页的地址
每次读取一个缓存页的时候 都会写入一个key value 如果下次使用的话 直接通过key 取value
存储引擎读取的最小单元
页
在InnoDB中最小单位默认16Kb大小
刷页
由于存在缓冲池BufferPoll 修改数据的时候先去更新缓冲池 而不是直接写入磁盘这样的话会形成脏数据
刷脏
起一个后台线程 隔一段时间往磁盘同步一次数据
redolog满了的时候
bufferpoll 内存不足
mysql 定时关闭
凡是被修改过的缓存页都会把描述数据flush双向链表中去 flush就是脏页
空闲的页
为BufferPolls设置一个 Free双向链表 这个链表里每个节点就是一个空闲缓存页的描述数据库的地址 当一个缓存页空闲就会被加载进Free链表
鉴别BufferPoll中空闲的页
为BufferPoll设置一个Free双向链表 这个链表里每个节点就事一个空闲的缓存页的描述的数据块的地址 当一个缓存页事空闲的就会被加载进 Free链表中
Free链表的组成部分
由BufferPoll中的描述块组成 每个描述块里有两个指针 一个pre一个 next 分别指向下一个节点和上一个节点
将磁盘上的数据页同步到BufferPoll缓存
1.从free链表中取出描述快 然后根据描述块找到对应的数据页
2.然后把磁盘对应的数据页读取到对应的缓存页中
3.把相应的描述块的数据写入缓存的描述快中
预读机制
当从磁盘加载数据页的时候他可能会连带着把这个数据页相邻的其他数据页也加载到缓存中
触发预读机制的条件
1.如果顺序的访问了一个区里的多个数据页 访问的数据页的数量超过了这个阈值就会触发预读机制 把下一个相邻区的所有数据页都加载到缓存里去
