c++中表达式值类别(value categories)如下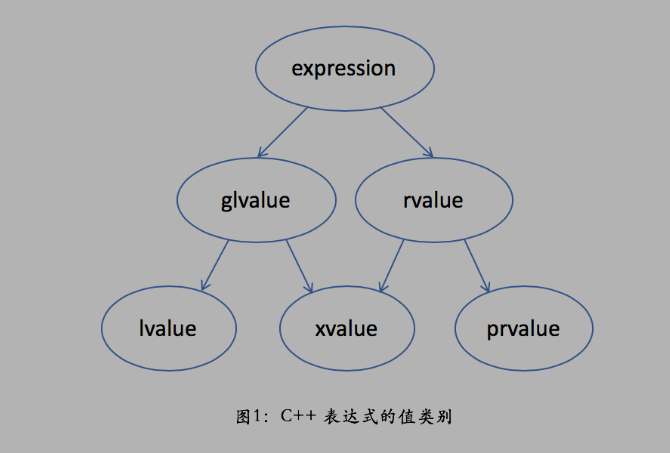
从字面意义上理解一下
一个 lvalue 是通常可以放在等号左边的表达式,左值
一个 rvalue 是通常只能放在等号右边的表达式,右值
一个 glvalue 是 generalized lvalue,广义左值
一个 xvalue 是 expiring lvalue,将亡值
一个 prvalue 是 pure rvalue,纯右值
先不管这么多先只看 lvalue 左值,prvalue 纯右值
左值是有标识符(有名—非匿名)、可以取地址的表达式,最常见的有:
变量、函数或数据成员的名字
返回左值引用的表达式 ++x,x=1,cout<<’ ’,(?:)
字符串字面量 如”hello world” 字符串字面量之所以是左值是因为它需要占用主存,是可以取地址的。而整数,字符等字面量是直接放在寄存器里 不能取地址。在C++中 字符串其实是const char[N],其实是个常量表达式,在内存中有明确的地址。
解引用表达式比如p 转型为左值引用的表达式返回的也是左值staticcast
函数调用时 左值可以被绑定到 左值引用类型(T&)的形参。[常量变量只能绑定到常左值引用(const T&)]
纯右值是没有标识符(匿名)、不可取地址的表达式(匿名临时对象是不能取地址的)--一般就是临时对象 或者字面值 常见的有:
返回非引用类型的表达式 如x++(先返回加之前的匿名对象)、x+1(返回的是一个+1后的匿名对象)、make_shared
转型为右值引用的表达式(亡值 也算右值的一种) static_cast
lamba表达式
当a为右值,以下变量是亡值(右值的一种 move后的返回值就是亡值) a[n],a.m(m为非静态非引用类型)
除了字符串字面量之外的字面量 如42、true、nullptr
_x = 1(左值) 和 ++x(左值) 返回的都是对 x 的 int&。x++(右值) 则返回的是 int。
c++11前右值可以绑定到常左值引用(const lvalue reference—-如const T&),但不能绑定到左值引用上(T&)。 在c++11后多了一种引用类型 右值引用T&&,可以使用 const 和 volatile 来进行修饰,但最常见的情况是,我们不会用 const 和 volatile 来修饰右值
smart_ptr
smart_ptr
std::move强制将一个左值变为右值而不改变其内容,在我们这儿 std::move(ptr1) 等价于 static_cast
这种将一个有名对象强制变为左值,我们可以把 std::move(ptr1) 看作是一个有名字的右值。为了跟无名的纯右值 prvalue 相区别,C++ 里目前就把这种表达式叫做 xvalue。跟左值 lvalue 不同,xvalue 仍然是不能取地址的——这点上,xvalue 和 prvalue 相同。所以,xvalue 和 prvalue 都被归为右值 rvalue。
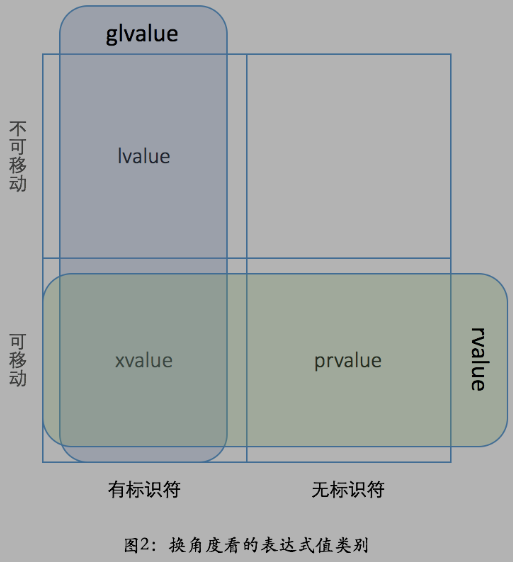
“值类别”(value category)和“值类型”(value type)是两个看似相似、却毫不相干的术语。前者指的是上面这些左值、右值相关的概念,后者则是指值类型,引用类型(reference type),表明一个变量是代表实际数值,还是引用另外一个数值。c++中所有c原生类型、枚举、结构、联合、类都是值类型,只有指针
生命周期和表达式类型
临时对象(纯右值)会在包含这个临时对象的完整表达式估值完成后、按生成顺序的逆序被销毁。
如process_shape(circle(), triangle());,一个圆和一个三角形,它们会在 process_shape 函数执行完成并生成结果对象(这个结果也是匿名的)后被销毁。
result process_shape(const shape& shape1,const shape& shape2){puts("process_shape()");return result();}
process_shape(circle(), triangle());的构造顺序是circle(), triangle(),result()。析构顺序是~result(),~triangle(),~ circle()。