2.BufferPoll里缓存了一个区里的13个连续的数据页 而且这些数据页都被频繁的访问 此时会触发预读机制把这个区里的其他数据页都加载到缓存里
线性预读
表空间里存储 以Extent为单位表示一个区 一个区有64的页 当一个区里面有56个page(数据页)就把下一个区缓存到bufferpoll中 每个page16k 每个页面里面有多行数据
随机预读
全表扫描
select * from user 会把表所有的数据页都从磁盘加载到BufferPoll中
数据从磁盘同步 BufferPoll过程
1.从free链表中取出描述快 然后根据描述块找到对应的数据页
2.然后把磁盘对应的数据页读取到对应的缓存页中
3.把相应的描述块的数据写入缓存的描述快中
4.去除free中的这个描述快
脏页
如果发现数据页没缓存 那么必然会基于free链表找到一个空闲的缓存页 然后读取到缓存页中 如果缓存了 那么下一次就必然会直接使用缓存页
当执行增删改的时候会去更新BufferPoll的缓存页中的数据 此时一旦更新了缓存页中的数据 那么缓存页里的数据和磁盘上的数据页里的数据不一致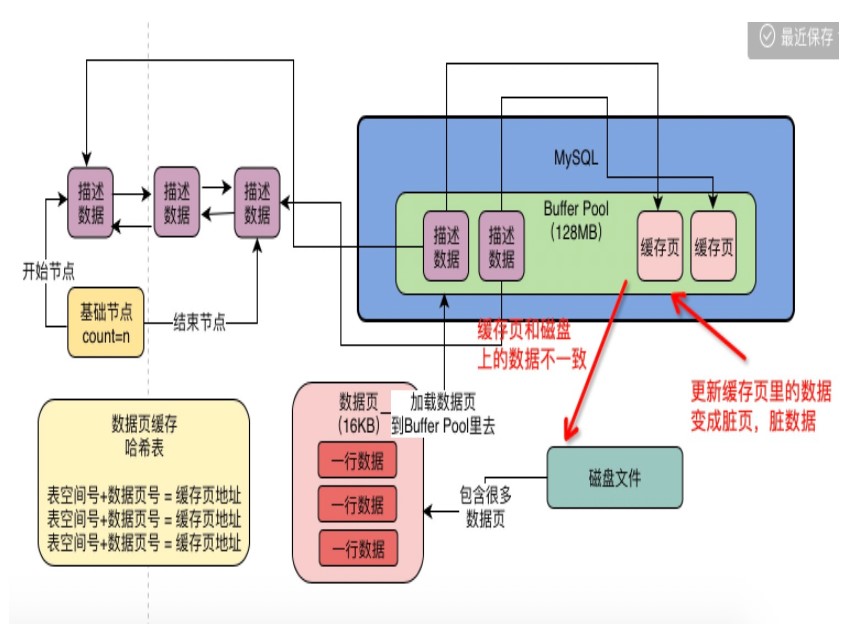
flush链表
这个链表本质也是通过缓存页的描述数据快中的两个指针 让被修改的缓存页的描述数据块组成一个双向链表
凡是被修改过的缓存页 都会把他的描述数据快加入到flush 链表中 后续都要把 flush 刷新到磁盘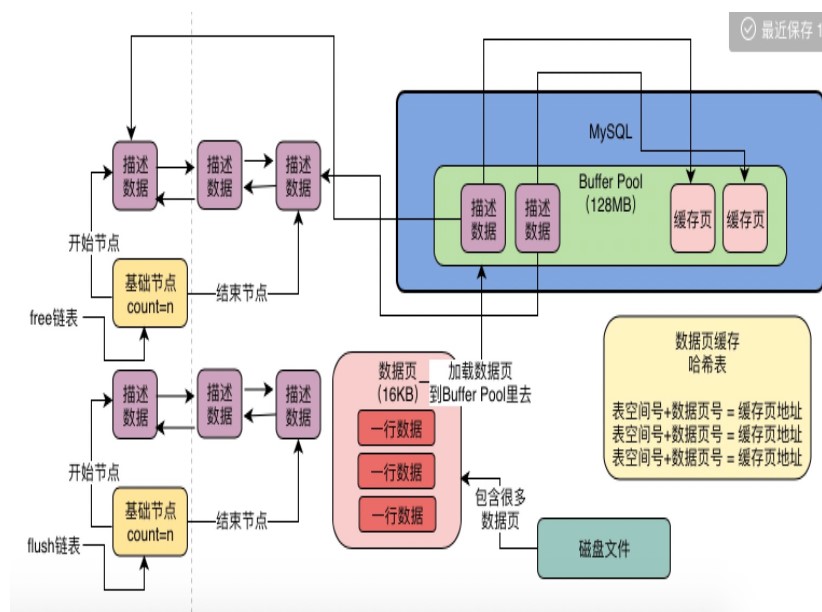
RedoLog
做数据持久化的 如果数据还没有同步到磁盘数据库宕机会造成数据丢失 所以把数据写入缓冲区之后会写入redoLog中 用来备份
RodoLog 大小事固定的如果文件满了 会触发一次磁盘的同步
结构
写数据的过程
用 redolog block 存放多个单行日志 一个redolog block最多存放 496个 redolog
redolog block 结构
存放多个单行日志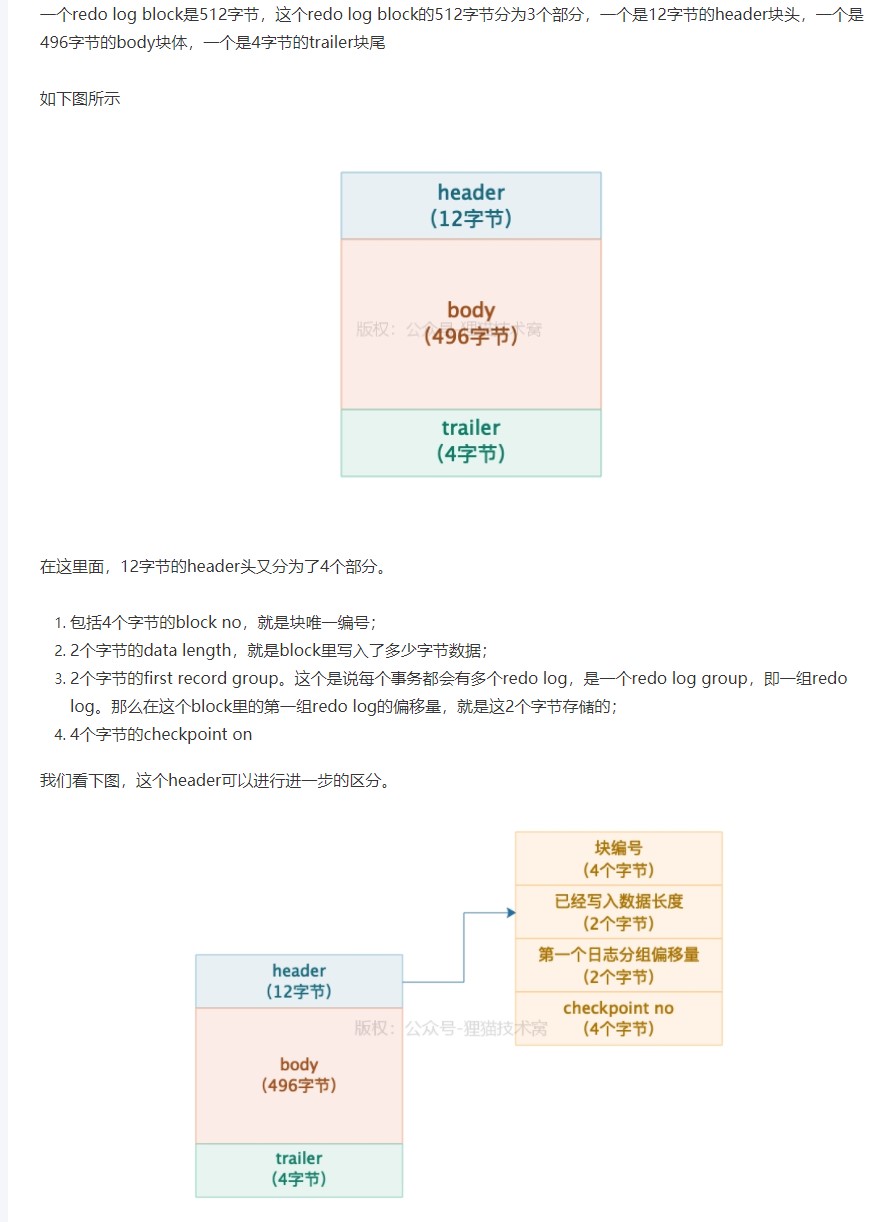
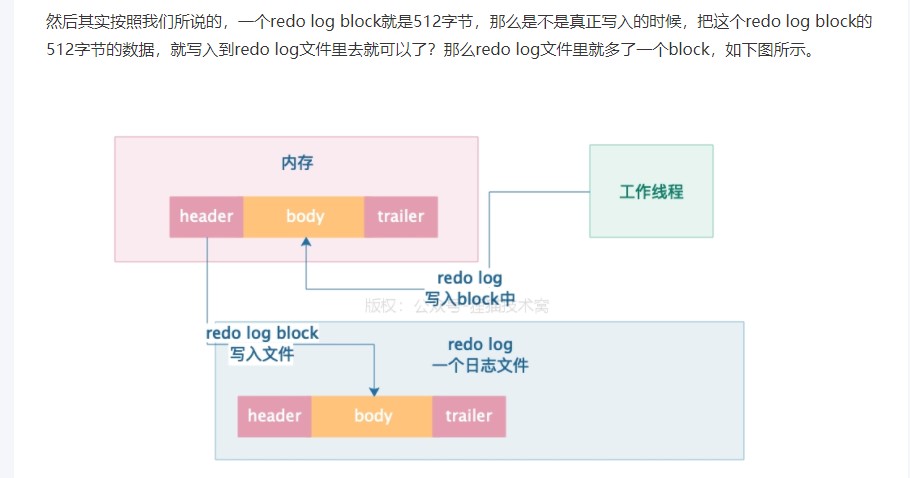
从缓存刷数据到磁盘的过程
log buffer 专门用来缓冲redolog 写入
mysql 启动的时候会申请一块连续的空间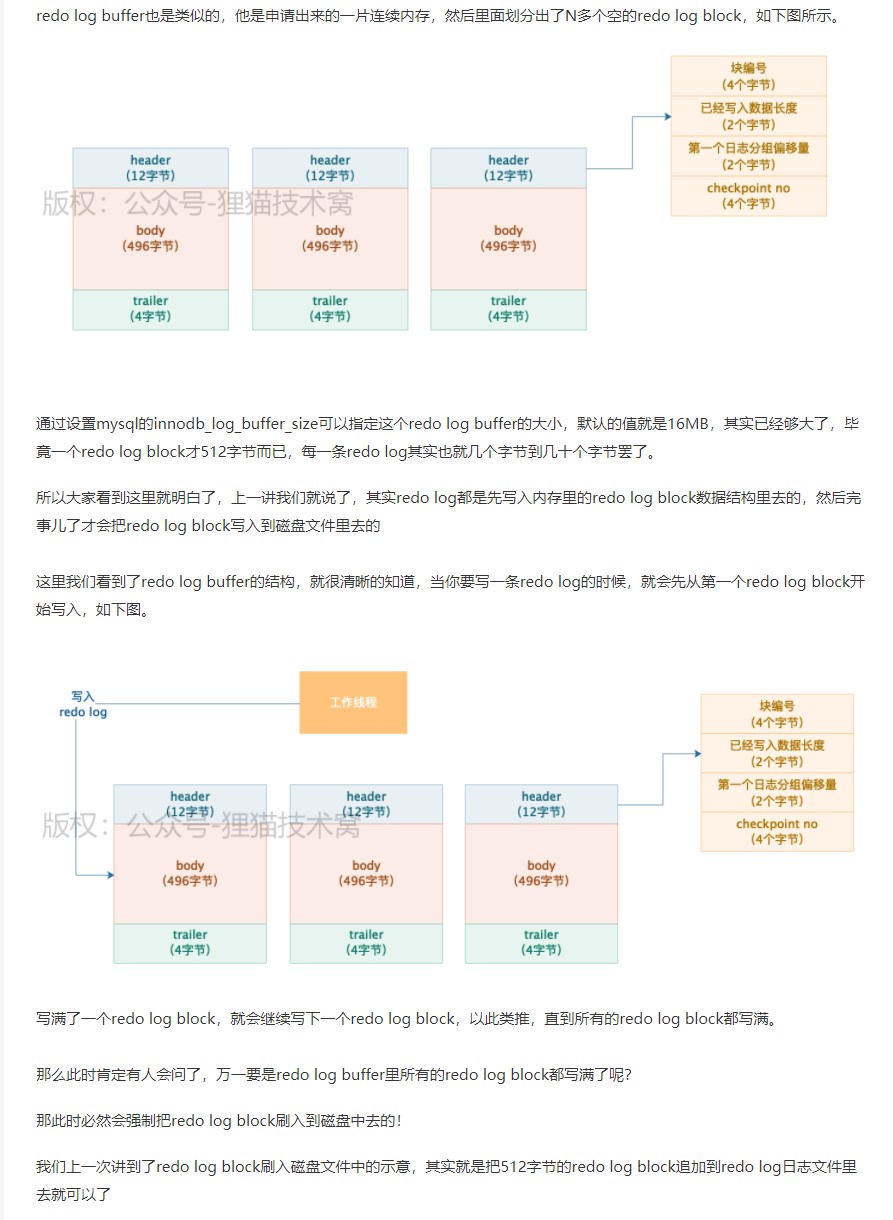
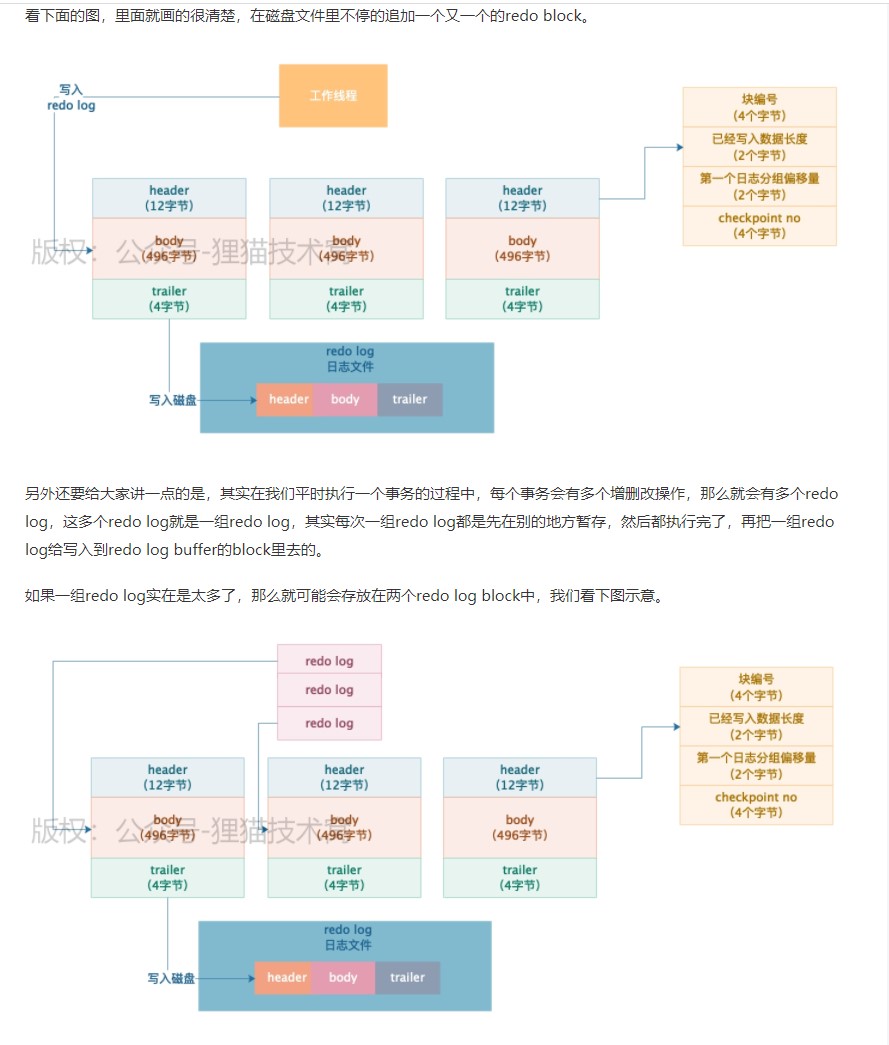
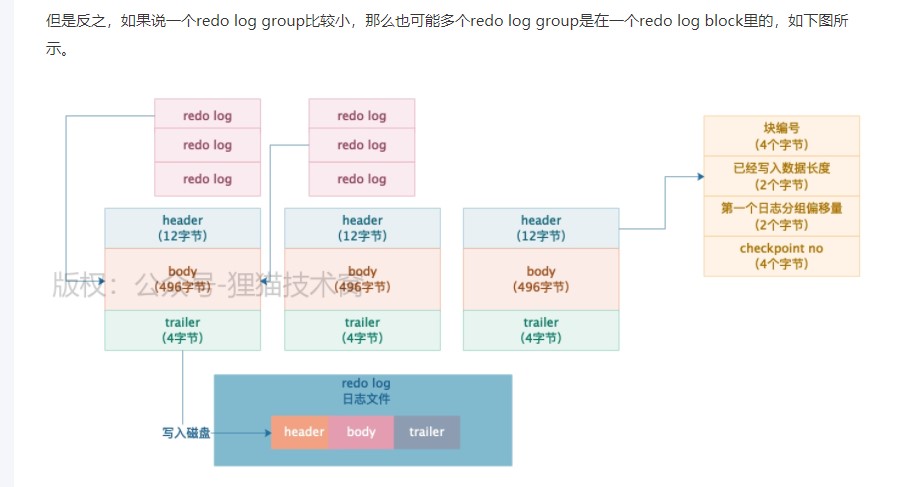
BufferPoll刷磁盘的时机