虽然要返回一个临时对象 但是只会在return result();时构造一次,在return后是将这个result()对象 拿去构造一个返回的临时对象相当于result(result()),因为result()是个右值所以如果result有定义移动构造的话,会调用移动构造去构造这个真正返回的临时对象(c++11是这样的,c++14,17做了优化不会重复result(result())只会调用一次result() ),在真正返回的result(result())构造完后,return result(); result()这个临时对象析构
下面举两个例子
X retX(int i) {return X(i);}X x1 = retX(1);
1 构造return中的X(1) 2 用X(1)这个临时对象移动构造 函数真正返回的匿名对象 相当于X(X(1)) 3 return的X(1)析构 4 X x1=X(X(1));调用移动构造 构造x1 5函数真正返回的匿名对象析构 6 main结束x1析构
X &operator=(X x) noexcept {...}X x1;x1 = retX(1);
1 默认构造x1 2 构造return中的X(1) 2 用X(1)这个临时对象移动构造 函数真正返回的匿名对象 相当于X(X(1)) 3 return的X(1)析构 4 调用op= 因为retX(1)返回的是个匿名对象所以调用移动构造 用retX(1)返回的构造op=形参x 5 执行op=函数体 6 op=结束形参x析构 7 retX函数真正返回的匿名对象析构 8 main结束x1析构
c++中提出了一种延长临时对象生命周期的规则,如果一个纯右值( 临时对象 prvalue) 被绑定到一个引用上,它的生命周期则会延长到跟这个引用变量一样长。
比如之前的例子中函数返回的匿名对象,如果被绑定到了一个右值引用上,则匿名对象的生命周期将被延长的和1 r这个变量(右值引用变量)一样(注意此规则只对纯右值有效 而对将亡值std::move(ptr1)无效,将亡值的生命周期不会被延长 2中move后的变量生命周期在这句话结束后就结束了不会延长的和2r这个变量一样) 否则在这句话结束后,匿名对象就析构了
result&& r = process_shape(circle(), triangle());
函数返回的匿名对象的生命周期延长为和r变量一样
#include <utility> // std::move…result&& r = std::move(process_shape(circle(), triangle()));
将会导致隐患, r所绑定的引用是个将亡值,在这句话结束后将亡值的生命周期结束,匿名对象析构,如果后续程序对r解引用是一个未定义行为,由于r指向的是栈空间通常不会立即导致程序崩溃,但程序会出现意象不到的行为。
以前老师傅对我们说,如果C++中,函数传参,不改变参数时,尤其是大数据,尽量使用const T&。我们常用的拷贝构造函数T(const T&)参数是这个形式,vector容器的函数push_back(const value_type& val)参数也是,有没有注意到,这类函数同时也是接受右值的,简单比如:
// 函数TestClassAFunc1参数为const T&形式,可以接受右值void TestClassAFunc1(const TestClassA& refTA){std::cout << "TestClassAFunc1" << refTA.m_iSize << std::endl;}// TestClassA(1001)是右值,能够编译TestClassAFunc1(TestClassA(1001));
你可以把一个没有虚析构函数的子类对象绑定到基类的引用变量上,这个子类对象的析构仍然是完全正常的——这是因为这条规则只是延后了临时对象的析构而已,不是利用引用计数等复杂的方法,因而只要引用绑定成功,其类型并没有什么影响。
移动的意义
花这么大功夫创造出的移动语义能简化多少的拷贝操作,能提升多大的效率
对于 smartptr,我们使用右值引用的目的是实现移动,而实现移动的意义是减少运行的开销——在引用计数指针的场景下,这个开销并不大
从移动构造和拷贝构造函数的区别中可以看出差别
移动构造函数少执行一次other.shared_count->addcount() 的调用,并且因为移动清空指针指向所以在析构时少执行一次shared_count->reduce_count() 的调用
其实在使用标准库容器的情况下,移动语义更有意义
string result = string("Hello, ") + name + ".";//name 是一个string 类型对象
在c++11以前 移动语义被创造出来以前 只有拷贝构造的时代 这种写法是绝对不推荐的,因为它会引入很多额外开销,c++11以前 其流程大致如下
先说明一下string op+返回的是string对象 而非引用,op+=返回的是string引用
1 调用构造函数 string(const char),生成临时对象 1;总共”Hello, “ 复制 1 次(将”Hello,”字符串内容复制到string的char所指的一块堆上内存中)。
2 调用operator+(const string&, const string&),生成临时对象 2;总共”Hello, “ 复制 2 次,name 复制 1 次。
3 调用operator+(const string&, const string&),生成临时对象 3;总共”Hello, “ 复制 3 次,name 复制 2 次,”.”复制1次。
4假设返回值优化能够生效(最佳情况),对象 3 可以直接在(用临时对象3拷贝构造result) result 里构造完成。
5 临时对象 2 析构,释放指向 string(“Hello, “) + name 的内存。
6 临时对象 1 析构,释放指向 string(“Hello, “) 的内存。
合格的c++程序员会这么写
string result = "Hello, ";result += name;result += ".";
这样的话,只会调用构造函数一次和 string::operator+= (op+=返回的应该是个左值)两次,没有任何临时对象需要生成和析构,所有的字符串都只复制了一次。但显然代码就啰嗦多了——尤其如果拼接的步骤比较多的话。
从c++11开始string result = string(“Hello, “) + name + “.”;//name 是一个string 类型对象
的执行流程变为如下
1调用构造函数 string(const char),生成临时对象 1;”Hello, “ 复制 1 次。
2调用 operator+(string&&临时对象 1右值, const string&),直接在临时对象 1 上面执行追加操作,并把结果移动(op+返回的匿名对象时调用移动构造将资源移到匿名对象上)到临时对象 2;name 复制 1 次。
3调用 operator+(string&&临时对象 2右值, const char),直接在临时对象 2 上面执行追加操作,并把结果移动到 result(调用移动构造 用追加后的临时对象构造result);”.” 复制 1 次。
4临时对象 2 析构,内容已经为空,不需要释放任何内存。
5临时对象 1 析构,内容已经为空,不需要释放任何内存
性能上,所有的字符串只复制了一次;虽然比啰嗦的写法仍然要增加临时对象的构造和析构,但由于这些操作不牵涉到额外的内存分配和释放,是相当廉价的。程序员只需要牺牲一点点性能,就可以大大增加代码的可读性。而且,所谓的性能牺牲,也只是相对于优化得很好的 C 或 C++ 代码而言——这样的 C++ 代码的性能仍然完全可以超越 Python 类的语言的相应代码。
为了快速地直接复制对象(不是对象引用而是对象),所以c++添加了移动语义
移动语义使得在 C++ 里返回大对象(如容器)的函数和运算符成为现实,因而可以提高代码的简洁性和可读性,提高程序员的生产率。所有的现代 C++ 的标准容器都针对移动进行了优化。
如何让我设计的对象支持移动
1 类中要分别有拷贝构造和移动构造(除非你想像unique_ptr一个资源只能有一个对象获得 那么就只写移动构造不写拷贝构造)
2 类中要有swap成员函数,支持和另外一个对象快速交换成员变量以及资源
void swap(smart_ptr& rhs)//用于资源交换