1.redolog block(写满了)
2.写入 redolog buffer 的文件大小超过了 redologbuffer 总大小的一半会同步磁盘
事务提交的时候会吧 redolog 所在的redolog block 同步到磁盘
3.后台线程每隔一秒就会把 redolog buffer 中的 redolog block 刷新到磁盘中去
4.MySQL关闭的时候会触发一次刷新
UndoLog
记录了更改之前的数据 方便回滚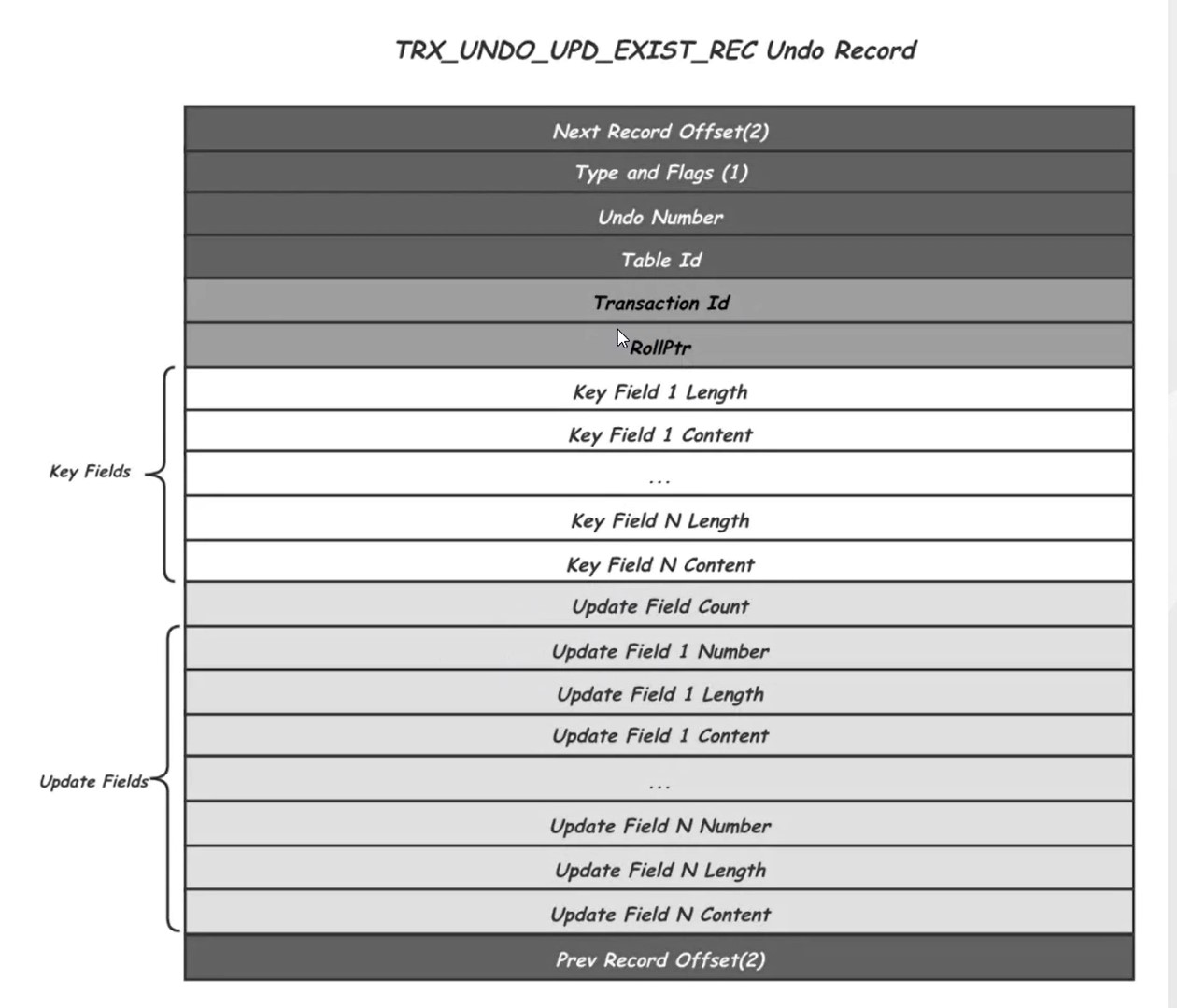
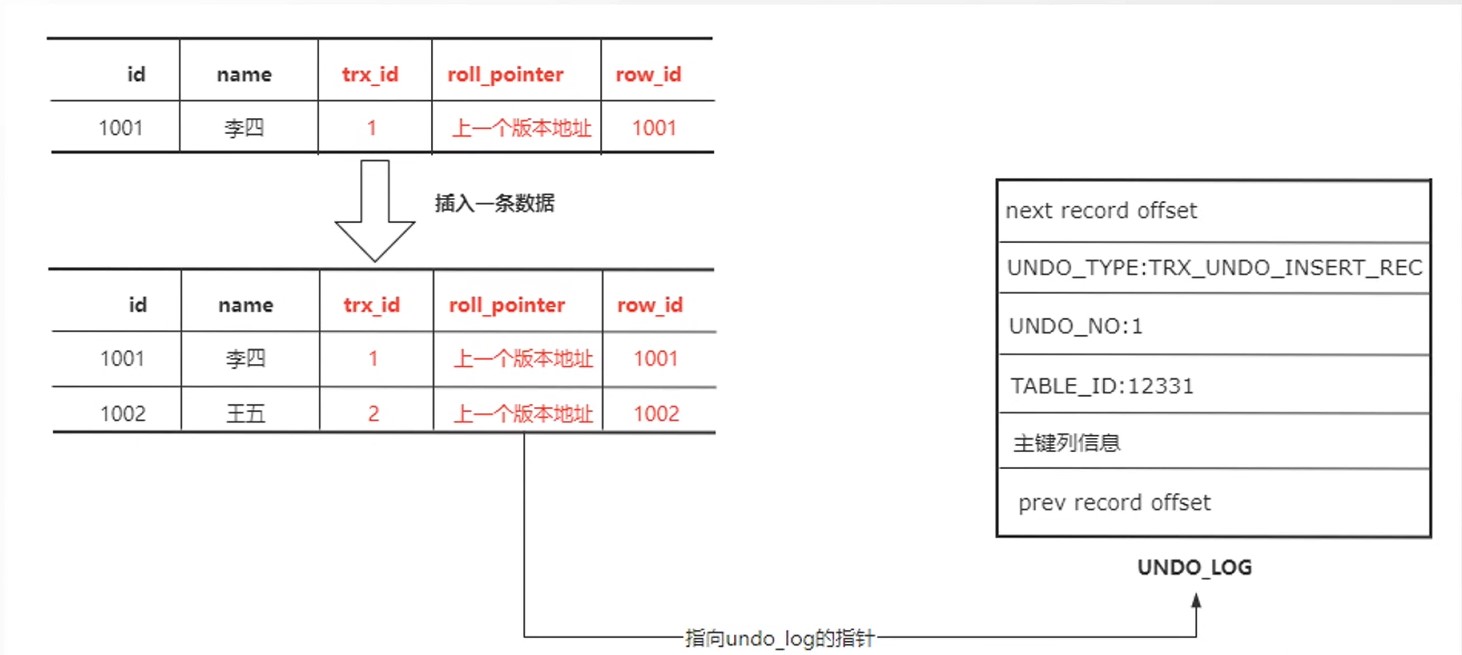
新增时 undolog的变化

修改时undolog的变化
更新主键
将原来的记录delete_mask 设置为1 表示删除 然后重新定位 插入到聚簇索引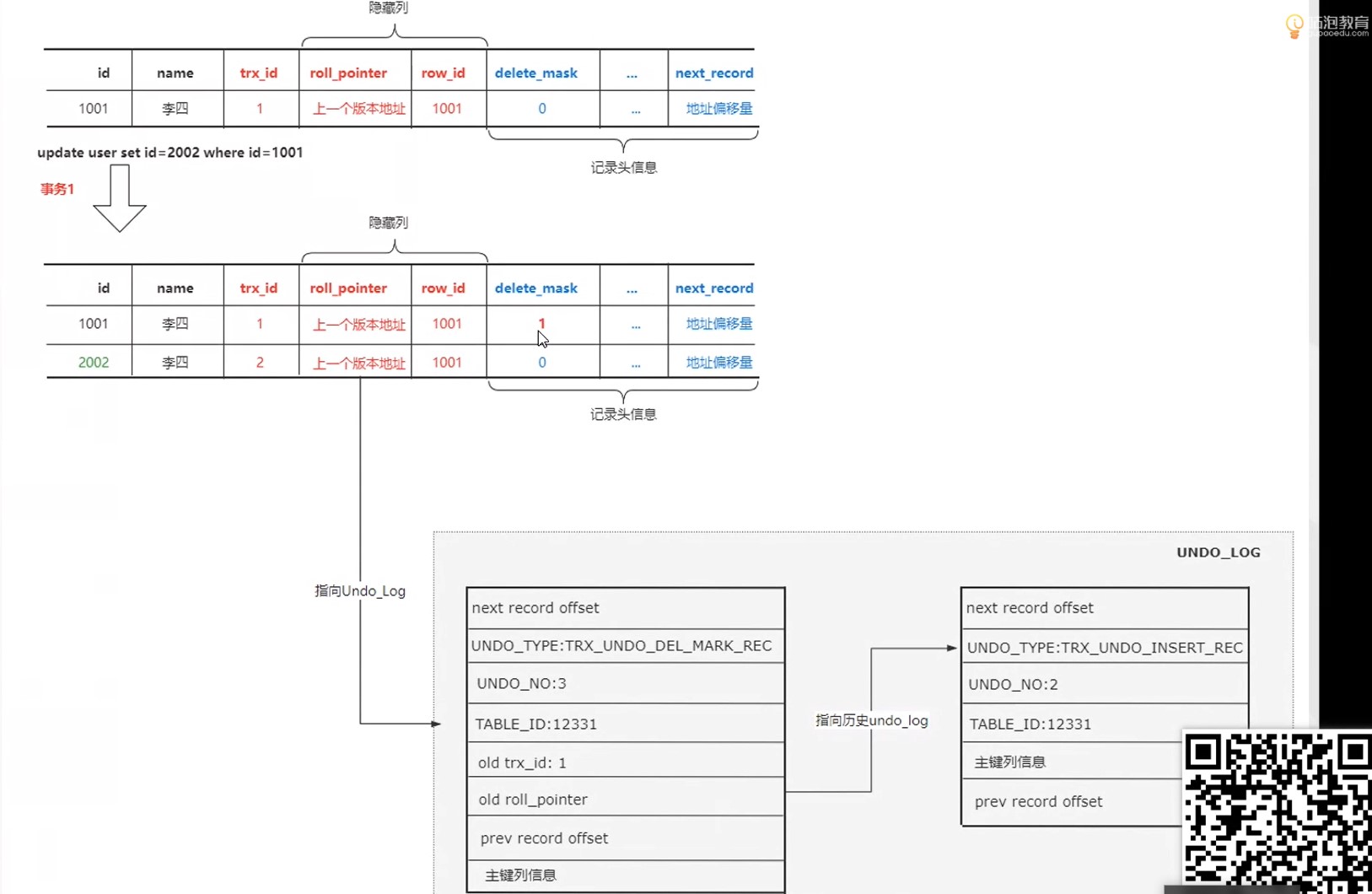