3 在类所在命名空间下,还要有一个全局的swap函数,调用成员swap实现交换。这种做法方便在其他对象里包含你这个对象时能实现快速交换swap。
template <typename T>void swap(smart_ptr<T>& lhs,smart_ptr<T>& rhs) noexcept
4 实现通用的operator=
通常我们考虑到 a = a; 这样的写法安全,下面的写法算是个小技巧,对传递左值和右值都有效,而且规避了 if (&rhs != this) 这样的判断。—-这个技巧的解释在上面也有讲过23页有技巧解释
smart_ptr& operator=(smart_ptr rhs) noexcept{rhs.swap(*this);return *this;//this swap获得了rhs的资源 而rhs是局部对象在函数结束后自动析构}
注意上面的各个函数如果不抛出异常的话 都应当标识noexcept,这对移动构造函数尤为重要(因为只有在标识noexcept的情况下才会调用移动构造)
具体的写法可以参考之前实现的smart_ptr
移动构造函数应当从另一个对象获取资源,清空其资源,并将其置为一个可析构的状态。
从C++11开始,如果我们没有手写移动拷贝构造函数,编译器会不会帮我们生成一个呢?只有下面4个函数同时没有手动定义时,编译器才会帮我们生成移动拷贝构造函数,原型为:T(const T& )
1.复制构造函数
2.复制赋值运算符
3.移动赋值运算符
4.析构函数
不要返回局部变量的引用
在函数里返回一个局部对象的引用。由于在函数结束时局部对象即被销毁,返回一个指向局部对象的引用属于未定义行为。理论上来说,程序出任何奇怪的行为都是正常的。
在c++11之前,返回一个局部对象(返回对象,而不是返回对象的引用)意味着这个对象会被拷贝,除非编译器发现可以做返回值优化(NRVO),能把对象直接构造到调用者的栈上(即直接返回一个局部对象,一般还需要用这个retuern 后标识的对象再去构造一个真正返回的临时对象,而如果编译器有做NRVO优化的话会直接用retuern 后标识的对象去构造用于接受函数返回值的栈上对象—-c++11NRVO优化行为,否则就是还需要再冗余地包装一层)。
在c++11开始,NRVO仍可以发生,在NRVO没有发生的情况下,编译器将试图把局部对象移动出去(将局部对象移动给 真正返回的匿名对象 而后局部对象析构)而不是像以前那样拷贝(拷贝给真正返回的 匿名对象)出去。这一行为不需要程序员手动std::move干预,std::move对移动行为没有帮助,反而会禁止NRVO
#include <iostream> // std::cout/endl#include <utility> // std::moveusing namespace std;class Obj {public:Obj(){cout << "Obj()" << endl;}Obj(const Obj&){cout << "Obj(const Obj&)"<< endl;}Obj(Obj&&){cout << "Obj(Obj&&)" << endl;}};Obj simple(){Obj obj;// 简单返回对象;一般有 NRVOreturn obj;}Obj simple_with_move(){Obj obj;// move 会禁止 NRVOreturn std::move(obj);}Obj complicated(int n){Obj obj1;Obj obj2;// 有return分支,一般无 NRVO 使用移动构造函数返回的对象if (n % 2 == 0) {return obj1;} else {return obj2;}}int main(){cout << "*** 1 ***" << endl;auto obj1 = simple();cout << "*** 2 ***" << endl;auto obj2 = simple_with_move();cout << "*** 3 ***" << endl;auto obj3 = complicated(42);}
输出
1
Obj()
2
Obj()
Obj(Obj&&)
3
Obj()
Obj()
Obj(Obj&&)

若有收获,就点个赞吧
0 人点赞