不更新主键
更新之后占据的存储空间是否发生变化(字段长度发生变化)
更新之后占据的存储空间是否发生变化(字段长度不发生变化)
删除时 undolog的变化
将 delete_mask修改成1
undolog回滚

BinLog
磁盘寻址的过程
磁盘的盘片不停的旋转 磁头会画出一个圆形轨迹 这个叫磁道
从内到外有很多磁道又用半径线把磁道分为扇区 如果要找数据就需要找到对应的扇区
随机IO
顺序IO
假设我们找到一块数据 后面所需的数据都在这块数据后面 速度快
刷盘是随机IO 记录日志是顺序IO
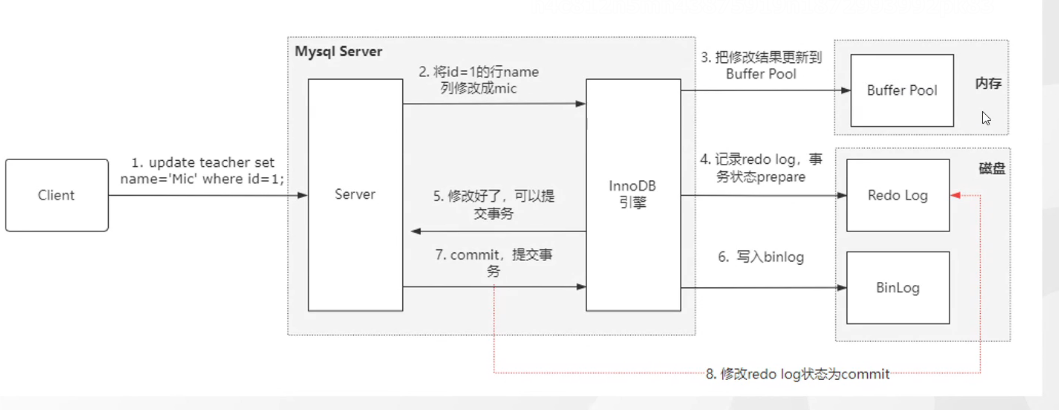
Update 语句的执行流程
将数据行更改
将修改前的值写道undolog中方便出现异常回滚
修改BuffPoll中的数据
写redlog日志
修改好了提交事务
写入binlog
提交事务
将redolog的状态改为事务已提交状态
注意:只有当redolog的事务状态为已提交状态 才算真正的执行成功 后台会有一个线程专门去监控这个状态 便于刷脏
刷盘机制

innodb_flush_log_at_trx_commit
用什么方式将 redolog buffer信息刷新到磁盘
0
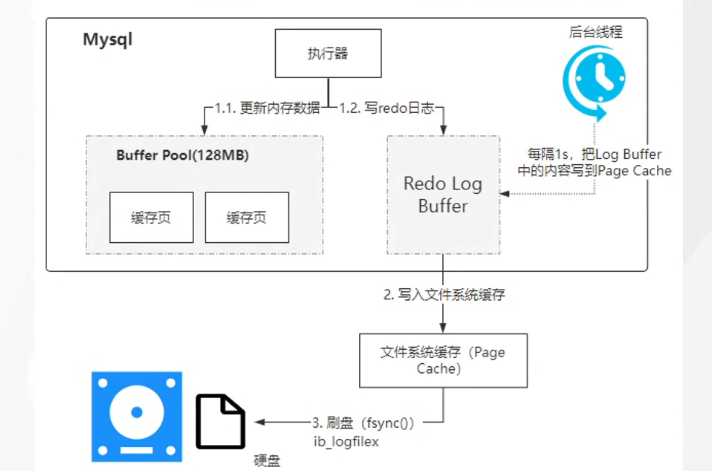
1
2
每次事务提交都会把logbuffer 写到 page Cache 中但是不会刷盘
Doublewrite Buffer Fikles
os 每次只写4k而一个数据页是16k 防止页断裂
所以会在 这个文件中记录完整的数据
如果页 数据不一致 则从 这个文件中进行恢复

若有收获,就点个赞吧
0 人点赞
